







在 Java 多线程编程领域,Java 内存模型(Java Memory Model,JMM)是保障程序正确性与性能的核心机制。它定义了多线程环境下共享变量的访问规则,影响程序的原子性、有序性和可见性。本文将从 JMM 的基础概念出发,深入剖析其与 Java 运行时内存区域的关系、内存可见性问题、指令重排序、顺序一致性模型以及 happens-before 原则等关键内容。
一、JMM 与 Java 运行时内存区域:概念本质与体系架构对比
1.1 抽象规则体系与具体内存划分的概念界定
Java 内存模型(JMM)是一套抽象的规则和规范,它并不直接对应物理内存或 JVM 的具体实现,而是定义了多线程环境下,线程如何与主内存、工作内存进行交互,以及共享变量的访问方式。JMM 通过规范线程对共享变量的读写操作,确保在不同的 JVM 实现和硬件平台上,多线程程序能够保持一致的行为。
而 Java 运行时内存区域则是 JVM 在运行 Java 程序时,对内存的具体划分。根据《Java 虚拟机规范》,Java 运行时内存区域主要包括程序计数器、虚拟机栈、本地方法栈、堆和方法区。这些区域各自承担着不同的功能,如虚拟机栈用于存储局部变量和方法调用的帧信息,堆用于存放对象实例等 。
1.2 功能特性层面的本质性差异分析
JMM 围绕原子性、有序性和可见性等特性展开,旨在解决多线程环境下共享变量的访问问题。例如,在多线程并发修改共享变量时,JMM 需要保证一个线程对共享变量的修改能够及时被其他线程感知(可见性),并且操作的执行顺序符合预期(有序性),同时某些关键操作具备原子性,不会被其他线程干扰 。
Java 运行时内存区域的划分则侧重于程序运行时的内存管理和资源分配。每个区域有着明确的职责和生命周期,比如堆内存是所有线程共享的,用于对象的创建和存储,而虚拟机栈是线程私有的,随着线程的创建而创建,随着线程的结束而销毁 。
1.3 私有 / 共享数据区域的逻辑对应关系阐释
在逻辑上,JMM 中的主存对应 Java 运行时内存区域中的共享数据区域,主要包含堆和方法区。堆中存放着对象实例,方法区存储类的元数据、常量等,这些数据可以被多个线程共享访问 。
JMM 中的本地内存则对应 Java 运行时内存区域中的私有数据区域,包括程序计数器、本地方法栈和虚拟机栈。程序计数器记录当前线程执行的字节码指令地址,本地方法栈用于本地方法调用,虚拟机栈存储局部变量和方法调用信息,它们都是线程私有的,每个线程都有独立的副本,其他线程无法直接访问 。
二、JMM 内存可见性问题:理论根源、作用域与解决方案
2.1 基于 JMM 规范的可见性问题产生机理
根据 JMM 的规定,线程对共享变量的所有操作都必须在自己的本地内存中进行,不能直接从主存中读取。每个线程都保存了一份该线程使用到的共享变量的副本,当线程对共享变量进行修改时,首先修改的是本地内存中的副本,然后再将修改后的结果刷新到主存中 。
由于线程间通信必须经过主存,这就导致了内存可见性问题。例如,线程 A 修改了共享变量 x 的值,并将其刷新到主存中,但此时线程 B 的本地内存中仍然是 x 的旧值。如果线程 B 没有及时从主存中读取最新值,就会出现读取到的数据与实际值不一致的情况,这就是变量延迟更新、不一致的内存可见性问题 。
2.2 共享变量内存空间的可见性问题作用域界定
在 Java 中,对于每一个线程来说,栈都是私有的,而堆是共有的。栈中的变量(局部变量、方法定义的参数、异常处理的参数)不会在线程之间共享,因此不会出现内存可见性问题,也不受内存模型的影响 。
而堆中的变量是共享的,一般称之为共享变量,内存可见性问题主要就针对这些在堆中的共享变量。当多个线程同时访问和修改堆中的共享变量时,如果没有正确的同步机制,就容易出现内存可见性问题,导致程序运行结果错误 。
2.3 volatile 与 synchronized 的可见性保障策略解析
1、volatile关键字可以保证变量的可见性,但不保证原子性。当一个变量被声明为volatile时,线程在读取变量时,会直接从主存中读取最新值,而不是使用本地内存的副本;在写入变量时,会立即将新值刷新到主存中,从而确保其他线程能够及时看到该变量的最新值 。
例如:
public class VolatileExample {
// 使用volatile关键字确保flag变量的可见性
private volatile boolean flag = false;
// 设置flag为true
public void setFlag() {
flag = true;
}
// 获取当前flag状态
public boolean isFlag() {
return flag;
}
}
在上述代码中,flag变量被声明为volatile,当一个线程调用setFlag方法修改flag的值后,其他线程调用isFlag方法能够立即获取到最新值 。
2、synchronized关键字则不仅保证可见性,还保证原子性。当一个线程进入synchronized同步块时,会先将本地内存中的共享变量刷新到主存中,然后从主存中读取最新值;在退出同步块时,会将修改后的共享变量再次刷新到主存中,确保其他线程能够看到最新的修改 。同时,在同一时刻,只有一个线程能够进入synchronized同步块,保证了同步块内的操作是原子性的 。
例如:
public class SynchronizedExample {
private int count = 0;
// 线程安全的计数增加方法
public synchronized void increment() {
count++;
}
// 获取当前计数值
public int getCount() {
return count;
}
}
在这个例子中,increment方法使用synchronized修饰,保证了count++操作的原子性和可见性,多个线程同时调用increment方法时,不会出现数据竞争和结果错误的情况 。
3、happens—before也可以解决(下面详解)
三、JMM 与指令重排序:性能优化机制与线程安全风险
3.1 指令重排序的 CPU 性能优化理论基础
计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排。指令重排的核心原理基于流水线技术。每个指令的执行包含多个步骤,且各步骤可由不同硬件执行。流水线技术允许指令 1 未执行完时,就开始执行指令 2,从而提升执行效率。但流水线技术最怕中断,恢复中断的代价高昂。
以代码a = b + c; d = e - f ;为例,先加载b、c,但执行add(b,c)时需等待b、c装载完成,这会产生停顿,后续加载e和f的指令也会停顿,降低执行效率。而通过指令重排,在加载完b和c后,同时加载e和f,再执行add(b,c),在不影响串行程序结果的前提下,减少了停顿,提高了 CPU 执行效率 。
3.2 编译器、指令并行与内存系统的重排序类型解析
指令重排一般分为以下三种类型:
- 编译器优化重排:编译器在不改变单线程程序语义的前提下,对代码进行分析和优化,重新安排语句的执行顺序。例如,编译器可能会将一些不相关的变量赋值操作提前执行,以提高程序的执行效率 。
- 指令并行重排:现代处理器采用指令级并行技术(包含取指令-指令译码 - 执行指令 - 内存访问 - 数据写回这 5 个阶段),将多条指令重叠执行。当不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果)时,处理器可以改变语句对应的机器指令的执行顺序,从而提高处理器的利用率 。
- 内存系统重排序:由于处理器使用缓存和读写缓存冲区,内存与缓存的数据同步存在时间差,这使得加载 (load) 和存储 (store) 操作看上去可能是在乱序执行。例如,处理器可能会先将数据写入缓存,而不是立即写入内存,导致其他处理器读取到的数据不是最新值 。
3.3 多线程环境下指令重排序引发的语义错乱风险
指令重排可以保证串行语义一致,但在多线程环境下,它没有义务保证多线程间的语义也一致。例如,在多线程程序中,如果两个线程同时访问和修改共享变量,并且存在指令重排,可能会导致一个线程看到的操作顺序与实际执行顺序不同,从而引发数据竞争和程序逻辑错误 。
以下是一个经典的指令重排序导致问题的示例:
public class ReorderingExample { private static int a = 0, b = 0; private static int x = 0, y = 0; public static void thread1() { a = 1; x = b; } public static void thread2() { b = 1; y = a; } public static void main(String[] args) throws InterruptedException { int iteration = 0; while (true) { iteration++; // 重置变量 a = b = x = y = 0; Thread t1 = new Thread(ReorderingExample::thread1); Thread t2 = new Thread(ReorderingExample::thread2); t1.start(); t2.start(); t1.join(); t2.join(); if (x == 0 && y == 0) { System.out.println("检测到指令重排异常,发生在第 " + iteration + " 次迭代"); break; } } } }
在上述代码中,由于指令重排,可能会出现thread1中a = 1和x = b的执行顺序被打乱,thread2中b = 1和y = a的执行顺序也被打乱,从而导致x == 0 && y == 0的情况出现,这与我们预期的结果不符 合。
四、JMM 与顺序一致性模型:理想模型与工程实现的差异
4.1 顺序一致性模型的理论特性定义
顺序一致性模型是一个理想化的内存一致性模型,它保证了以下两个特性:
- 单线程内的操作顺序:一个线程中的所有操作必须按照代码中定义的顺序执行。例如,对于线程 A 中的操作 A1、A2、A3,在顺序一致性模型下,必须严格按照 A1、A2、A3 的顺序执行,不会发生重排序 。
- 多线程可见性:不论程序是否同步,所有线程都只能看到一个全局一致的操作顺序。也就是说,一个线程的所有操作在其他线程中必须是原子且立即可见的。例如,线程 A 对共享变量的修改,线程 B 能够立即看到最新值,且看到的操作顺序与实际执行顺序一致 。
4.2 单线程执行顺序的模型差异对比
在顺序一致性模型中,严格保证单线程内的操作会按程序的顺序执行,不会出现任何重排序情况。而 JMM 虽然不保证单线程内的操作会按程序的顺序执行(因为在临界区可能会做重排序),但 JMM 保证单线程下的重排序不会影响执行结果 。
JMM 的具体实现方针是:在不改变(正确同步的)程序执行结果的前提下,尽量为编译期和处理器的优化打开方便之门。例如,在没有数据依赖的情况下,JMM 允许编译器和处理器对单线程内的指令进行重排,以提高程序的执行效率 。
4.3 多线程可见性与原子性保障的实现差异
顺序一致性模型提供了一致的可见性,所有线程在同一时间能看到相同的操作结果,不存在数据竞争问题。而 JMM 则没有保证所有线程在同一时间能看到相同的操作结果,因为 JMM 不保证所有操作立即可见 。
在 JMM 中,如果没有正确的同步(例如使用volatile、synchronized或final),在多线程环境中就可能出现数据竞争问题,导致一个线程读取到不一致的、甚至是错误的值 。
此外,顺序一致性模型保证对所有的内存读写操作都具有原子性,而 JMM 不保证对 64 位(可能需要多个 CPU 指令来完成)的long型和double型变量的写操作具有原子性。在 JMM 中,对long和double类型变量的写操作可能会被拆分成两个 32 位的操作,从而导致在多线程环境下出现数据不一致的情况 。
五、JMM 与 happens-before 原则:内存可见性的规则保障体系
5.1 happens-before 关系的形式化定义与语义解析
happens-before是 JMM 中一种约定的开发规则,它的定义如下:如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前 。
需要注意的是,两个操作之间存在happens-before关系,并不意味着 Java 平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么 JMM 也允许这样的重排序 。
例如,在以下代码中:
public class HappensBeforeExample { private int num = 0; private boolean flag = false; public void write() { num = 1; // 操作1:写入num flag = true; // 操作2:设置flag } public void read() { if (flag) { // 操作3:检查flag int result = num; // 操作4:读取num } } }
在write方法中,操作 1happens-before操作 2;在read方法中,如果flag为true,那么操作 3happens-before操作 4。并且,由于write方法中的操作 2 对read方法中的操作 3 可见,所以操作 1 的结果(num的值为 1)对操作 4 也是可见的 。
5.2 基于 happens-before 规则的内存可见性保障机制
happens-before规则是 JMM 提供的强大的内存可见性保证。只要遵循happens-before规则,我们编写的程序就能保证在 JMM 中具有强的内存可见性 。
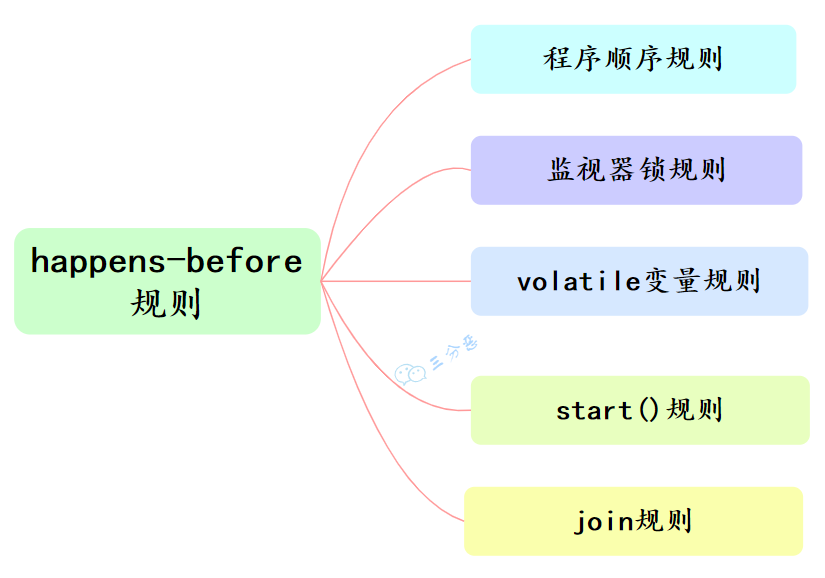
happens-before规则包含了多种情况,例如:
- 程序顺序规则:一个线程内,按照程序代码顺序,前面的操作happens-before于后面的操作。
- 监视器锁规则:对一个监视器锁的解锁操作happens-before于后续对这个监视器锁的加锁操作。
- volatile 变量规则:对一个volatile变量的写操作happens-before于后续对这个volatile变量的读操作 。
通过这些规则,我们可以在多线程编程中合理地安排操作顺序,确保共享变量的正确访问和内存可见性,避免出现数据竞争和错误的结果 。
六、博主总结
-
Java内存模型JMM(用来描述多线程环境中共享变量的内存可见性。)
- Java 内存模型(JMM) 和 Java 运行时内存区域的划分,这两者既有差别又有联系:
- JMM抽象模型示意图
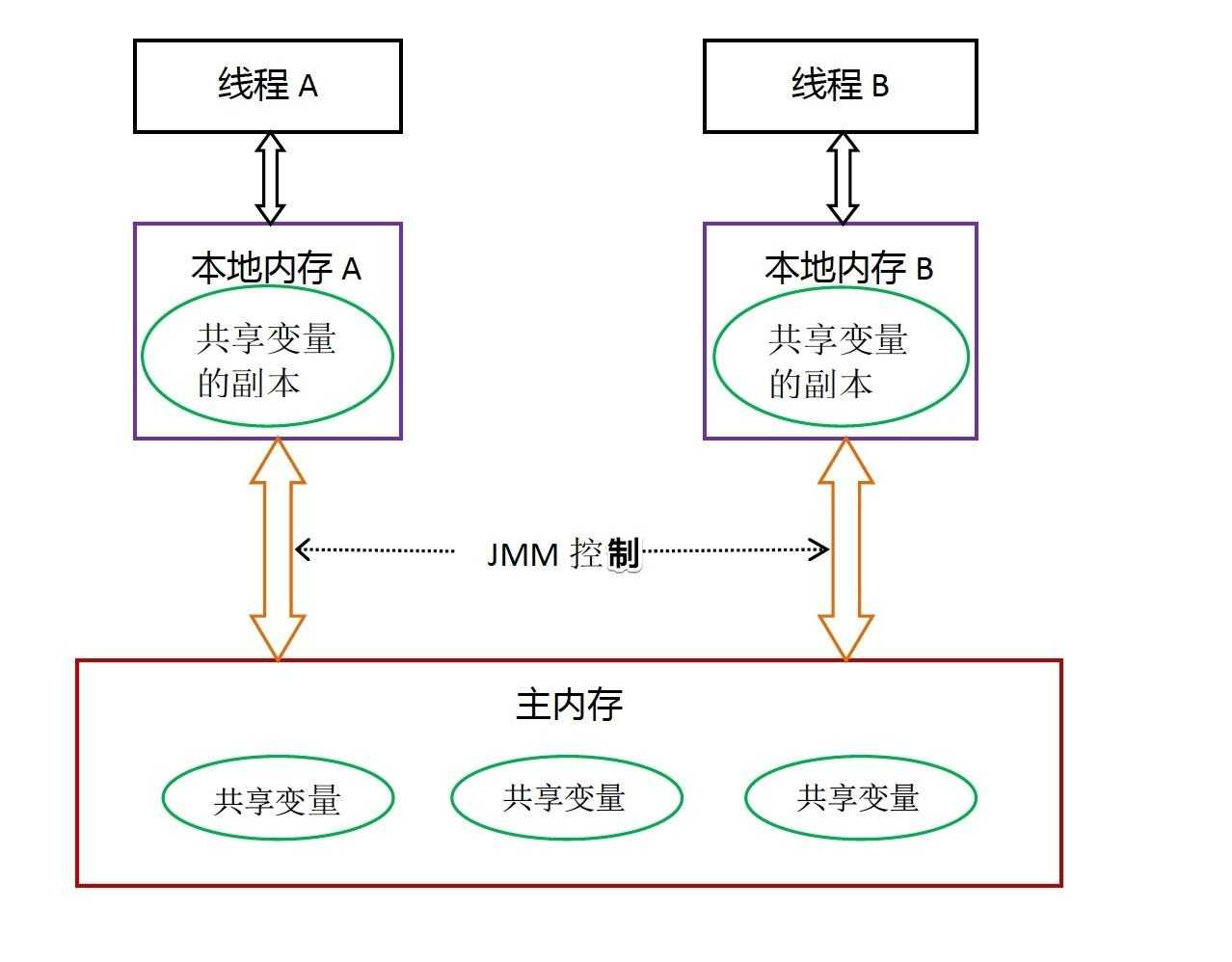
- 从图中可以看出:
- 所有的共享变量都存在主存中。
- 每个线程都保存了一份该线程使用到的共享变量的副本。
- 如果线程 A 与线程 B 之间要通信的话,必须经历下面 2 个步骤:
- 线程 A 将本地内存 A 中更新过的共享变量刷新到主存中去。
- 线程 B 到主存中去读取线程 A 之前已经更新过的共享变量。
- 从图中可以看出:
- Java 运行时内存区域示意图
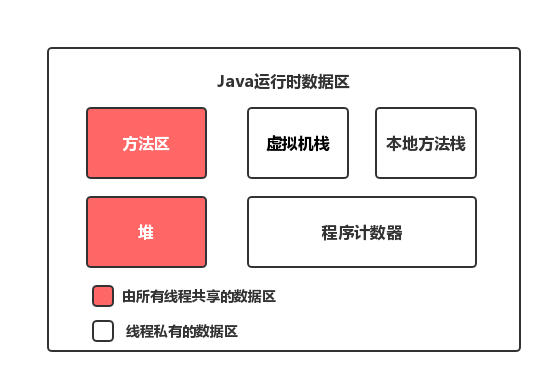
- 区别:两者是不同的概念。
- JMM 是抽象的,他是用来描述一组规则,通过这个规则来控制各个变量的访问方式,围绕原子性、有序性、可见性等展开,主要针对的是多线程环境下,如何在主内存与工作内存之间安全地执行操作。
- 而 Java 运行时内存的划分是具体的,是 JVM 运行 Java 程序时必要的内存划分。
- 联系:都存在私有数据区域和共享数据区域。
- 一般来说,JMM 中的主存属于共享数据区域,包含了堆和方法区。JMM 中的本地内存属于私有数据区域,包含了程序计数器、本地方法栈、虚拟机栈。
- JMM抽象模型示意图
- JMM内存可见性问题(为什么出现?在哪里出现?怎么解决?)
- 为什么出现?(为了高效,而使用了缓存)
- 这是因为现代计算机为了高效,往往会在高速缓存区中缓存共享变量,因为 CPU 访问缓存区比访问内存要快得多。
- 根据 JMM 的规定,线程对共享变量的所有操作都必须在自己的本地内存中进行,不能直接从主存中读取。
- 根据JMM抽象模型图也可以看出,线程 A 无法直接访问线程 B 的工作内存,线程间通信必须经过主存。所以线程 B 并不是直接去主存中读取共享变量的值,而是先在本地内存 B 中找到这个共享变量,发现这个共享变量已经被更新了,然后本地内存 B 去主存中读取这个共享变量的新值,并拷贝到本地内存 B 中,最后线程 B 再读取本地内存 B 中的新值。
- 所以会出现变量延迟更新、不一致情况即出现内存可见性问题。
- 在哪里出现?
- 对于每一个线程来说,栈都是私有的,而堆是共有的。也就是说,在栈中的变量(局部变量、方法定义的参数、异常处理的参数)不会在线程之间共享,也就不会有内存可见性的问题,也不受内存模型的影响。而在堆中的变量是共享的,一般称之为共享变量。所以,内存可见性针对的是堆中的共享变量。
- 怎么解决?
- JMM与happens-before
- happens-before是一种约定的开发规则。happens-before 关系的定义如下:
- 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在 happens-before 关系,并不意味着 Java 平台的具体实现必须要按照 happens-before 关系指定的顺序来执行。如果重排序之后的执行结果,与按 happens-before 关系来执行的结果一致,那么 JMM 也允许这样的重排序。
- happens-before 规则是 JMM 提供的强大的内存可见性保证,只要遵循 happens-before 规则,那么我们写的程序就能保证在 JMM 中具有强的内存可见性。
- JMM 规定了 6 种 Happens-Before 规则,满足这些规则的操作不会被重排序,并且保证了数据的可见性。
-
- happens-before是一种约定的开发规则。happens-before 关系的定义如下:
- volitile也可保证可见性但是不保证原子性。
- sync锁保证可见性、原子性。

- JMM与happens-before
- 为什么出现?(为了高效,而使用了缓存)
- JMM 与重排序(保证运行高效)
- 计算机在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排。
- 举个例子来说明一下:为什么要重排序。
- 那可能有小伙伴就要问:为什么指令重排序可以提高性能?简单地说,每一个指令都会包含多个步骤,每个步骤可能使用不同的硬件。因此,流水线技术产生了,它的原理是指令 1 还没有执行完,就可以开始执行指令 2,而不用等到指令 1 执行结束后再执行指令 2,这样就大大提高了效率。但是,流水线技术最害怕中断,恢复中断的代价是比较大的,所以我们要想尽办法不让流水线中断。指令重排就是减少中断的一种技术。我们分析一下下面这段代码的执行情况:
- a = b + c; d = e - f ;
- 先加载 b、c(注意,有可能先加载 b,也有可能先加载 c),但是在执行 add(b,c) 的时候,需要等待 b、c 装载结束才能继续执行,也就是需要增加停顿,那么后面的指令(加载 e 和 f)也会有停顿,这就降低了计算机的执行效率。为了减少停顿,我们可以在加载完 b 和 c 后把 e 和 f 也加载了,然后再去执行 add(b,c),这样做对程序(串行)是没有影响的,但却减少了停顿。换句话说,既然 add(b,c) 需要停顿,那还不如去做一些有意义的事情(加载 e 和 f)。
- 综上所述,指令重排对于提高 CPU 性能十分必要,但也带来了乱序的问题。
- 重排序有哪几种?指令重排一般分为以下三种:
- 编译器优化重排,编译器在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
- 指令并行重排,现代处理器采用了指令级并行技术(取指令-指令译码-执行指令-内存访问-数据写回这5个阶段)来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
- 内存系统重排,由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
- 指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。所以在多线程下,指令重排序可能会导致一些问题。
- JMM与顺序一致性模型(保证答案正确)
- 顺序一致性模型是什么:是一个理想化的内存一致性模型,它保证了以下两个特性:
- 单线程内的操作顺序:一个线程中的所有操作必须按照代码中定义的顺序执行。对于线程 A 中的操作 A1、A2、A3,必须按照此顺序执行,而不会重排序。
- 多线程可见性:不论程序是否同步,所有线程都只能看到一个全局一致的操作顺序。换句话说,一个线程的所有操作在其他线程中必须是原子且立即可见的。
- 区别:未同步程序在 JMM 和顺序一致性内存模型中的执行特性有如下差异:
- 顺序一致性保证单线程内的操作会按程序的顺序执行;JMM 不保证单线程内的操作会按程序的顺序执行。(因为在临界区做了重排序,但是 JMM 保证单线程下的重排序不影响执行结果)。
- JMM 会在线程进入和退出临界区时进行特殊处理,以确保临界区内(同步块或同步方法中)内程序的行为与顺序一致性模型相同,接着在临界区做了重排序。由此可见,JMM 的具体实现方针是:在不改变(正确同步的)程序执行结果的前提下,尽量为编译期和处理器的优化打开方便之门。
- 顺序一致性模型提供了一致的可见性,而 JMM 则没有保证所有线程在同一时间能看到相同的操作结果。(因为 JMM 不保证所有操作立即可见)。
- JMM存在的数据竞争问题(可见性问题):在多线程环境中,如果没有正确的同步(例如使用 volatile、synchronized 或 final),这会导致一个线程读取到不一致的、甚至是错误的值。就可能出现数据竞争。
- 顺序一致性模型保证对所有的内存读写操作都具有原子性,而 JMM 不保证对 64 位(可能需要多个 CPU 指令来完成)的 long 型和 double 型变量的写操作具有原子性。
- 顺序一致性保证单线程内的操作会按程序的顺序执行;JMM 不保证单线程内的操作会按程序的顺序执行。(因为在临界区做了重排序,但是 JMM 保证单线程下的重排序不影响执行结果)。
- 顺序一致性模型是什么:是一个理想化的内存一致性模型,它保证了以下两个特性:
- Java 内存模型(JMM) 和 Java 运行时内存区域的划分,这两者既有差别又有联系:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









