










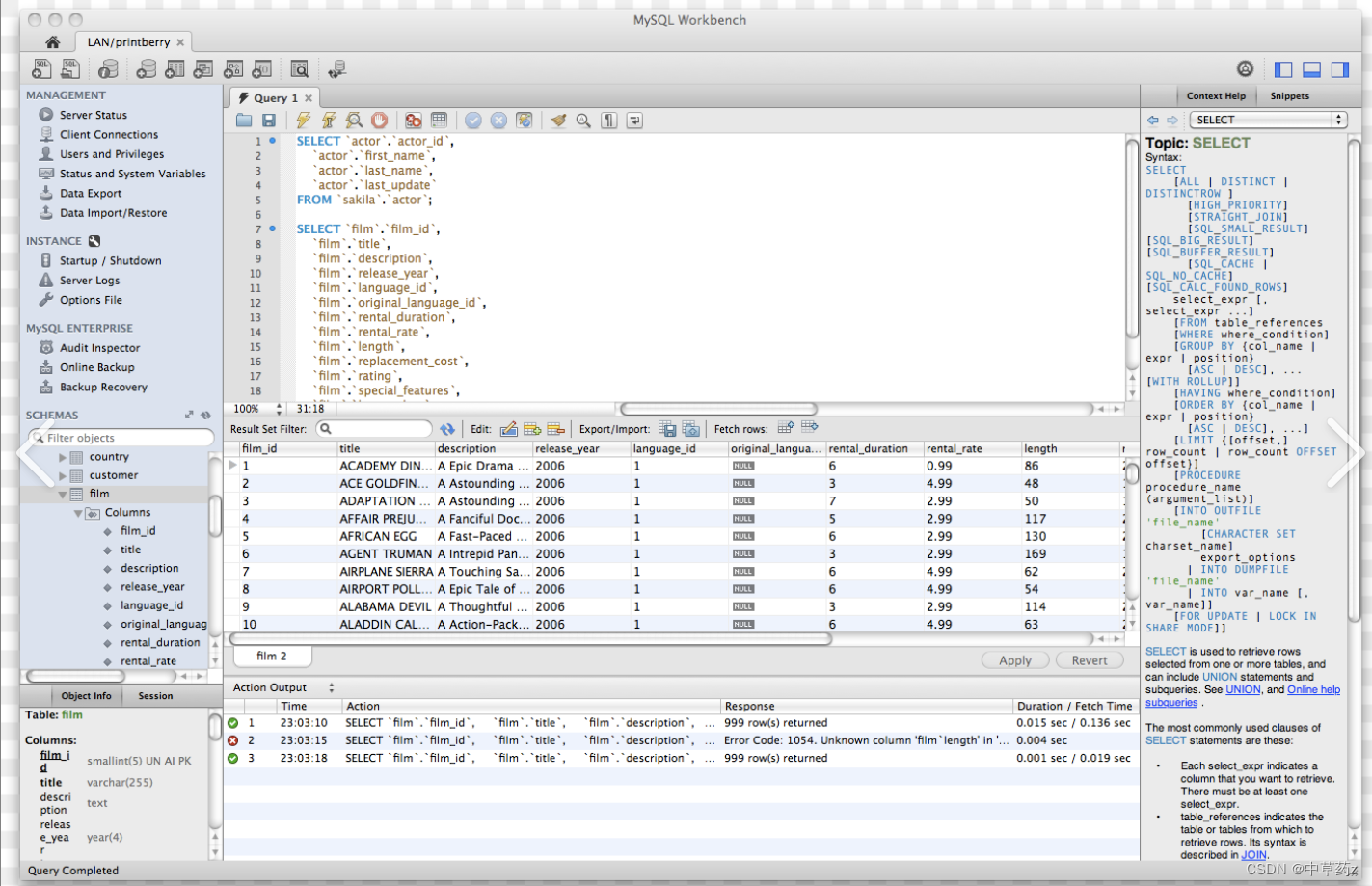
在信息爆炸的今天,数据无处不在,它们构成了互联网世界的基石。但数据本身若未经有效组织和管理,就如同散落在沙滩上的珍珠,难以发挥其真正的价值。这时,“数据库”这一概念便如同一根线,将这些珍珠串联起来,使之成为璀璨的项链。本文将带您初步认识数据库,了解其基本概念、发展历程、主要职能及重要作用。
⚗️ 一.数据库

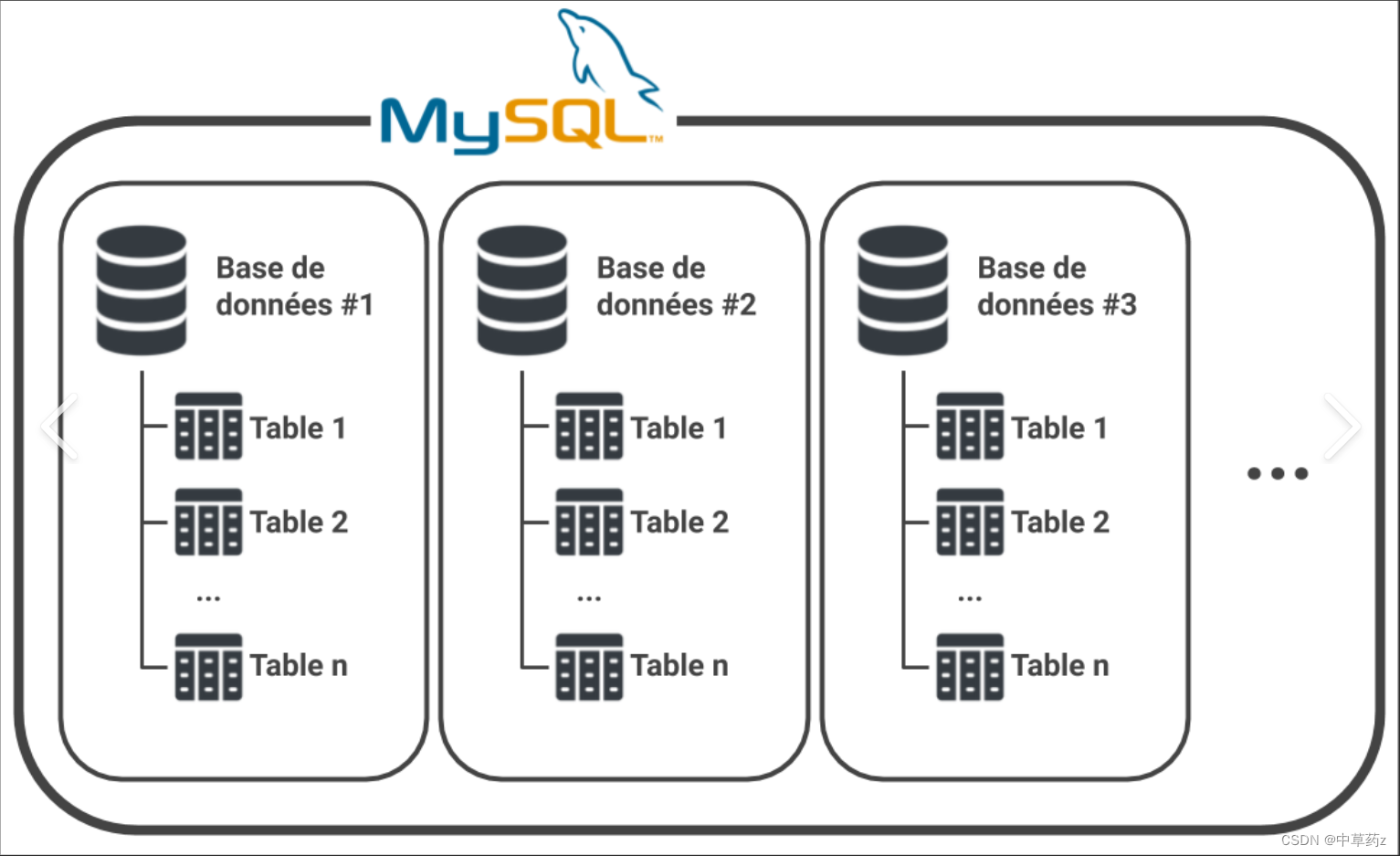
数据库(Database)是一种用于存储、管理和检索数据的系统,它允许用户以结构化方式组织、存储和检索大量信息。在数字时代,数据库是几乎所有软件应用和服务的基石,支撑着从简单的网站到复杂的业务系统和数据分析平台的数据管理需求。
🧪1.定义
数据库可以被形象地比喻为电子化的文件柜,但它远比传统文件管理更加高效和灵活。它不仅仅是一个存放数据的地方,更是一个包含了一系列规则、方法和程序的综合系统,用于确保数据的准确、安全、高效访问。

🧫2.特点
- 结构化: 数据库中的数据按照特定的结构(如表格、键值对等)组织,这有助于高效地存储和查询信息。
- 最小冗余度: 通过规范化等手段减少数据重复,确保每个数据元素只存储一次,提高存储效率和数据一致性。
- 数据独立性: 数据的存储方式与应用程序分离,这意味着数据结构的变化不会影响到应用程序的正常运行。
- 共享性: 多个用户或应用程序可以同时访问数据库中的数据,支持协同工作和资源共享。
- 安全性: 数据库管理系统(DBMS)提供访问控制、加密等手段,保护数据免受未经授权的访问和修改。
🧬3.数据库的组成部分
- 数据: 实际存储的信息。
- 数据库管理系统(DBMS): 负责创建、维护和管理数据库的软件,如MySQL、Oracle、SQL Server等。(我们学习的主体)
- 应用程序: 访问数据库并执行数据操作的前端软件。
- 数据库管理员: 负责设计、监控和维护数据库的专业人员。
🔬4.数据库的历史(了解)
以下内容为拓展内容,不感兴趣可以直接跳过
数据库技术的发展历程是信息技术领域一个充满创新和变革的领域,它伴随着计算机科学的进步和数据管理需求的不断增长而演变。下面是一段详尽的数据库历史概述:
早期数据管理(1950s-1960s)
在数据库技术正式诞生之前,数据主要通过手工或简单的文件系统管理。20世纪50年代,随着计算机的商业化应用,数据处理开始自动化,但仍然是以文件形式存储,缺乏统一的管理标准和数据共享能力。
层次与网状模型(1960s)
1960年代见证了数据库技术的初步形成。IBM的IMS(Information Management System)是最早的商业数据库系统之一,它采用了层次模型,数据以树状结构组织,适合展现一对多关系。几乎同时,CODASYL(Conference on Data Systems Languages)委员会提出了网状模型,数据间的关系更为灵活,可以有多对多的关系,但两者都存在数据冗余和复杂性的问题。
关系模型的诞生(1970s)
1970年,埃德加·科德(Edgar F. Codd)在论文《大型共享数据库数据的关系模型》中首次提出了关系模型,这是数据库技术史上的一个里程碑。关系模型基于集合论和关系代数,将数据视为表的集合,强调数据的独立性、结构化查询语言(SQL)的使用,以及数据的一致性和完整性。随后,Oracle、IBM的DB2和Ingres等关系型数据库系统相继问世,标志着关系数据库时代的到来。
关系型数据库的黄金时期(1980s-1990s)
1980年代至1990年代,随着个人电脑和企业计算的普及,关系型数据库系统迅速发展,成为行业标准。SQL成为查询数据库的标准语言,数据库管理系统(DBMS)的性能和功能得到显著增强,支持了更多复杂的应用场景,如事务处理、数据仓库等。

面向对象数据库(1990s)
随着面向对象编程的兴起,面向对象数据库(OODBMS)试图将面向对象的特性与数据库技术结合,支持复杂对象的存储和继承关系,但未能广泛替代关系型数据库,主要因为性能和兼容性问题。
NoSQL与大数据时代(2000s至今)
进入21世纪,互联网和移动设备的爆炸性增长带来了数据量的激增,传统关系型数据库在处理大规模、高并发、非结构化数据时面临挑战。因此,一系列非关系型数据库(NoSQL)应运而生,如MongoDB、Cassandra、HBase等,它们放弃了严格的表结构,提供了更灵活的数据模型,支持水平扩展,能够更好地适应大数据和实时分析的场景。
新兴趋势(2010s-至今)
- NewSQL:为了解决关系型数据库扩展性问题,NewSQL数据库如Google的Spanner、Amazon Aurora等出现,旨在结合关系数据库的ACID属性和NoSQL的可扩展性。
- 云数据库:随着云计算的普及,云数据库服务如AWS RDS、Azure SQL Database、Google Cloud SQL等提供托管的数据库解决方案,降低了运维成本,提高了灵活性。
- 多模态数据库:为了应对复杂的数据处理需求,一些数据库系统开始支持多种数据模型,如文档、图形、键值等,以满足不同类型的应用场景。
- AI集成数据库:近年来,数据库与人工智能技术的融合成为趋势,通过机器学习算法优化查询性能、自动管理和调优数据库等。
数据库技术的发展是一个持续演进的过程,随着技术的不断进步和社会需求的不断变化,未来数据库领域预计将继续涌现更多创新技术和应用。
🔭5.数据库的作用
- 存储和管理数据: 集中存储数据,减少数据混乱和丢失的风险。
- 数据访问和检索: 快速、准确地查找所需数据。
- 数据共享: 支持多用户同时访问,促进信息交流与合作。
- 数据安全与保护: 通过访问控制、备份与恢复等机制保障数据安全。
- 业务支持与决策辅助: 为企业提供运营数据支持,辅助决策制定。
- 数据分析与挖掘: 作为大数据分析的基石,支持复杂的数据处理和洞察发现。
总之,数据库是现代信息社会的基础设施之一,它使得数据能够被有效地组织、保护和利用,是推动技术创新和业务增长的关键因素。
📡二.认识MySQL
在当今这个数据驱动的时代,MySQL作为一款广泛使用的开源关系型数据库管理系统(RDBMS),在互联网应用、企业级系统以及大数据处理等多个领域扮演着至关重要的角色。本文将带领您深入了解MySQL的奥秘,从其起源、特点、核心优势,到应用场景及未来发展,全方位剖析这款数据库界的明星产品。

🍇1.起源与现状
MySQL的故事始于1995年,由Michael Widenius和David Axmark在瑞典共同开发。起初,它是为了解决两位创始人所在公司内部的数据库需求而诞生的。随着时间的推移,MySQL凭借其开源、免费、高性能和易用性,迅速在全球范围内获得了广泛的认可和应用。2008年,MySQL被Sun Microsystems收购,随后Sun又被甲骨文(Oracle)公司收购,但MySQL的开源精神一直得以延续。
🍈2.MySQL的核心特点
- 开源免费:MySQL遵循GPL协议,为用户提供了零成本获取和使用的可能性,这也是其迅速普及的重要原因之一。
- 高性能:MySQL经过不断优化,能够在高并发环境下提供稳定的性能表现,支持大规模数据存储和快速查询。
- 跨平台性:支持Windows、Linux、macOS等多种操作系统,便于在不同环境下的部署和迁移。
- 丰富的数据类型与存储引擎:MySQL支持多种数据类型,满足不同场景的需求;同时,通过选择不同的存储引擎(如InnoDB、MyISAM),用户可以根据应用场景优化性能。
- 安全性:提供强大的安全性特性,包括SSL连接、访问控制、数据加密等,确保数据的安全传输和存储。
- 强大的社区支持:MySQL拥有庞大的用户和开发者社区,这意味着丰富的资源、教程、第三方工具以及及时的技术支持。
🍉3.应用场景
MySQL几乎无处不在,从个人博客、中小企业网站到大型社交网络、电子商务平台、金融系统,甚至是大数据分析的基础设施,都能看到它的身影。其灵活性和可扩展性,使其成为Web应用开发的首选数据库。
🍊4.MySQL的未来展望
随着云计算和大数据技术的快速发展,MySQL也在不断地进化以适应新时代的需求。MySQL 8.x版本引入了诸多新特性,比如原生JSON支持、窗口函数、改进的安全性等,进一步提升了其竞争力。同时,MySQL在云原生环境下的部署和管理也得到了加强,如与Kubernetes的集成,使得MySQL在云环境下的部署更加灵活和高效。
🍋5.结语
MySQL作为一款久经考验的数据库系统,不仅在过去几十年里证明了自己的价值,而且在面对未来技术挑战时也展现出强大的适应性和创新能力。无论是对于初学者还是经验丰富的数据库管理员,深入学习和掌握MySQL都是一项值得投资的技能。随着技术的不断演进,MySQL无疑将继续在数据库领域发挥重要作用,为全球的数据管理和分析提供坚实的基础。
🍌三.基本操作
🍍1.环境搭建与配置
- 版本选择:基于性能优化考虑,推荐使用MySQL 5.5或5.6版本。虽然目前可能有更新版本,但这些版本在稳定性与性能之间提供了良好的平衡。
- 初始密码设置:安装MySQL后,首要任务是为root用户设置一个安全的初始密码,确保数据库的安全性。
🥭2.数据库操作
创建数据库
CREATE DATABASE [IF NOT EXISTS] db_name [create_specification [,
create_specification] ...]
create_specification:
[DEFAULT] CHARACTER SET charset_name
[DEFAULT] COLLATE collation_name- 大写的表示关键字
- [] 是可选项
- CHARACTER SET: 指定数据库采用的字符集
- COLLATE: 指定数据库字符集的校验规则
说明:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集: utf8 ,校验规则是:utf8_ general_ ci
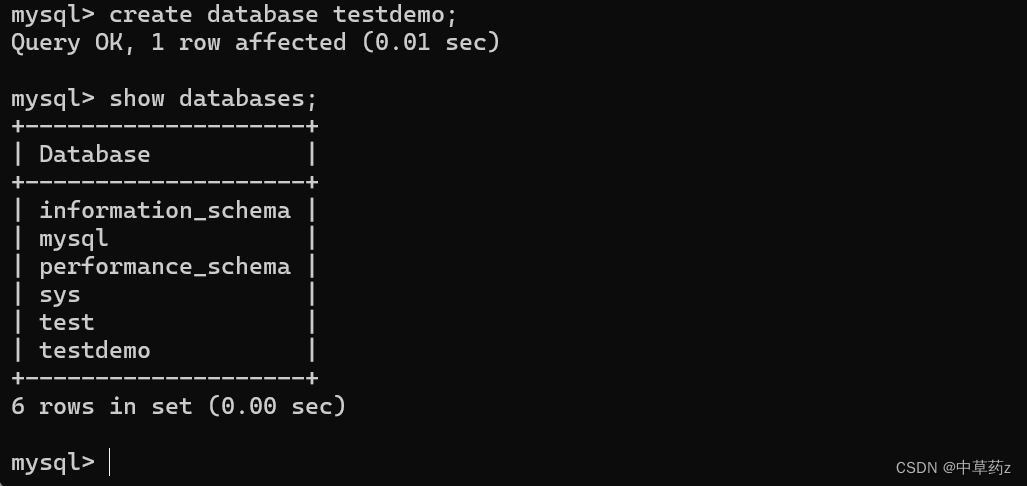
如果系统没有 db_test2 的数据库,则创建一个名叫 db_test2 的数据库,如果有则不创建
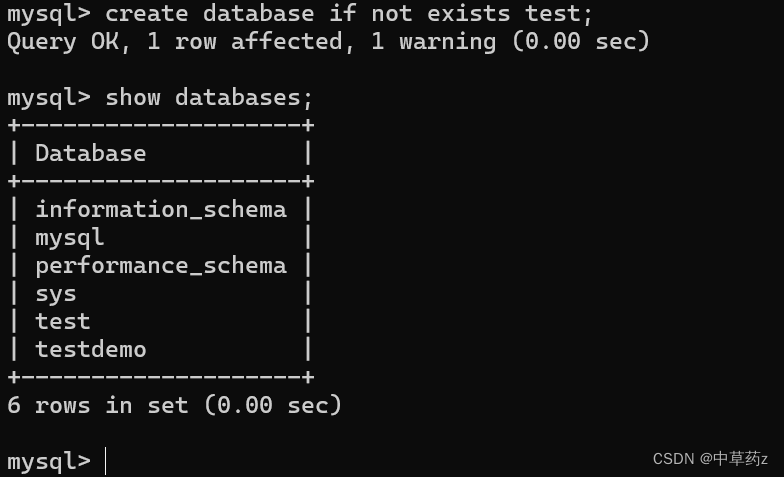
使用数据库
use 数据库名;显示数据库
show databases;删除数据库
DROP DATABASE [IF EXISTS] db_name;数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
🍎3.表的操作
需要操作数据库中的表时,需要先使用数据库
use db_test;查看表结构
desc 表名;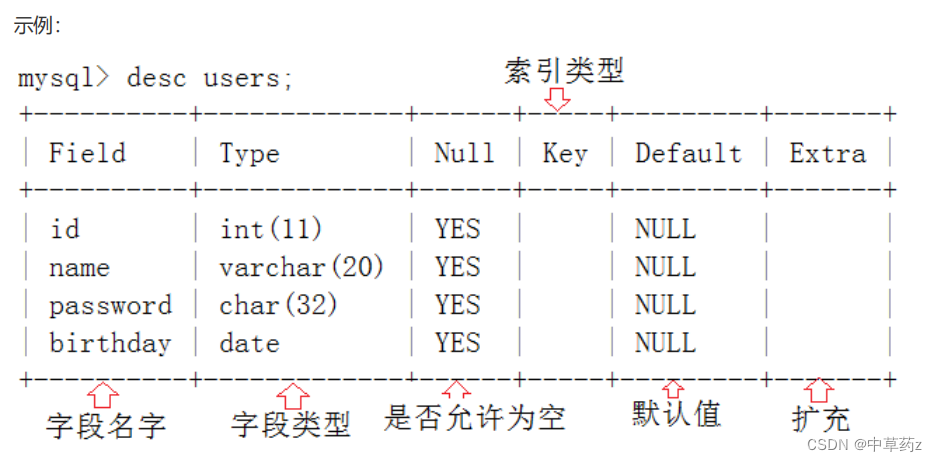
创建表
CREATE TABLE table_name (
field1 datatype,
field2 datatype,
field3 datatype
);create table stu_test (
id int,
name varchar(20) comment '姓名',
password varchar(50) comment '密码',
age int,
sex varchar(1),
birthday timestamp,
amout decimal(13,2),
resume text
);
删除表
DROP [TEMPORARY] TABLE [IF EXISTS] tbl_name [, tbl_name]……实例:
-- 删除 stu_test 表
drop table stu_test;
-- 如果存在 stu_test 表,则删除 stu_test 表
drop table if exists stu_test;🍒四.常用数据类型
🍓1.基本数据类型
| 数据类型 | 描述 | 存储大小 | 有符号范围 | 无符号范围 |
对应
java
类型
|
|---|---|---|---|---|---|
| TINYINT | 小整数 | 1字节 | -128 ~ 127 | 0 ~ 255 |
Byte
|
| SMALLINT | 短整数 | 2字节 | -32,768 ~ 32,767 | 0 ~ 65,535 |
Short
|
| MEDIUMINT | 中等整数 | 3字节 | -8,388,608 ~ 8,388,607 | 0 ~ 16,777,215 | - |
| INT或INTEGER | 整数 | 4字节 | -2,147,483,648 ~ 2,147,483,647 | 0 ~ 4,294,967,295 |
Integer
|
| BIGINT | 大整数 | 8字节 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | 0 ~ 18,446,744,073,709,551,615 |
Long
|
| FLOAT | 单精度浮点数 | 4字节 | 带小数点的数值,精度约7位 | 同有符号范围 |
Float
|
| DOUBLE | 双精度浮点数 | 8字节 | 带小数点的数值,精度约15位 | 同有符号范围 |
Double
|
| DECIMAL | 定点数 | 可变 | 用户定义的精度和小数位数 | 同用户定义 |
Big
Decimal
|
| CHAR | 固定长度字符串 | 1字节 * N | 最大255字节,不足时用空格填充 | - | Char |
数值类型可以指定为无符号(unsigned),表示不取负数。
尽量不使用 unsigned ,对于 int 类型可能存放不下的数据, int unsigned 同样可能存放不下,与其如此,还不如设计时,将int 类型提升为 bigint 类型。
🫐2.字符串类型
|
数据类型
|
大小
|
说明
|
对应
java
类型
|
|
VARCHAR (SIZE)
|
0-65,535
字节
|
可变长度字符串
| String |
|
TEXT
|
0-65,535
字节
|
长文本数据
| String |
|
MEDIUMTEXT
|
0-16 777 215
字节
|
中等长度文本数据
| String |
|
BLOB
|
0-65,535
字节
| 二进制形式的长文本数据 | byte[] |
🥝3.日期类型
|
数据类型
| 大小 | 说明 | 对应java类型 |
| DATATIME | 8字节 | 范围从1000到9999年,不会进行时区的检索及转换 |
java.util.Date
、
java.sql.Timestamp
|
| TIMESTAMP | 4字节 | 范围从1970到2038年,自动检索当前时区并进行转换 |
java.util.Date
、
java.sql.Timestamp
|
🍅五.总结与反思
不为圣贤,便为禽兽;不问收获,但问耕耘。——曾国藩
代码举例
-- 创建数据库
create database if not exists bit32mall
default character set utf8 ;
-- 选择数据库
use bit32mall;
-- 创建数据库表
-- 商品
create table if not exists goods
(
goods_id int comment '商品编号',
goods_name varchar(32) comment '商品名称',
unitprice int comment '单价,单位分',
category varchar(12) comment '商品分类',
provider varchar(64) comment '供应商名称'
);
-- 客户
create table if not exists customer
(
customer_id int comment '客户编号',
name varchar(32) comment '客户姓名',
address varchar(256) comment '客户地址',
email varchar(64) comment '电子邮箱',
sex bit comment '性别',
card_id varchar(18) comment '身份证'
);
-- 购买
create table if not exists purchase
(
order_id int comment '订单号',
customer_id int comment '客户编号',
goods_id int comment '商品编号',
nums int comment '购买数量'
);学习MySQL的基础操作过程中,我深入了解了数据库的核心概念和基本操作,包括表操作和基本数据类型。下面是我对所学内容的总结与反思:
基本操作
学习MySQL的基础操作,我首先了解了如何连接到MySQL数据库服务器,并掌握了使用命令行或图形化界面工具进行交互的方法。通过学习基本的SQL语句,我能够执行常见的数据库操作,如创建数据库、创建表、插入数据、更新数据和删除数据等。这些基本操作为我进一步深入学习数据库提供了坚实的基础。
表操作
表是数据库中存储数据的基本单位,学习MySQL时我学会了如何创建表、定义表的结构(列)、设置主键和外键等。此外,我还学习了如何使用ALTER TABLE语句对表进行修改,包括添加新列、删除列、修改列属性等。这些表操作使我能够灵活地设计和管理数据库结构,以适应不断变化的需求。
基本数据类型
MySQL支持多种基本数据类型,包括整数、浮点数、日期时间、字符串等。学习MySQL基础操作时,我深入了解了这些数据类型的特点和用法。掌握了正确的数据类型选择对于数据库的性能和数据完整性至关重要。因此,我努力理解每种数据类型的适用场景,以便在实际应用中进行合理的选择。
通过学习MySQL的基础操作,我对数据库的概念和原理有了更深入的理解,同时也提升了我的实际操作能力。我意识到数据库作为信息系统的核心,对于任何与数据相关的应用都至关重要。在未来的学习和工作中,我将继续深入学习数据库技术,并不断提升自己的数据库管理和优化能力,以应对日益复杂的数据管理需求。
学习MySQL不仅仅是学习一门技术,更是培养了我对数据的敏感性和处理数据的能力。我相信这些所学将在我的职业生涯中发挥重要作用,并为我未来的发展奠定坚实的基础。
🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀🍀
以上,就是本期的全部内容啦,若有错误疏忽希望各位大佬及时指出💐
制作不易,希望能对各位提供微小的帮助,可否留下你免费的赞呢🌸















 954
954

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









