






题目描述
小 K 喜欢翻看洛谷博客获取知识。每篇文章可能会有若干个(也有可能没有)参考文献的链接指向别的博客文章。小 K 求知欲旺盛,如果他看了某篇文章,那么他一定会去看这篇文章的参考文献(如果他之前已经看过这篇参考文献的话就不用再看它了)。
假设洛谷博客里面一共有 n(n≤105)n(n≤105) 篇文章(编号为 1 到 nn)以及 m(m≤106)m(m≤106) 条参考文献引用关系。目前小 K 已经打开了编号为 1 的一篇文章,请帮助小 K 设计一种方法,使小 K 可以不重复、不遗漏的看完所有他能看到的文章。
这边是已经整理好的参考文献关系图,其中,文献 X → Y 表示文章 X 有参考文献 Y。不保证编号为 1 的文章没有被其他文章引用。
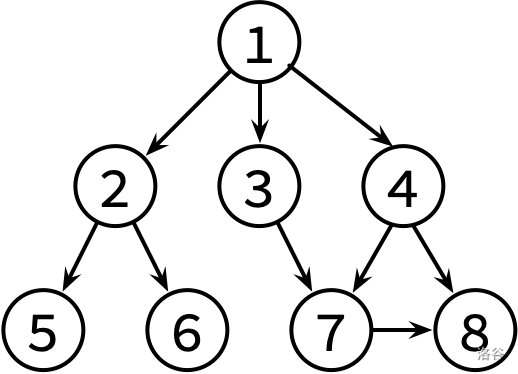
请对这个图分别进行 DFS 和 BFS,并输出遍历结果。如果有很多篇文章可以参阅,请先看编号较小的那篇(因此你可能需要先排序)。
输入格式
共 m+1m+1 行,第 1 行为 2 个数,nn 和 mm,分别表示一共有 n(n≤105)n(n≤105) 篇文章(编号为 1 到 nn)以及m(m≤106)m(m≤106) 条参考文献引用关系。
接下来 mm 行,每行有两个整数 X,YX,Y 表示文章 X 有参考文献 Y。
输出格式
共 2 行。 第一行为 DFS 遍历结果,第二行为 BFS 遍历结果。
输入输出样例
输入 #1复制
8 9 1 2 1 3 1 4 2 5 2 6 3 7 4 7 4 8 7 8
输出 #1复制
1 2 5 6 3 7 8 4 1 2 3 4 5 6 7 8
代码解答:
#include <bits/stdc++.h>
using namespace std;
const int MAX_NODES = 100005;
int nodeCount, edgeCount;
bool visited[MAX_NODES]; // 记录节点是否被访问过
vector<int> adjacencyList[MAX_NODES]; // 图的邻接表
// 深度优先搜索(DFS)函数
void depthFirstSearch(int currentNode, int remainingNodes) {
visited[currentNode] = true;
if (remainingNodes == 0) {
cout << currentNode << ' ';
return;
}
cout << currentNode << ' ';
for (int i = 0; i < adjacencyList[currentNode].size(); i++) {
int neighbor = adjacencyList[currentNode][i];
if (!visited[neighbor]) {
depthFirstSearch(neighbor, remainingNodes - 1);
}
}
}
// 广度优先搜索(BFS)函数
void breadthFirstSearch() {
queue<int> nodeQueue;
nodeQueue.push(1);
visited[1] = true;
while (!nodeQueue.empty()) {
int currentNode = nodeQueue.front();
nodeQueue.pop();
cout << currentNode << ' ';
for (int i = 0; i < adjacencyList[currentNode].size(); i++) {
int neighbor = adjacencyList[currentNode][i];
if (!visited[neighbor]) {
nodeQueue.push(neighbor);
visited[neighbor] = true;
}
}
}
}
int main() {
cin >> nodeCount >> edgeCount;
for (int i = 1; i <= edgeCount; i++) {
int node1, node2;
cin >> node1 >> node2;
adjacencyList[node1].push_back(node2);
}
// 对每个节点的邻接表进行排序
for (int i = 1; i <= nodeCount; i++) {
sort(adjacencyList[i].begin(), adjacencyList[i].end());
}
// 从节点 1 开始进行深度优先搜索
depthFirstSearch(1, nodeCount);
cout << endl;
// 重新初始化访问状态
fill(visited, visited + nodeCount + 1, false);
// 从节点 1 开始进行广度优先搜索
breadthFirstSearch();
return 0;
}代码解析 :
1.使用 vector 替代链表, vector 提供了更高效的随机访问和更简洁的内存管理。vector 支持动态调整大小,同时具有比链表更好的缓存局部性和较低的内存开销。这使得 vector 在处理邻接表时通常比链表更高效,尤其是在需要频繁访问和迭代的场景中。
2.fill(visited, visited + nodeCount + 1, false); 的主要目的是将 visited 数组中的所有元素设置为 false,从而重新初始化访问状态。这是图遍历算法中常见的一步,确保每次遍历时都从一个干净的状态开始。
头文件说明:
这段代码中包含了以下头文件:
<bits/stdc++.h> - 这是一个通用的头文件,包含了 C++ 标准库中的所有常用头文件(在实际使用中不推荐,因为它会增加编译时间和可能的依赖冲突)。
此段代码所用的头文件:
<iostream>- 用于输入输出流。<vector>- 用于 STL 的动态数组。<queue>- 用于 STL 的队列。<algorithm>- 用于 STL 的排序函数sort。
















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











