







第二章 大型语言模型微调技术
2.1 有监督微调(Supervised Fine-Tuning, SFT)
核心定义
有监督微调(Supervised Fine-Tuning, SFT)是一种基于标注数据对预训练语言模型进行二次训练的技术。其本质是将通用语言模型适配到具体任务中,如同医生通过专科培训获得特定领域的诊疗能力。
数学形式化表达:
给定预训练模型参数
θ
p
r
e
\theta_{pre}
θpre,SFT目标是通过标注数据集
D
=
{
(
x
i
,
y
i
)
}
i
=
1
N
\mathcal{D} = \{(x_i, y_i)\}_{i=1}^N
D={(xi,yi)}i=1N,学习新参数
θ
s
f
t
\theta_{sft}
θsft使得:
θ
s
f
t
=
arg
min
θ
∑
i
=
1
N
L
(
f
θ
(
x
i
)
,
y
i
)
+
λ
Ω
(
θ
)
\theta_{sft} = \arg\min_{\theta} \sum_{i=1}^N \mathcal{L}(f_{\theta}(x_i), y_i) + \lambda \Omega(\theta)
θsft=argθmini=1∑NL(fθ(xi),yi)+λΩ(θ)
其中
L
\mathcal{L}
L为损失函数(如交叉熵),
Ω
\Omega
Ω为正则化项,
λ
\lambda
λ控制正则化强度。
2.1.1 SFT的基本概念
SFT(Supervised Fine-Tuning)监督微调是指在源数据集上预训练一个神经网络模型,即源模型。然后创建一个新的神经网络模型,即目标模型。目标模型复制了源模型上除了输出层外的所有模型设计及其参数。这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。
为了让大家更直观地理解有监督微调(SFT),可以用“装修房子”来类比。预训练模型就像开发商建造的毛坯房,通过海量无标签数据“通用材料”搭建起基本框架,赋予模型基础的通用语言理解能力。而监督微调则是房主根据自身需求,比如要打造一个适合烹饪的空间,使用标注数据作为“定制家具”,对模型参数(厨房)进行改造,让模型能够完成像生成医疗报告这样的特定任务。这种方式高效又低成本,就好比装修房子时无需重建地基,只调整墙面颜色、更换局部设施(微调顶层网络),在保留预训练参数核心优势的同时,大幅节省了时间和资源。
以BERT举例, BERT模型是Google AI 研究院提出的一种与训练模型,通过预训练+微调的方式用于多个NLP下游任务,达到了当时的最先进水平,如实体识别、文本匹配、阅读理解等。BERT模型微调时,将预训练好的模型参数复制到微调模型,而输出层参数随机初始化
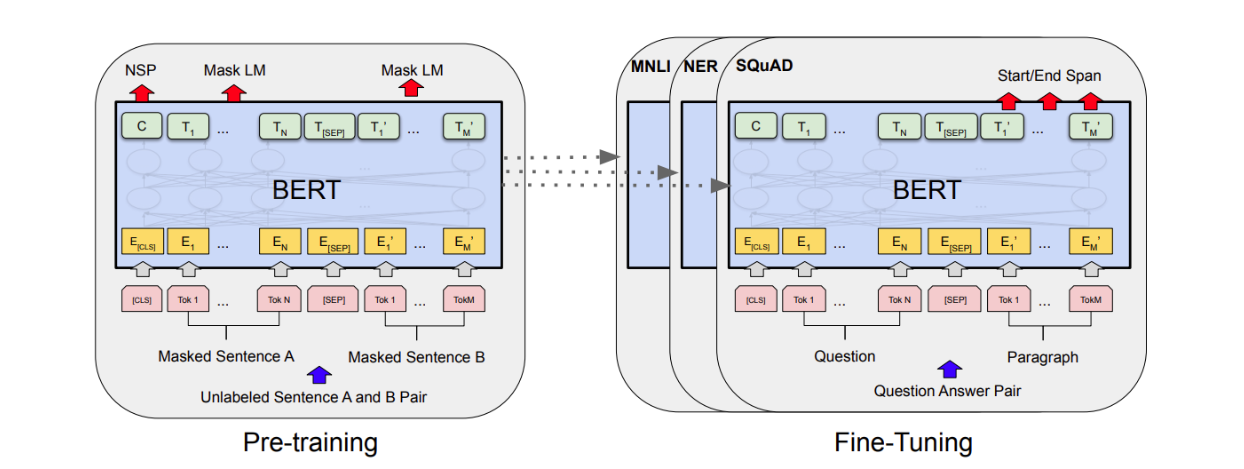
微调时,为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。在目标数据集上训练目标模型时,将从头训练到输出层,其余层的参数都基于源模型的参数微调得到。
2.1.2 SFT的步骤
1. 数据收集与预处理
-
构建指令数据集
收集多样化的用户指令(如问题、任务描述)及对应的优质回复,形成“指令-回复”对。
示例:{ "instruction": "用简洁语言解释量子力学", "output": "量子力学是描述微观粒子行为的物理理论,其核心包括波粒二象性、不确定性原理和量子纠缠等概念..." } -
数据清洗与标准化
- 去除噪声数据(如乱码、重复内容)。
- 统一格式(如回复长度、语言风格)。
- 标注特殊指令类型(如摘要、翻译、创意写作)。
2. 模型选择与初始化
-
选择基础模型
基于任务需求选择预训练模型(如Llama 2、GPT-3.5),模型规模需平衡性能与成本。 -
冻结部分参数(可选)
对于超大规模模型,可冻结底层参数以减少计算量,仅微调上层几层。
示例(Python伪代码):from transformers import AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("llama-7b") # 冻结前60层,仅微调后10层 for param in model.parameters()[:60]: param.requires_grad = False
3. 评估与优化
使用目标任务的测试集对微调后的模型进行评估,得到模型在目标任务上的性能指标。
-
内部评估指标
- 困惑度(Perplexity):衡量模型对验证集的预测能力。
- 准确率(Accuracy):分类任务中预测正确的比例。
- BLEU/METEOR:生成任务中与参考回复的相似度。
-
人工评估
邀请人类标注者对模型输出进行评分,评估维度包括:- 指令遵循度:是否完全回答问题?
- 内容质量:是否准确、连贯、无矛盾?
- 安全性:是否包含有害信息或偏见?
2.1.3 核心问题与解决思路
要解决的问题:
预训练语言模型虽然具备强大语言理解能力,但难以直接适配具体应用场景(如客服问答、医疗咨询等)。就像刚毕业的学生需要岗前培训才能胜任具体工作一样,模型需要通过微调学习特定任务的输入输出模式。
方法思路:
使用人工标注的"指令+输出"数据集对模型进行二次训练,使其学会遵循特定格式完成任务。例如:
- 单轮对话:用户问"北京有多少人口?“,要求模型输出"截至2023年,北京常住人口约2154万”
- 多轮对话:用户连续提问时,要求模型保持上下文一致性(如先问"推荐旅游景点",再问"这些地方有什么美食")
方法分类:
- 单轮对话微调:针对独立问答场景(如知识问答)
- 多轮对话微调:针对持续交互场景(如客服对话)
2.1.4 单轮对话微调实例
典型场景:
电商客服机器人需要根据用户问题自动生成标准答案。例如:
输入:退货流程是什么?
标签输出:请登录APP→我的订单→选择商品→申请退货→等待审核
数据集构建示例:
{
"instruction": "请将以下英文翻译成中文",
"input": "Artificial Intelligence is transforming the world.",
"output": "人工智能正在改变世界。"
}
2.1.5 多轮对话微调实例
典型场景:
医疗问诊助手需维持多轮对话逻辑。例如:
用户:我最近头痛严重
模型:请问持续多久了?伴随其他症状吗?
用户:大概一周,有时恶心
模型:建议尽快就医,可能需要做脑部CT检查
关键技术:
- 对话状态追踪(Dialogue State Tracking)
- 注意力机制优化:增强对历史对话的上下文记忆
数据集构建示例:
{
"history": [
["用户:推荐几部科幻电影", "助手:《星际穿越》《阿凡达》《银翼杀手2049》"],
["用户:这些电影的导演是谁?", "助手:诺兰、卡梅隆、维伦纽瓦"]
],
"new_input": "他们的获奖情况如何?",
"output": "《星际穿越》获奥斯卡最佳视觉效果奖,《阿凡达》获最佳摄影..."
}
训练过程:
- 构建包含10万条"问题-答案"对的数据集
- 冻结底层参数,仅微调顶层适配层
- 使用交叉熵损失函数:
L = − ∑ t = 1 T log P θ ( y t ∣ y < t , x ) \mathcal{L} = -\sum_{t=1}^{T} \log P_{\theta}(y_t | y_{<t}, x) L=−t=1∑TlogPθ(yt∣y<t,x)
其中 x x x为输入, y y y为目标输出
2.2 高效微调方法(Parameter-Efficient Fine-Tuning, PEFT)
2.2.1 技术演进背景
一、传统微调的困境
在深度学习模型微调的场景中,尤其是对于像大型语言模型这样参数规模巨大的模型,传统的全量微调方法存在诸多问题。
首先是计算资源的高消耗,以一个具有数十亿甚至上百亿参数的模型为例,对其进行全量微调时,需要大量的GPU内存来存储和更新参数,这不仅要求计算机具备强大的硬件配置,还会带来高昂的计算成本。
其次,在很多实际应用场景中,我们可能只需要模型在特定任务上进行适应性调整,并不需要对所有参数进行更新,全量微调在这种情况下显得过于冗余。
传统全参数微调面临两大挑战: 1. 计算资源消耗大(如微调70亿参数模型需数TB显存)2. 多任务部署困难(每个任务需保存完整模型副本)
二、解决方案
在大语言模型微调过程中,为减少计算资源消耗并提升特定任务表现,出现了多种高效微调方法:
LoRA 通过引入低秩矩阵分解,仅调整不到 0.1% 的参数,就能优化模型;Adapter 则是在模型特定层插入小型神经网络模块,参数占比 1 - 3%,便于灵活切换任务;Prefix Tuning 是在输入序列前添加可学习的前缀向量,以约 0.5% 的参数占比,引导模型生成特定任务输出。
主流方法对比:
| 方法 | 核心思想 | 参数占比 |
|---|---|---|
| LoRA | 引入低秩矩阵分解 | <0.1% |
| Adapter | 插入小型神经网络模块 | 1-3% |
| Prefix Tuning | 添加可学习前缀向量 | 0.5% |
2.2.2 LoRA(Low-Rank Adaptation)
一、LoRA的基本思想
LoRA(Low - Rank Adaptation,低秩自适应)的出现,就是为了解决上述传统微调的问题。其核心思想是在不改变预训练模型原有参数的前提下,通过引入低秩矩阵来对模型进行微调。具体来说,LoRA在模型的某些关键层(例如注意力机制中的权重矩阵)上添加了可训练的低秩矩阵。这些低秩矩阵的参数数量相对整个模型的参数数量极少,但却能够有效地捕捉特定任务的特征,从而实现对模型的高效微调。
我们可以把预训练模型看作是一个已经具备了丰富通用知识的“大脑”,而LoRA就像是给这个“大脑”戴上一副特殊的“眼镜”,这副“眼镜”能够让模型在处理特定任务时,以一种更聚焦的方式去看待问题,而不需要对整个“大脑”的知识体系进行大规模调整。
二、LoRA技术原理
假设模型权重变化具有低秩特性,在原始权重矩阵间插入低秩矩阵:
W
′
=
W
+
Δ
W
=
W
+
A
⋅
B
W' = W + \Delta W = W + A \cdot B
W′=W+ΔW=W+A⋅B
其中
A
∈
R
d
×
r
,
B
∈
R
r
×
d
A \in \mathbb{R}^{d \times r}, B \in \mathbb{R}^{r \times d}
A∈Rd×r,B∈Rr×d,秩
r
≪
d
r \ll d
r≪d
如图:
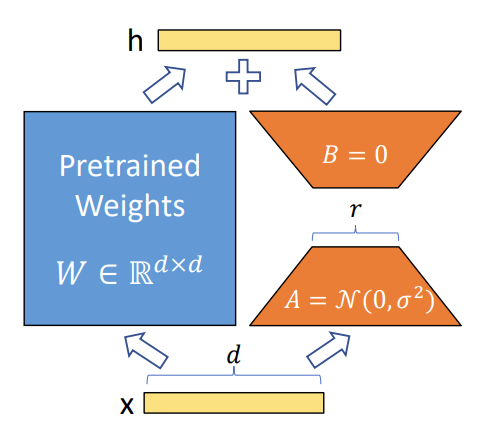
实现步骤:
- 冻结原始模型参数 W W W
- 随机初始化低秩矩阵 A , B A,B A,B
- 仅训练 A , B A,B A,B参数(通常 r = 64 r=64 r=64时新增参数仅占0.08%)
三、LoRA的优势
- 计算资源高效:由于LoRA只需要训练少量的低秩矩阵参数,相比于全量微调,其所需的计算资源大幅降低。在实际应用中,可能只需要原来几十分之一甚至几百分之一的计算资源就能完成模型的微调任务。例如,在微调一个7B参数的语言模型时,使用LoRA可能只需要训练不到1M的参数,大大减少了训练时间和内存占用。
- 灵活性高:LoRA可以方便地应用于不同类型的模型架构,无论是Transformer架构的语言模型,还是其他深度学习模型。而且,在不同的任务之间切换时,只需要保存和加载不同的低秩矩阵参数即可,不需要重新训练整个模型。
- 可扩展性强:可以将多个LoRA模块应用于模型的不同层,以适应更复杂的任务需求。同时,LoRA还可以与其他微调技术相结合,进一步提升模型的性能。
四、LoRA的应用案例
- 机器翻译:在多语言模型中,为每种语言单独训练LoRA模块
- 医疗领域适配:使用LoRA微调通用模型的医学术语理解能力
五、LoRA面临的挑战与未来发展
尽管LoRA在提高模型微调效率方面取得了显著成效,但也面临一些挑战。例如,在某些复杂任务中,低秩近似可能无法完全捕捉到任务所需的全部信息,导致模型性能受限。未来,研究人员可能会探索更优化的低秩矩阵结构,或者结合其他先进的技术来进一步提升LoRA的性能。同时,随着模型规模的不断增大和应用场景的日益复杂,如何更好地将LoRA与其他微调方法融合,以实现更高效、更精准的模型微调,也是一个值得深入研究的方向。
2.2.3 Adapter Tuning
一·、Adapter Tuning的基本思想
2019年,Houlsby N等人将Adapter引入NLP领域,作为全模型微调的一种替代方案。
Adapter Tuning 是一种参数高效的迁移学习方法。其基本思想是在预训练语言模型(PLM)基础上,在 Transformer 模型的每个层(或特定层)中增加额外的、紧凑且可扩展的 Adapter 模块 。Adapter 模块由降维和升维的前馈网络两个子层构成,通过控制中间维度大小限制参数量。训练时,固定原始预训练模型参数,仅对新增的 Adapter 结构进行微调 。这样,用少量可训练参数就能达到与全量参数微调相近的效果,还能为新任务添加新的 Adapter 模块,且无需重新访问以前的任务,实现了高度的参数共享。
二、Adapter的主体架构
Adapter主体架构下图所示。
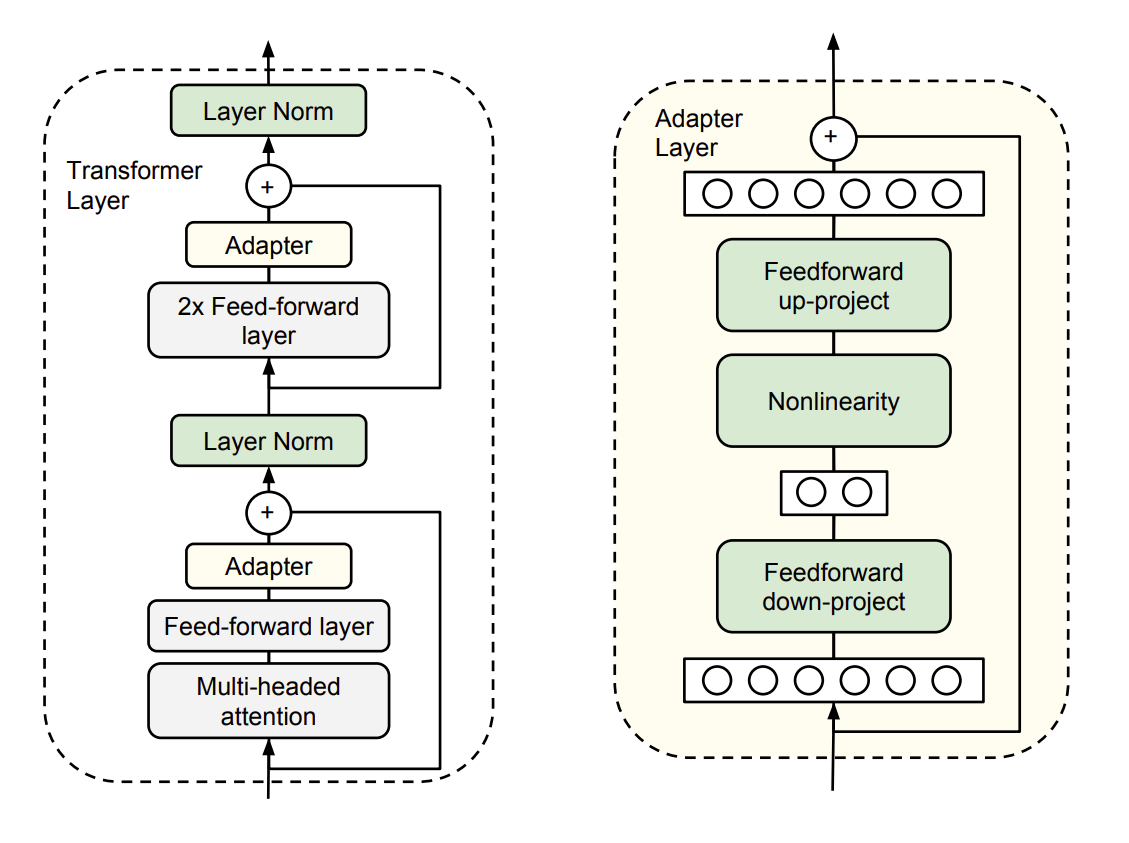
左图展示了在Transformer层中,Adapter模块分两处添加,一处在多头注意力后的前馈层之后,另一处在两个前馈层之后,可分别对不同阶段的特征进行特定任务优化。右图呈现了Adapter层内部结构,它由前馈降维层、非线性变换层、前馈升维层组成瓶颈结构,参数量少,还有跳跃连接融合原始特征,在调优时与层归一化参数、分类层一同训练,让模型能高效适配特定任务。
三、adapter的实现方式
在Transformer层中插入小型全连接网络:
class Adapter(nn.Module):
def __init__(self, dim=768, bottleneck=64):
self.down_proj = nn.Linear(dim, bottleneck)
self.up_proj = nn.Linear(bottleneck, dim)
def forward(self, x):
return x + self.up_proj(GELU(self.down_proj(x)))
四、Adapter Tuning的优势
部署优势:
- 移动端应用:新增参数仅增加0.5MB存储需求
- 多任务切换:通过替换Adapter模块实现快速任务切换
性能对比:
在GLUE基准测试中,Adapter仅使用3%额外参数即可达到全量微调98%的效果。
2.2.4 Prefix Tuning
Prefix Tuning 是一种专为生成式语言模型设计的参数高效微调技术,通过优化输入序列前的**可训练前缀(Prefix)**来引导模型生成特定任务的输出,而无需调整预训练模型的主体参数。其核心思想与实现方式如下:
一、Prefix Tuning的核心原理
Prefix Tuning 的核心思想是将任务指令编码为连续的向量序列(前缀),作为输入的一部分与原始文本共同参与模型计算。这些前缀向量在训练过程中通过反向传播优化,本质上是一种“软提示”(Soft Prompt)机制。如图:
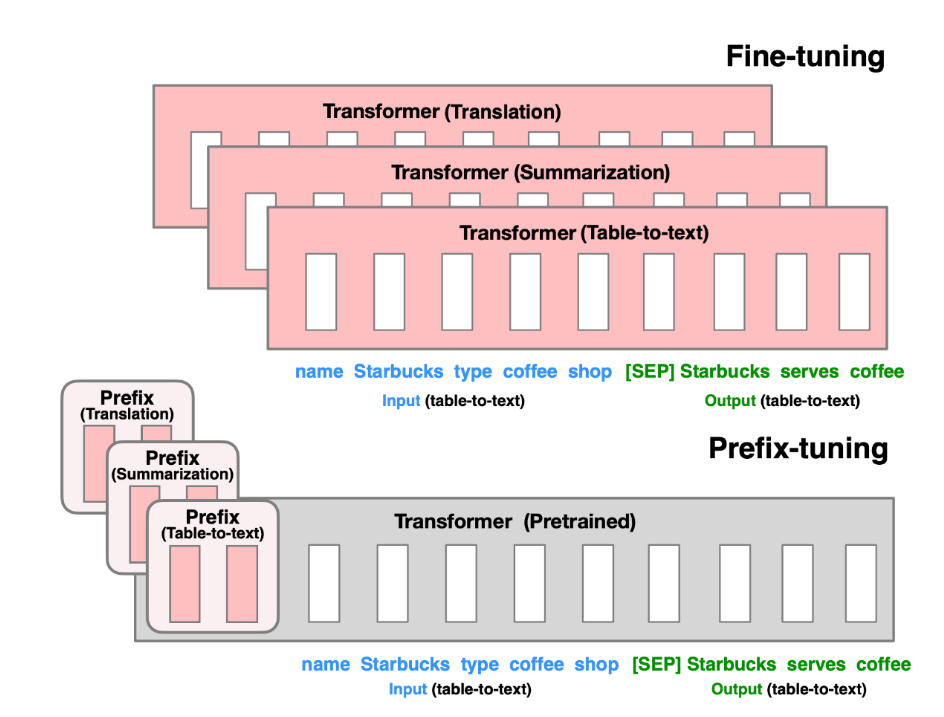
- Fine-tuning(微调):更新模型的所有参数(红色的Transformer块),需要为每个任务存储整个模型。
- Prefix-tuning(前缀微调):冻结模型参数,仅优化前缀(红色的前缀块),只需为每个任务存储前缀参数。
因此可以看到,相比于Fine-tuning,Prefix-tuning的优势在于:
-
前缀作为“软提示”(Soft Prompt)
在输入文本前添加一段连续的可训练向量(即 Prefix),这些向量作为模型的“提示信息”,引导模型生成符合任务需求的内容。- 示例:在机器翻译任务中,Prefix 可编码“将英语翻译成中文”的指令,使模型在生成时更倾向于输出翻译结果。
-
冻结主体,仅训练前缀
预训练模型的所有参数保持不变,仅优化 Prefix 的参数(通常占全模型参数的 0.1%–1%)。- 优势:大幅降低计算成本,支持快速任务切换(不同任务只需切换 Prefix)。
-
跨层共享与特定层设计
Prefix 可设计为:- 全局共享:所有层使用相同的前缀向量。
- 层特定:不同 Transformer 层使用独立前缀,捕获更细粒度的任务信息。
二、Prefix Tuning的技术实现
Prefix Tuning 的具体实现包括以下关键环节:
-
Prefix 结构设计
- 连续向量:通常为固定长度的向量序列,可通过随机初始化后训练得到。
- 任务编码:Prefix 需包含任务类型、领域知识等信息,例如在问答任务中,Prefix 可编码问题类型(如事实类、观点类)。
-
与模型的交互方式
- 在自回归生成过程中,Prefix 作为输入的一部分参与计算,影响注意力机制的权重分配。
- 例如,在 GPT 系列模型中,Prefix 会被插入到输入序列的起始位置,与文本 tokens 共同参与生成。
-
优化目标
通过最大化特定任务的生成概率来训练 Prefix,例如在文本摘要任务中,优化前缀使模型生成更符合原文核心的摘要内容。
三、Prefix Tuning的优势与应用场景
| 优势 | 应用场景 |
|---|---|
| 极低参数开销 | 资源受限环境(如边缘设备)下的任务适配,仅需存储和更新小规模的 Prefix 参数。 |
| 快速任务切换 | 多任务系统中,通过切换 Prefix 支持不同任务(如翻译、问答、生成),无需重新训练。 |
| 避免灾难性遗忘 | 保留预训练模型的通用能力,适用于持续学习场景(如不断添加新任务)。 |
| 可解释性与可控性 | 通过设计特定的 Prefix,可引导模型生成符合特定风格或内容约束的文本。 |
四、Prefix Tuning与其他微调方法的对比
| 方法 | 可训练参数 | 任务切换成本 | 预训练知识保留 |
|---|---|---|---|
| 全量微调 | 100% 模型参数 | 高(需重新训练) | 可能丢失 |
| Adapter | 1%–3% 额外参数 | 低(切换 Adapter) | 保留 |
| LoRA | <0.1% 额外参数 | 低(切换 LoRA) | 保留 |
| Prefix Tuning | <0.1% 前缀参数 | 极低(切换 Prefix) | 保留 |
五、Prefix Tuning的局限性与改进方向
- 长文本任务挑战:Prefix 长度有限,对复杂任务的编码能力可能不足,需探索更长或结构化的前缀设计。
- 与离散提示的结合:将可训练前缀与人工设计的离散提示(如模板)结合,提升灵活性与可控性。
Prefix Tuning 通过“提示工程+参数高效优化”的思路,为生成式模型在多任务、低资源场景下的应用提供了轻量化解决方案,尤其适用于需快速部署和切换任务的生产环境。
方法选择指南
- LoRA:适合大规模模型+多任务场景(如千人千面推荐系统)
- Adapter:适合资源受限设备(如智能手表上的语音助手)
- Prefix Tuning:适合需要强上下文控制的任务(如代码生成)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









