






一:认识Hadoop
1:基本介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,它允许用户在不了解分布式底层细节的情况下,开发分布式程序,并充分利用集群的威力进行高速运算和存储。Hadoop起源于Apache Nutch项目,该项目是Apache Lucene的子项目之一。Hadoop的命名来源于其创始人Doug Cutting儿子的玩具大象。
2:优点及用途
Hadoop的优点包括高可靠性、高扩展性、高效性、高容错性和低成本。Hadoop还具有高可扩展性,可以方便地将数据计算任务分配到更多的计算机上进行处理。此外,Hadoop还具有低成本的特点,因为它依赖于社区服务,使得任何人都可以使用。
Hadoop的用途非常广泛,包括数据清洗、ETL和批处理分析等任务,大数据存储,实时数据处理,数据仓库和商业智能,日志和事件处理,机器学习和人工智能,以及图计算等。
3:需要安装VMware Workstation 17 Player并配置虚拟机及克隆并用到MobaXterm
1:查看ip地址的起始和结束地址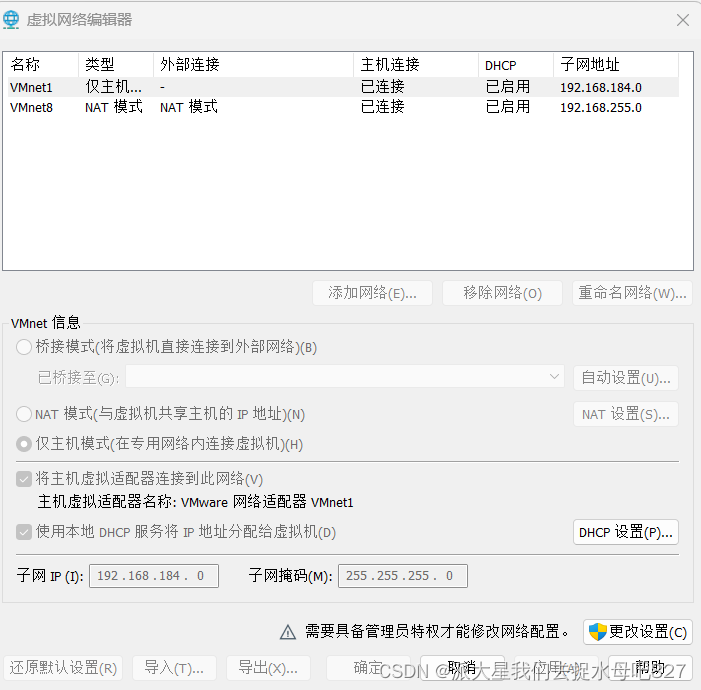
2:修改网络配置文件
①vi /etc/sysconfig/network-scripts/ifcfg-ens33mac地址为2步骤的enter值
ip地址参照4步骤自行选择(必须在起始和结束的范围内)
子网掩码默认设置为255.255.255.0
网关的值为将ip地址中最后一段的值改为2
DNS使用谷歌提供的免费dns1:8.8.8.8

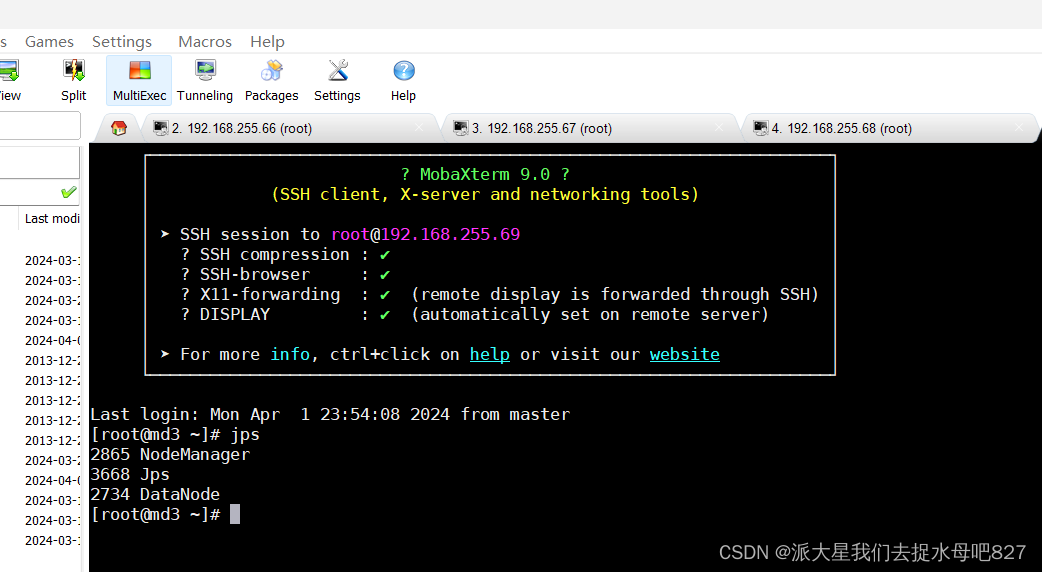
二:设置SSH无密码登录节点
执行命令在本机生成公钥、私钥和验证文件
ssh-keygen -t rsa执行命令将登录信息复制到验证文件
ssh-copy-id md1 # master为主机名
ssh-copy-id md2 # master为主机名
ssh-copy-id md3 # master为主机名
注:这里免密登录配置和上面一样,虚拟机相互之间都要执行ssh-copy-id这个命令
————————————————
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
原文链接:https://blog.csdn.net/JunLeon/article/details/120505585
三集群搭建和配置
1:分布式集群的网络和节点规划
| 主机名 | ip地主 | 节点类型 |
| master | 192.168.255.66 | master |
| md1 | 192.168.255.67 | md1 |
| md2 | 192.168.255.68 | md2 |
| md3 | 192.168.255.69 | md3 |
2:节点规划
| 服务 | master | md1 | md2 | md3 |
| jps | * | * | * | * |
| Secondary NameNode | * | |||
| NodeManager | * | * | * | |
| DataNode | * | * | * | * |
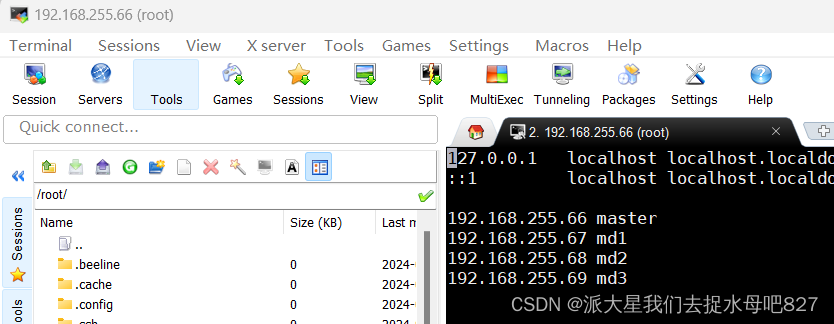
3:设置主机名和IP的映射
使用:vi /etc/hostsj进入/etc/hosts文件编辑,如下图
4:防火墙
systemctl status firewalld #查看防火墙状态(active(running)表示防火墙在启动状态)
systemctl stop firewalld #关闭防火墙 (inactive(dead)表示已经关闭防火墙了)
systemctl is-enabled firewalld #查看防火墙是否开机自启(enabled:表示开机自启;disabled:表示开机不自启)
三:Hadoop配置
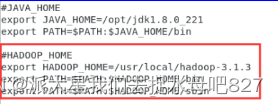
1:安装Java和hadoop并配置环境变量
安装好就要配置/my_env.sh
java的;在/etc/profile.d下创建一个my_env.sh,进行配置JAVA环境变量,命令:vi /etc/profile.d/my_env.sh;同理Hadoop也是一样
Java

Hadoop:
2:配置分布式集群环境
环境变量配置文件:hadoop-env.sh、yarn-env.sh、mapred-env.sh
全局核心配置文件:core-site.xml
HDFS配置文件:hdfs-site.xml
YARN配置文件:yarn-site.xml
1:vi etc/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/log/hadoop/tmp</value>
</property>
</configuration>2:vi /hadoop-env.sh进入文件添加以下部分export JAVA_HOME=/opt/jdk1.8.0_221,修改yarn-env.sh文件,在底部添加以下部分export JAVA_HOME=/opt/jdk1.8.0_221
3:vi /mapred-site.xml进入文件,添加以下代码
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>4:vi /yarn-site.xml进入文件添加
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/hadoop/yarn/local</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data/tmp/logs</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http:///master:19888/jobhistory/logs</value>
<description>URL for job history server</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>5:vi /workers文件
改成以下部分(这里不添加master节点,因此后面启动时候master没有datanote,其他3个子节点会有datanote)
md1
md2
md3
6:vi /hdfs-site.xml文件,添加以下代码
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>注意:1-6点进入的文件都在/usr/local/hadoop-3.1.3/etc/hadoop/路径下进入修改
7:/usr/local/hadoop-3.1.3/sbin/下进入以下文件修改并添加代码
|
vi /start-dfs.sh |
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root |
|
vi /stop-dfs.sh |
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root |
|
vi /start-yarn.sh |
注意:在文件开头添加以下部分 YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root |
|
vi /stop-yarn.sh |
注意:在文件开头添加以下部分 YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root |
四:配置时间同步服务
1:查看
版本命令:ntpq -c version;没有则安装命令为:yum install -y ntp
2:修改master,md1、md2、md3里的vi /etc/ntp.conf文件,用#注释掉server行,并添加以下代码:
restrict 192.168.0.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 103:在mster、md1、md2、md3里使用以下命令
systemctl start ntpd、systemctl enable ntpd启动服务、systemctl status ntpd查看服务状态
4:在md1、md2、md3里使用以下命令
使用命令ntpdate master同步时间
五:启动和关闭Hadoop集群
1:启动集群
进入Hadoop安装目录:cd $HADOOP_HOME
| start-all.sh |
开启所用HDFS,不包含日志,要在单独开一次日志 |
|
sbin/start-dfs.sh |
开启HDFS |
|
sbin/start-yarn.sh |
开启yarn |
| mapred --daemon start historyserver | 开启日志 |
2:关闭集群
进入cd $HADOOP_HOME关闭集群命令
| stop-all.sh | 关闭所用HDFS,不包含日志,要在单独关一次日志 |
|
sbin/stop-yarn.sh | 关闭HDFS |
|
sbin/stop-dfs.sh | 关闭yarn |
|
mapred --daemon stop historyserver | 关闭日志 |















 437
437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









