






目录
6.利用xpath进行解析获取top250电影名称name_list与详情页链接url_list
一、效果展示

二、爬取过程
1.运用工具
1.python3.10
2.requests
3.xpath
2.代码撰写
1.导入所需模块
import requests from lxml import etree import pandas as pd
2.获取网址
url='https://movie.douban.com/top250'
3.进行UA伪装
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}
获取方式:
(1)网页界面单击鼠标右键
(2)选择“检查”
(3)选择“Network”
(4)按住F5进行刷新
(6)选择如图所示第一项
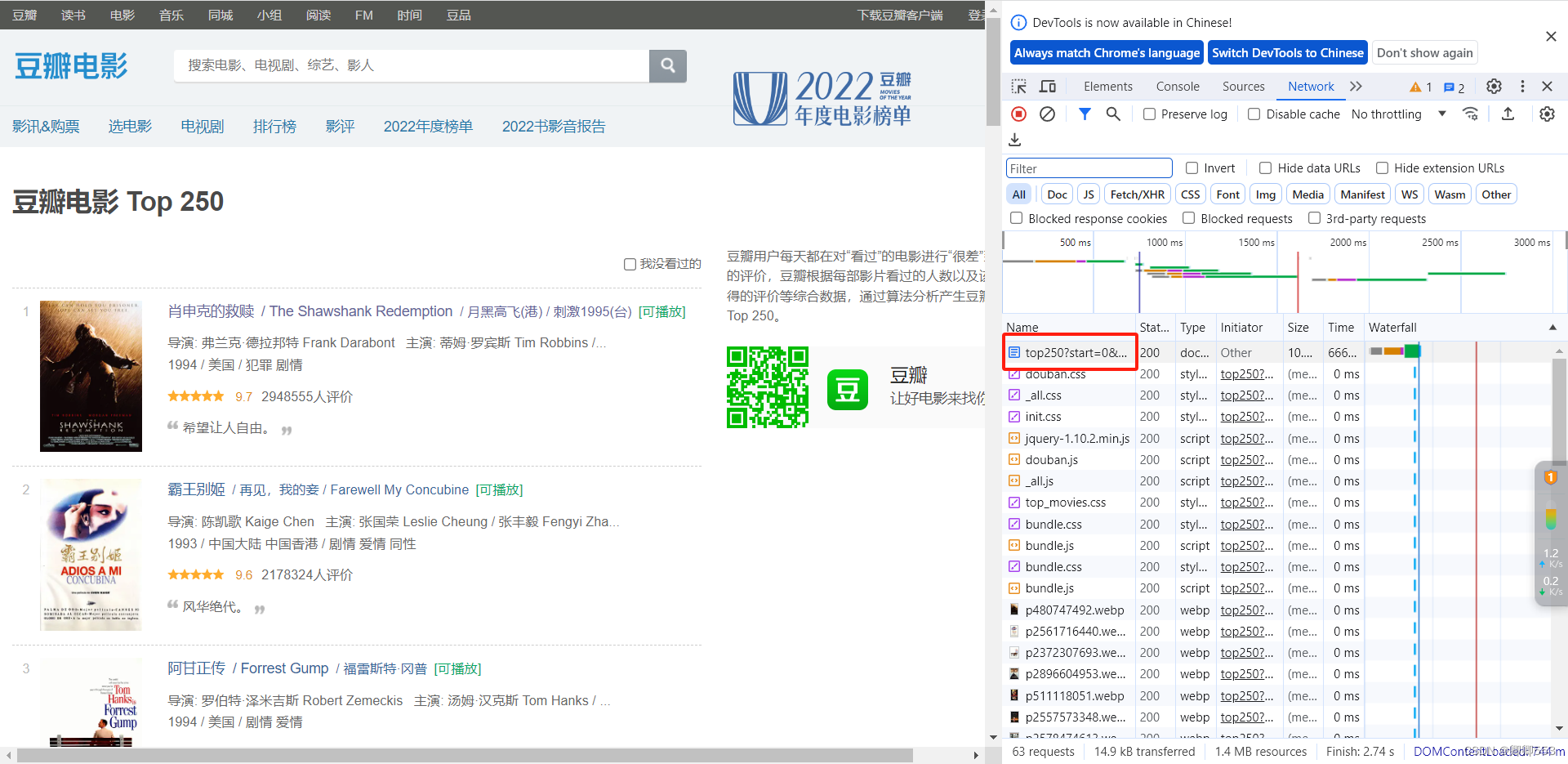
(7)划到最底部,复制粘贴如图最后一项即可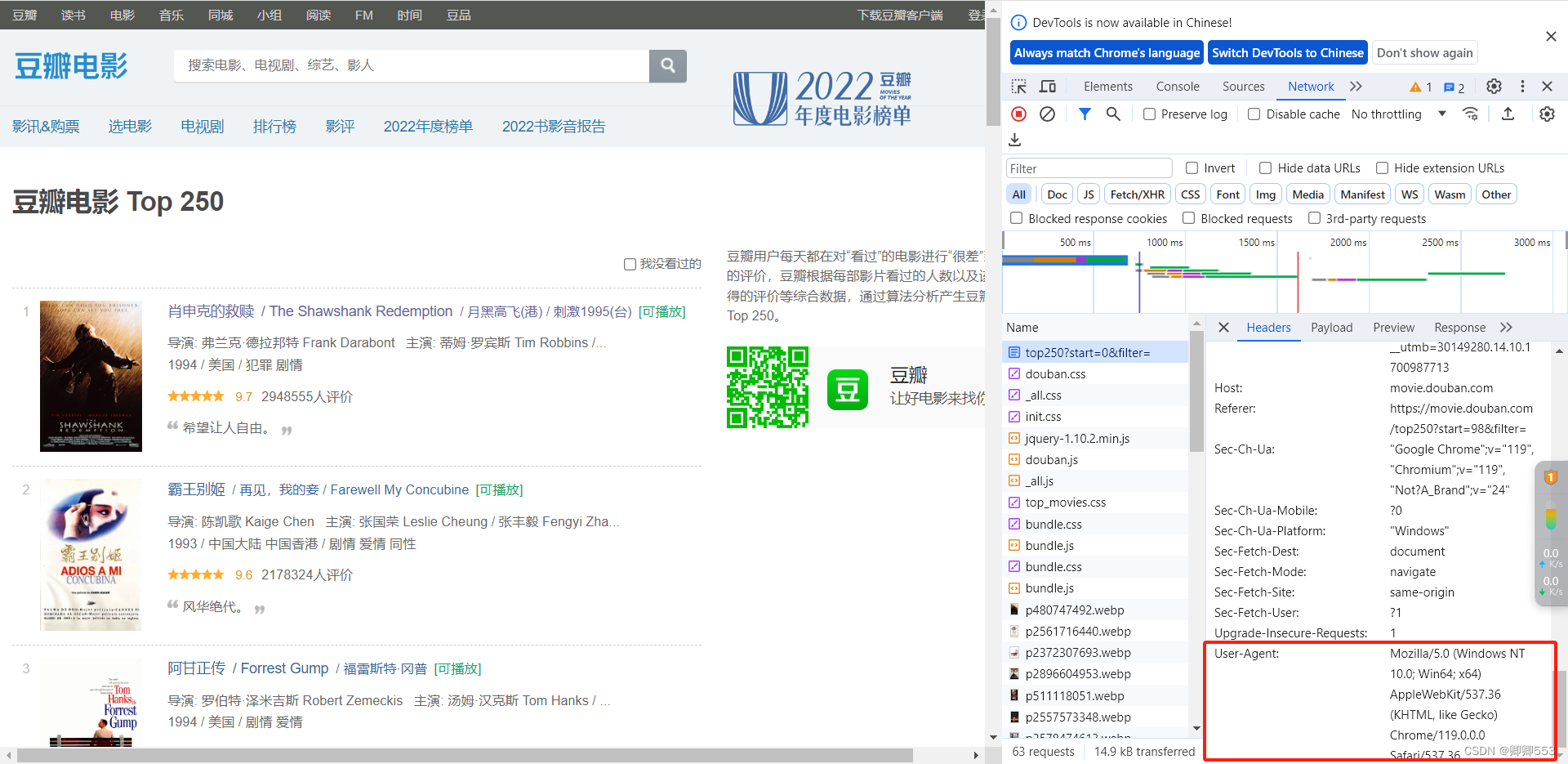
4.翻页功能实现
观察翻页时网址内容变化:
第一页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
推测第一页时start=0,实验过后确实如此,所以翻页功能可以利用for循环实现,利用range以25为间隔使start后的值依次等于0,25,50……,代码如下:
for num in range(0,250,25):
newurl='https://movie.douban.com/top250'+f'?start={num}&filter='
5.利用requests获取html
html=requests.get(url=newurl,headers=headers).text
6.利用xpath进行解析获取top250电影名称name_list与详情页链接url_list
jx=etree.HTML(html)
(1)获取电影名称
name=jx.xpath('//div[@class="hd"]//span[@class="title"]/text()')
由于所选区域包含不需要的内容
所以需要利用for循环把多余数据删除
name_list=[]
for i in name:
if "/" in i:
continue
else:
name_list.append(i)
name_list输出内容展示:

(2)获取电影详情页链接
url_list=jx.xpath('//div[@class="hd"]//a/@href')
7.将数据导出为csv文件
all_data=pd.DataFrame({'电影名称':name_list,'详情页网址':url_list})
all_data.to_csv('D:/豆瓣电影top250信息.csv',mode='a',encoding='utf-8-sig')
注意:encoding不要用utf-8,否则用Excel打开时会显示乱码
三、完整代码展示
import requests
from lxml import etree
import pandas as pd
# url='https://movie.douban.com/top250'
for num in range(0,250,25):
newurl='https://movie.douban.com/top250'+f'?start={num}&filter='
# 利用headers伪装成普通浏览器访问
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \
Chrome/119.0.0.0 Safari/537.36'}
html=requests.get(url=newurl,headers=headers).text
# print(html)
jx=etree.HTML(html)
name=jx.xpath('//div[@class="hd"]//span[@class="title"]/text()')
# print(name)
name_list=[]
for i in name:
if "/" in i:
continue
else:
name_list.append(i)
# print(name_list)
url_list=jx.xpath('//div[@class="hd"]//a/@href')
# print(url_list)
all_data=pd.DataFrame({'电影名称':name_list,'详情页网址':url_list})
all_data.to_csv('D:/豆瓣电影top250信息.csv',mode='a',encoding='utf-8-sig')四、Excel数据清洗整理
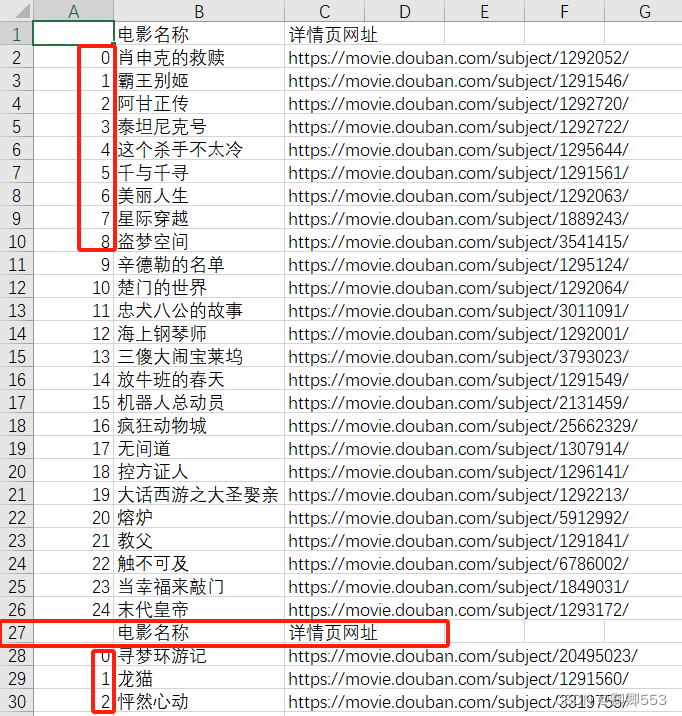

python输出的原表格会存在表头重复、序号排列和一个异常值的问题
快速解决表头重复问题:数据——删除重复值——全选(不要勾选数据包含标题)
序号排列:填充前两个单元格1,2后选中后双击
异常值处理:返回原网址经查验后发现该处有电影,将名字粘贴上去
最终得出开头展示的完整表格。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











