







目录
前言
不知道小伙伴们是否喜欢看电影呢?我本人是非常喜欢在周末闲暇之余看看一些好电影的,这不最近又重温了一下《肖申克的救赎》,雀食不戳啊!!!那么还有些什么比较经典的电影呢?今天给大家带来一个爬虫经典案例:豆瓣Top250电影数据爬取。
代码实现
一.明确受害者
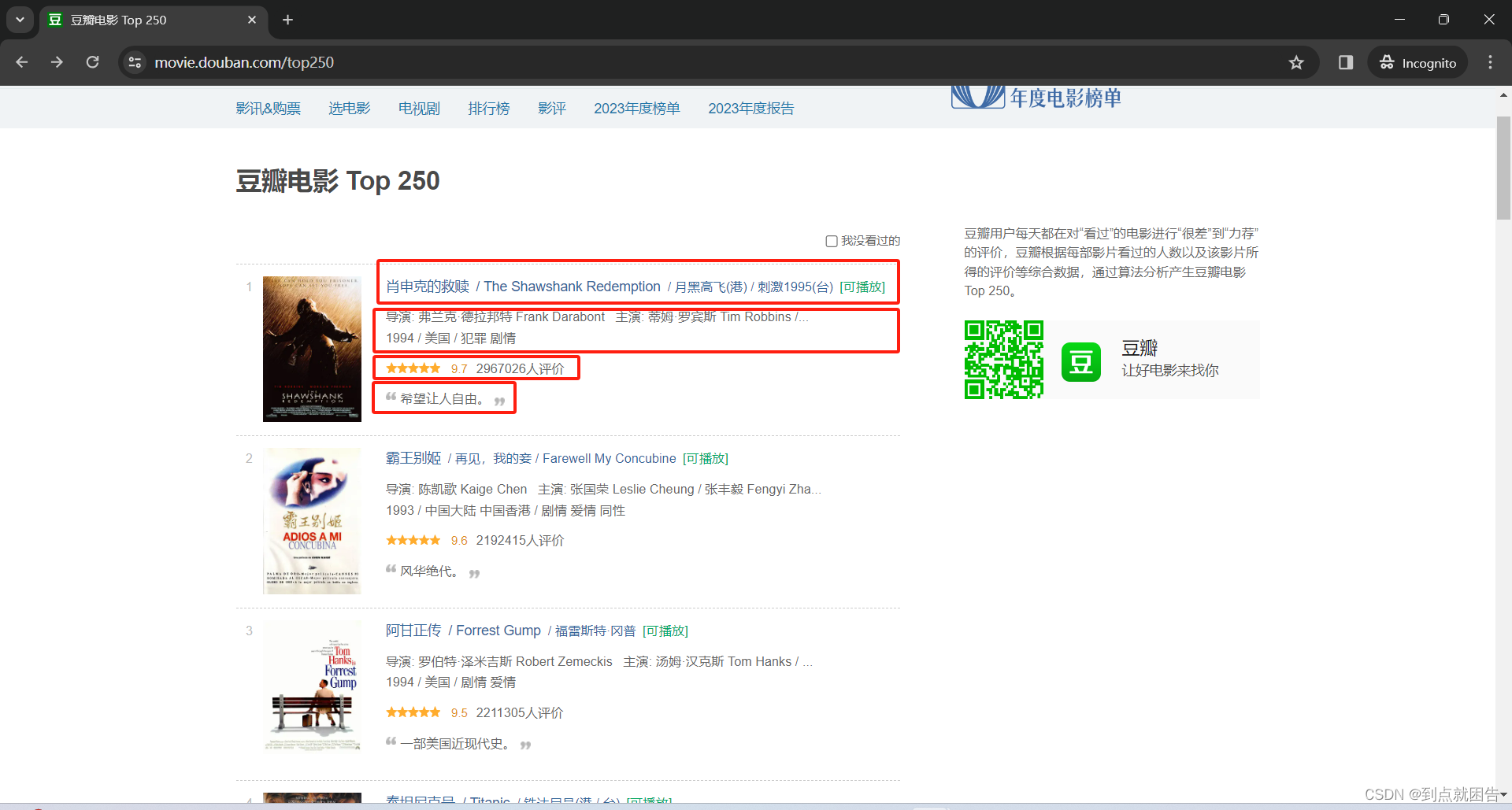
本次的爬取网页是豆瓣电影 Top 250
目标主要是:电影名、电影信息、评分、评价人数、引言以及详情页
二.导入相关模块
import requests
import parsel
import csvParsel是一个用于解析JSON数据的Python库。它提供了一个简单易用的API,可以轻松地从JSON文件或字符串中解析数据。可以对 HTML 和 XML 进行解析,并支持使用 XPath 和 CSS Selector 对内容进行提取和修改,同时它还融合了正则表达式提取的功能。
三.对目标网址发送请求
url = f'https://movie.douban.com/top250'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
response = requests.get(url=url, headers=headers)四.解析数据
F12打开开发者工具,找到我们需要的信息地址,通过xpath获得
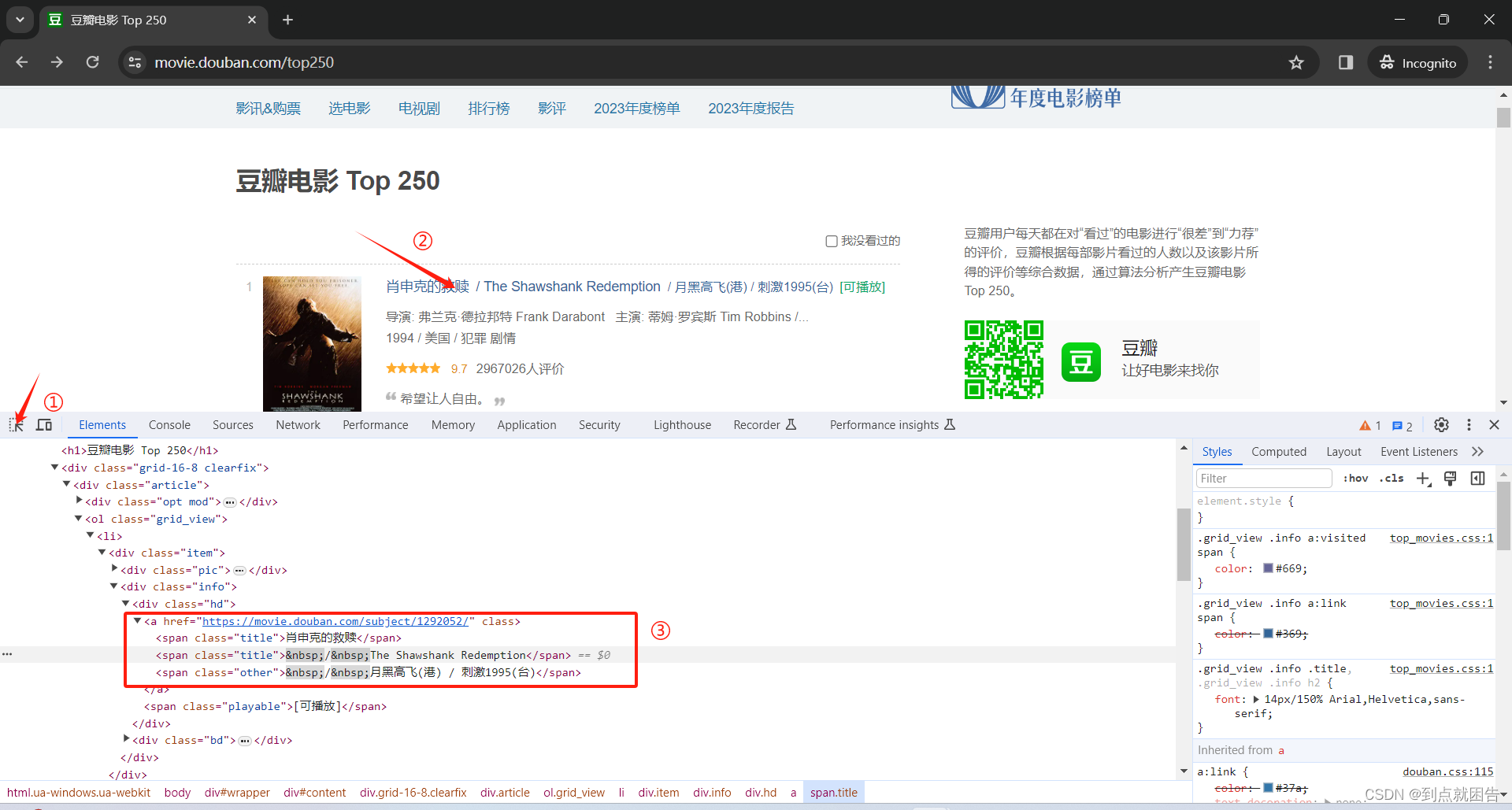
selector = parsel.Selector(response.text)
# print(selector)
lis = selector.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
movie_name = li.xpath('.//div/div[2]/div[1]/a/span[1]/text()').get() # 电影名
movie_info = li.xpath('.//div/div[2]/div[2]/p[1]/text()').getall() # 电影信息
movie_info = (''.join(movie_info).strip()).replace('\n', '')
movie_score = li.xpath('.//div/div[2]/div[2]/div/span[2]/text()').get() # 电影评分
movie_num = li.xpath('.//div/div[2]/div[2]/div/span[4]/text()').get() # 评价人数
movie_lines = li.xpath('.//div/div[2]/div[2]/p[2]/span/text()').get() # 电影摘引
movie_href = li.xpath('.//div/div[2]/div[1]/a/@href').get() # 豆瓣电影详情页
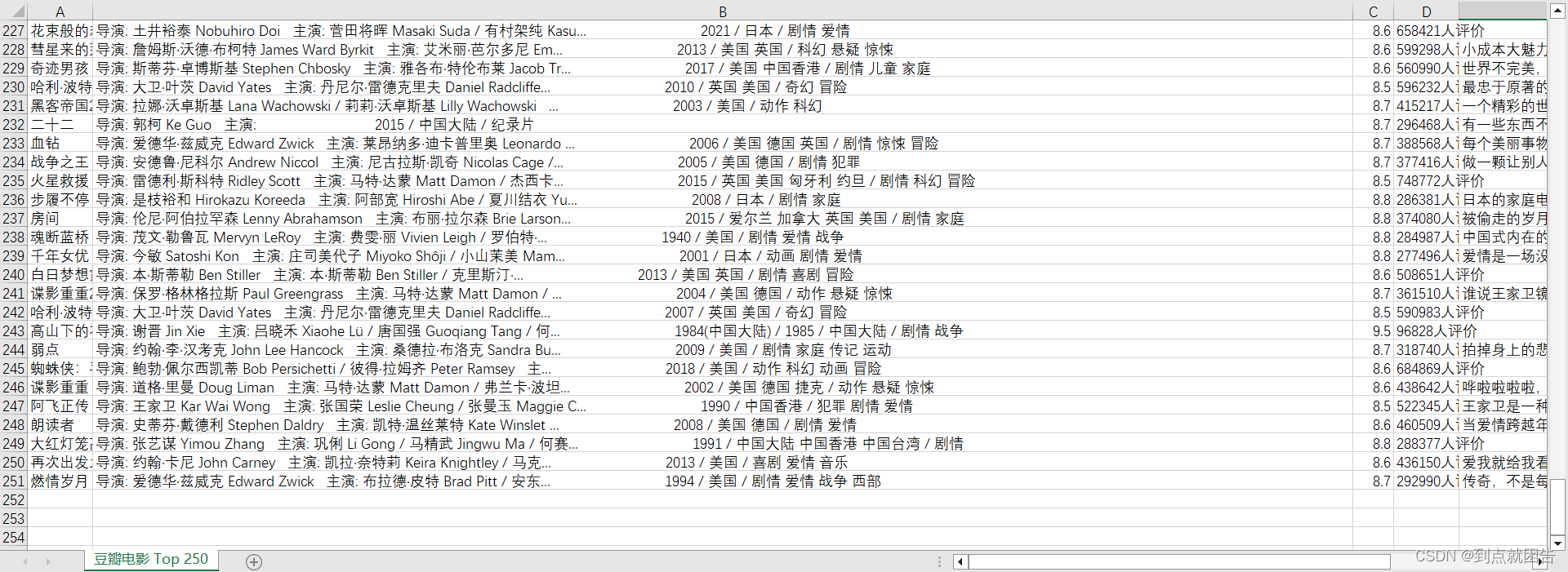
print(movie_name, movie_info, movie_score, movie_num, movie_lines, movie_href)运行结果如下图所示

五.保存数据
f = open('豆瓣电影 Top 250.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名', '电影信息', '评分', '评价人数', '摘引', '豆瓣详情页'])
csv_writer.writeheader()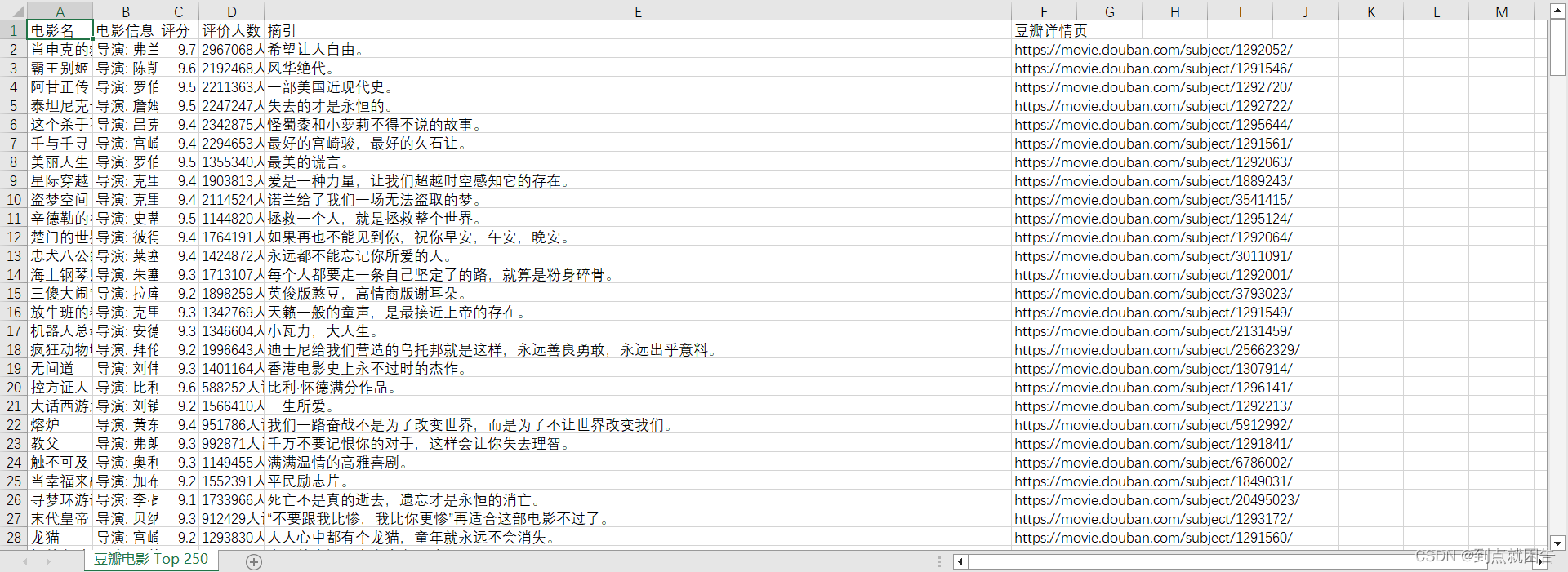
六.实现多页爬取
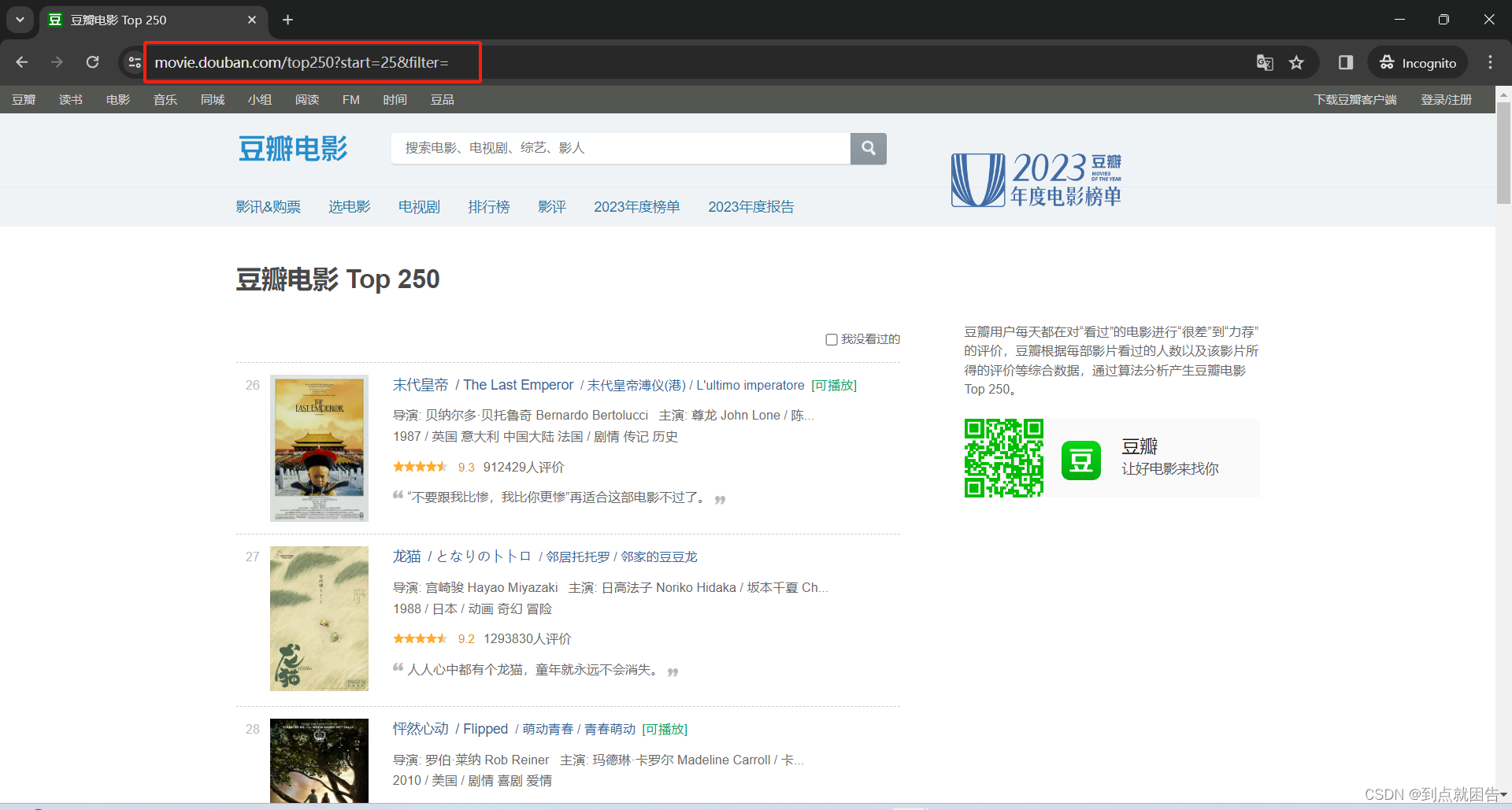
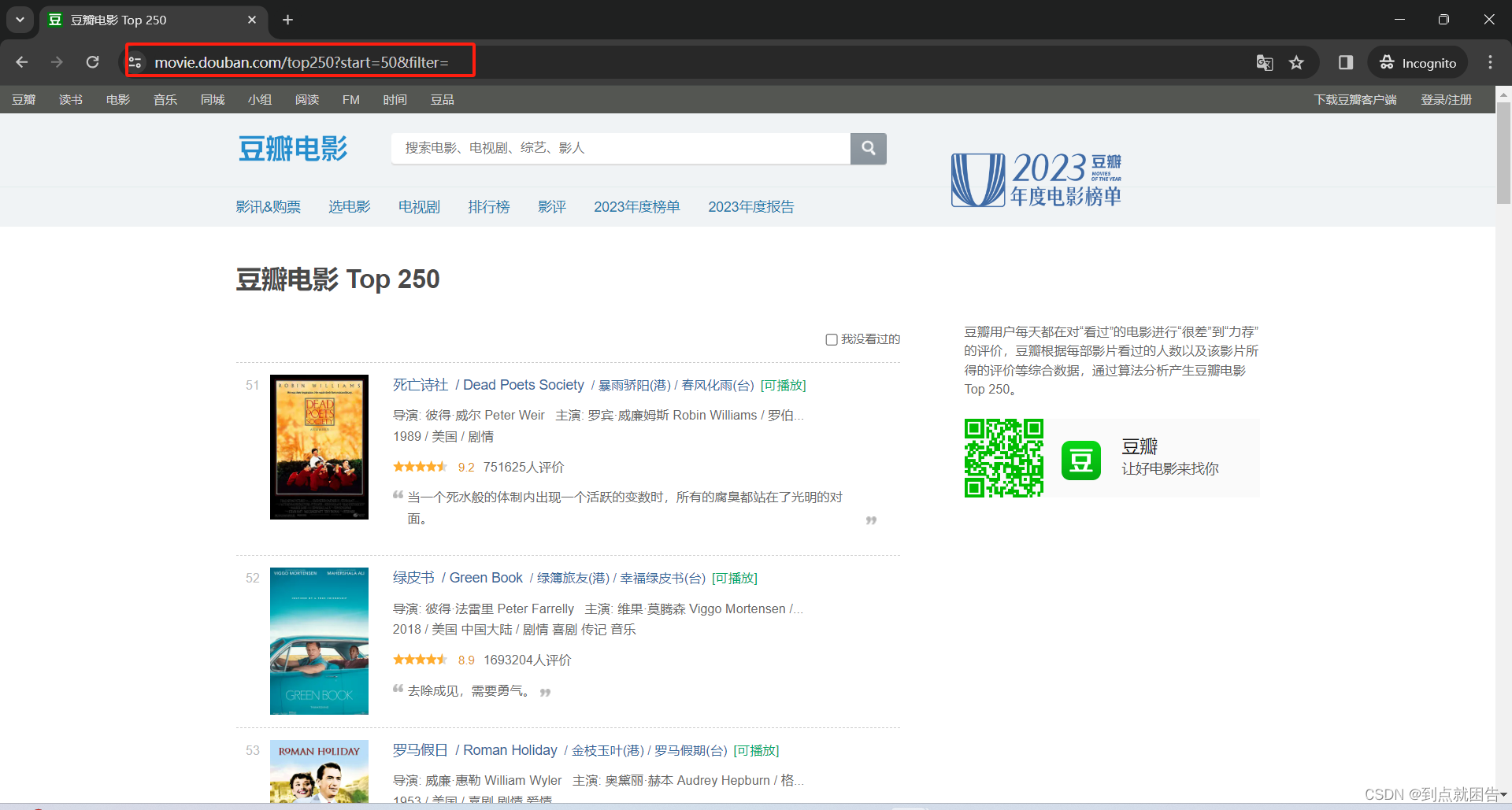
点击下一页,我们可以观察的其网页链接构造
第一页的URL:https://movie.douban.com/top250
第二页的URL:https://movie.douban.com/top250?start=25&filter=
第三页的URL:https://movie.douban.com/top250?start=50&filter=
…
第十页的URL:https://movie.douban.com/top250?start=225&filter=
因此我们只要设置一个参数使其从0开始,设置步长为25直到255构建一个循环即可
num = 0
while num <= 225:
url = f'https://movie.douban.com/top250?start={num}&filter='
num += 25完整代码
import requests
import parsel
import csv
f = open('豆瓣电影 Top 250.csv', mode='a', encoding='utf-8-sig', newline='')
csv_writer = csv.DictWriter(f, fieldnames=['电影名', '电影信息', '评分', '评价人数', '摘引', '豆瓣详情页'])
csv_writer.writeheader()
num = 0
while num <= 225:
url = f'https://movie.douban.com/top250?start={num}&filter='
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
# print(selector)
lis = selector.xpath('//*[@id="content"]/div/div[1]/ol/li')
for li in lis:
movie_name = li.xpath('.//div/div[2]/div[1]/a/span[1]/text()').get() # 电影名
movie_info = li.xpath('.//div/div[2]/div[2]/p[1]/text()').getall() # 电影信息
movie_info = (''.join(movie_info).strip()).replace('\n', '')
movie_score = li.xpath('.//div/div[2]/div[2]/div/span[2]/text()').get() # 电影评分
movie_num = li.xpath('.//div/div[2]/div[2]/div/span[4]/text()').get() # 评价人数
movie_lines = li.xpath('.//div/div[2]/div[2]/p[2]/span/text()').get() # 电影摘引
movie_href = li.xpath('.//div/div[2]/div[1]/a/@href').get() # 豆瓣电影详情页
dit = {
'电影名': movie_name,
'电影信息': movie_info,
'评分': movie_score,
'评价人数': movie_num,
'摘引': movie_lines,
'豆瓣详情页': movie_href
}
csv_writer.writerow(dit)
print(movie_name, movie_info, movie_score, movie_num, movie_lines, movie_href)
num += 25
欢迎点赞评论关注三连



















 4299
4299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











