







网址: 笔趣阁_免费无弹窗阅读元尊,圣墟,庆余年等小说的笔趣阁
本案例所使用到的模块:
- requests
- parsel
爬取步骤:
一.确定目标需求
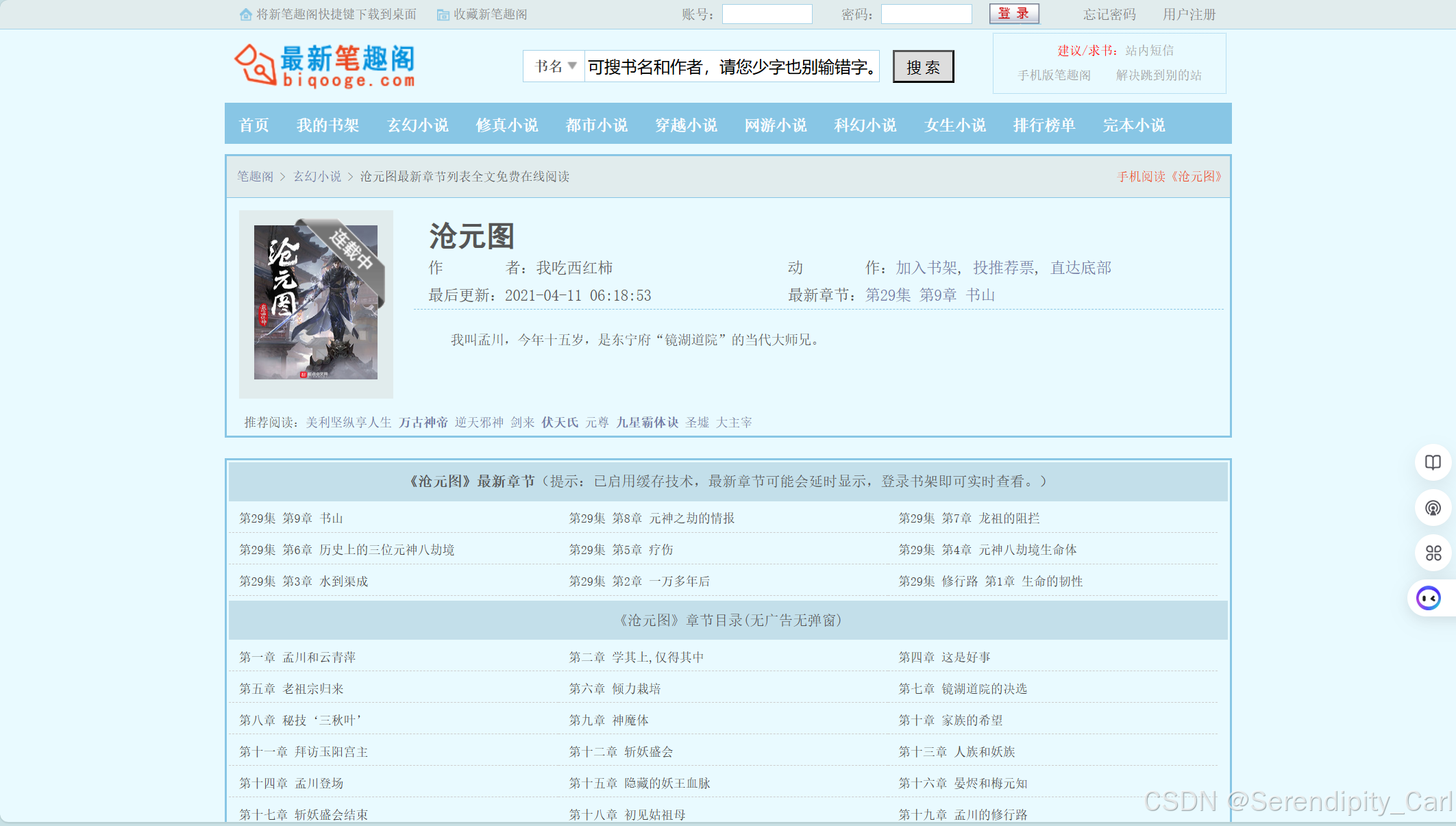
选择自己喜欢的一本小说 进行爬取 首先从爬一章开始
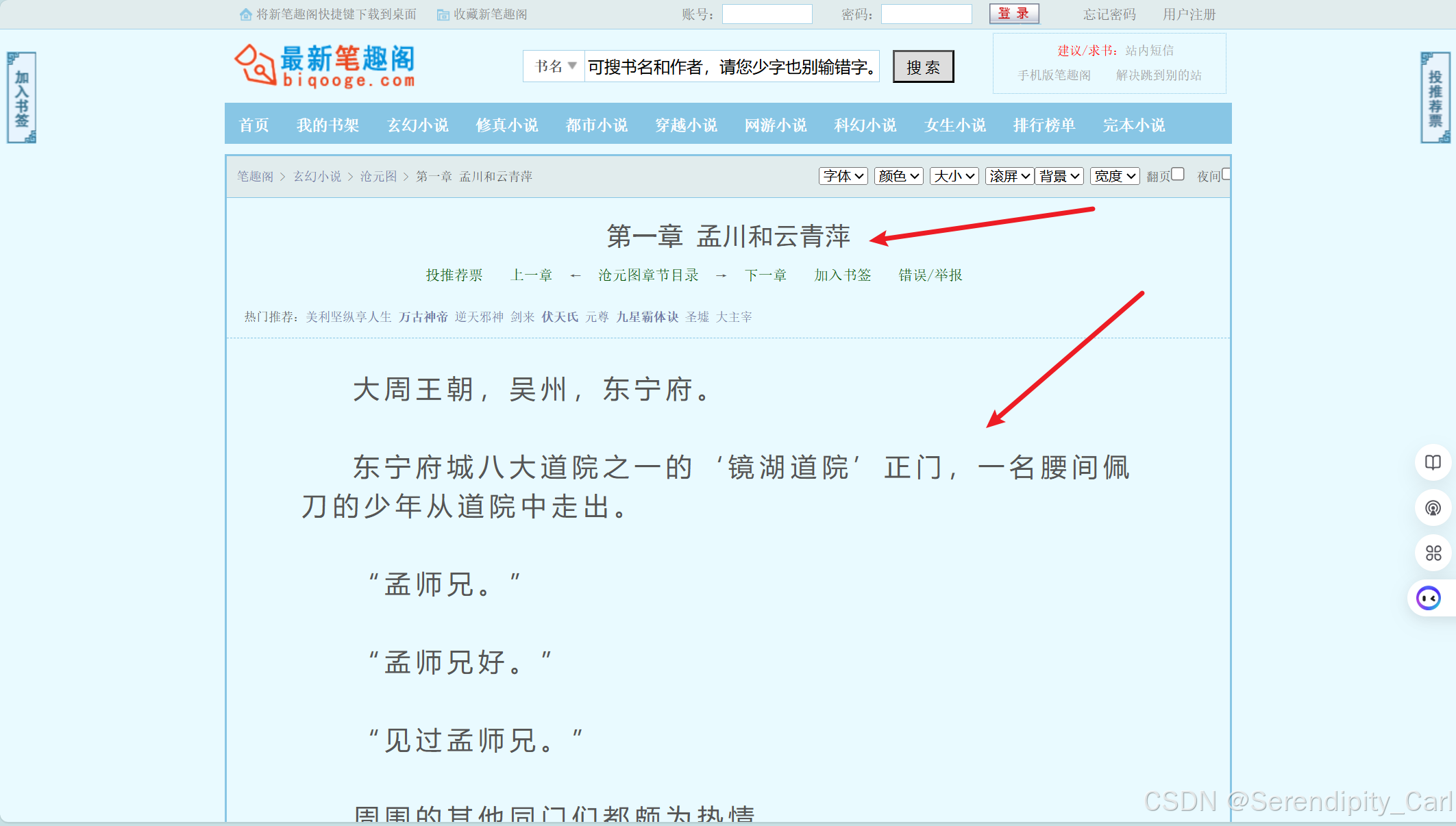
目标是:爬取每一章节的章节名称 以及内容
二. 请求数据 模拟浏览器向服务器发送请求
F12 or 右击打开开发者模式
点击网络 or network
Ctrl+F 打开搜索框 输入文本的一段内容 确定我们所需要的数据在哪个数据包
如下图所示
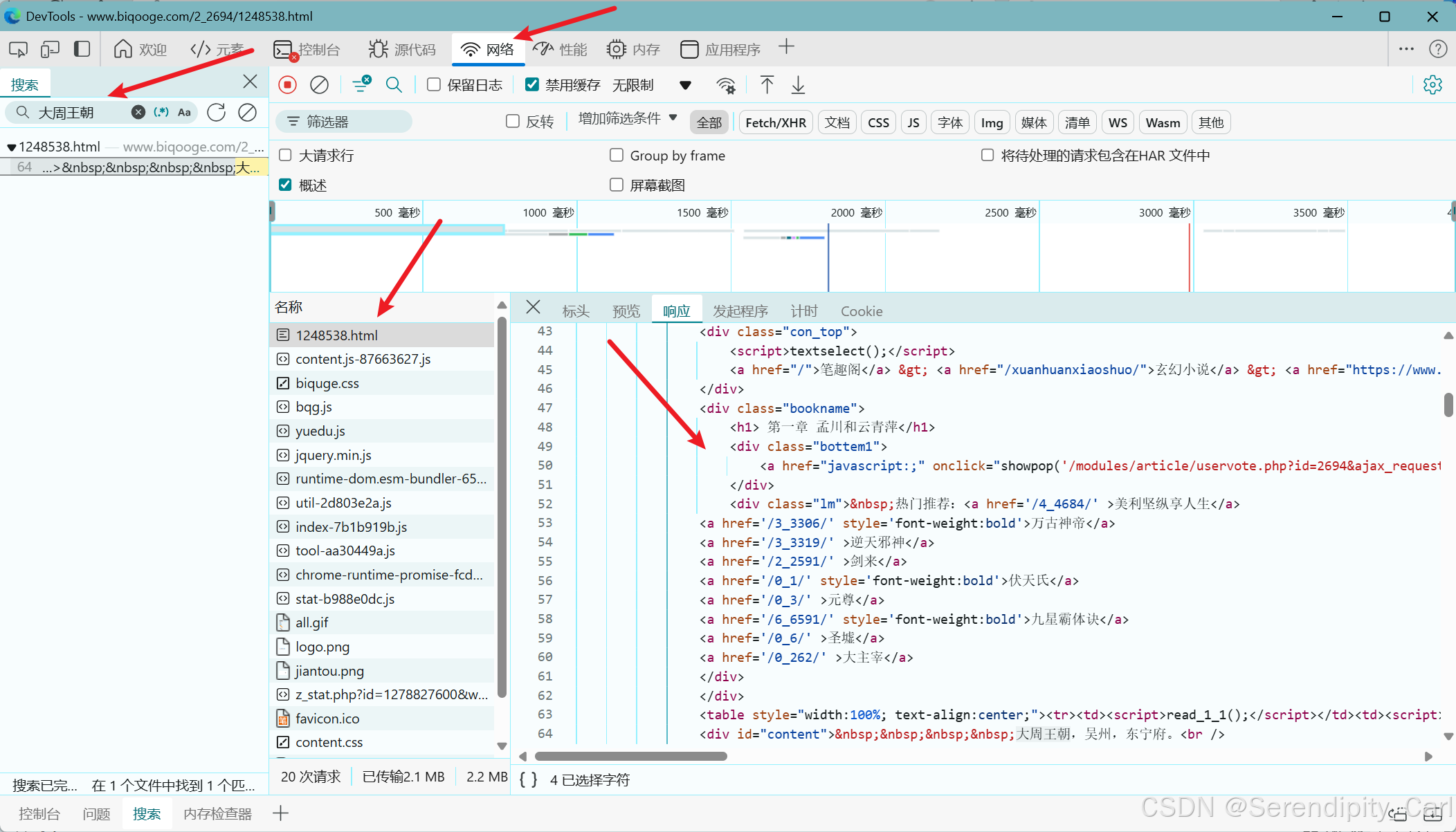
接着我们点击标头 这里面有我们向服务器发送的基本信息包括url地址 请求方式 请求头等
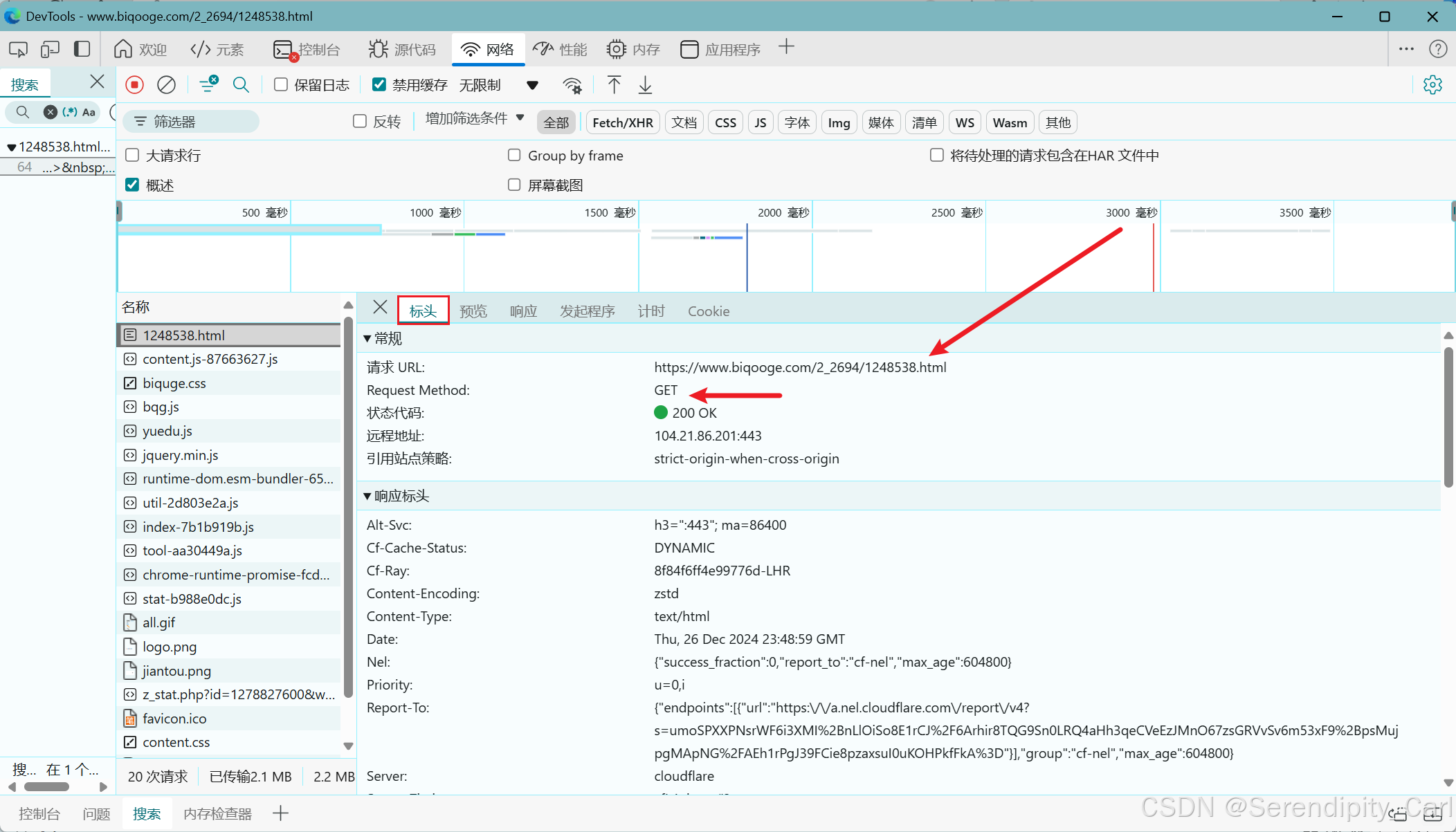
之后复制url 地址到我们的本地py文件,因为是爬虫基础就不使用工具了
将User-Agent也复制过去 UA 为浏览器的基本信息 将爬虫程序模拟基本的浏览器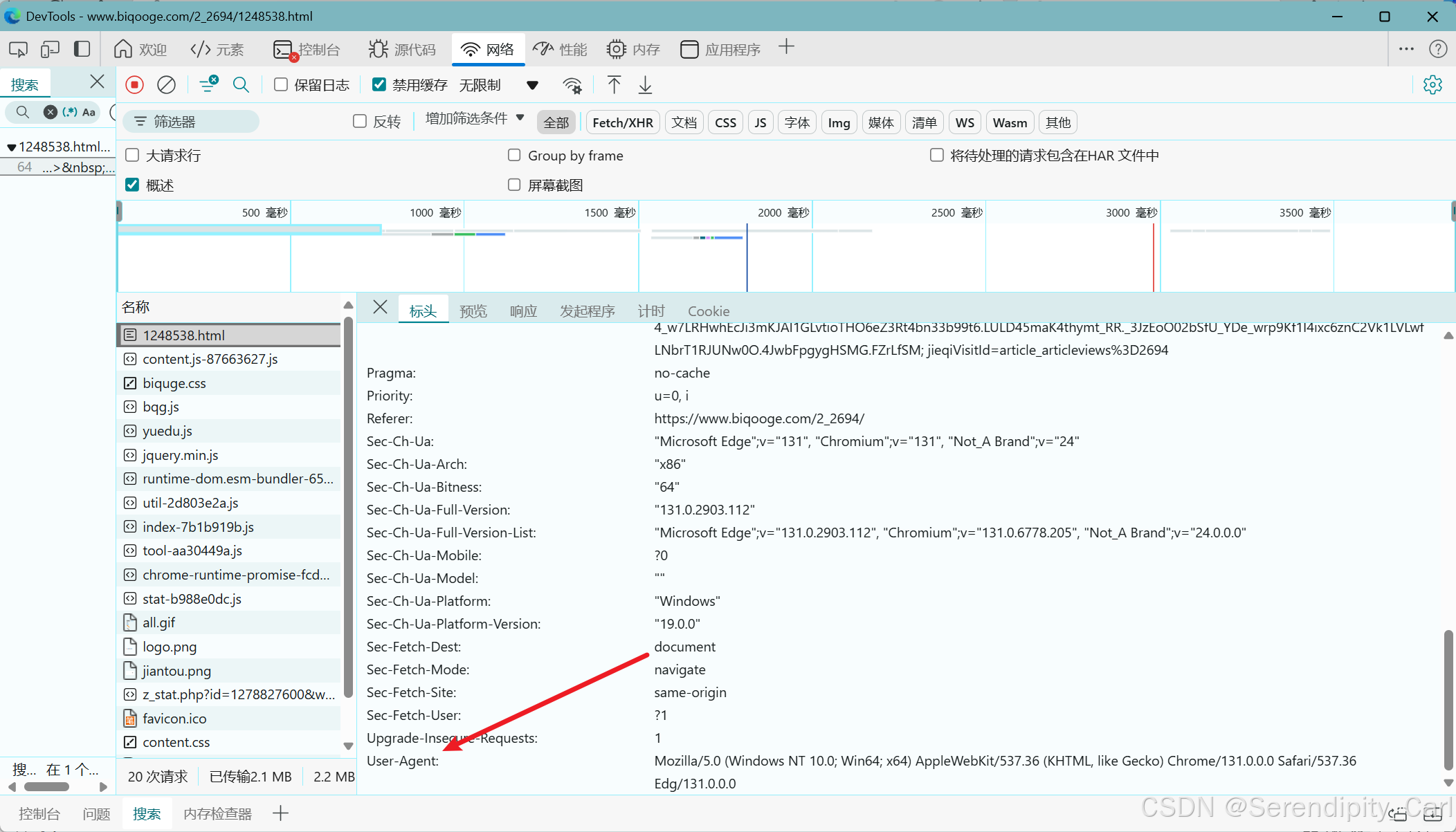
应为请求体中只加个UA 请求不到数据 我们需要继续添加参数 将referer(防盗链) 和cookie(包含我们用户的相关信息)这样就可以从服务器请求到数据了
import requests
url = 'https://www.biqooge.com/2_2694/1248538.html'
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
'referer':
'https://www.biqooge.com/2_2694/',
'cookie':
'cf_clearance=JIIfAcUehsEU9ZTvNWBjd47WrNq98D9ntTsVJkkGMNo-1735256698-1.2.1.1-2BDyIxNzvxdjKBz4JGmE2pCDyUqcOmvfAbRmUC60W.Pn2nuOJ1nMiSNHEJDZgaylaaropOYUIXAaVL5XFS3IiDu4t8ig1vlwOpfwvMb6cIsvb1b.aMJUE0ZoVuuFKGKre4yZDu4sTyPowHUagp3f9Yb65HWhHEqEybZ08tOV.j54ujMrdMTJpmEUGexJoM5HLEpeWpu7YgvRJK4VlzURs5l6uS2vmpt9h8DaoBio6vL8VABxmFiWuvox.COjtK1GWnwuD18zIJnFpNCmpNmgGjJBIC4E6E7NAd4GUfPYDREYIbgOi4_w7LRHwhEcJi3mKJAI1GLvtioTHO6eZ3Rt4bn33b99t6.LULD45maK4thymt_RR._3JzEoO02bSfU_YDe_wrp9Kf1I4ixc6znC2Vk1LVLwfLNbrT1RJUNw0O.4JwbFpgygHSMG.FZrLfSM; jieqiVisitId=article_articleviews%3D2694'
}
resp = requests.get(url, headers=headers).text
print(resp)
运行上述代码之后的结果如下: 可以发现 看不懂思密达 这是编码问题 将我们的编码设置为gbk 就可以了
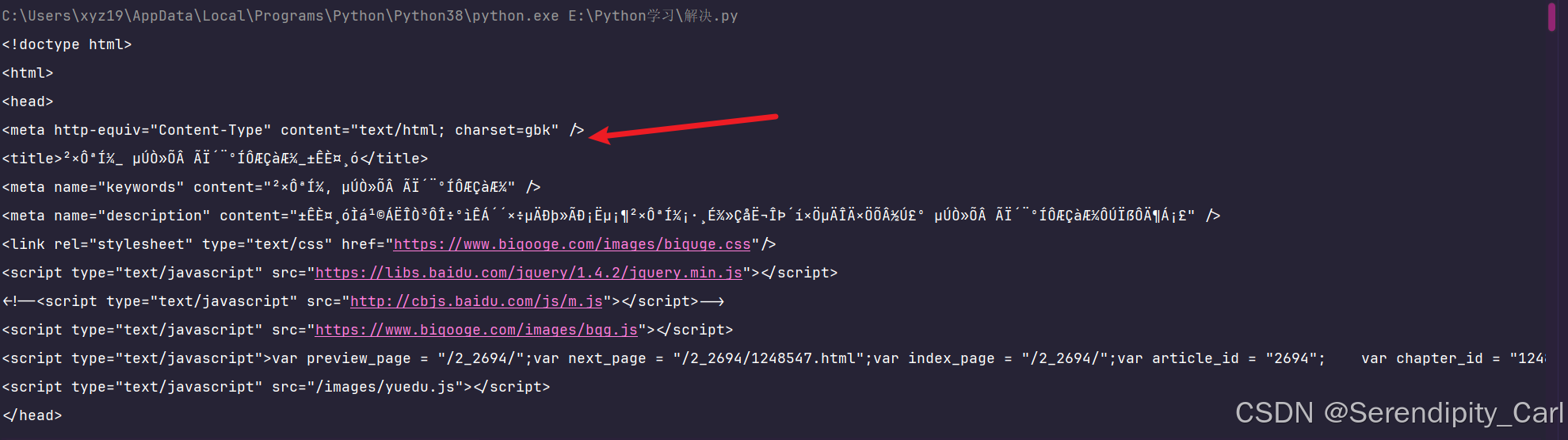
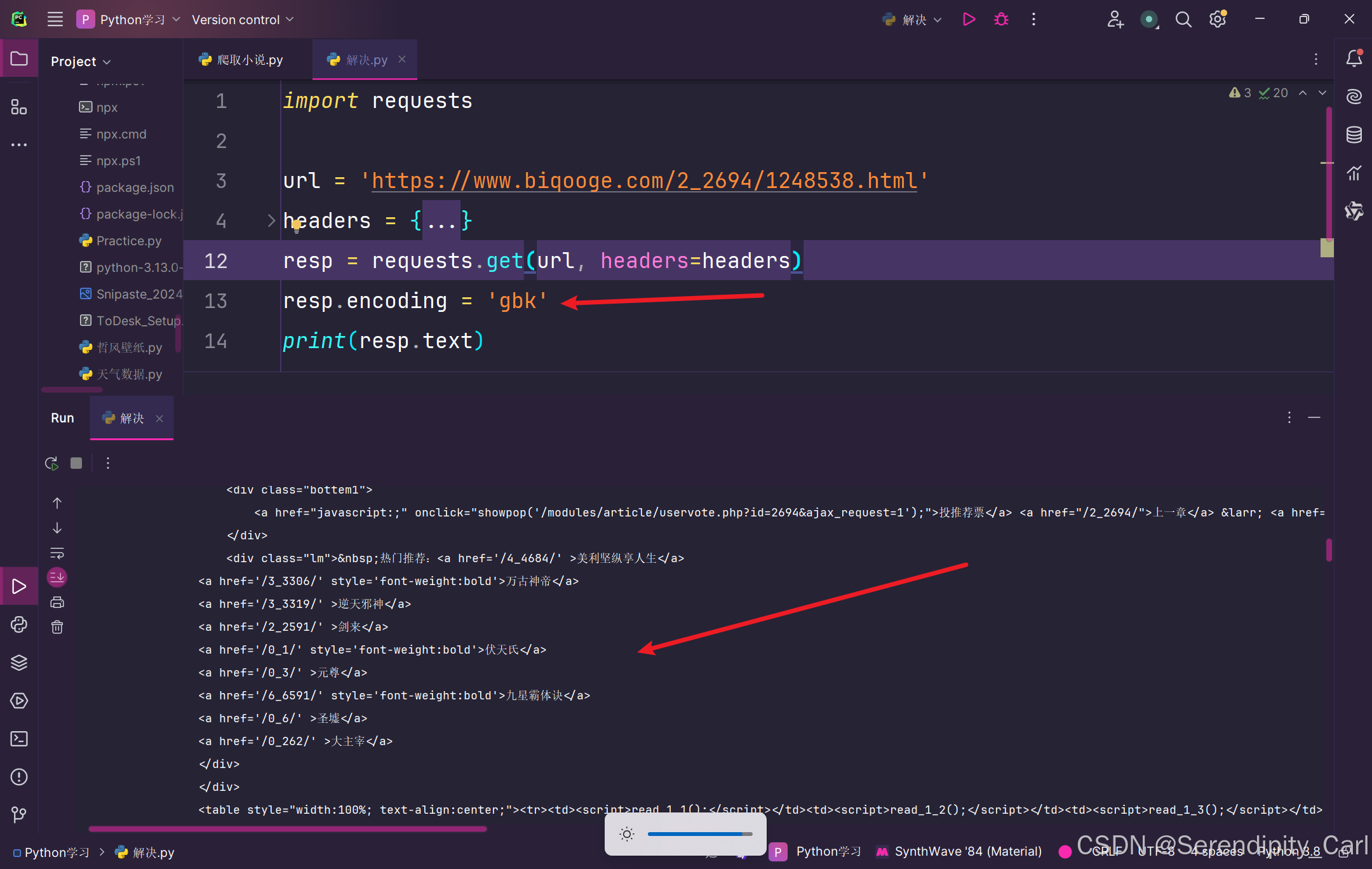
设置完就可以看到我们的明文数据啦
三. 解析数据 分析我们想要的数据在什么位置 如何去提取
还记得我们的目标嘛 章节名称和小说的数据 如下图所示


之后我们再运行会报出此代码 这是网址采用了反爬虫技术 5s盾 tls反爬技术 哦豁了
别急我们这个网址有其他的还是可以爬的
例如这个 :沧元图-第一章 孟川和云青萍-笔趣阁
方法和思路一样 后面我会出用自动化模块绕过此反爬去采集正版小说网站数据 敬请期待哟
接着我们跟新一下代码
都是差不多的 需要改一下url地址参数定位元素的位置
Explain: 此网站无反爬 只需要UA就可以
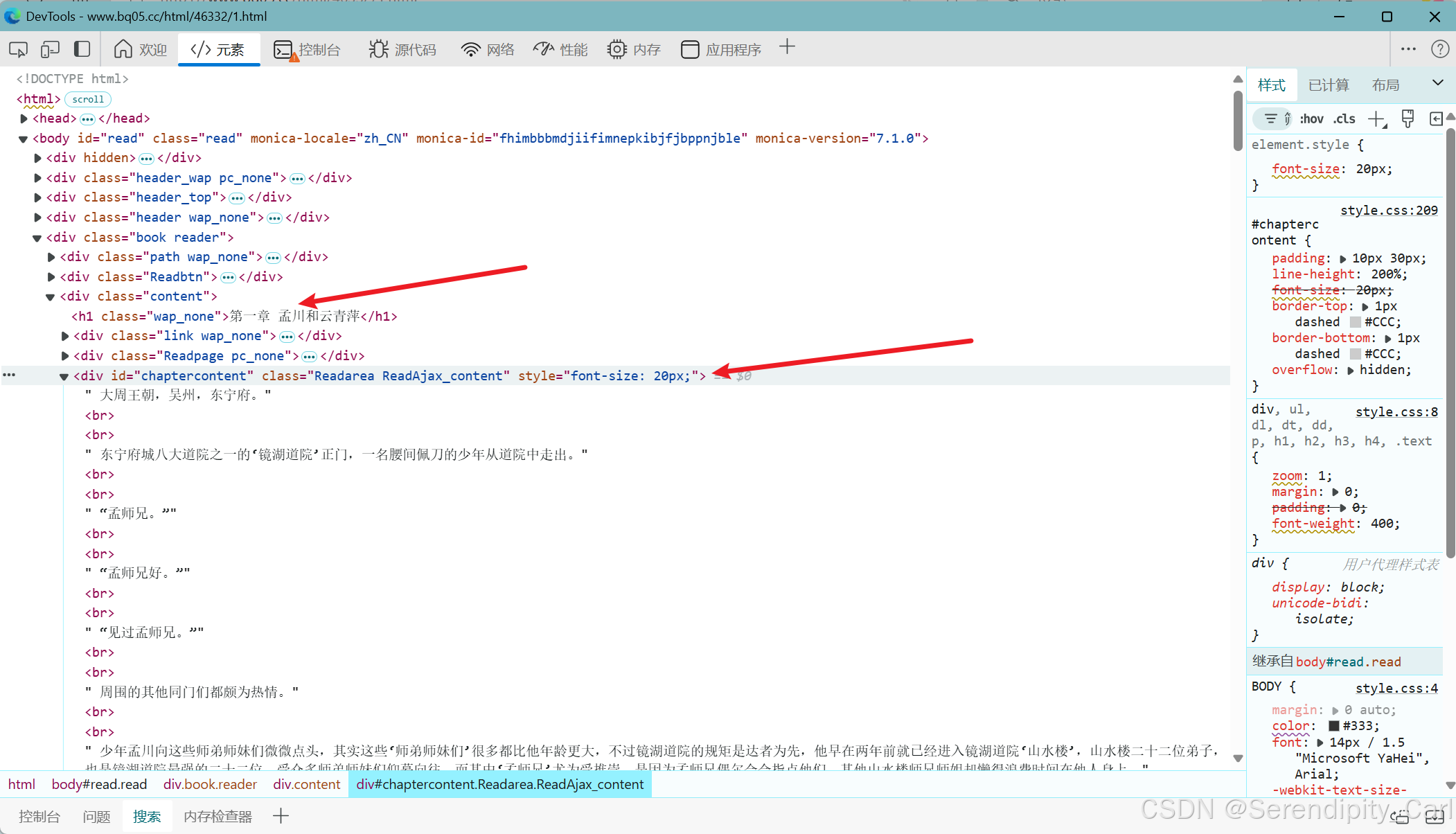
右击元素 复制它的selector 意思为css语法 还有其他的 如xpath等
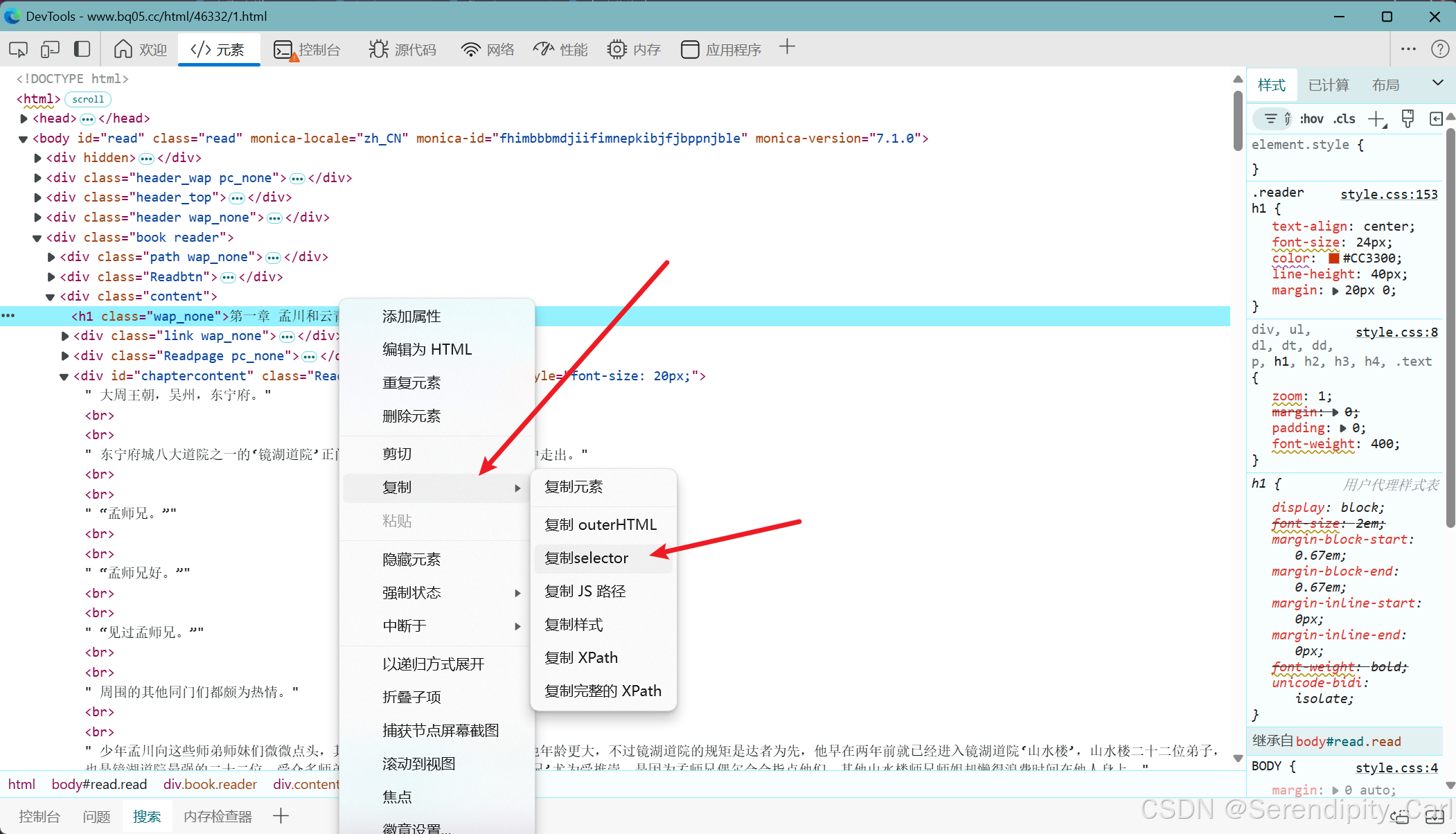
import time
import parsel
import requests
url = 'https://www.bq05.cc/html/46332/1.html'
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
}
resp = requests.get(url,headers=headers)
# 创建一个实例化对象
selector = parsel.Selector(resp.text)
# getall 顾名思义 获取所有的意思 其放回值为列表 对列表取值
name = selector.css('#read > div.book.reader > div.content > h1::text').getall()[0]
content = selector.css('#chaptercontent::text').getall()
print(name)
print(content)
输出内容如下 内容我们需要后续处理

# 去除前后空格并每隔一个取元素:
#使用列表推导式 [i.strip() for i in content[:-4:]],其中 i.strip() 去除每个元素的前后空格,#content[:-4:] 表示每隔一个元素取一次,直到倒数第四个元素。
#连接成字符串:使用 ''.join(...) 将处理后的元素连接成一个字符串。
#替换句号为换行符:使用 .replace('。', '\n') 将字符串中的句号替换为换行符。
#这样保存到txt中的文件就是一行一行的
new_content = ''.join([i.strip()for i in content[:-4:]]).replace('。','\n')四.保存数据到本地
with open(f'{name}.txt','w',encoding='utf-8',newline='') as f:
f.write(new_content)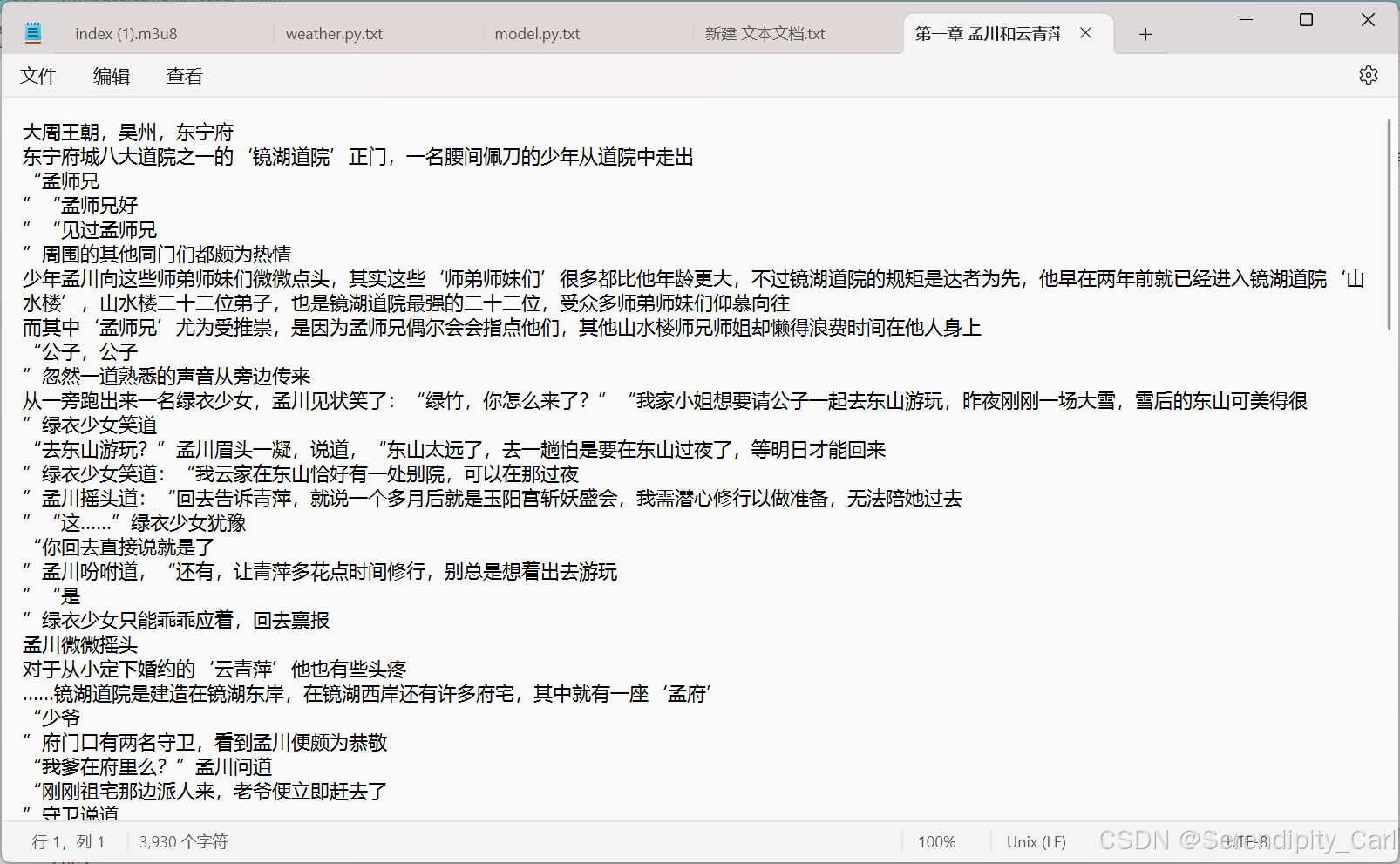 到此 一个章节的内容爬取完毕 接着我们进行多个章节的爬取
到此 一个章节的内容爬取完毕 接着我们进行多个章节的爬取
多章节采集
在整本小说中打开开发者工具中的元素面板 找寻规律
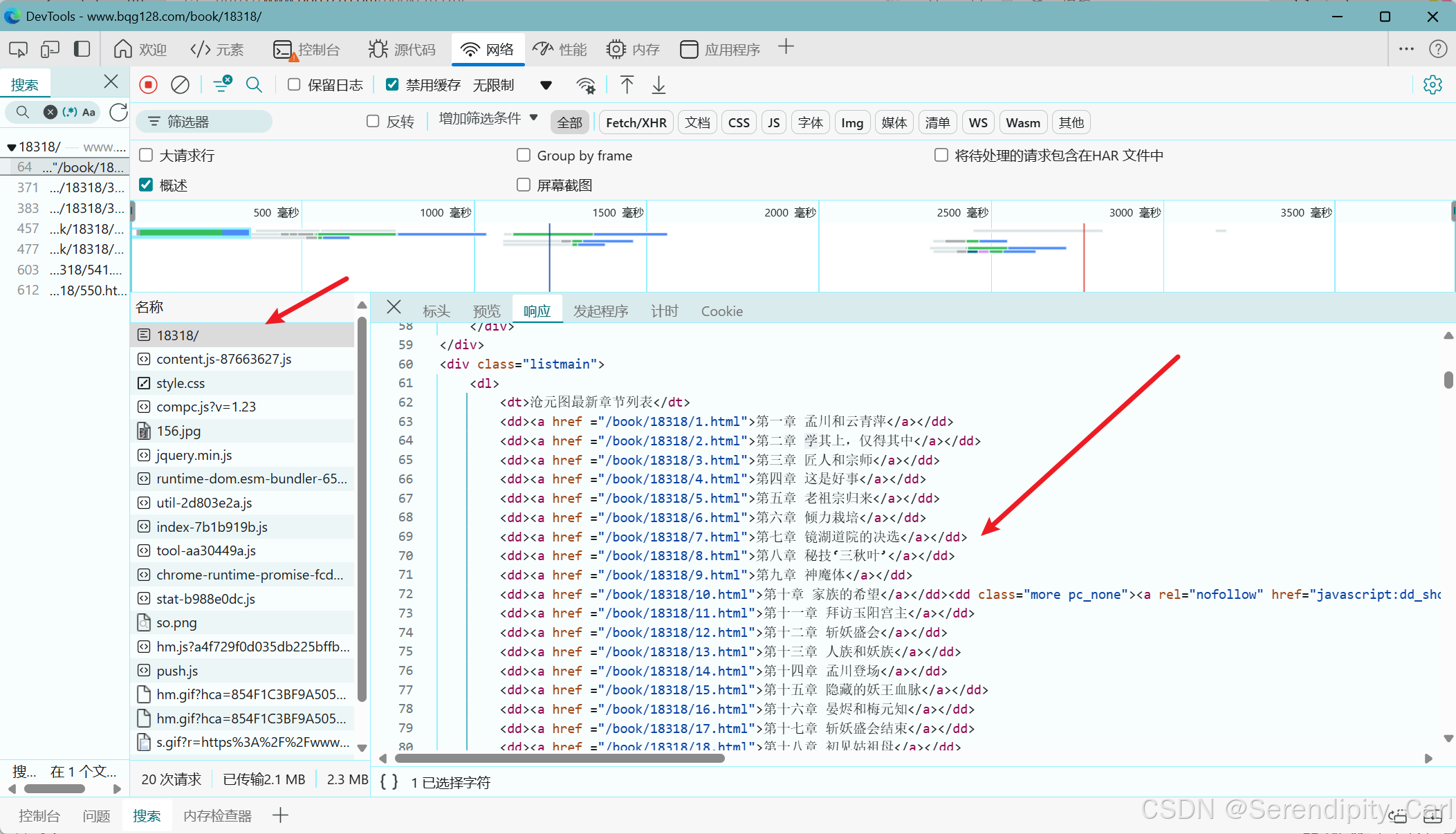
对此数据包进行请求 拿到我想要的数据 a标签中的href值
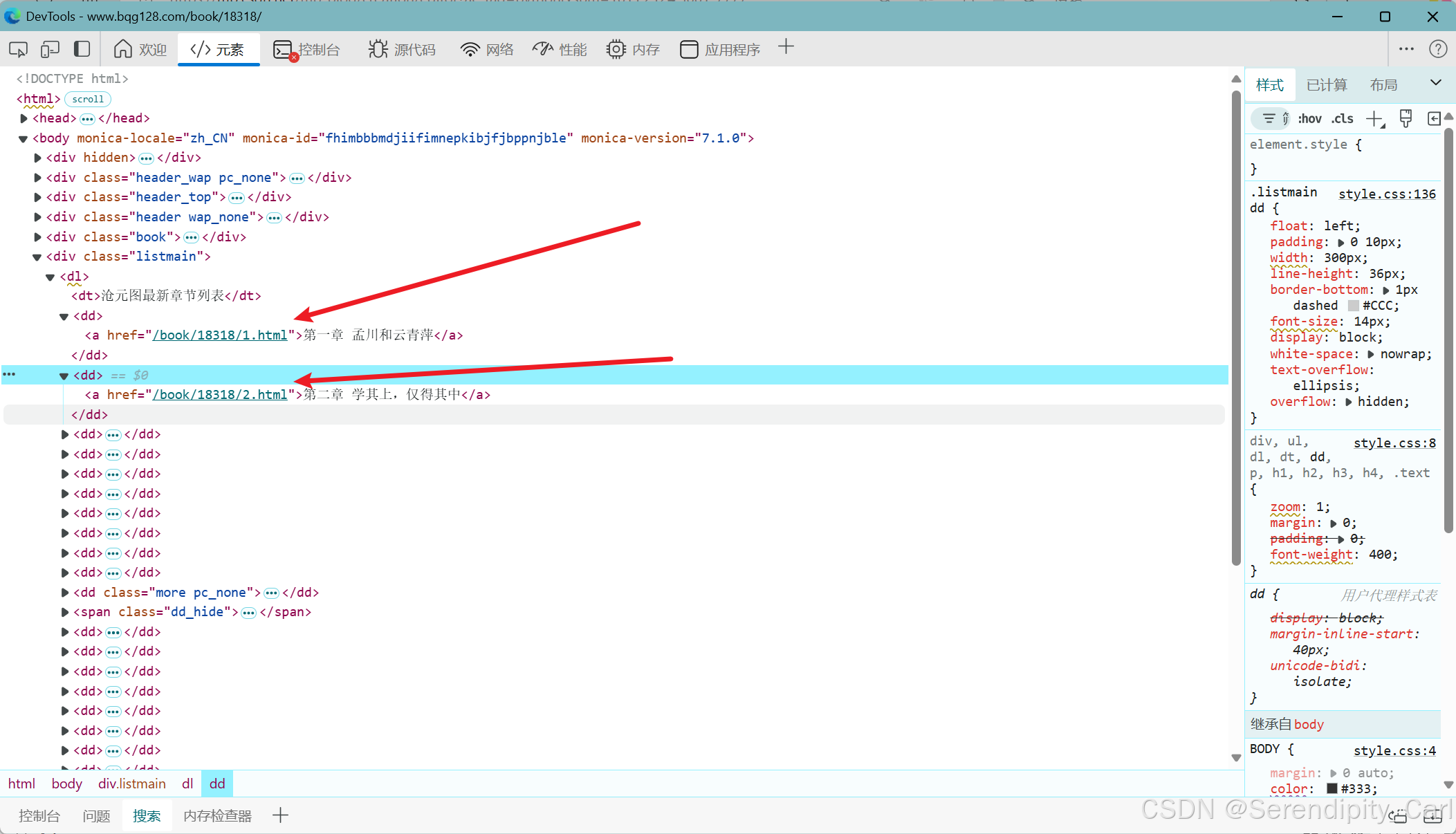
因中间有这个 我们可以跳过 做两次采集就可以啦
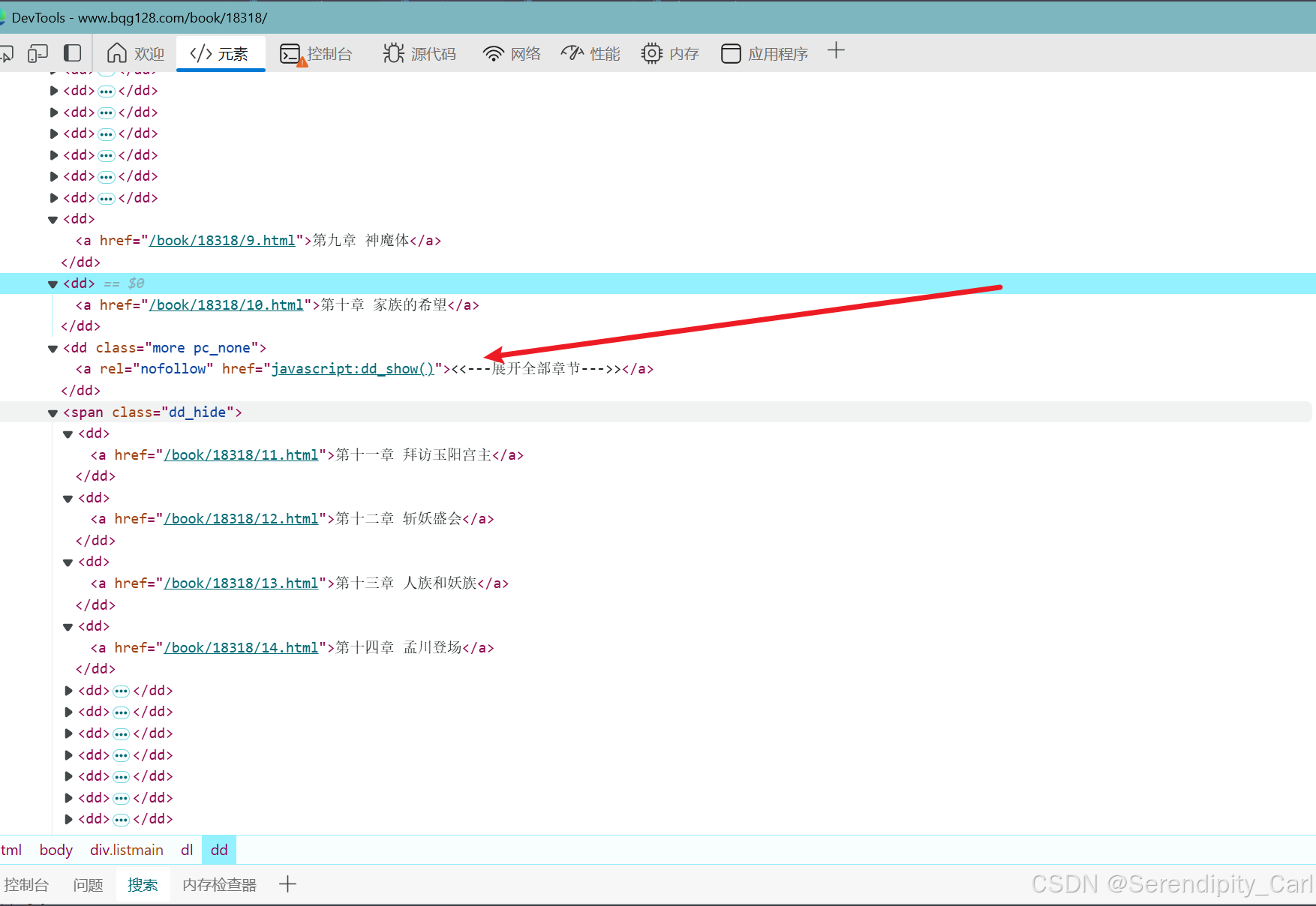
以下是本次案例的源代码 仅供学习交流使用
import parsel
import requests
headers = {
'user-agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
}
ini_url = 'https://www.bqg128.com/book/18318/'
ini_resp = requests.get(url=ini_url,headers=headers)
ini_selector = parsel.Selector(ini_resp.text)
href = ini_selector.css(".listmain dd a::attr(href)").getall()
# 这个地址其实也就是在首页的地址上拼接1-...
for j in href[0:10]:
# 先采集前面一部分再采集后面的
fi_url = "https://www.bqg128.com"+j
resp = requests.get(url=fi_url,headers=headers)
selector = parsel.Selector(resp.text)
name = selector.css('#read > div.book.reader > div.content > h1::text').getall()[0]
content = selector.css('#chaptercontent::text').getall()
new_content = ''.join([i.strip()for i in content[:-4:]]).replace('。','\n')
with open(f'txt\\{name}.txt','w',encoding='utf-8',newline='') as f:
f.write(new_content)
print(name)

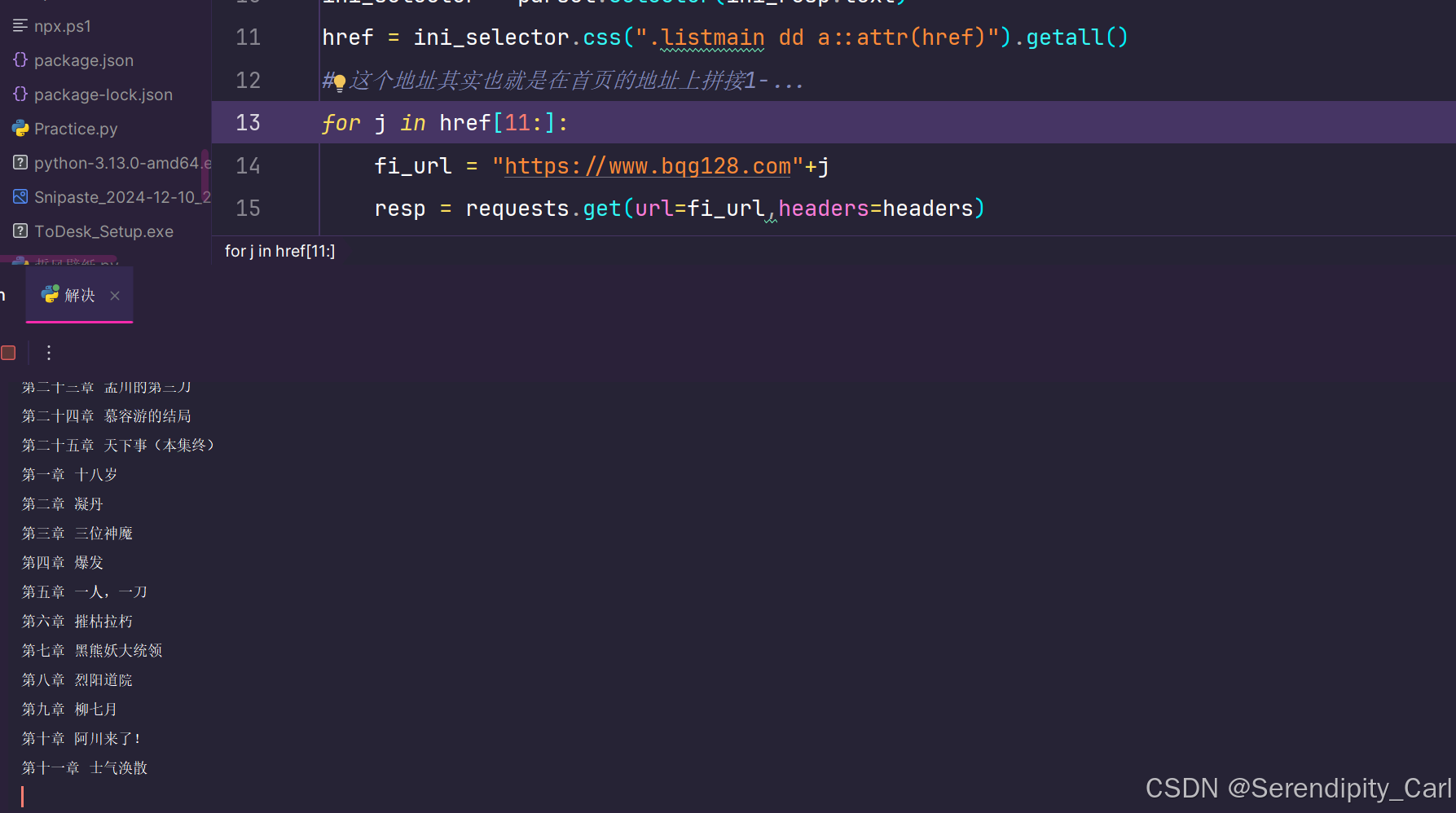
这样就可以啦 整本小说采集完毕 至于多本小说的采集 在外面套层for 循坏就可以啦
感兴趣的同学可以动手试试
本次的案例分享就到此结束了 感谢大家的观看 后续我会出自动化绕过正版网站反爬的文章
点个关注不迷路哟 谢谢!



















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











