







声明: 本案列内容仅供学习交流使用 任何用于非法用途的均与本作者无关
确定需求:
- 网址:酒店,酒店预订查询,宾馆住宿【携程酒店】
- 需要采集的数据: 酒店名称 价格 位置 评分 简介
| requests | json |
| pandas | pprint |
| pyecharts | pandas |
监听数据包:
- 打开开发者工具 F12 or 右击点击检查 点击网络
- 点击下一页 或者往下滑
- Ctrl+F 快捷键打开搜索框 输入想要爬取的数据
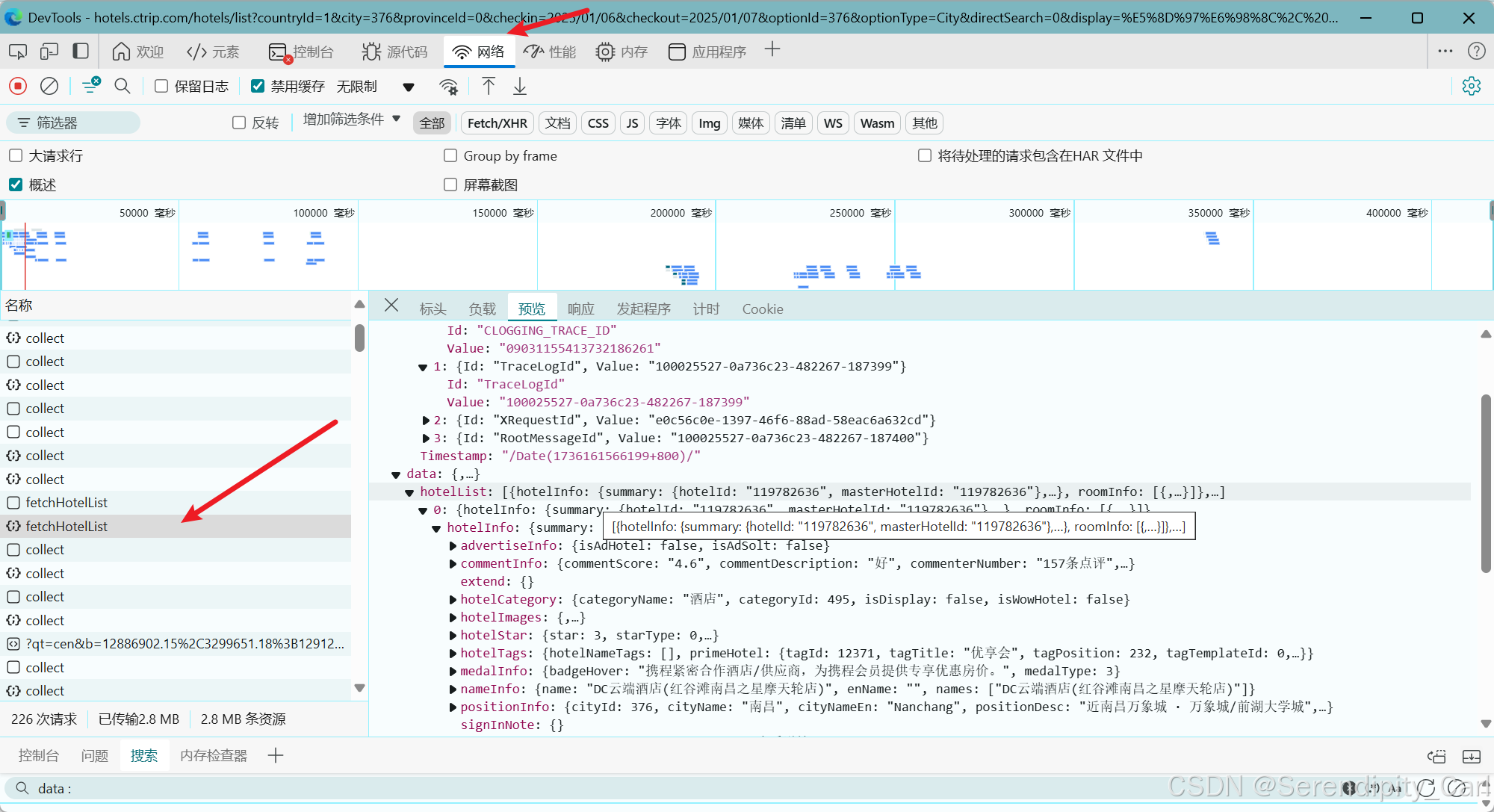
初步分析我们想要的数据包含在如下图的数据包中
接着我们使用爬虫工具 爬虫工具库-spidertools.cn
复制如下图的代码 注意是bash 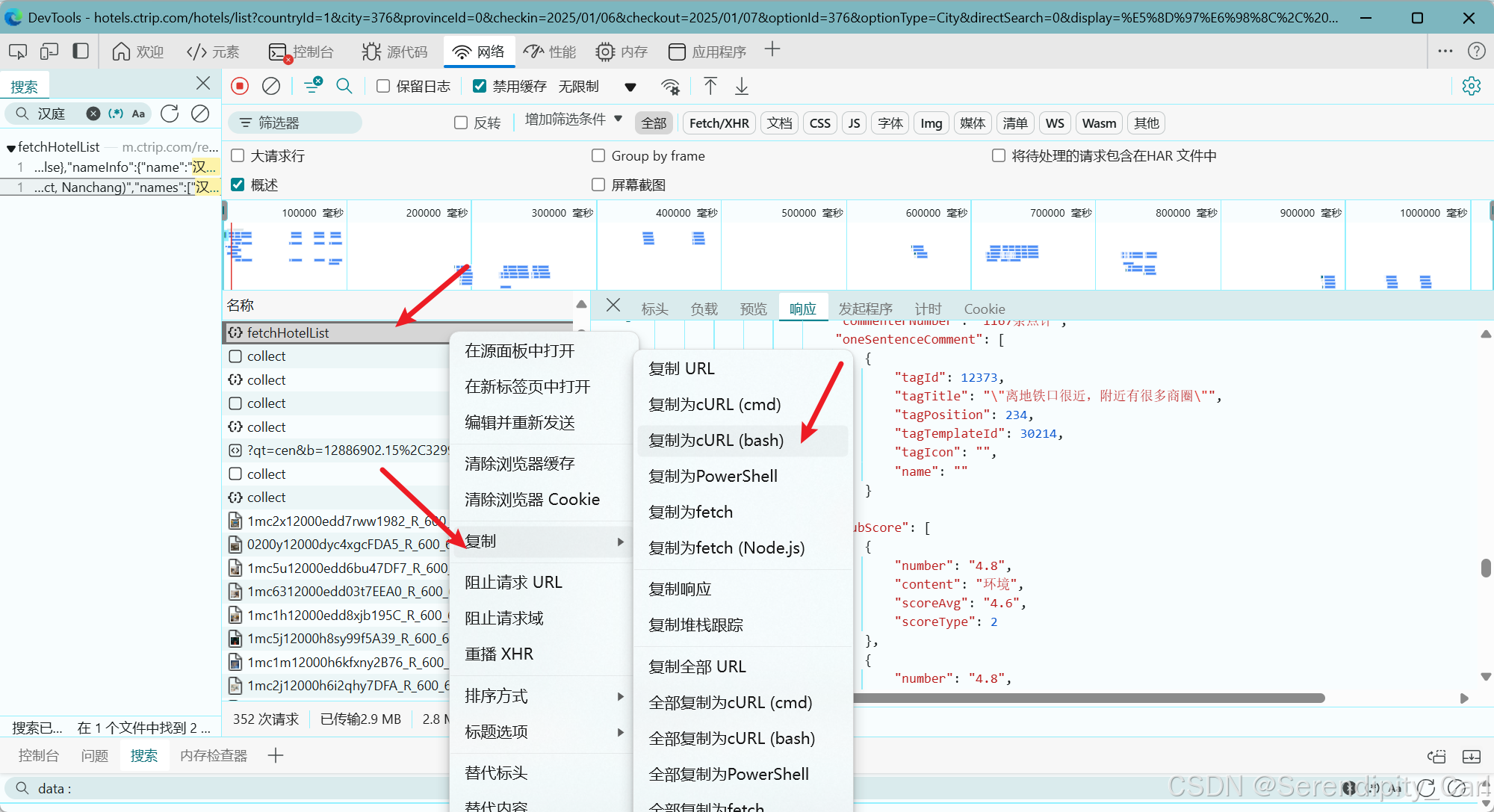
虽然代码很多 但是不要慌 不需要管它 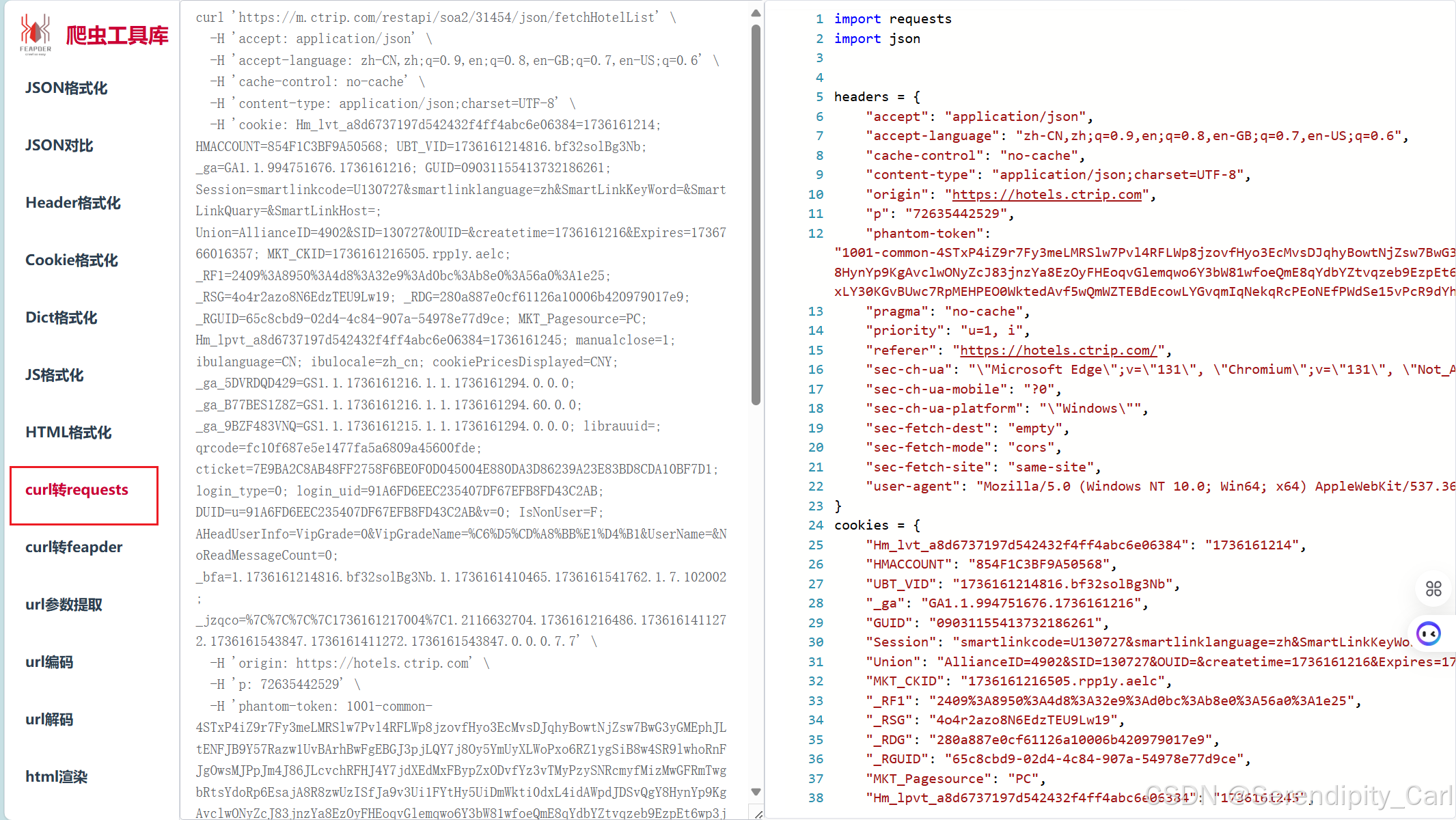
复制到本地py文件 运行 因为服务器返回的数据包是JSON格式的 可以使用pprint模块进行格式化内容 具体如下图 这样看起来舒服多了
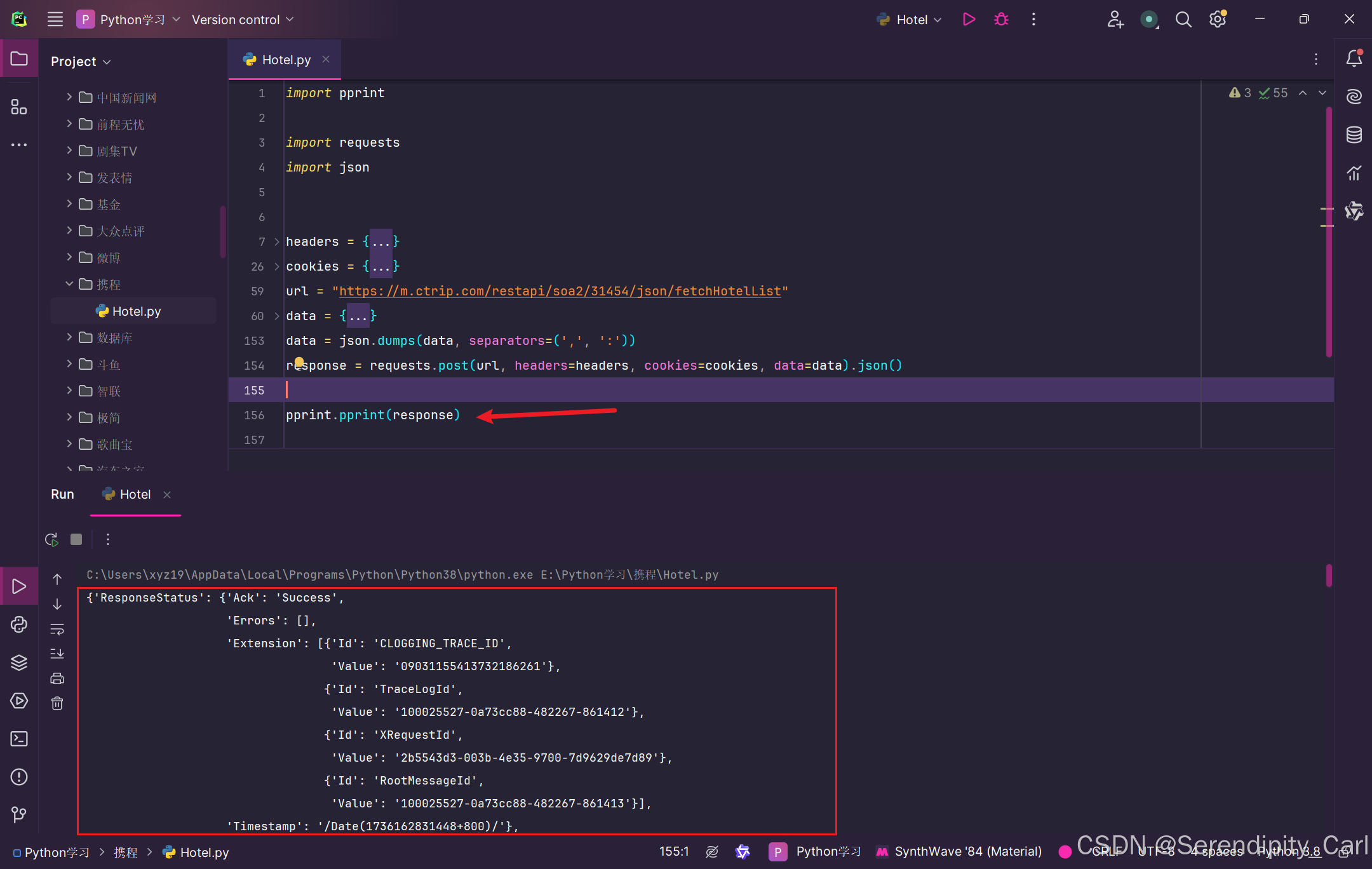
第一步模拟浏览器向服务器发送请求完毕 接着我们分析提取数据
# 获取JSON格式的数据
response = requests.post(url, headers=headers, cookies=cookies, data=data).json()
# 根据键值对取值
json_data = response['data']['hotelList']
# 格式化打印 查看内容
pprint.pprint(json_data) 接着遍历列表提取数据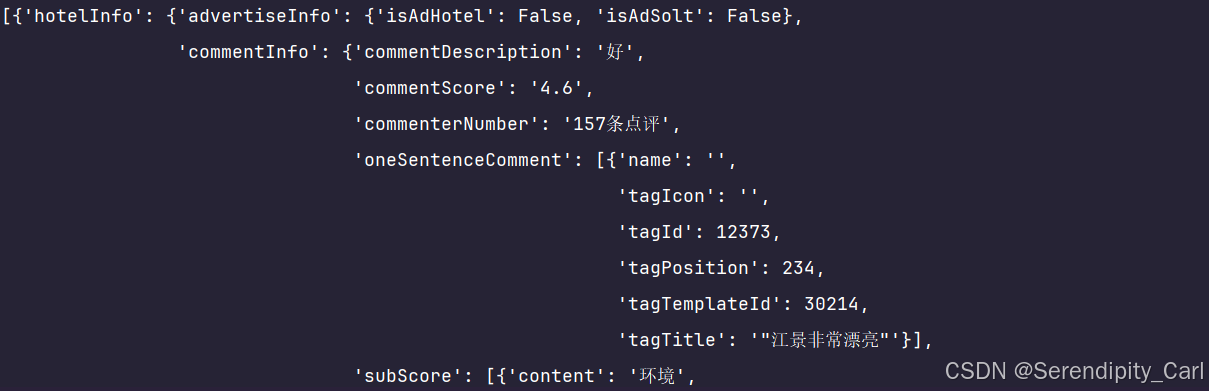
for item in json_data:
name = item["hotelInfo"]["nameInfo"]["name"]
address = item["hotelInfo"]["positionInfo"]["address"]
position_detail = item["hotelInfo"]["positionInfo"]["positionDesc"]
price = item["roomInfo"][0]["priceInfo"]["price"]
room_intro = item["roomInfo"][0]["summary"]["physicsName"]
judge = item["hotelInfo"]["commentInfo"]["commentDescription"]
score = item["hotelInfo"]["commentInfo"]["commentScore"]
# 处理成纯数字内容 转换成字符串 进行替换
comment = ''.join(item["hotelInfo"]["commentInfo"]["commenterNumber"]).replace('条点评','')
# 同样的 将字符串两边的""去掉
tag_info = ''.join(item["hotelInfo"]["commentInfo"]["oneSentenceComment"][0]["tagTitle"]).replace('"','').replace('"','')
room_img = item["hotelInfo"]["hotelImages"]["multiImgs"][0]["url"]
print(name, address, position_detail, price, room_intro, judge, score, comment, tag_info, room_img)
# 酒店名称 地址 位置信息 价格 房间信息 评分 评论人数 标签信息 房间图片 OK 接着我们进行多页数据的分析
在我们复制的data中 有page的信息
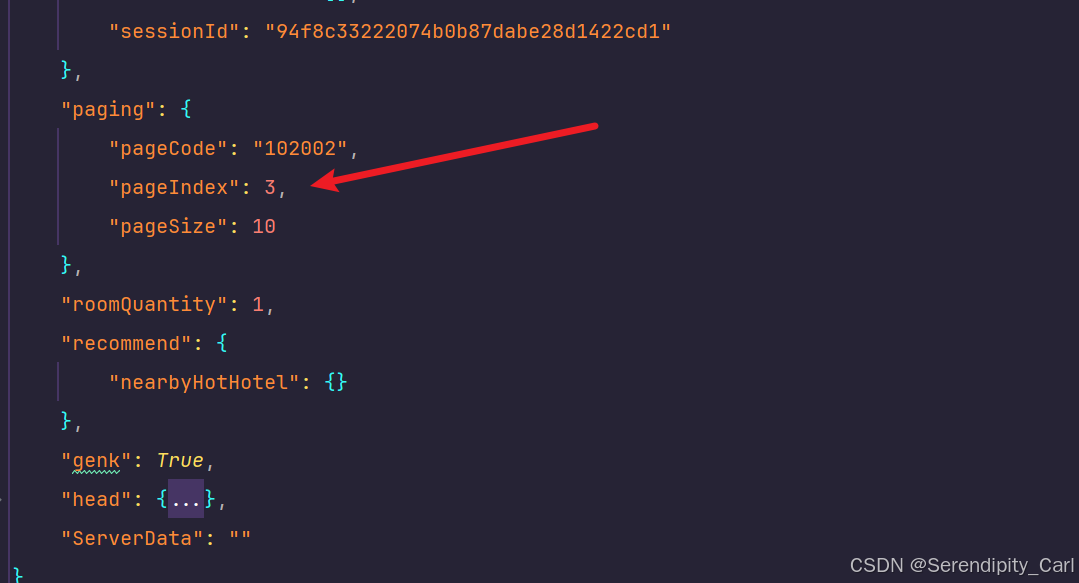
嵌套for循坏进行遍历
OK 最后一步 保存数据到本地
声明一个list变量 将字典数据存入其中 再使用pandas 保存数据
dit = {
'酒店名称': name,
'酒店价格': price,
'酒店地址': address,
'酒店位置': position_detail,
'酒店简介': room_intro,
'酒店评价': judge,
'酒店评分': score,
'酒店评论数': comment,
'酒店标签': tag_info,
'酒店图片': room_img
}
lis.append(dit)
pd.DataFrame(lis).to_excel('hotel_NC.xlsx', index=False)本案例的所有代码如下 仅供学习参考使用
import pprint
import pandas as pd
import requests
import json
lis = []
headers = {
"accept": "application/json",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"cache-control": "no-cache",
"content-type": "application/json;charset=UTF-8",
"origin": "https://hotels.ctrip.com",
"p": "72635442529",
"phantom-token": "1001-common-4STxP4iZ9r7Fy3meLMRSlw7Pvl4RFLWp8jzovfHyo3EcMvsDJqhyBowtNjZsw7BwG3yGMEphJLtENFJB9Y57Razw1UvBArhBwFgEBGJ3pjLQY7j8Oy5YmUyXLWoPxo6RZ1ygSiB8w4SR9lwhoRnFJgOwsMJPpJm4J86JLcvchRFHJ4Y7jdXEdMxFBypZxODvfYz3vTMyPzySNRcmyfMizMwGFRmTwgbRtsYdoRp6EsajA8R8zwUzISfJa9v3Ui1FYtHy5UiDmWkti0dxL4idAWpdJDSvQgY8HynYp9KgAvclwONyZcJ83jnzYa8EzOyFHEoqvGlemqwo6Y3bW81wfoeQmE8qYdbYZtvqzeb9EzpEt6wp3j3LeO4JFhJsfvNBw0kjmDi4UJZ7jUpvcdJFqJPMYMfKHqWdbYmY3zKgzwp3W5LvBpEUmYkmwlnRNDJ1BYl1w5DRk6e3HeAY1cylSW6BjzcYHMEAwSlJB1rHYf8rA5iPLJolv4teZfYZDiFcYgHi6kwa7W5Y35waSEBvPUez6Ef1jsgWDOElaySHv8YFHRflWkaInSrhsKZaePUEOmWlti6bx4SxLY30KGvBUwc7RpMEHPEO0WktedAvf5wQmWZTEBdEcowLYGvqmIqNekqRcPEoNEfPWdSe15vPcR9dYhBeOnxlF",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://hotels.ctrip.com/",
"sec-ch-ua": "\"Microsoft Edge\";v=\"131\", \"Chromium\";v=\"131\", \"Not_A Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-site",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0"
}
cookies = {
"Hm_lvt_a8d6737197d542432f4ff4abc6e06384": "1736161214",
"HMACCOUNT": "854F1C3BF9A50568",
"UBT_VID": "1736161214816.bf32solBg3Nb",
"_ga": "GA1.1.994751676.1736161216",
"GUID": "09031155413732186261",
"Session": "smartlinkcode=U130727&smartlinklanguage=zh&SmartLinkKeyWord=&SmartLinkQuary=&SmartLinkHost=",
"Union": "AllianceID=4902&SID=130727&OUID=&createtime=1736161216&Expires=1736766016357",
"MKT_CKID": "1736161216505.rpp1y.aelc",
"_RF1": "2409%3A8950%3A4d8%3A32e9%3Ad0bc%3Ab8e0%3A56a0%3A1e25",
"_RSG": "4o4r2azo8N6EdzTEU9Lw19",
"_RDG": "280a887e0cf61126a10006b420979017e9",
"_RGUID": "65c8cbd9-02d4-4c84-907a-54978e77d9ce",
"MKT_Pagesource": "PC",
"Hm_lpvt_a8d6737197d542432f4ff4abc6e06384": "1736161245",
"manualclose": "1",
"ibulanguage": "CN",
"ibulocale": "zh_cn",
"cookiePricesDisplayed": "CNY",
"_ga_5DVRDQD429": "GS1.1.1736161216.1.1.1736161294.0.0.0",
"_ga_B77BES1Z8Z": "GS1.1.1736161216.1.1.1736161294.60.0.0",
"_ga_9BZF483VNQ": "GS1.1.1736161215.1.1.1736161294.0.0.0",
"librauuid": "",
"qrcode": "fc10f687e5e1477fa5a6809a45600fde",
"cticket": "7E9BA2C8AB48FF2758F6BE0F0D045004E880DA3D86239A23E83BD8CDA10BF7D1",
"login_type": "0",
"login_uid": "91A6FD6EEC235407DF67EFB8FD43C2AB",
"DUID": "u=91A6FD6EEC235407DF67EFB8FD43C2AB&v=0",
"IsNonUser": "F",
"AHeadUserInfo": "VipGrade=0&VipGradeName=%C6%D5%CD%A8%BB%E1%D4%B1&UserName=&NoReadMessageCount=0",
"_bfa": "1.1736161214816.bf32solBg3Nb.1.1736161410465.1736161541762.1.7.102002",
"_jzqco": "%7C%7C%7C%7C1736161217004%7C1.2116632704.1736161216486.1736161411272.1736161543847.1736161411272.1736161543847.0.0.0.7.7"
}
url = "https://m.ctrip.com/restapi/soa2/31454/json/fetchHotelList"
for page in range(1, 11):
data = {
"hotelIdFilter": {
"hotelAldyShown": [
"108810813",
"3000934",
"120041506",
"116555822",
"125267693",
"122917811",
"125224948",
"21908844",
"86161845",
"106273549",
"121946765",
"1502123",
"124000681",
"1989371",
"5234820",
"2302810",
"71499046",
"53573946",
"18068125",
"116711492",
"125230623",
"70529466",
"70438642",
"48474645"
]
},
"destination": {
"type": 1,
"geo": {
"cityId": 376,
"countryId": 1
},
"keyword": {
"word": ""
}
},
"date": {
"dateType": 1,
"dateInfo": {
"checkInDate": "20250106",
"checkOutDate": "20250107"
}
},
"filters": [
{
"filterId": "17|1",
"type": "17",
"subType": "2",
"value": "1"
},
{
"filterId": "29|1",
"type": "29",
"value": "1|1",
"subType": "2"
}
],
"extraFilter": {
"childInfoItems": [],
"sessionId": "94f8c33222074b0b87dabe28d1422cd1"
},
"paging": {
"pageCode": "102002",
"pageIndex": page,
"pageSize": 10
},
"roomQuantity": 1,
"recommend": {
"nearbyHotHotel": {}
},
"genk": True,
"head": {
"platform": "PC",
"cid": "09031155413732186261",
"cver": "hotels",
"bu": "HBU",
"group": "ctrip",
"aid": "4902",
"sid": "130727",
"ouid": "",
"locale": "zh-CN",
"timezone": "8",
"currency": "CNY",
"pageId": "102002",
"vid": "1736161214816.bf32solBg3Nb",
"guid": "09031155413732186261",
"isSSR": False
},
"ServerData": ""
}
data = json.dumps(data, separators=(',', ':'))
response = requests.post(url, headers=headers, cookies=cookies, data=data).json()
json_data = response['data']['hotelList']
for item in json_data:
name = item["hotelInfo"]["nameInfo"]["name"]
address = item["hotelInfo"]["positionInfo"]["address"]
position_detail = item["hotelInfo"]["positionInfo"]["positionDesc"]
price = item["roomInfo"][0]["priceInfo"]["price"]
room_intro = item["roomInfo"][0]["summary"]["physicsName"]
judge = item["hotelInfo"]["commentInfo"]["commentDescription"]
score = item["hotelInfo"]["commentInfo"]["commentScore"]
comment = ''.join(item["hotelInfo"]["commentInfo"]["commenterNumber"]).replace('条点评', '')
tag_info = ''.join(item["hotelInfo"]["commentInfo"]["oneSentenceComment"][0]["tagTitle"]).replace('"',
'').replace(
'"', '')
room_img = item["hotelInfo"]["hotelImages"]["multiImgs"][0]["url"]
dit = {
'酒店名称': name,
'酒店价格': price,
'酒店地址': address,
'酒店位置': position_detail,
'酒店简介': room_intro,
'酒店评价': judge,
'酒店评分': score,
'酒店评论数': comment,
'酒店标签': tag_info,
'酒店图片': room_img
}
lis.append(dit)
pd.DataFrame(lis).to_excel('hotel_NC.xlsx', index=False)
运行查看我们所保存的数据
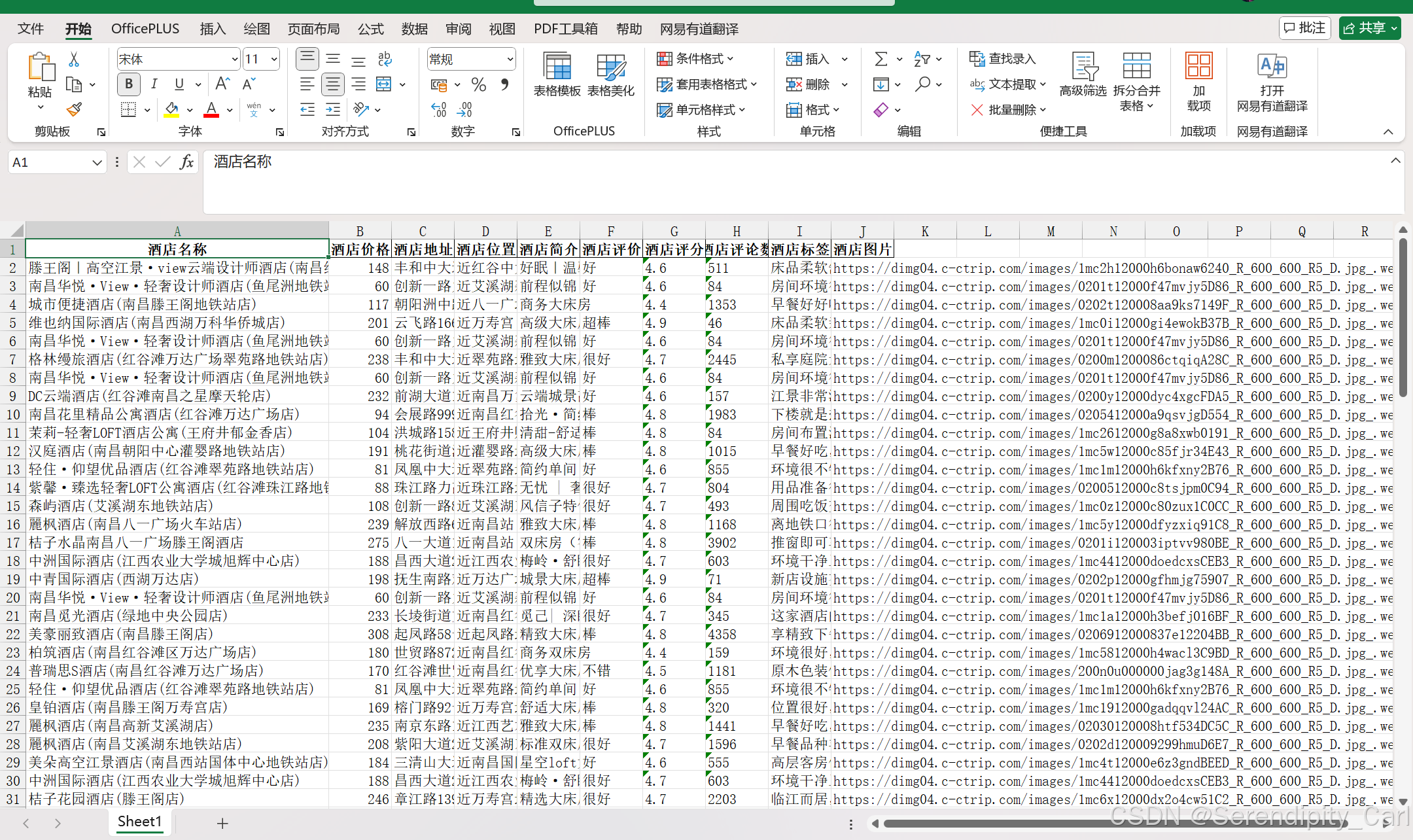
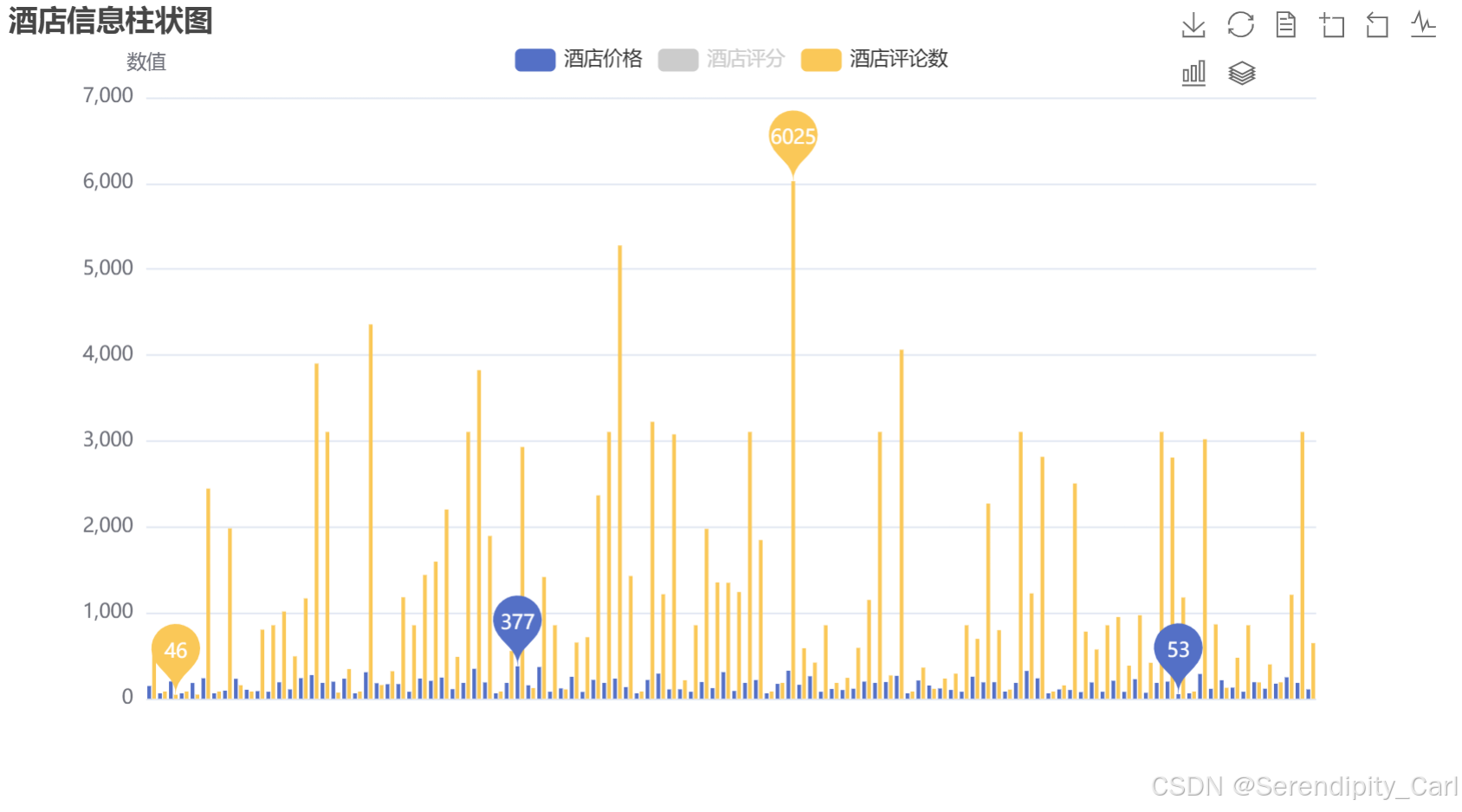
数据可视化
- 为了可视化的数据更加地美观 我们需要做一些配置改变
- 底下的酒店名称就不要显示了 这样显得很乱
- 每个柱状图的数值也不要显示了 只显示最大最小值
- 然后鼠标放上去对应的酒店名称和数据会自动出来
#导包
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Line,Bar
df = pd.read_excel('hotel_NC.xlsx')
# 创建一个柱状图对象
bar = (
Bar()
.add_xaxis(df['酒店名称'].tolist())
# 只显示 数值的最大值与最小值
.add_yaxis("酒店价格", df['酒店价格'].tolist(),markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_='max', name="最大值" ),
opts.MarkPointItem(type_='min', name="最小值")
]))
.add_yaxis("酒店评分", df['酒店评分'].tolist(),markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_='max', name="最大值" ),
opts.MarkPointItem(type_='min', name="最小值")
]))
.add_yaxis("酒店评论数", df['酒店评论数'].tolist(),markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_='max', name="最大值" ),
opts.MarkPointItem(type_='min', name="最小值")
]))
.set_global_opts(
title_opts=opts.TitleOpts(title="酒店信息柱状图"),
xaxis_opts=opts.AxisOpts(name="酒店名称", axislabel_opts={"rotate": 45},is_show=False),
yaxis_opts=opts.AxisOpts(name="数值"),
toolbox_opts=opts.ToolboxOpts(is_show=True),
legend_opts=opts.LegendOpts(pos_top="5%",is_show=True)
)
# 将每个柱状图的数据隐藏
.set_series_opts(label_opts=opts.LegendOpts(is_show=False))
)
# 渲染图表并保存为 HTML 文件
bar.render("hotel_bar_chart.html")效果展示
本次的案列分享就到此结束 感谢大家的观看 您的点赞和关注是我更新的动力



















 1829
1829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











