






目录
一.指针基础概念
指针是什么?
指针理解的2个要点:
1.指针是内存中一个最小单元的编号,也就是地址
2.平时口语中说的指针,通常指的是指针变量,是用来存放内存地址的变量
总结:指针就是地址,口语说的指针通常是指针变量的缩写,不要混为一谈
具体讲解:
由于内存很大(8G、16G、32G……),因此计算机将其划分成了一个个内存单元 - 1byte(字节)
为了方便找到所需的内存单元,计算机给每个内存单元进行编号,而内存单元的编号即为地址,地址也叫指针
联想记忆:
一家五星级酒店,每个房间的住户在不同时间段姓氏不同,因此要通过顾客来寻找某间房间不容易,因此给每个房间安上了一个门牌号(编号),这个门牌号即为房间地址(指针)
假设有一个整型变量a,那我们在取地址时,取的是其首地址的地址
这是因为整型变量总共占了四个字节,给了连续的四个编号,但是取地址时只会取第一个内存单元的编号
联想记忆:
还是那家五星级酒店,一个旅游团(大小根据不同类型的字节大小来定)来住酒店,每个人单独一间房且相邻而居,那么在导游去找这个旅游团时,只要找到离他最近的那间房间地址(门牌号),其余的房间地址就都知道了
int a = 10;
int* pa = &a;上面的代码中,pa即为指针变量,用来存放a的地址,而通过这个地址,就可以找到一个内存单元
注:
1.本质上指针就是地址
2.口语中说的指针,其实就是指针变量,指针变量就是一个变量,指针变量是用来存放地址的一个变量
3.给指针变量重新赋值以后,a的值也相应改变;同理,a的值改变了,指针变量的值也就相应改变了
联想记忆:
一个指针变量(指针)就是酒店房间登记册的某几页,该变量具体记录(指向)了某个房间门牌号(内存单元地址);里面的顾客是由酒店前台来安排的(给指针变量,即某一内存单元地址赋值),(4字节、8字节的不同情况上文已经讲解过),在重新安排住户后(重新赋值),由于需要再次进行编译,所以赋完的值存放的地址也改变了。而指针大小(后续会讲)就决定了页数的多少,这取决于登记册(X86、X64)的不同,一本册子大一点,用的页数少(4字节),一本册子小一点,用的页数多(8字节)
注:请勿将指针大小和指针所指向的空间大小混为一谈,两者不是一个东西
二.指针和指针类型
通过上述介绍,相信大家对指针、指针变量有了大致的了解,可是地址又是如何产生的呢?
对于32位的机器,假设有32根地址线,那么假设每根地址线在寻址的时候产生高电平(高电压)和低电平(低电压)就是(1或者0);
那么32根地址线产生的地址就会是:
00000000 00000000 00000000 00000000(32个0)
00000000 00000000 00000000 00000001
00000000 00000000 00000000 00000010
00000000 00000000 00000000 00000011
……(以此类推)
11111111 11111111 11111111 11111111(32个1)
这里就有2^32个地址
每个地址标识一个字节,那我们就可以给 (2^32Byte == 2^32/1024kB == 2^32/1024/1024MB == 2^32/1024/1024/1024Gb == 4GB) 4G的空闲进行编址
同样的方法,那64位机器,如果给64根地址线,那能编址多大空间,请读者自行计算(结果是16GB)
这里我们就明白:
1.在32位的机器上,如果是32个0或者1组成二进制序列,那地址就得用4个字节的空间来存储,所以一个指针变量的大小就应该是4个字节
2.那如果是在64位机器上,如果有64个地址线,那一个指针变量的大小是8个字节,才能存放一个地址
3.X86 - 32位的环境 X64 - 64位的环境
4.指针大小是4个字节或者8个字节,指针所指向的空间可以是1个字节、4个字节、8个字节等等
5.指针大小的输入输出类型是%zu,一般都与sizeof()函数搭配使用
注:
进行不同指针类型(如int* 和char*) 的强制转换后,指针类型决定了指针在被解引用的时候访问几个字节
如果是int* 的指针,解引用访问4个字节(在内存中存放的是44 33 22 11)
如果是char* 的指针,解引用访问1个字节(假设赋了0值,如果依然还是int*型,那么即为00 00 00 00;如果是char*型,那么即为00 33 22 11)
推广到其他类型,double* 、 float*等等
int main()
{
int a;
int* pa = &a;
char* pc = (char*)&a; //pa = pc = 006FF9F8(pa、pc所指向的地址都是a变量所在地址,因此即是指针类型不同,指向地址相同)
printf("pa = %p", pa); //pa = 006FF9F8
printf("pa+1 = %p", pa+1); //pa+1 = 006FF9FC
printf("pc = %p", pc); //pc = 006FF9F8
printf("pc+1 = %p", pc); //pc = 006FF9F9
}
//请注意,每次编译以后计算机分配的地址都是不同的,因此读者在自己尝试该代码时,指针变量所指向地址会有所差异上述代码解释:
指针变量所指向的空间对应的输入输出类型应该是%p,而指针的类型决定了指针 +- 的时候,跳过几个字节(步长)
并且,int*(4字节)和float*(4字节)不能通用,除了不能通用外, +- 时的效果等都是相同的
原因:计算机中,浮点数的存储方式与整数的存储方式是不同的。因此如果pa是个实型,且pa = 100,那么在计算机中与int*型可以通用;可如果pa = 100.0,那么在计算机中就与int*型不通用了
三.野指针介绍
概念:野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
野指针的可能成因:
1.指针没有初始化
原因:*p没有初始化,就意味着没有明确的方向;一个局部变量不初始化的话,放的是随机值:0xccccccc,即非法访问内存,这种被称为野指针
2.指针越界访问
int main()
{
int arr[10] = { 0 };
int* p = arr; //&arr[0]
int i = 0;
for (i = 0; i <= 11; i++)
{
//数组最多存放10个数,循环语句总共要存放12个数
*(p++) = i; //当指针指向的范围超出数组arr的范围时,p就是野指针
}
return 0;
}3.指针指向的空间释放
int* test()
{
int a = 10; //函数调用时创建a
return &a; //将a的地址返回到 p 中去
}
int main()
{
int* p = test(); //test()函数返回了a的地址,同时 p 接受了test()函数传来的地址
return 0;
}上述代码当中,a是局部变量,出了test()函数自动销毁(即将这部分空间还给操作系统了),可是p还保存了原来 a 的地址,此时 p 能找到他保存的地址空间,但却不能使用与访问
动态内存管理详细讲解(重要):
四.规避野指针的办法
1.指针初始化
2.小心指针越界
3.指针指向空间释放后即刻置NULL
4.避免返回局部变量的地址
5.指针使用之前检查有效性
五.指针运算
++和--运算符:
float values[5];
float* vp;
for (*vp = &values[0]; vp < &values[5];)
{
*vp++ = 0;
}如上代码,for语句当中先是对指针*vp进行了初始化,将values数组的首地址传给了vp(传的是首地址左边那条线的地址),循环退出条件为指针vp和数组最后一个元素所在位置(最后一个元素所在地址的右边那条线)相比较,当指针vp越界以后结束循环;而后置++先是使用指针*vp,对每个空间赋0(赋值是对指针所指向的那条线右边的空格(即地址)进行的),然后再进行地址+1操作,具体如下
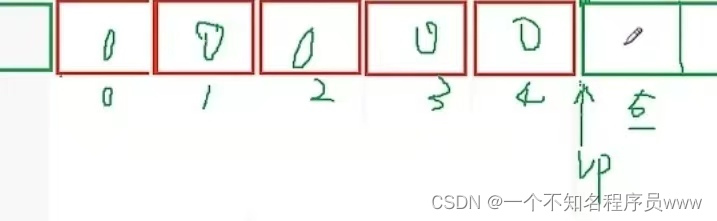
注:红色格子下的数字为假设的地址,0为首地址,4为末地址,上述黑体字指的是计算机编程守则
此处请注意,*vp++ != (*vp)++
原因解释:
首先我们现需要知道 * 和 ++ 是两个作为操作符的存在,他们的操作优先级和结合顺序已在日前详细介绍过
文章链接:操作符汇总
++的优先级高于*,因此应该先计算++,然后再计算*
对于*vp++,++由于是后置++,因此应该是先使用,后++;所以先是*vp,然后vp++,可以看成用++把vp这个地址先取出来,*在此并没有作用,然后进行了+1操作,所以是vp所指向的地址加了1,而非它所指向的空间数值加1
对于(*vp)++,由于括号的存在,先是*在此起到作用,直接指向了vp指针所指向的空间,++即该空间所存放的内容加了1
而如果想要完成上述操作,也可以使用 -- 操作符
具体代码如下
float values[5];
float* vp;
for (*vp = &values[5]; vp > &values[0];)
{
*--vp = 0;
}与++不同的是,--是需要前置的,如果不前置会影响到数组外的空间,循环退出条件是指针和数组首元素的左边那条线进行比较,讲解此处省略
实际在绝大部分的编译器上是可以完成任务的,然而我们还是需要避免这样写,因为标准并不保证它可以运行,标准规定:
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较(即指向数组的指针和数组最后一个元素所在地址的右边那条线进行比较,允许指向数组的指针向后越界还能进行比较),但是不允许与指向第一个元素之前的那个内存位置的指针进行比较(即指向数组的指针和数组首元素所在地址的左边那条线进行比较,但不允许指向数组的指针向前越界还能进行比较)
指针相减:
int main()
{
int arr[10] = { 0 };
printf("%d\n", &arr[9] - &arr[0]);
return 0;
}上述代码结果为9,指针相减的结果是指针和指针之间元素个数
同时,不是所有的指针都能相减,指向同一块空间的2个指针才能相减
存在一个 char* ch[10] 以及一个 int* arr[10]
如果想用arr[10] - ch[5] ,此时程序会报错
例题:请使用指针相减的方法计算“abc”的字符个数
#include<stdio.h>
int my_strlen(char* str) //字符串可以看成一个字符的数组,数组传参时传的是首地址
{
char* start = str; //start = 首地址
while (*str != '\0')
{
str++; //退出循环时,str已经指向了末地址
}
return (str - start);
}
int main()
{
int len = my_strlen("abc");
printf("%d", len);
return 0;
}讲解已在批注中体现,此处省略
六.指针和数组
数组即是地址的集合(这也是数组名传参传递的是数组首元素地址的原因)
int arr[10] = 0;
int* p = arr; //arr是首元素的地址,即&arr[0],这便是通过指针来访问数组
//假设有个i(i<=9 || i>=0 ),那么满足下列等式
arr[i] = *(p+i) = *(arr+i)
同时,也并非所有情况下,数组名就是数组首元素地址,下面介绍两种特殊情况:
1.sizeof(数组名)
#include<stdio.h>
int main()
{
int arr[10] = { 0 };
printf("%d", sizeof(arr));
return 0;
}上述结果为40,1个整型数据的字节大小为4字节,因此4*10 = 40,sizeof(数组名)指的是整个数组所有元素加起来的大小
2.&数组名:
对数组名取地址所产生的值的类型是一个指向整个数组的指针,而不是一个指向数组某一元素的指针。所以&arr的类型是指向整个数组的指针,而arr是arr[0]的地址
因此,&arr在加1或减1的时候,跨越的地址数量不同
还是以上述代码为例,因为arr存放了10个整型数据,因此arr+1 ,地址加4;*arr + 1,地址加40
指针数组:
概念介绍:
int a = 10;
int b = 20;
int c = 30;
int* parr[10] = { &a,&b,&c };//parr就是存放指针的数组,即指针数组,上述代码中就和一般的一维整型数组中存放了a、b、c三个元素效果相同
int arr1[4] = {1,2,3,4};
int arr2[4] = {2,3,4,5};
int arr3[4] = {3,4,5,6};
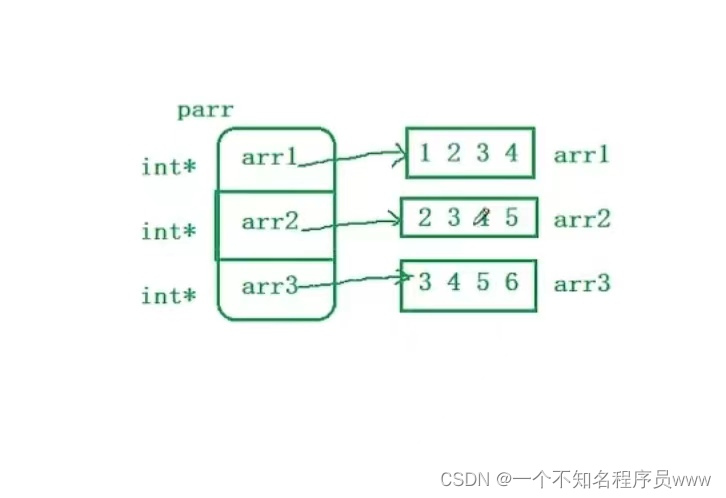
int* parr[3] = { arr1,arr2,arr3 };//上述代码即是和一般二维整型数组中存放了12个元素效果相同,内存存储方式如下图所示
假设有一个数组int (*parr1)[10] ,那为什么不能写成 int *parr1[10]?
前者将*parr划分在一起,因此是指向了整形数据的数组指针,也可以写成&parr1,代表了整个数组的地址
后者应该将int*看成一起的(后文有讲解),因此是指向整型指针变量的数组,即整型指针数组,代表了一个数组里存放的全是整型指针
同时还有int (*parr1[10])[5]这种情况:
这种数组是存放了数组指针的数组,以此为例,在内存中的存储如下图所示
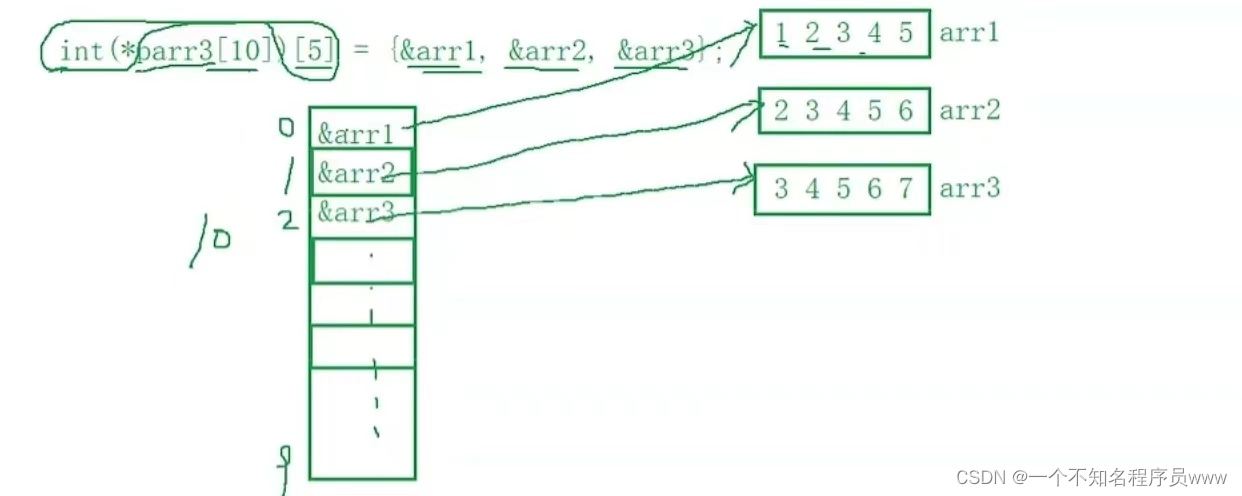
注:本例是假设的,绿色长方形旁的数字指的是数组下标,讲解此处略,详见B站鹏哥C语言
而对于指针数组,我们也可以有二维数组的形式,即可以将 arr[i][j] 看成 *(parr[i] + j)
七.指针和数组传参
我们在编写代码时,难免会遇到函数需要使用到指针或者数组,因此本单元会详细介绍这两者的传参和自函数的接收
函数传参定则:形参、实参类型一致即可
数组和指针数组的传参:
数组名在传参时传的是数组首地址的元素,因此指针数组名传的是所有元素中的第一个指针;同时如果想要传输非首元素的地址,可以传参时是arr[具体下标],然后用一个整型变量int x接收。但这种情况下传递的不再是数组的地址,而是数组某一特定地址的值(类似于将指针解引用)
对于数组,函数的接收方式可以有以下三种:
1.int arr[ ] //按照上述定则,易知形参为数组
2.int arr[10] //形参数组可以不指定大小,在定义数组时在数组后加个空的方括号
3.int* arr //数组是指针常量的集合,因此也可用指针来接收
对于指针数组,函数的接收方式有以下三种:
1.int* arr[20] 2.int* arr[ ]
3.int** arr //指针数组即为指向指针的指针常量的集合,因此可以看成二级指针
二维数组传参定则:二维数组传参,函数形参的设计只能省略行,不能省略列,因为对一个二维数组而言,可以不知道有多少行,但是必须要知道有多少列
二维数组传参:
假设一个二维数组int arr[3][5] = {0},传参时传数组名arr
则根据上述两条定则,函数共有以下三种接收方式:
1.int arr[3][5]
2.int arr[ ][5]
3.int (*arr)[5] //
//二维数组的数组名表示首元素的地址,其实是第一行的地址,而第一行是一个长度为5的一维数组
//因此函数接收时不能用int* arr 或 int*arr[5] 或 int** arr
一级指针传参:
定义int* ptr = &a; int arr[10]
那么传参时既可以是 ptr 也可以是 arr 或者 &a
函数在接收时,应该是int* p
二级指针传参:
函数接收时,应该是int** p
那么传参时,就可以是** p2,&(*p),int* arr[10] 的数组名
八.二级指针
概念介绍:二级指针变量是用来存放一级指针变量地址的
int main()
{
int a = 10;
int* pa = &a;//pa是一个指针变量,一级指针变量
int** ppa = &pa;//ppa是一个二级指针变量
return 0;
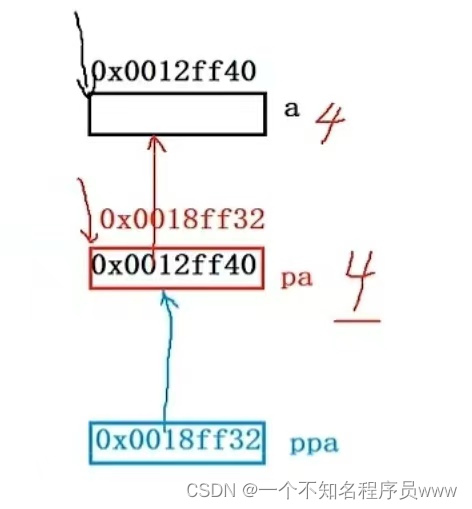
}假设a的地址为0x0012ff40,pa指向该地址;但由于pa作为指针变量也需要空间去存放,因此会开辟4或8字节(上文已讲解过)存放,假设pa的地址为0x0012ff32;ppa同理,指向该地址,并会有个空间存放,如下图所示
int** pa拆分详解:
int*是说明ppa指向的对象是int*类型
*ppa是说明ppa是个指针
九. 函数指针
类比记忆法:
数组指针是指向数组的指针,而函数指针就是指向函数的指针
函数也有它的地址,因此 &函数名 取出的即是函数地址,在对函数取地址时,可以简写为函数名
函数指针接收方法:
int (*pf)(int, int) = &数组名
指针后的括号指的是函数指针的参数(只需要交代类型即可),*pf说明pf是个指针,前面的int说明函数指针返回的内容为整型
那么函数指针究竟有什么作用呢?
答:假如有个Add函数,完成了加法的操作,那么如果 int (*pf)(int, int) = &Add,则 (*pf)(2, 3) = Add(2, 3),pf前的 * 数量可以随意,想要几个就写几个,0个也可以
函数指针的使用让我们得以将两个函数更加紧密地联系起来,例如void 函数名(int (*pf)(int, int)),我们就可以在一个自定义函数中使用另一个自定义函数
( *( void (*)() )0 )()
上述代码解释:
void(*p)(),p是函数指针;void(*)()是函数指针类型,就像是int*,char*一样
0是个int类型数据,假设0存放在了0x0012ff40这个地址处,前面的( void (*)() )是在进行强制类型转换,把0强制转换成无参,返回类型为void的函数地址,前面的*是指调用0x0012ff40处的函数,可以想象成(*0x0012ff40)()
因此上述代码是一次函数调用,调用的是0作为地址处的函数
函数指针数组(转移表):
函数指针也是指针,把函数指针放在数组中,其实就是函数指针数组
假如要在函数指针数组中存入4个函数,那么写法如下:
int (*arr[4])(int, int) = {Add, Sub, Mul, Div}
注:存入的都需要是 int(*p)(int, int) 型的函数指针
作用:
可以将计算器中的众多功能计算简化成几条代码,有效解决了代码冗余的问题;然后可以将这种思想延申到各种各样的多任务解决中去。它提供了跳转到某个函数的功能,因以也被叫做转移表。
指向函数指针数组的指针:
无限套娃(笑)
写法:
假设有一个函数指针,int (*prArr[ ])(int, int),则指向该函数指针数组的指针应该为:
int(*(*ppfArr[ ])(int, int) = &pfArr
用得很少,了解即可
函数概念小贴士:
1.函数只要写好了就有地址
2.函数指针也是一个指针,大小为4字节或8字节
3.当出现了极其复杂的表达式,例如 void(*signal(int,void(*)(int)))(int),可以把void(*)(int)类型重命名为pf_t(随意,怎么简单怎么来),最后就改成了 pf_t(int, pf_t)
4.上述表达式中,signal函数的返回值是指向signal函数的函数指针
十.qsort( )函数

void* base:要排序的数据的起始位置
size_t num:待排序的数据元素个数
size_t width:待排序的数据元素的大小(单位是字节)
int(* cmp)(const void* e1, const void* e2):函数指针,完成比较大小功能的函数
qsort函数接收完函数返回值后,会根据正负情况来判断计算方法,正值会进行交换,负和0不进行操作
void* 是无具体类型的指针,可以接受任何类型的地址,因此不能接受解引用操作,也不能+-整数
使用该函数前要引用stdlib.h这个头文件
cmp函数的写法:
1.整型数据:
例如 9876543210,要把它变成 0123456789 (每个数字都是以个位而计,共10个元素)
int cmp_int(const void* e1, const void* e2)
{
return (*(int*)e1 - *(int*)e2); //强制转换}
上述已经提到,比较函数返回决定了qsort函数进行换位操作,因此当出现 0123456789,要把它变成 9876543210,则
int cmp_int(const void* e1, const void* e2)
{
return (*(int*)e2 - *(int*)e1); //降序操作}
2.字符串
假如存在 zhangsan 和 lisi 两个字符串
由于是字符串,所以需要使用strcmp函数,而strcmp函数的返回值与qsort正负判断重合
int cmp_chat(const void* e1, const void* e2)
{
return (strcmp( (char*)e1, (char*)e2));}
这边需要注意的是,字符串与字符串的qsort只会对不同字符串的首字符进行排序,并不会在各个字符串内部再进行排序。
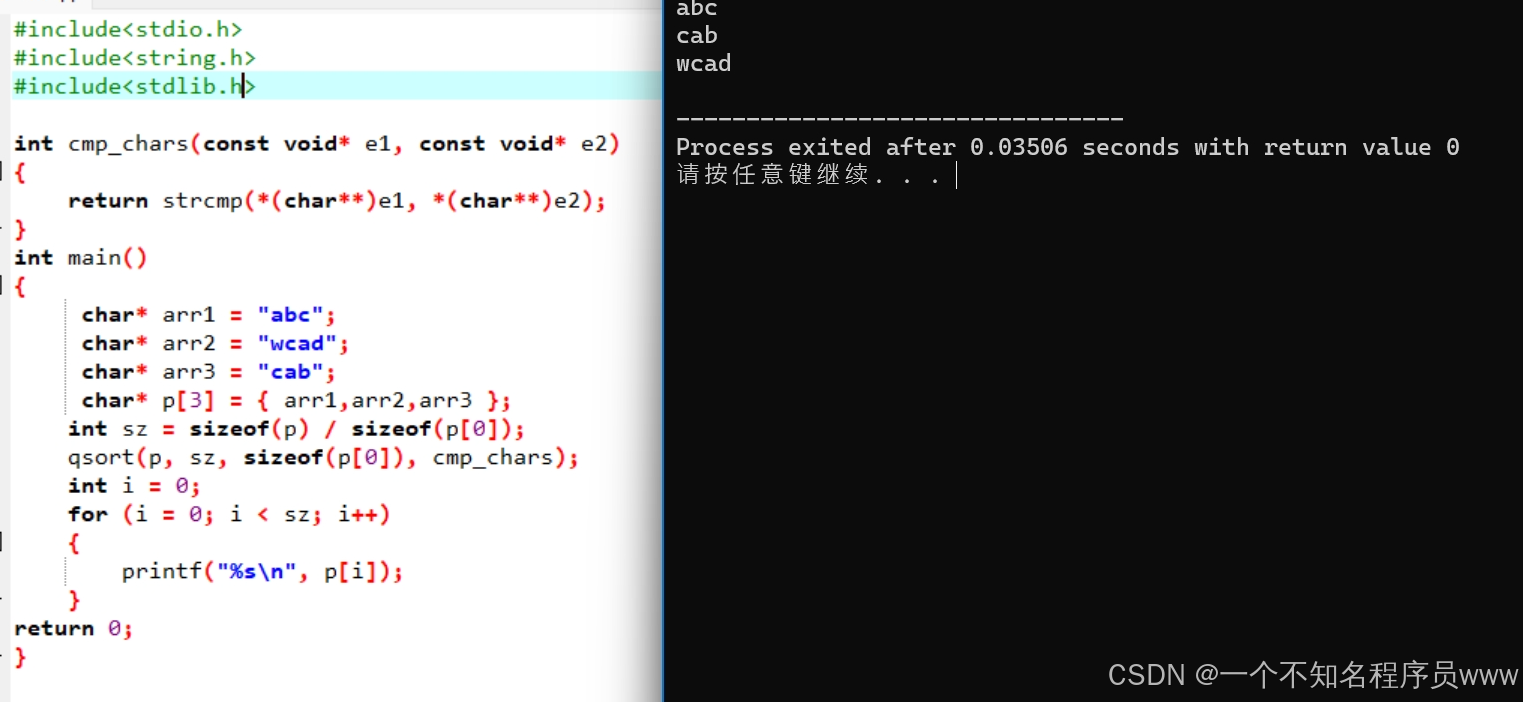
3.字符
一个字符串进行内部的字符排序,所以函数应该是ascii码相减的情况
int cmp_char(const void* e1, const void* e2)
{
return *(char*)e1 - *(char*)e2;
}这种情况才能够完成某一字符串内部的排序,如下图所示
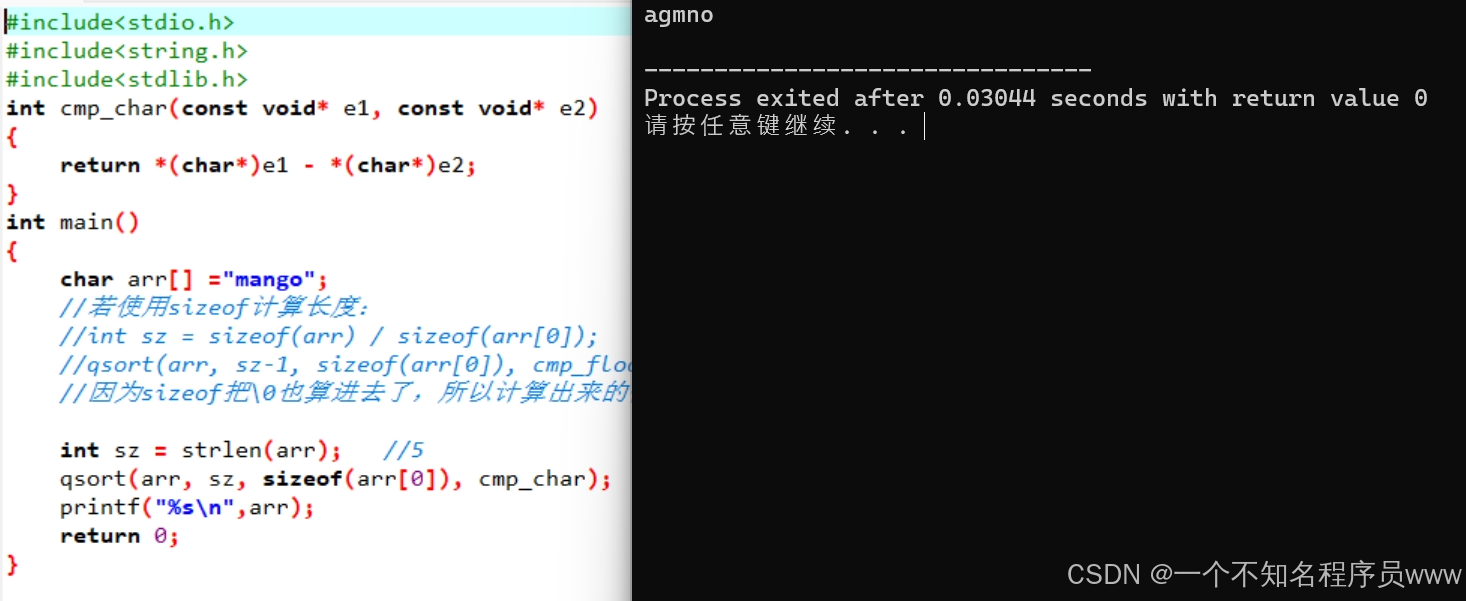
4.结构体
一个结构体里有年龄、名字两项,名字还是以字符串讲解中出现的名字为例
struct Stu
{
char name[20]; //存入zhangsan,lisi
int age;
}
int cmp_struct(const void* e1, const void* e2)
{
return strcmp( ( (struct Stu*)e1) -> name, ( (struct Stu*)e2) -> name);}
比较年龄就把strcmp改为相减的表达式,结构体的表示方式不变,除将name改为age
qsort函数自我创造方法:
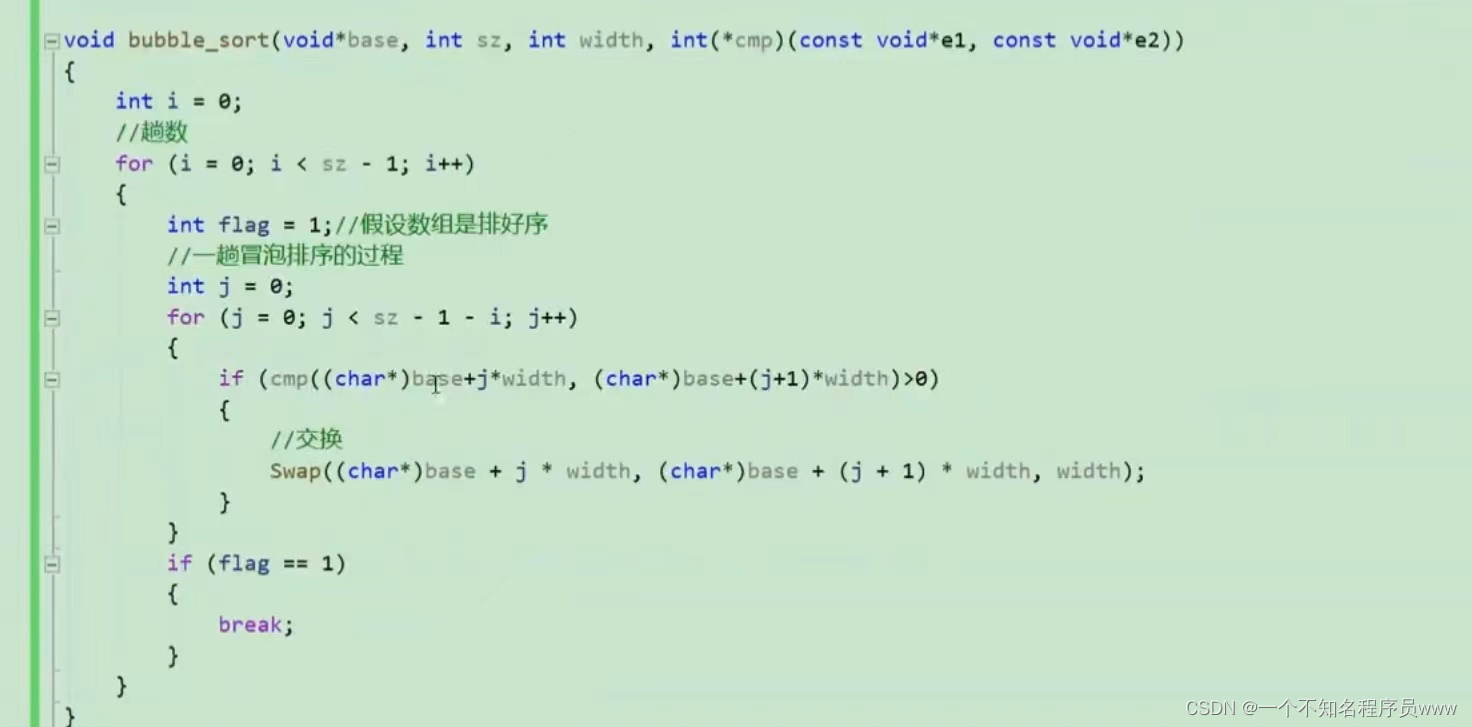

注:第一张图片代码在swap函数后缺少一句 "flag = 0;"
上述代码解释:
由于需要比较的两个函数都是void*,因此需要进行强制转换,由于数据类型不确定,即数据字节大小未知,因此我们可以将数据转换成char* 型,如此它每次的+-只会移动1个字节,width在此也就起到了作用,可以通过元素位置与width相乘,再加上数组首地址,最后进行比较。
此后就要开始交换,交换时接收两个需要交换的元素,由于拿来的是char型,可能需要进行交换的元素是int型,因此需要通过循环,将存放整型数据的四个空间地址一个个交换,同样能实现数据交换的功能。
十一.字符指针
例如 char* p = "abcdef"
这是在把首字符a的地址,赋值给了*p;而在打印指针*p时,会从*p指向的a开始打印,然后打印a之后的元素,直到遇到了 '\0' 停止
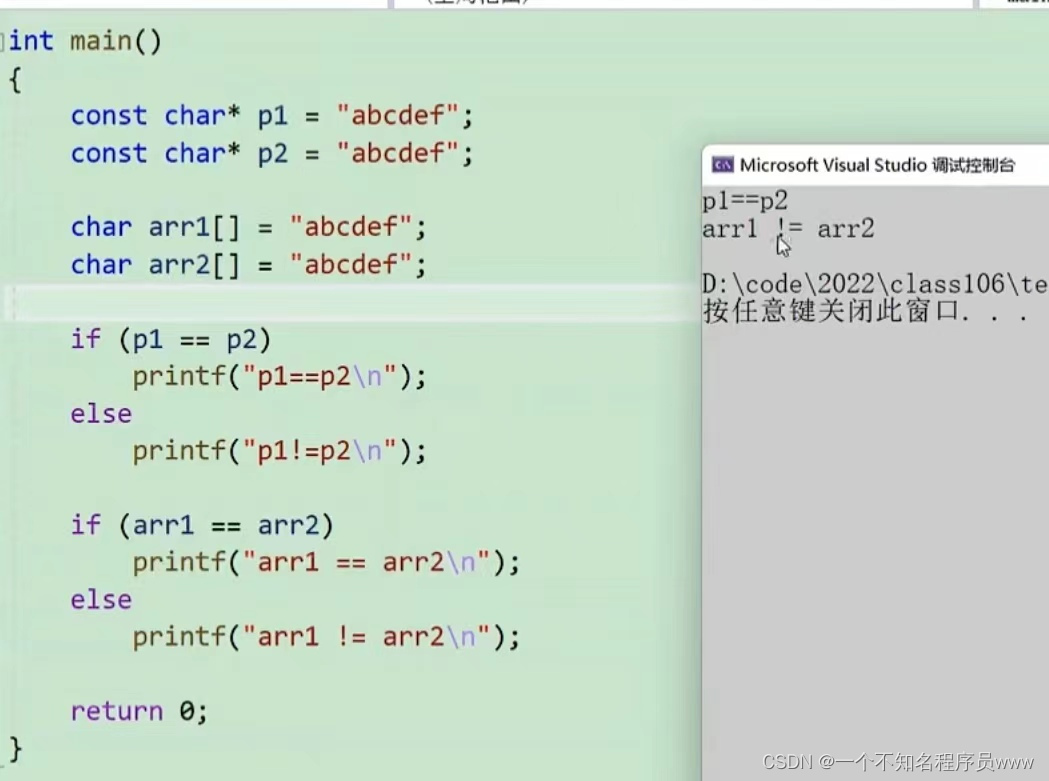
指针p是一个指针,指向了abcdef的a这个元素;arr1[ ]是开辟了一个内存空间,存放了abcdef,arr1是数组首元素;== > < 对于两个字符来说,比较的是ascll码的前后,越前面的越小,越后面的越大
十二.assert断言
assert.h头文件定义了宏assert( ),用于在运行时确保程序符合指定条件,如果不符合,就报错终止运行。这个宏常常被称为“断言”。
assert( )宏接受一个表达式作为参数。如果该表达式为真(返回值为零),assert( )不会产生任何作用,程序继续运行。如果该表达式为假(返回值为零),assert( )就会报错,在标准错误流stderr中写入一条错误信息,显示没有通过的表达式,以及包含这个表达式的文件名和行号。
assert语句的优点:
- 能自动标识文件和出问题的行号。
- 无需更改代码就能开启或关闭assert( )。如果已经确认程序没有问题,不需要再做断言,就在 #include<assert.h> 前,定义一个宏 NDEBUG 。(代码如下所示)
#define NDEBUG
#include <assert.h>assert语句的缺点:
因为引入了额外的检查,增加了程序的运行时间。
因此,我们一般可以在Debug版本中使用assert断言,在Release版本中禁用它。这样在debug版本中有利于程序员排除问题,在release版本中不影响用户使用时的程序效率。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









