






目录
2.IDEA的下载安装(我选择的版本是2019.2.3,建议选择低版本的IDEA)
3.scala的下载(我选择的版本是2.12.15)安装及环境变量的配置
编辑 4.scala插件(版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装
5.maven的下载(我选择的版本是3.5.4)与安装,系统环境变量的配置
Spark编程基础
一.从内存中读取创建RDD
1.parallelize()
parallelizeO方法有两个输人参数,说明如下:
(1)要转化的集合:必须是 Seq集合。Seq 表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
(2)分区数。若不设分区数,则RDD 的分区数默认为该程序分配到的资源的 CPU核心数。

2.makeRDD()
makeRDD0方法有两种使用方式,第一种使用方式与 parallelize0方法一致;第二种方式是通过接收一个 Seq[(T,Seq[String])]参数类型创建 RDD。第二种方式生成的RDD中保存的是T的值,Seq[String]部分的数据会按照 Seqf(T,Seq[String])的顺序存放到各个分区中,一个 Seq[Stringl对应存放至一个分区,并为数据提供位置信息,通过preferredLocations0方法可以根据位置信息查看每一个分区的值。调用 makeRDD0时不可以直接指定 RDD 的分区个数,分区的个数与 Seq[String]参数的个数是保持一致的。

二.从外部存储系统中读取数据创建RDD
1.从外部存储系统中读取数据创建RDD是指直接读取存放在文件系统中的数据文件创建RDD。从内存中读取数据创建 RDD 的方法常用于测试,从外部存储系统中读取数据创建 RDD 才是用于实践操作的常用方法。
2.从外部存储系统中读取数据创建 RDD 的方法可以有很多种数据来源,可通过SparkContext对象的 textFile0方法读取数据集。textFileO方法支持多种类型的数据集,如目录、文本文件、压缩文件和通配符匹配的文件等,并且允许设定分区个数,分别读取 HDFS文件和Linux本地文件的数据并创建 RDD,具体操作如下。
分别读取HDFS文件和Linux本地文件的数据并创建RDD,具体操作如下。
通过HDFS文件创建RDD
直接通过textFile()方法读取HDFS文件的位置即可。
通过Linux本地文件创建RDD
本地文件的读取也是通过sc.textFile("路径")的方法实现的,在路径前面加上“file://”表示从Linux本地文件系统读取。在IntelliJ IDEA开发环境中可以直接读取本地文件;但在spark-shell中,要求在所有节点的相同位置保存该文件才可以读取它.

三.RDD方法归纳
1.使用map()方法转换数据
map()方法是一种基础的RDD转换操作,可以对 RDD 中的每一个数据元素通过某种函数进行转换并返回新的RDD。mapO方法是懒操作,不会立即进行计算。
转换操作是创建RDD的第二种方法,通过转换已有RDD生成新的RDD。因为RDD是一个不可变的集合,所以如果对 RDD 数据进行了某种转换,那么会生成一个新的 RDD。
例如,通过一个存放了5个 Int类型的数据元素的列表创建一个 RDD,可通过 map0方法对每一个元素进行平方运算,结果会生成一个新的RDD,代码如下:

2.使用 sortBy()方法进行排序
sortBy0方法用于对标准RDD 进行排序,有3个可输人参数,说明如下。
(1)第1个参数是一个函数f:(T)=>K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
(2)第2个参数是 ascending,决定排序后 RDD 中的元素是升序的还是降序的,默认是 true,即升序排序,如果需要降序排序则需要将参数的值设置为 false。
(3)第3个参数是numPartitions,决定排序后的RDD 的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即 this.partitions.size。
第一个参数是必须输人的,而后面的两个参数可以不输人。例如,通过一个存放了 3个二元组的列表创建一个 RDD,对元组的第二个值进行降序排序,分区个数设置为1,代码如下

3.使用collect()方法查询数据
collectO方法是一种行动操作,可以将 RDD 中所有元素转换成数组并返回到 Driver 端,适用于返回处理后的少量数据。因为需要从集群各个节点收集数据到本地,经过网络传输,并且加载到 Driver 内存中,所以如果数据量比较大,会给网络传输造成很大的压力。因此,数据量较大时,尽量不使用collectO方法,否则可能导致Driver 端出现内存溢出间题。collectO方法有以下两种操作方式。
(1) collect:直接调用 collect 返回该 RDD 中的所有元素,返回类型是一个 Array[T数组,这是较为常用的一种方式。
(2)collect[U: ClassTag](f: PartialFunction[T, U]):RDD[U]。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。首先定义一个函数one,用于将collect方法得到的数组中数值为1的值替换为“one”,将其他值替换为“other”。
4.使用flatMap()方法转换数据
flatMap()方法将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的RDD。
使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。这个转换操作通常用来切分单词。
例如,分别用 maPO方法和 AatapO方法分制字符串。用 mapO方法分削后,每个元素对应返回一个迷代器,即数组。fatNapO方法在进行同 mapO方法一样的操作后,将3个选代器的元素扁平化(压成同一级别),保存在新 RDD 中,代码如下

5.使用take()方法查询某几个值
take(N)方法用于获取RDD的前N个元素,返回数据为数组。take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。获取RDD的前5个元素,代码如下。

6.使用union()方法合并多个RDD
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。代码如下

7.使用filter()方法进行过滤
filter()方法是一种转换操作,用于过滤RDD中的元素。
filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。
filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
创建一个RDD,并且过滤掉每个元组第二个值小于等于1的元素。代码如下

三.使用简单的集合操作
(1)intersection()方法
intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。创建两个RDD,其中有相同的元素,通过intersection()方法求出两个RDD的交集

(2)subtract()方法
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。两个RDD的顺序会影响结果。创建两个RDD,分别为rdd1和rdd2,包含相同元素和不同元素,通过subtract()方法求rdd1和rdd2彼此的补集。

(3)cartesian()方法
cartesian()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。创建两个RDD,分别有4个元素,通过cartesian()方法求两个RDD的笛卡儿积。

任务实现
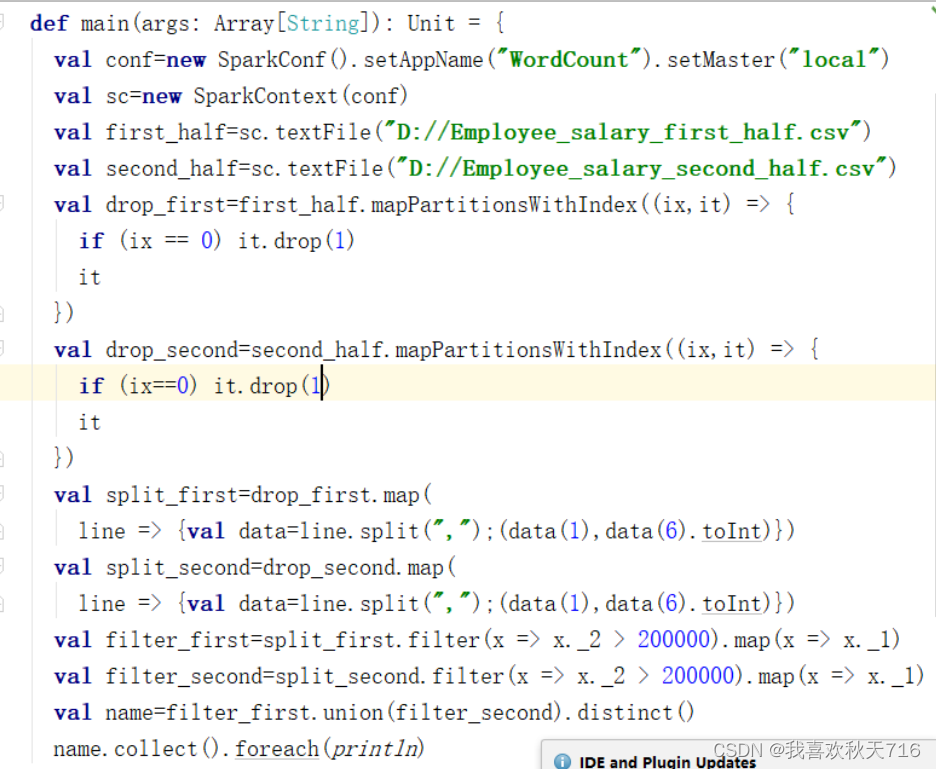
四.RDD
1.了解键值对RDD
Spark的大部分RDD操作都支持所有种类的单值RDD,但是有少部分特殊的操作只能作用于键值对类型的RDD。 顾名思义,键值对RDD由一组组的键值对组成,这些RDD被称为PairRDD。PairRDD提供了并行操作各个键或跨节点重新进行数据分组的操作接口。 例如,PairRDD提供了reduceByKey()方法,可以分别规约每个键对应的数据,还有join()方法,可以把两个RDD中键相同的元素组合在一起,合并为一个RDD。
2.创建键值对RDD
有很多种创建键值对RDD的方式,很多存储键值对的数据格式会在读取时直接返回由其键值对组成的PairRDD。 当需要将一个普通的RDD转化为一个PairRDD时可以使用map函数来进行操作,传递的函数需要返回键值对。

3.使用键值对RDD的keys和values方法
键值对RDD,包含键和值两个部分。
Spark提供了两种方法,分别获取键值对RDD的键和值。 keys方法返回一个仅包含键的RDD。 values方法返回一个仅包含值的RDD。
 4.使用键值对RDD的reduceByKey()方法
4.使用键值对RDD的reduceByKey()方法
(1)当数据集以键值对形式展现时,合并统计键相同的值是很常用的操作。
(2)reduceByKey()方法用于合并具有相同键的值,作用对象是键值对,并且只对每个键的值进行处理,当RDD中有多个键相同的键值对时,则会对每个键对应的值进行处理。
(3)reduceByKey()方法需要接收一个输入函数,键值对RDD相同键的值会根据函数进行合并并且创建一个新的RDD作为返回结果。
(4)在进行处理时,reduceByKey()方法将相同键的前两个值传给输入函数,产生一个新的返回值,新产生的返回值与RDD中相同键的下一个值组成两个元素,再传给输入函数,直到最后每个键只有一个对应的值为止。reduceByKey()方法不是一种行动操作,而是一种转换操作。
 5.使用键值对RDD的groupByKey()方法
5.使用键值对RDD的groupByKey()方法
(1)groupByKey()方法用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作。
(2)对于一个由类型K的键和类型V的值组成的RDD,通过groupByKey()方法得到的RDD类型是[K,Iterable[V]]。

五.使用join()方法连接两个RDD
1.将有键的一组数据与另一组有键的数据根据键进行连接,是对键值对数据常用的操作之一。 与合并不同,连接会对键相同的值进行合并,连接方式多种多样,包含内连接、右外连接、左外连接、全外连接,不同的连接方式需要使用不同的连接方法。
连接方法 如下表。

1.join()方法
join()方法用于根据键对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。 例如,在两个RDD中分别有键值对(K,V)和(K,W),通过join()方法连接会返回(K,(V,W))。 创建两个RDD,含有相同键和不同的键,通过join()方法进行内连接。
 2,rightOuterJoin()方法
2,rightOuterJoin()方法
rightOuterJoin()方法用于根据键对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。 在rightOuterJoin()方法中,如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。

3.leftOuterJoin()方法
leftOuterJoin()方法用于根据键对两个RDD进行左外连接,与rightOuterJoin()方法相反,返回结果保留左边RDD的所有键。

4.fullOuterJoin()方法
fullOuterJoin()方法用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
 5.使用zip()方法组合两个RDD
5.使用zip()方法组合两个RDD
(1)zip()方法用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。
(2)将两个RDD组合成Key/Value形式的RDD,这里要求两个RDD的partition数量以及元素数量都相同,否则会抛出异常。

6.使用combineByKey()方法合并相同键的值
combineByKey()方法是Spark中一个比较核心的高级方法,键值对的其他一些高级方法底层均是使用combineByKey()方法实现的,如groupByKey()方法、reduceByKey()方法等。 combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。 combineByKey()方法的使用方式如下。 combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)
combineByKey()方法接收3个重要的参数,具体说明如下。 createCombiner:V=>C,V是键值对RDD中的值部分,将该值转换为另一种类型的值C,C会作为每一个键的累加器的初始值。 mergeValue:(C,V)=>C,该函数将元素V聚合到之前的元素C(createCombiner)上(这个操作在每个分区内进行)。 mergeCombiners:(C,C)=>C,该函数将两个元素C进行合并(这个操作在不同分区间进行)。
由于合并操作会遍历分区中所有的元素,因此每个元素(这里指的是键值对)的键只有两种情况:以前没出现过或以前出现过。对于这两种情况,3个参数的执行情况描述如下。 如果以前没出现过,则执行的是createCombiner()方法,createCombiner()方法会在新遇到的键对应的累加器中赋予初始值,否则执行mergeValue()方法。 对于已经出现过的键,调用mergeValue()方法进行合并操作,对该键的累加器对应的当前值(C)与新值(V)进行合并。 由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法对各个分区的结果(全是C)进行合并。
7.使用lookup()方法查找指定键的值
lookup(key:K)方法作用于键值对RDD,返回指定键的所有值。

任务实现
查询每位员工2020年的月均实际薪资需要先筛选出上、下半年的员工薪资数据中的员工姓名和实际薪资两个字段数据并创建RDD,然后将筛选后的两个RDD合并,再根据员工姓名对实际薪资求和,最后查询出2020年的每位员工的月均实际薪资,具体实现步骤如下。 获取两个RDD,即split_first和split_second,使用union()方法合并两个RDD。 使用combineByKey()方法计算每位员工2020年的月均实际薪资。
六.读取与存储文件
Spark支持的一些常见文件格式

1.读取与存储JSON文件
(1).JSON文件的读取

(2).JSON文件的存储

2.读取与存储CSV文件
(1)CSV文件的读取
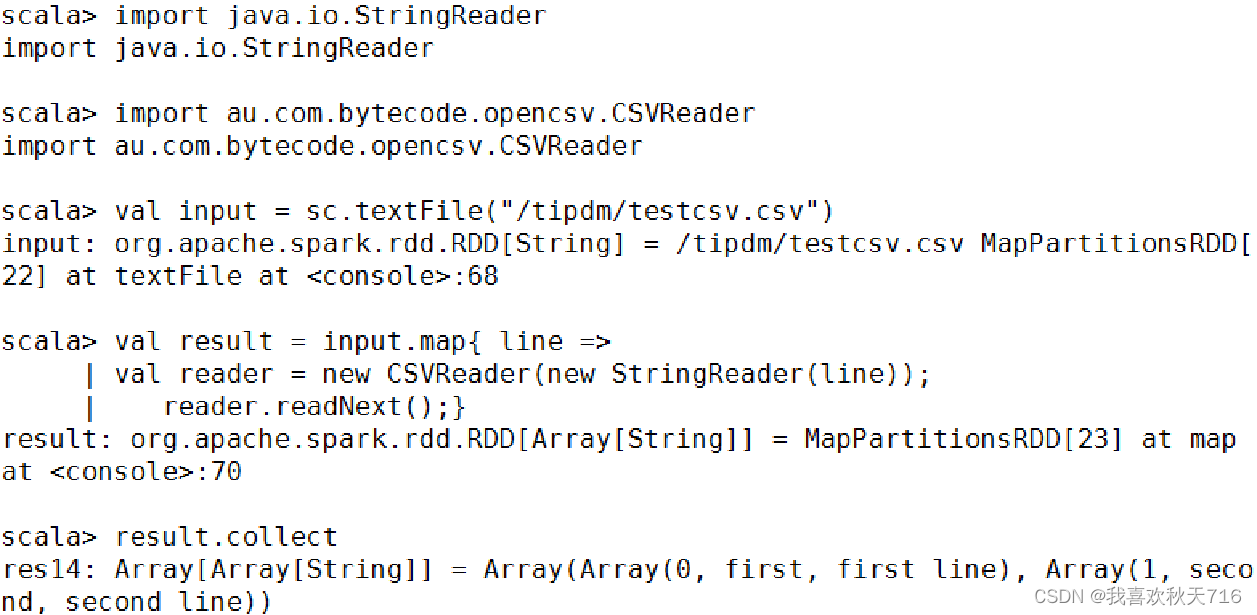

(2)CSV文件的存储
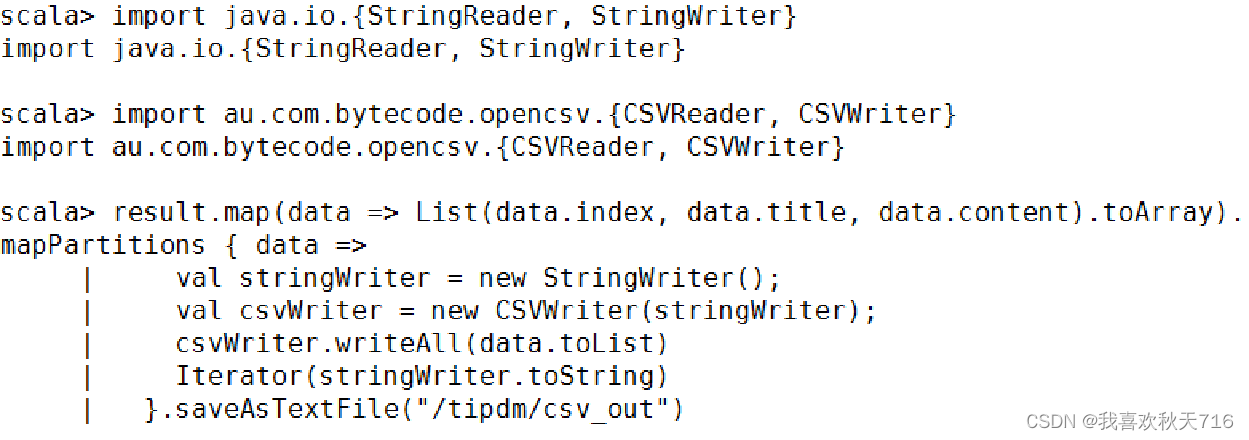
3. 读取与存储SequenceFile文件
(1)SequenceFile文件的存储


(2)SequenceFile文件的读取

4.读取与存储文本文件
(1)文本文件的读取
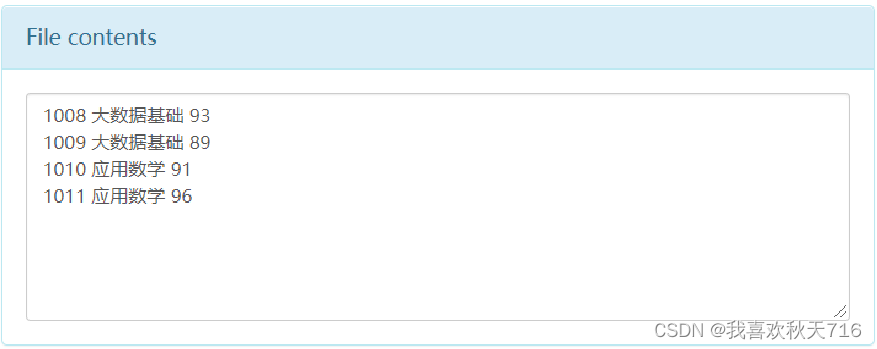
通过textFile()方法即可直接读取,一条记录(一行)作为一个元素。

(2)文本文件的存储
RDD数据可以直接调用saveAsTextFile()方法将数据存储为文本文件。
搭建Spark开发环境
一、相关软件的下载及环境配置
1.jdk的下载安装及环境变量配置
(我选择的版本是jdk8.0(即jdk1.8),建议不要使用太高版本的,不然配置pom.xml容易报错)
链接:https://pan.baidu.com/s/1deXf6pgMiRca1O724fUOxg
提取码:sxuy
双击安装包,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将jdk1.8安装在了D盘目录下的soft文件夹,bin路径如下:
配置环境变量:



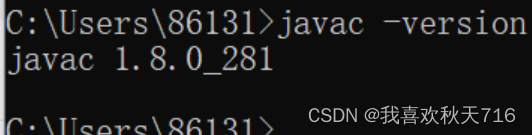
win+R打开命令窗口输入:javac -verison ,进行检测是否成功配置环境变量:
2.IDEA的下载安装(我选择的版本是2019.2.3,建议选择低版本的IDEA)
官网下载地址:IntelliJ IDEA – 领先的 Java 和 Kotlin IDE (jetbrains.com.cn)

3.scala的下载(我选择的版本是2.12.15)安装及环境变量的配置
官网下载地址:The Scala Programming Language (scala-lang.org)

双击打开下载好的安装程序,一直“Next”即可,最好不要安装到C盘,中间修改一下安装路径即可,最后点击“Finish”。我将scala软件安装在了D盘目录下的Develop文件夹,bin路径如下:

配置scala的系统环境变量,将scala安装的bin目录路径加入到系统环境变量path中:

win+R打开命令窗口输入:scala -verison ,进行检测是否成功配置环境变量:
 4.scala插件(版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装
4.scala插件(版本要与IDEA版本保持一致,下载2019.2.3版本)的下载安装
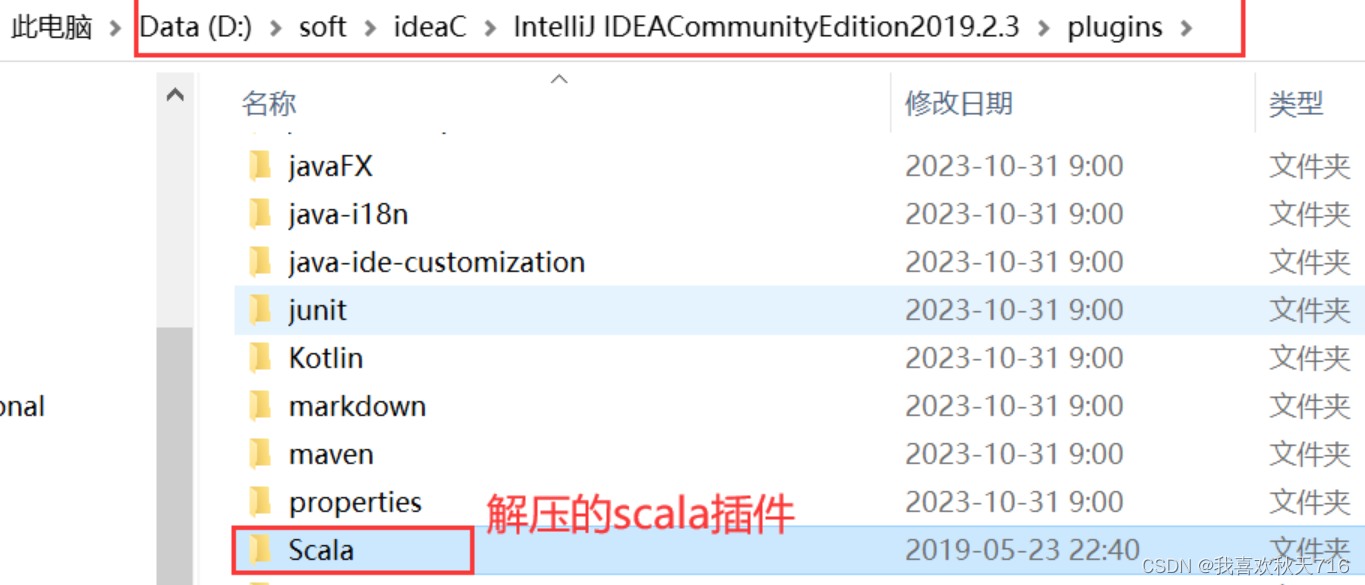
官网地址:Scala - IntelliJ IDEs Plugin | Marketplace编辑https://plugins.jetbrains.com/plugin/1347-scala/versions/stable下载完成后,将下载的压缩包解压到IDEA安装目录下的plugins目录下
5.maven的下载(我选择的版本是3.5.4)与安装,系统环境变量的配置
官网地址:Maven – Download Apache Maven
将对应版本的压缩包下载到本地,并新建一个文件夹Localwarehouse,用来保存下载的依赖文件

配置maven的系统环境配置,跟以上配置的方法一样,将bin目录地址写入path环境变量:


打开maven安装包下的conf文件夹下面的settings.xml,添加如下代码:
<localRepository>D:\\Develop\\maven\\Localwarehouse</localRepository>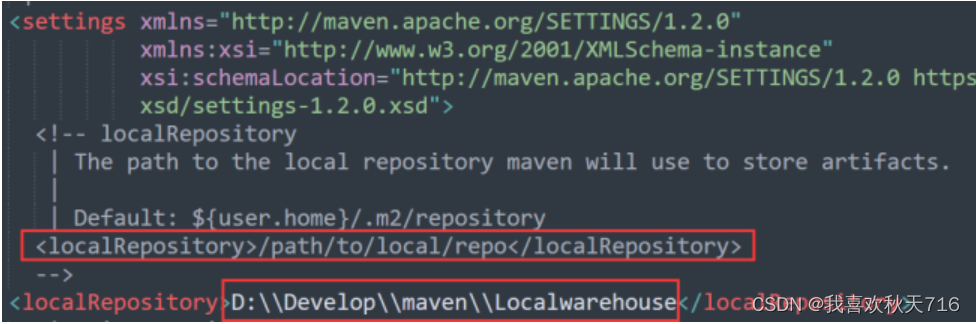 在settings.xml配置文件中找到mirrors节点,添加阿里云仓库代码,具体代码如下配置(注意要添加在<mirrors>和</mirrors>两个标签之间):
在settings.xml配置文件中找到mirrors节点,添加阿里云仓库代码,具体代码如下配置(注意要添加在<mirrors>和</mirrors>两个标签之间):
<!-- 阿里云仓库 -->
<mirror>
<id>alimaven</id>
<mirrorOf>central</mirrorOf>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central/</url>
</mirror>
添加如下代码用来配置jdk版本
<profile>
<id>jdk-1.8.0</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8.0</jdk>
</activation>
<properties>
<maven.compiler.source>1.8.0</maven.compiler.source>
<maven.compiler.target>1.8.0</maven.compiler.target>
<maven.compiler.compilerVersion>1.8.0</maven.compiler.compilerVersion>
</properties>
</profile>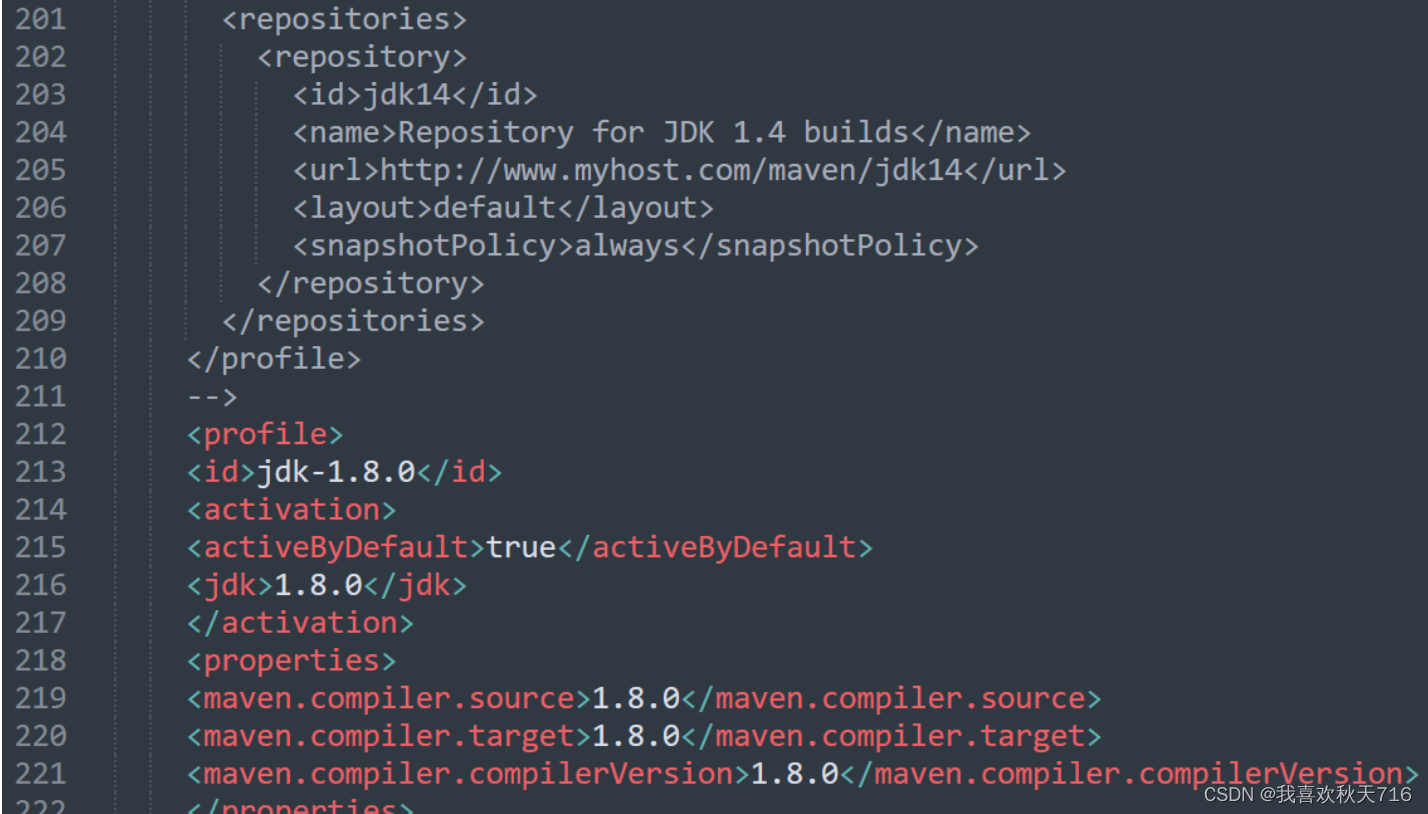
二、将maven加载到IDEA中 
三、检测scala插件是否在IDEA中已经安装成功

四、用maven新建一个工程项目


五、配置pom.xml文件
<properties>
<!-- 声明scala的版本 -->
<scala.version>2.12.15</scala.version>
<!-- 声明linux集群搭建的spark版本,如果没有搭建则不用写 -->
<spark.version>3.2.1</spark.version>
<!-- 声明linux集群搭建的Hadoop版本 ,如果没有搭建则不用写-->
<hadoop.version>3.1.4</hadoop.version>
</properties>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.2.1</version>
<scope>provided</scope>
</dependency>
</dependencies>六、新建scala类文件编写代码
当你右键发现无法新建scala类,需要将scala SDK添加到当前项目中。

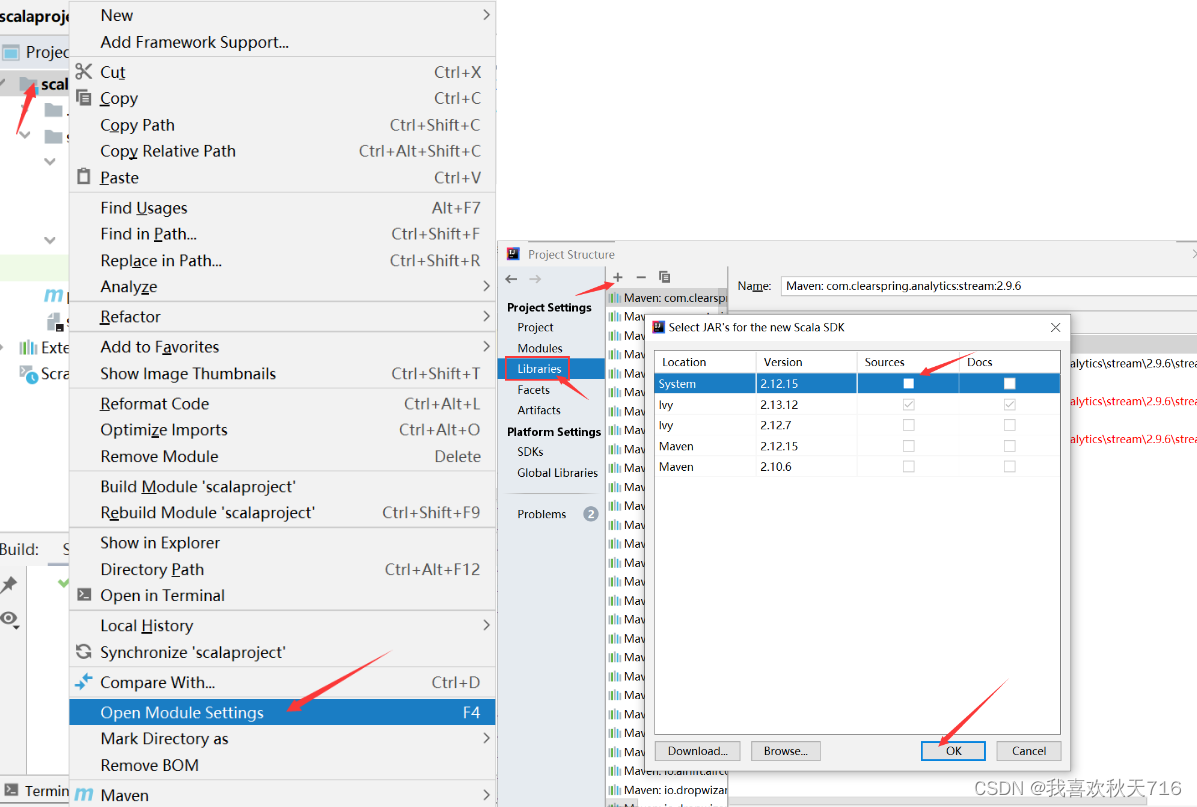
鼠标点击java文件夹,右键new--->Scala Class

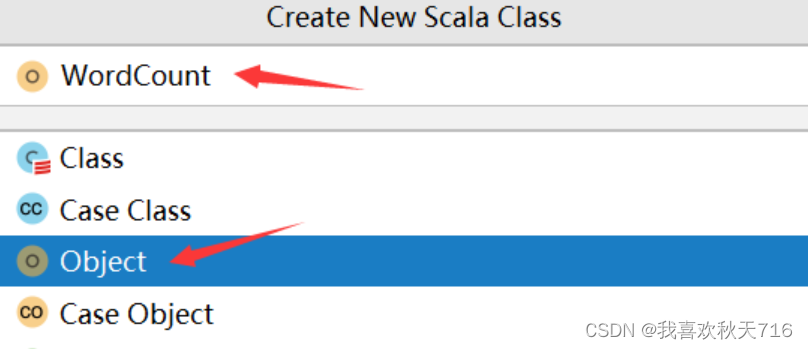
在WordCount文件中编写如下代码:
import org.apache.spark.sql.SparkSession
object WordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local[*]")
.appName("word count")
.getOrCreate()
val sc = spark.sparkContext
val rdd = sc.textFile("data/input/words.txt")
val counts = rdd.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
counts.collect().foreach(println)
println("全部的单词数:"+counts.count())
counts.saveAsTextFile("data/output/word-count")
}
}准备好测试文件words.txt,将文件存放在scalaproject-->data-->input-->words.txt
hello me you her
hello me you
hello me
hello 运行WordCount程序
运行WordCount程序

运行结果:


七、其他注意事项
如果运行spark程序,控制台有输出 “Could not locate executable null\bin\winutils.exe in the Hadoop binaries”错误提示,解决方案请参考以下文章:
https://blog.csdn.net/hyj_king/article/details/104299371
https://blog.csdn.net/hyj_king/article/details/104299371
winuntils.exe下载地址:
GitHub - cdarlint/winutils: winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows
winutils.exe hadoop.dll and hdfs.dll binaries for hadoop windows - cdarlint/winutils
https://github.com/cdarlint/winutils
如果运行你的spark程序,在控制台上打印出很多info信息,解决方案请参考以下文章:
Spark控制台不打印INFO,只输出结果_no custom resources configured for spark.driver.-CSDN博客
https://blog.csdn.net/weixin_44328257/article/details/125846290















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









