






目录
1.修改主机名:hostnamectl set-hostname 主机名
2.查看主机ip地址:ip addr3.主机的ip变成静态固定ip
4.重启网络:systemctl restart network
1)systemctl stop firewalld.service
JAVA HOME exportIAVA HOME=/opt/module/idk1.8.0 161
再将JAVA HOME引用到path环境变量中 expor PATH=$JAVA HOME/bin:$PATH
scp -r/opt/module/jdk1.8.0 161 slave2:/opt/module
scp-r/etc/profile.d/my env.sh slave2:/etc/profile.d
1.需要将data文件夹下的内容清空(直接删除data文件夹),还要删除logs文件夹下的内容(直接删除logs文件夹)
1、核心思想:“分而治之”(Map一映射,Reduce-归约)。MapReduce 就是“任务解和的分结果的汇总”。
1.修改主机名:hostnamectl set-hostname 主机名
2.查看主机ip地址:ip addr3.主机的ip变成静态固定ip
vi /etc/sysconfig/network-scripts/ifcfg-ens32
(1)BOOTPROTO="static"
(2)IPADDR=192.168.15.130
NETMASK=255.255.255.0
GATEWAY=192.168.15.2
DNS1=192.168.15.2
DNS2=8.8.8.8
4.重启网络:systemctl restart network
5.关闭防火墙:
1)systemctl stop firewalld.service
2)systemctl stop firewalld
查看防火墙状态:systemctl status firewalld.service
移除防火墙:systemctl disable firewalld.service
防火墙开启:active
防火墙关闭:dead
6.克隆虚拟机
uuidgen生成新的uuid
7.ip地址和主机名的映射
/etc/hosts
8.免密登录设置
ssh-keygen 生成每台主机的密钥ssh-copy-id 主机名 复制密钥
配置jdk环境用来存放解压后的软件
opt/software用来存放安装包的压缩包
mkdir -p /opt/module
mkdir -p /opt/software
(1)上传安装包
(2)解压到指定的目录下
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module
tar -zxvf hadoop-3.1.4.tar.gz -C /opt/module/
(3)环境变量的配置
vi /etc/profile.d/my env.sh
新建系统变量
JAVA HOME exportIAVA HOME=/opt/module/idk1.8.0 161
再将JAVA HOME引用到path环境变量中 expor PATH=$JAVA HOME/bin:$PATH
生效环境变量的配置:source/etc/profile
(4)验证环境是否安装成功
java -version
向其他主机传送文件或文件夹:scp-r文件或文件夹的名字(绝对路径)主机名:传递目标目录
scp -r/opt/module/jdk1.8.0 161 slave2:/opt/module
scp-r/etc/profile.d/my env.sh slave2:/etc/profile.d
hdfs---分布式文件系统 namenode datanodeMapReduce---分布式计算框架
yarn---资源调度管理平台resourcemanager nodemanager
hdfs---分布式文件系统 namenode datanode
MapReduce---分布式计算框架 yarn---资源调度管理平台
resourcemanager nodemanager secondarynamenode master namenode datanode nodemanager slave1 datanod resourcemanager
nodemanager slave2 datanode nodemanager secondarynamenode
文件系统的格式化
hdfs namenode -format
启动hadoop平台
1.启动hdfs:start-dfs.sh(主节点master)
stop-dfs.sh
2.启动yarn:start-yarn.sh(主节点slave1)
stop-yarn.sh
hdfs Ul监控界面
主机名(IP地址):9870
1.Overview:hdfs基本信息:启动时间、版本号、编译版本等
2.Summary:集群信息。
3.NameNode Storage:提供了NameNode的信息
启动后需要检查:centos.2.x801.三台机子都敲入jps,检查进程是否完整
2.进入hdfs Ul监控界面:
(1)hdfs平台是active
(2)live nodes为3个
(3)NameNode Storage中State状态为active
(4)DFS Storage Types中Nodes In Service为3个
配置时间同步服务
NTP(Network Time Protocol)网络时间协议,使计算机时间同步的一种协议
1.下载安装ntp服务
yum install -y ntp
2.设置master节点为ntp服务的主节点
vi /etc/ntp.conf
注释掉server开头的行添加如下内容:
(restrict 192.168.15.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3.分别在slave1和slave2节点中配置ntp服务
(1)通过scp-r命令将ntp.conf传给slave1和slave2
(2)在ntp.conf文件中添加如下内容:
server master
4.关闭和禁用防火墙服务
5.启动ntp服务
(1)在master节点上使用
systemctl start ntpd 启动ntp服务
systemctlenable ntpd永久开启ntp服务
6.使用命令ntpdate master去同步master节点的时
在slave1和slave2节点上启动ntp服务
启动ntp服务nfsystemctl enable ntpd永久开启ntp服务
注意事项:
.二次格式化hdfs,
1.需要将data文件夹下的内容清空(直接删除data文件夹),还要删除logs文件夹下的内容(直接删除logs文件夹)
2.hdfs的Ul监控界面:master:98705
Safemode安全模式
保证系统保密性、完整性及可使用性的一种机制。
当处于安全模式,hdfs只接收读取数据的请求,不允许删除、修改等变更操作
查看安全模式状态
hdfs dfsadmin -safemode get
开启安全模式
hfds dfsadmin -safemode enter
关闭安全模式
hdfs dfsadmin -safemode leave
查看HDFS文件系统资源信息 hdfs dfsadmin -report
查看在线节点信息 hdfs dfsadmin -report -live
查看宕机节点信息 hdfs dfsadmin -report -dead
hdfs基本操作---命令行
1.创建目录(文件夹)
单层文件夹
hdfs dfs -mkdir /文件夹名
多层文件夹
hdfs dfs -mkdir -p /文件夹1/文件夹
2.上传文件
hdfs dfs-put 源文件的路径 目标路径 本地的源文件不删除
hdfs dfs -moveFromLocal 源文件的路径 目标路径 本地的源文件被删除
3.下载文件
hdfs dfs -get 源文件的路径 目标路径
hdfs dfs -copyToLocal 源文件的路径 目标路径
4.查看文件内容
hdfs dfs -cat 源文件的路径
hdfs dfs -tail 源文件的路径 查看文件最后1024KB的内容
5.删除文件或目录
hdfs dfs -rm -r源文件的路径
hdfs dfs -rmdir 源文件夹的路径
6.列出指定的文件和目录
hdfs dfs -ls [-d][-h][-R]<文件路径>
hdfs Ul监控界面:master:9870
yarn UI监控界面:slave1:8088
/opt/module/hadoop-3.1.4/share/hadoop/mapreduce/
hadoop-mapreduce-examples-3.1.4.jar
包含7个模块
1.wordcount对输入的单词文件进行词频统计
2.pi 应用拟蒙特卡罗方法计算圆周率的值
3.wordmean 计算输入文件单词的平均长度
4.wordmedian 计算输入文件的单词长度的中位数
1.进入目录
cd /opt/module/hadoop-3.1.4/share/hadoop/
2.提交mapreduce任务给集群运行
格式 Hadoop jar jar包所在绝对路径 输出结果文件的路径 就接下来使用的是wordcount样例:
hadoop jar hadoop-mapreduce-examples-3.1.4.jar wordcount 绝对路径 (/data/input)
注意:
输出结果文件提交前不能存在
即:首先,要确保建立/data/input,然后/data/下面只能存在input,不能存在output,如果有的话,将output的删除(删除的话,用hdfs dfs -rm -r的命令在linux界面下删除,这样就能在Linux系统里面删除;如果是在浏览器的UI界面上删除,是在WINDOWS系统里面删除,Linux系统里面无法删除,就会报错)
6.验证是否成功的方法:
1.方法(一):要确保在Linux系统的界面下出现successfully才成功
2.方法(二):也可以在浏览器的UI界面下进行查看验证,即点击/data/output,若点进去出现“SUCCESS”的字样,在yarn上运行的这个mapreduce样例程序就成功了
MapReduce编程思想
1、核心思想:“分而治之”(Map一映射,Reduce-归约)。MapReduce 就是“任务解和的分结果的汇总”。
2、MapReduce 执行的角色(进程)-个是JobTracker;另一个是TaskTracker。JobTracker用于调度(安排)工作的TaskTracker是用于执行工作的。一个 Hadoop 集群中只有一台 JobTracker,有若于个TaskTracker.
把处理过程高度抽象为两个函数:map和reduce,map负责把任务分解成多个任务负责把分解后多任务处理的结果汇总起来。
3.适用场景←
待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。←
MapReduce 处理过程
4.在 Hadoop 中,每个 MapReduce 任务都被初始化为一个Job,Job 将数据划分为多个数据块,每个数据块对应一个计算任务(Task),并自动调用计算节点来处理相应的数据块。每个 Job 又可以分为两种阶段:map 阶段reduce 阶段。←
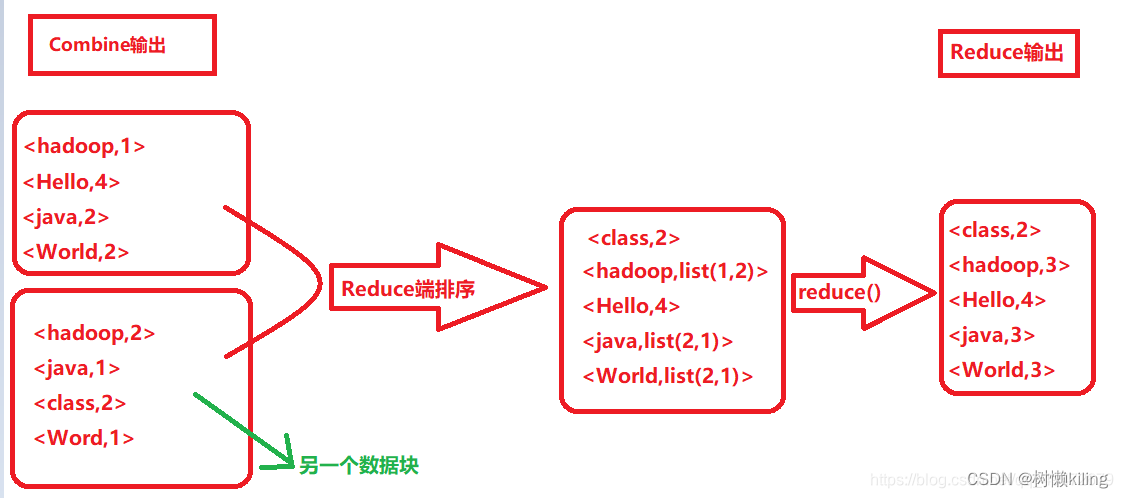
这两个阶段分别用两个函数表示,即 map 函数和 reduce 函数。map 函数接收一个<key,value>形式的输入,然后同样产生一个<key,value>形式的中间输出,reduce 函数接收一个如<key,(list of values)>形式的输入,然后对这个 value 集合进行处理,每个reduce 产生0或1个输出,reduce 的输出也是<key,value>形式的。
将map的输出作为输入传给reducer的过程就是shuffle。而shuffle是mapReduce的核心,主要工作是从Map结束阶段到Reduce阶段,可以分为Map端的Shuffle和Reduce端的Shuffle。
5 Hadoop
BooleanWritable:标准布尔型数值
BvteWritable:单字节数值~
DoubleWritable:双字节数
FloatWnitable:浮点数
IntWritable:整型数
LongWritable:长整型数
Text:使用 UTF8 格式存储的文本
NulIWritable:当<key,value>中的 key 或 value 为空时使用
6、Mapreduce具体过程
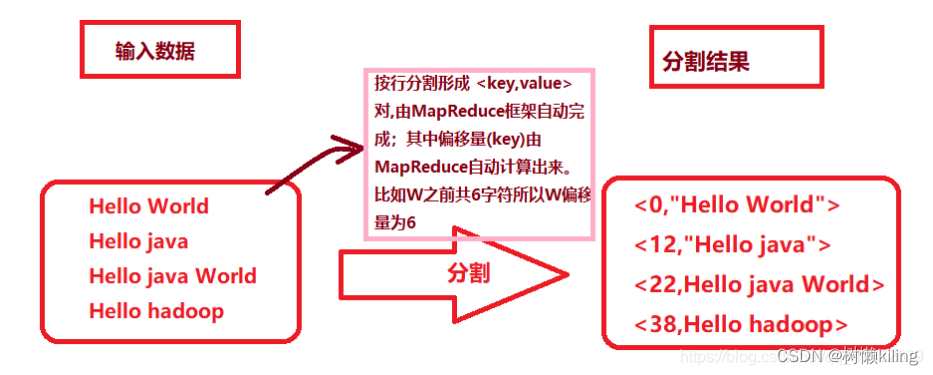
- Mapper类
Mapper类有两个包:org.apache.hadoop.mapreduce、org.apache.hadoop.mapred
org.apache.hadoop.mapred是hadoop 1.x版本的,负责资源的调度和计算
org.apache.hadoop.mapreduce是hadoop 2.x和3.x版本的,负责数据的计算
(2)Reducer类
(3)Job类
Map和reduce过程输入输出键值对类型的确定
2、reduce过程:对相同的的键值对的多个值进行计算(求和、求平均值、)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









