







paper:MLP-Mixer: An all-MLP Architecture for Vision
official implementation:https://github.com/google-research/vision_transformer
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/mlp_mixer.py
本文的创新点
本文的出发点是挑战计算机视觉领域中使用卷积神经网络(CNN)和注意力机制(如Vision Transformer, ViT)的传统方法,本文提出了一种完全基于多层感知机(MLP)的架构MLP-Mixer,旨在证明卷积和注意力并非实现高性能图像分类所必需的技术。
MLP-Mixer完全抛弃了卷积和注意力机制,转而使用两种类型的MLP层:channel mixing MLP和token mixing MLP来处理图像信息。该架构依赖基本的矩阵乘法、数据维度转换(reshape和transpose)和标量非线性操作,简化了模型复杂度。相比传统CNN和ViT,MLP-Mixer在预训练和推理阶段的成本具有竞争力。
尽管结构简单,MLP-Mixer在使用大规模数据集(如JFT-300M)预训练后,在图像分类基准测试中取得了接近最先进模型的表现。即使在使用较小规模数据集(如ImageNet-1k)时,也能通过现代正则化技术获得较好的性能。
方法介绍
MLP-Mixer的整理结构非常简单,如图1所示。和ViT一样,输入首先通过patch embedding层得到一个不重叠image patch的序列,然后转置一下,经过一个token_mlp层,token_mlp层单独作用于每个通道,用于不同空间位置(token)的信息交互,实现token mixing。得到的结果再转置一下,然后经过一个channel_mlp层,channel_mlp单独作用于每个token,用于不同通道的信息交互,实现channel mixing。一个token_mlp加一个GELU激活函数再加一个channel_mlp组成一个block,MLP-Mixer的主体部分由若干个block组成,最后通过一个全局平均池化加一个线性分类层得到最终的输出。
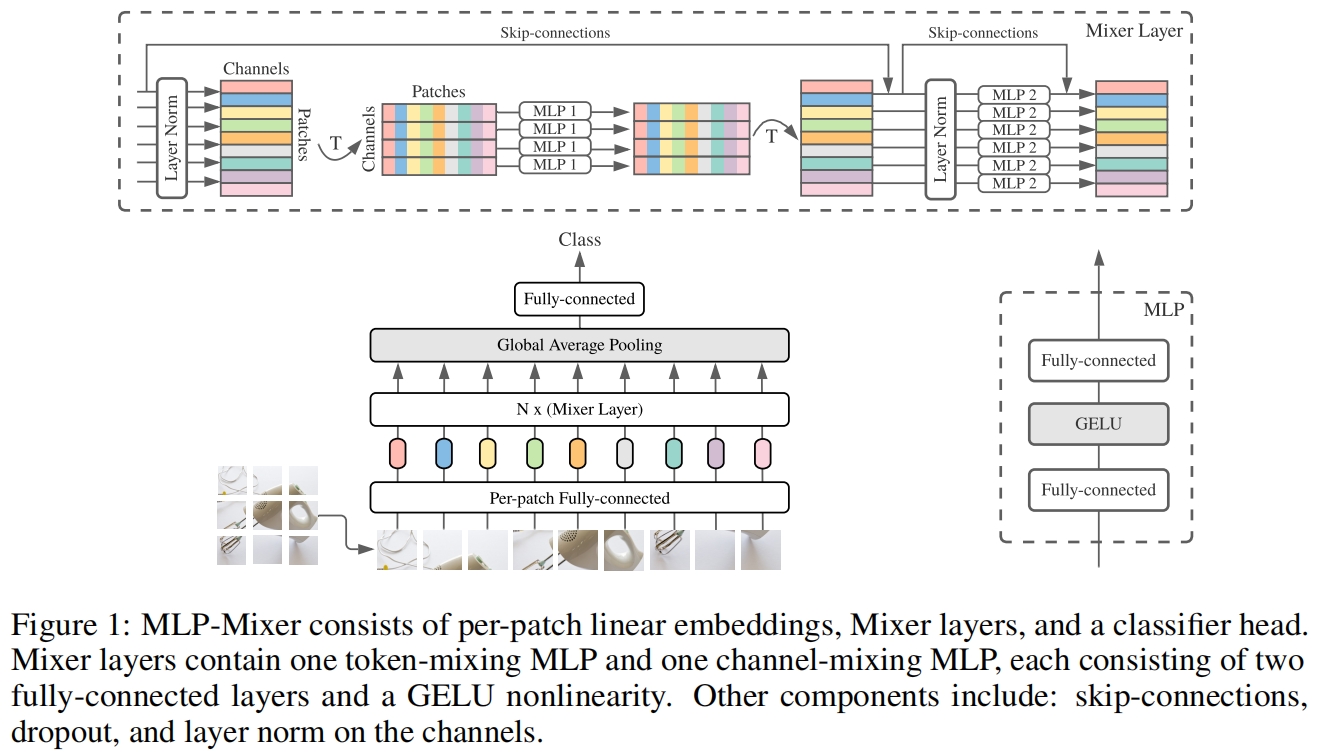
除了MLP外,MLP-Mixer还使用了skip-connection和layer normalization。和ViT不一样的是,MLP-Mixer没有使用位置编码因为token-mixing MLP本身就对输入token的顺序是敏感的。
MLP-Mixer的每一层的输入和输出维度是一致的,和ViT一样,而没有采用CNN那样的金字塔结构,即随着网络的加深分辨率越来越小。
实验结果
作者设计了多种不同大小的MLP-Mixer,具体配置如下

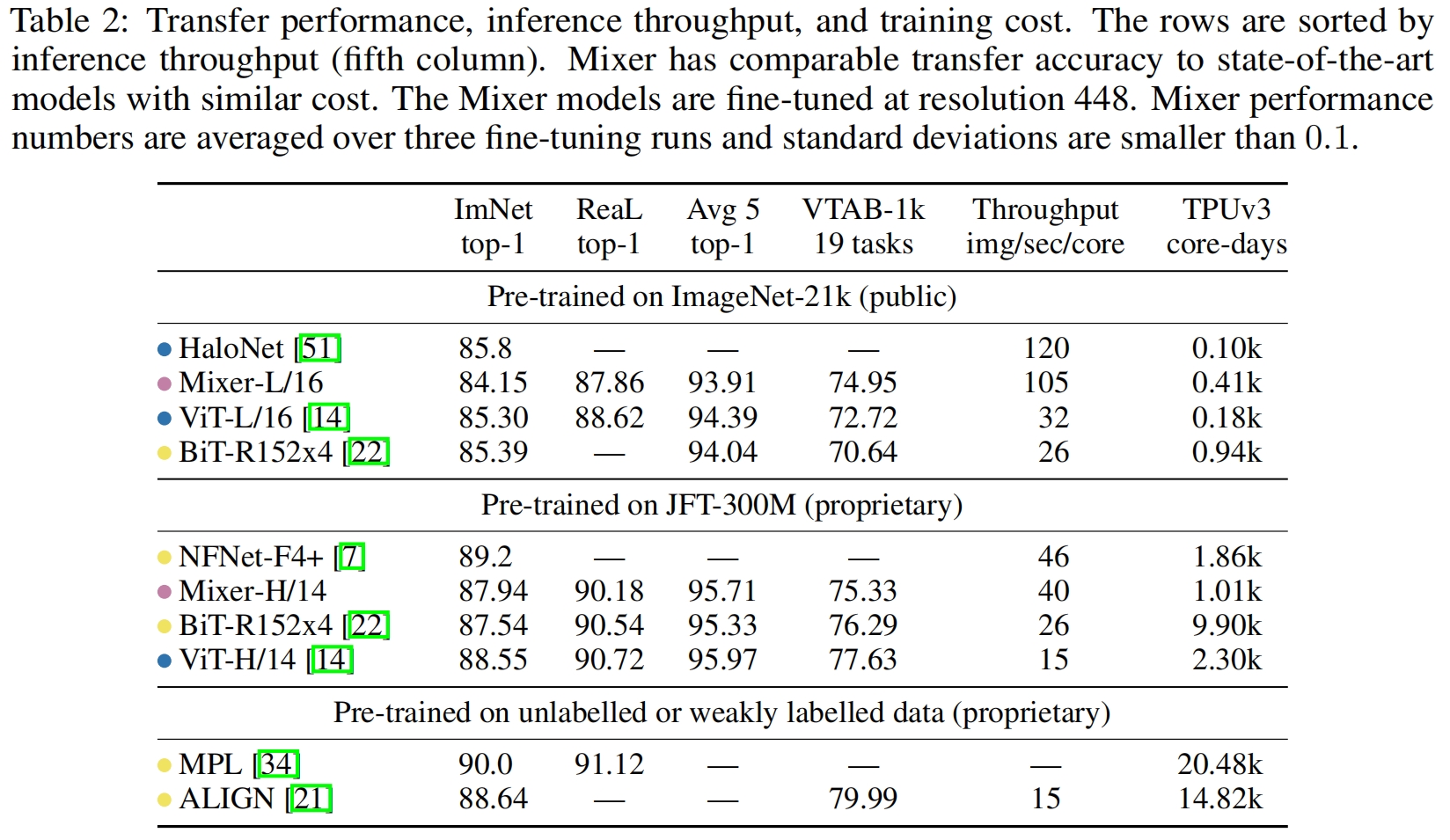
和其它SOTA模型的分类性能对比如下,可以看到MLP-Mixer略差于其它模型。但当在更多的无标签或弱标签数据上进行预训练后,MLP-Mixer的性能会得到大幅提升。
代码解析
这里以timm中的实现为例,模型选择"mixer_b16_224",输入shape为(1, 3, 224, 224),实现在类MixerBlock中,代码如下。在这之前输入首先经过self.stem处理,就是ViT中的patch embedding层,patch_size=16,得到输出shape为(1, 196, 768),分别表示(batch_size, token_num, embed_dim),其中196=(224/16)^2,768=16x16x3。
由下面代码可知,block包含一个mlp_token和一个mlp_channel,并且用了残差连接。每个mlp又由2个fc组成,mlp_ratio=(0.5, 4)表示两个mlp中第一个fc的输出通道数与输入通道数的比例。
class MixerBlock(nn.Module):
""" Residual Block w/ token mixing and channel MLPs
Based on: 'MLP-Mixer: An all-MLP Architecture for Vision' - https://arxiv.org/abs/2105.01601
"""
def __init__(
self,
dim,
seq_len,
mlp_ratio=(0.5, 4.0),
mlp_layer=Mlp,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
act_layer=nn.GELU,
drop=0.,
drop_path=0.,
):
super().__init__()
tokens_dim, channels_dim = [int(x * dim) for x in to_2tuple(mlp_ratio)] # 384,3072
self.norm1 = norm_layer(dim)
self.mlp_tokens = mlp_layer(seq_len, tokens_dim, act_layer=act_layer, drop=drop) # 196,384
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp_channels = mlp_layer(dim, channels_dim, act_layer=act_layer, drop=drop) # 768,3072
def forward(self, x): # (1,196,768)
# self.mlp_tokens
# Mlp(
# (fc1): Linear(in_features=196, out_features=384, bias=True)
# (act): GELU()
# (drop1): Dropout(p=0.0, inplace=False)
# (norm): Identity()
# (fc2): Linear(in_features=384, out_features=196, bias=True)
# (drop2): Dropout(p=0.0, inplace=False)
# )
x = x + self.drop_path(self.mlp_tokens(self.norm1(x).transpose(1, 2)).transpose(1, 2)) # (1,768,196)->(1,768,196)->(1,196,768)
# self.mlp_channels
# Mlp(
# (fc1): Linear(in_features=768, out_features=3072, bias=True)
# (act): GELU()
# (drop1): Dropout(p=0.0, inplace=False)
# (norm): Identity()
# (fc2): Linear(in_features=3072, out_features=768, bias=True)
# (drop2): Dropout(p=0.0, inplace=False)
# )
x = x + self.drop_path(self.mlp_channels(self.norm2(x))) # (1,196,768)->(1,196,768)
return x

















 1901
1901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











