






目录
一.Numpy库:
科学计算包,支持N维数组运算、处理大型矩阵、成熟的广播函数库、矢量运算、线性代数、傅里叶变换、随机数生成,并可与C++/Fortran语言无缝结合。
多维数组对象:NumPy的核心是多维数组对象(ndarray),它是一个快速而灵活的大数据容器,可以存储相同类型的数据。
数学函数:NumPy提供了大量的数学函数,用于在数组上执行元素级的计算和操作。
线性代数:NumPy支持各种线性代数操作,如矩阵乘法、特征值计算等。
统计函数:NumPy还包含许多统计函数,用于计算数组的描述性统计量。
随机数生成:NumPy有一个随机数生成器,用于生成符合各种分布的随机数。
1)基本函数:
| 函数 | 说明 | 示例 |
| numpy.array() | 创建一个数组 | arr = numpy.array([1, 2, 3, 4]) |
| numpy.zeros() | 创建一个全零数组 | zeros = numpy.zeros((3, 3)) |
| numpy.ones() | 创建一个全一数组 | ones = numpy.ones((2, 2)) |
| numpy.eye() | 创建一个对角线上为1,其余为0的数组(单位矩阵) | eye = numpy.eye(3) |
| numpy.arange() | 创建一个具有等差步长的数组 | arange = numpy.arange(0, 10, 2) |
| numpy.linspace() | 创建一个在指定范围内具有指定数量的等间隔样本的数组 | linspace = numpy.linspace(0, 1, 5) |
| numpy.random.rand() | 创建一个指定形状的数组,数组中的元素来自[0, 1)的均匀分布 | rand_arr = numpy.random.rand(2, 3) |
| numpy.random.randn() | 创建一个指定形状的数组,数组中的元素来自标准正态分布(均值为0,标准差为1) | randn_arr = numpy.random.randn(2, 2) |
| numpy.sum() | 计算数组元素的总和 | total = numpy.sum(arr) |
| numpy.mean() | 计算数组元素的平均值 | avg = numpy.mean(arr) |
| numpy.std() | 计算数组元素的标准差 | std_dev = numpy.std(arr) |
| numpy.min() | 找到数组元素中的最小值 | min_val = numpy.min(arr) |
| numpy.max() | 找到数组元素中的最大值 | max_val = numpy.max(arr) |
| numpy.argmin() | 找到数组元素中最小值的索引 | min_index = numpy.argmin(arr) |
| numpy.argmax() | 找到数组元素中最大值的索引 | max_index = numpy.argmax(arr) |
| numpy.dot() | 计算两个数组的点积(对于一维数组,这就是向量的点积) | dot_prod = numpy.dot(arr1, arr2) |
| numpy.reshape() | 更改数组的形状而不更改其数据 | reshaped_arr = arr.reshape((2, 2)) |
2)实际问题处理:
当使用 numpy 库时,我们可以解决各种实际问题,包括数据分析、图像处理、信号处理等。以下是一个简单的例子,我们将使用 numpy 来计算一组数据的平均值、标准差,并找出最大值和最小值。
假设我们有一组关于某个产品销售额的数据,我们需要对这些数据进行基本的统计分析。
import numpy as np
# 假设这是我们的销售额数据(单位:元)
sales_data = np.array([1200, 1500, 800, 2200, 1000, 1700, 1900, 1100, 2300, 1600])
# 计算销售额的平均值
average_sales = np.mean(sales_data)
print(f"平均销售额为:{average_sales}元")
# 计算销售额的标准差
std_sales = np.std(sales_data)
print(f"销售额的标准差为:{std_sales}元")
# 找出销售额的最大值
max_sales = np.max(sales_data)
print(f"最高销售额为:{max_sales}元")
# 找出销售额的最小值
min_sales = np.min(sales_data)
print(f"最低销售额为:{min_sales}元")
# 也可以同时找出最大值和最小值的索引
max_index = np.argmax(sales_data)
min_index = np.argmin(sales_data)
print(f"最高销售额出现在索引位置:{max_index}")
print(f"最低销售额出现在索引位置:{min_index}")这段代码首先导入了 numpy 库,并定义了一个名为 sales_data 的一维数组,其中包含了一系列产品的销售额。然后,它使用 numpy 的函数来计算这些数据的平均值、标准差、最大值、最小值以及这些值在数组中的索引位置。这些统计信息对于了解销售数据的特点和趋势非常有用。
二.Scipy库:
scipy在numpy的基础上增加了大量用于数学计算、科学计算以及工程计算的模块,包括线性代数、常微分方程数值求解、信号处理、图像处理、稀疏矩阵等等。
scipy的constants模块包含了大量用于科学计算的常数
scipy的special模块包含了大量函数库,包括基本数学函数、特殊函数以及numpy中的所有函数。
signal模块包含大量滤波函数、B样条插值算法等等。
模块ndimage提供了大量用于N维图像处理的方法。
1)基本函数:
scipy是一个用于数学、科学和工程计算的开源 Python 库,它包含了大量的子模块,每个子模块都提供了特定的功能。以下是 scipy库中一些常用子模块的基本函数及其说明:
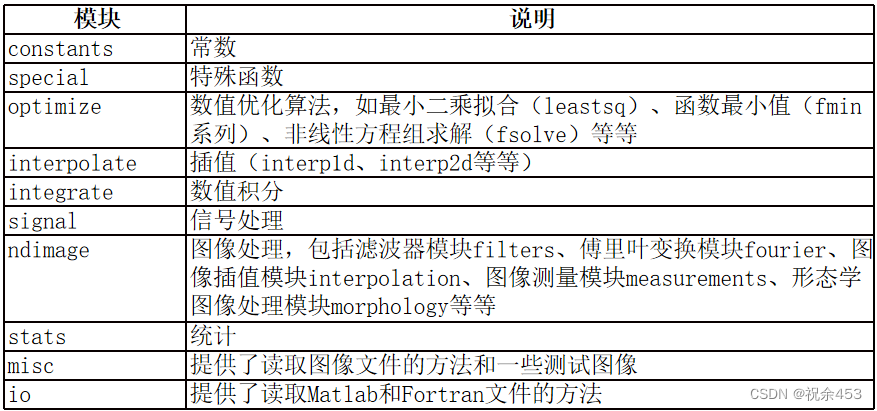
| 子模块 | 函数 | 说明 |
| scipy.optimize | scipy.optimize | 求解函数的最小值(可以处理非线性优化问题) |
| minimize_scalar | 求解一元函数的最小值 | |
| curve_fit | 曲线拟合,找到最佳拟合参数 | |
| scipy.stats | norm.pdf | 计算正态分布的概率密度函数值 |
| norm.cdf | 计算正态分布的累积分布函数值 | |
| norm.rvs | 从正态分布中抽取随机样本 | |
| ttest_ind | 独立样本的 t 检验 | |
| scipy.interpolate | interp1d | 一维插值 |
| griddata | 多维插值 | |
| scipy.signal | butter | 设计巴特沃斯滤波器 |
| convolve | 一维卷积 | |
| spectrogram | 计算短时傅里叶变换并返回频谱图 | |
| scipy.linalg | inv | 计算矩阵的逆 |
| eig | 计算矩阵的特征值和特征向量 | |
| solve | 求解线性方程组 | |
| scipy.integrate | quad | 计算一元函数的定积分 |
| odeint | 求解常微分方程的初始值问题 | |
| scipy.spatial | distance.cdist | 计算两个输入数组之间的成对距离 |
| ConvexHull | 计算输入点的凸包 | |
| scipy.special | gamma | 计算伽马函数值 |
| erf | 计算误差函数值 | |
| beta | 计算贝塔函数值 |
Scipy库的图像处理模块主要包含在scipy.ndimage中,它提供了许多用于图像处理和计算机视觉的功能。
| ndimage.gaussian_filter | 对图像进行高斯滤波,以去除噪声和细节。 | blurred_image = ndimage.gaussian_filter(image, sigma=2) |
| ndimage.median_filter | 可用于中值滤波,这也是一种常见的去噪方法 | filtered_image = ndimage.median_filter(image, size=3) |
| ndimage.rotate | 旋转图像 | rotated_image = ndimage.rotate(image, angle=45) |
| ndimage.zoom | 缩放图像 | resized_image = ndimage.zoom(image, 0.5) |
| ndimage.sobel | 边缘检测 |
2)用scipy.ndimage模块处理图像:
from scipy import misc
from scipy import ndimage
import matplotlib.pyplot as plt
face = misc.face() # face是测试图像之一
plt.figure() # 创建图形
plt.imshow(face) # 绘制测试图像
plt.show() # 原始图像

blurred_face = ndimage.gaussian_filter(face, sigma=7) # 高斯滤波
plt.imshow(blurred_face)
plt.show() # 显示结果图像

blurred_face1 = ndimage.gaussian_filter(face, sigma=1) # 边缘锐化
blurred_face3 = ndimage.gaussian_filter(face, sigma=3)
sharp_face = blurred_face3 + 6*(blurred_face3-blurred_face1)
plt.imshow(sharp_face)
plt.show()
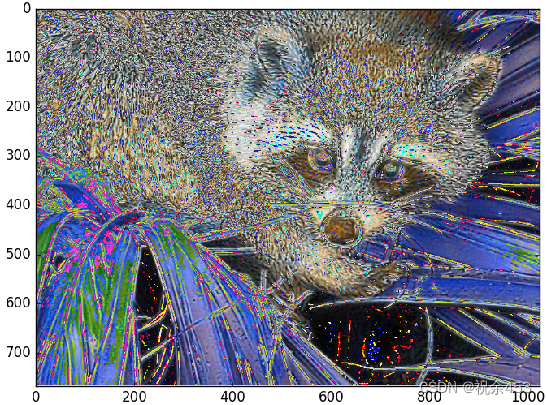
median_face = ndimage.median_filter(face, 7) # 中值滤波
plt.imshow(median_face)
plt.show()

三.Pandas库:
基于numpy的数据分析模块,提供了大量标准数据模型和高效操作大型数据集所需要的工具,可以说pandas是使得Python能够成为高效且强大的数据分析环境的重要因素之一。
Pandas的特点包括:
数据对齐:Pandas可以自动对齐不同索引的数据,使得数据操作更加方便。
处理缺失值:Pandas提供了强大的工具来处理缺失值,包括删除、填充等操作。
强大的数据分析功能:Pandas支持各种数据分析和统计计算,如平均值、中位数、标准差等。
灵活的数据导入和导出:Pandas可以读取和写入多种数据格式,包括CSV、Excel、SQL数据库、JSON等。
1)基本函数:
| 函数名 | 说明 |
| read_csv() | 从CSV文件中读取数据,并返回一个DataFrame对象。 |
| read_excel() | 从Excel文件中读取数据,并返回一个DataFrame对象。 |
| head(n) | 返回DataFrame的前n行(默认为5行)。 |
| tail(n) | 返回DataFrame的后n行(默认为5行)。 |
| info() | 提供DataFrame的基本信息,如列名、数据类型、非空值数量等。 |
| describe() | 提供DataFrame中数值列的描述性统计信息,如计数、平均值、标准差、最小值、最大值等。 |
| sort_index() | 根据索引对DataFrame或Series进行排序(默认为升序)。 |
| sort_values(by, ascending=True) | 根据指定列的值对DataFrame进行排序。 |
| reindex(index=None, columns=None) | 根据新的索引或列标签重新索引DataFrame。 |
| dropna() | 删除包含缺失值的行或列。 |
| fillna(value=None, method=None) | 用指定的值或方法填充缺失值。 |
| groupby(by=None) | 根据指定的列或列组合对数据进行分组。 |
| mean() | 计算DataFrame中每列或每组的平均值。 |
| sum() | 计算DataFrame中每列或每组的和。 |
| query(expr) | 使用查询表达式对DataFrame进行过滤。 |
import pandas as pd
# 从CSV文件中读取数据
df = pd.read_csv('data.csv')
# 显示前5行数据
print(df.head())
# 显示基本信息
print(df.info())
# 显示描述性统计信息
print(df.describe())
# 根据索引排序
df_sorted_index = df.sort_index()
print(df_sorted_index.head())
# 根据某列的值排序
df_sorted_values = df.sort_values(by='column_name')
print(df_sorted_values.head())
# 重新索引
df_reindexed = df.reindex(columns=['column1', 'column2'])
print(df_reindexed.head())
# 删除缺失值
df_no_na = df.dropna()
print(df_no_na.head())
# 填充缺失值
df_filled = df.fillna(method='ffill')
print(df_filled.head())
# 分组并计算平均值
df_grouped = df.groupby('group_column').mean()
print(df_grouped.head())
# 使用查询表达式过滤数据
df_filtered = df.query('column_name > 10')
print(df_filtered.head())请注意,上述示例中的data.csv文件应包含要处理的数据,而'column_name'和'group_column'应替换为实际的列名。此外,你可能需要根据自己的需求调整函数参数和示例代码。
2)实例:
问题:假设我们有一个包含员工销售数据的CSV文件,我们想要找出每个销售部门的总销售额。
解决方案:
*读取数据:
sales_data = pd.read_csv('sales_data.csv')*数据分组和聚合:
假设CSV文件中有'department'(部门)和'sales_amount'(销售额)两列,我们可以这样计算每个部门的总销售额:
total_sales_per_department = sales_data.groupby('department')['sales_amount'].sum()*查看结果:
print(total_sales_per_department)结合matplotlib绘图:
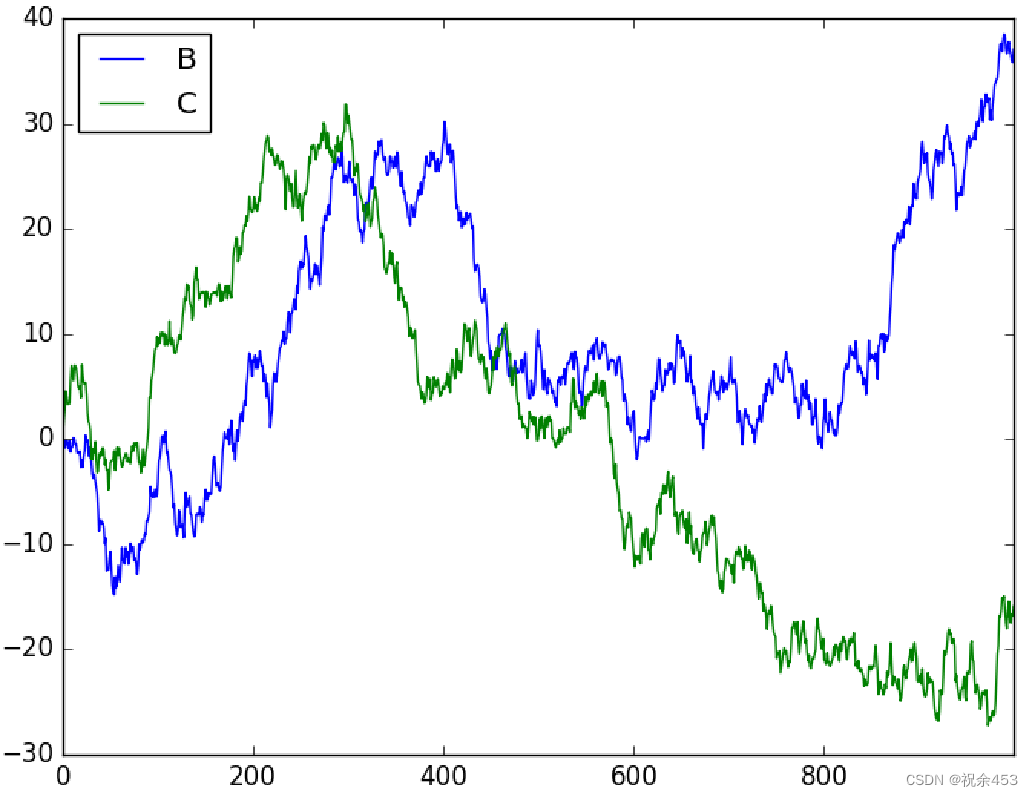
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.DataFrame(np.random.randn(1000, 2), columns=['B', 'C']).cumsum()
df['A'] = pd.Series(list(range(len(df))))
plt.figure()
df.plot(x='A')
plt.show()
四.Matplotlib库:
matplotlib 是一个用于绘制静态、动态和交互式图表的 Python 库。它是数据可视化领域中最常用的库之一,尤其适用于二维图表;
matplotlib模块依赖于numpy模块和tkinter模块,可以绘制多种形式的图形,包括线图、直方图、饼状图、散点图、误差线图等等。
1)基本函数:
| 函数名 | 说明 |
| plot() | 绘制线图。可以接收x和y坐标数据,并绘制出线条。 |
| scatter() | 绘制散点图。根据给定的x和y坐标数据,在图上绘制散点。 |
| bar() | 绘制条形图。用于显示分类数据的数值关系。 |
| hist() | 绘制直方图。用于显示数据的分布情况。 |
| pie() | 绘制饼图。用于显示不同分类的数据占比。 |
| imshow() | 绘制图像。用于显示图像数据。 |
| xlabel() | 设置x轴标签。用于给x轴添加标签说明。 |
| ylabel() | 设置y轴标签。用于给y轴添加标签说明。 |
| title() | 设置图形标题。用于给整个图形添加标题。 |
| legend() | 设置图例。用于显示图中的数据系列标签。 |
| xlim() | 设置x轴范围。用于指定x轴的显示范围。 |
| ylim() | 设置y轴范围。用于指定y轴的显示范围。 |
| subplot() | 创建子图。用于在一张画布上创建多个子图。 |
| subplots() | 创建多个子图并返回画布和子图对象。与subplot()类似,但更简洁。 |
| savefig() | 保存图形到文件。将绘制的图形保存为图片文件。 |
| show() | 显示图形。在屏幕上显示绘制的图形。 |
| close() | 关闭图形。关闭当前显示的图形窗口。 |
| figure() | 创建图形对象。用于创建一个新的图形窗口。 |
2)实例:
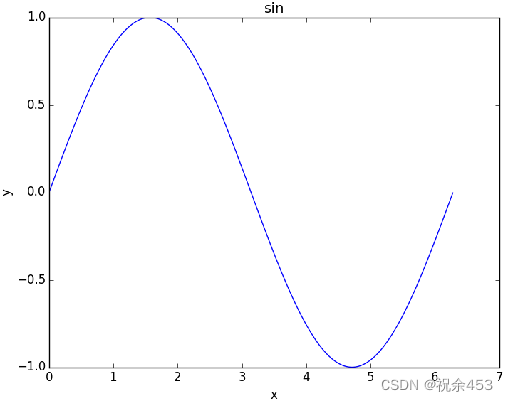
import numpy as np
import pylab as pl
t = np.arange(0.0, 2.0*np.pi, 0.01) #生成数组,0到2π之间,以0.01为步长
s = np.sin(t) #对数组中所有元素求正弦值,得到新数组
pl.plot(t,s) #画图,以t为横坐标,s为纵坐标
pl.xlabel('x') #设置坐标轴标签
pl.ylabel('y')
pl.title('sin') #设置图形标题
pl.show() #显示图形
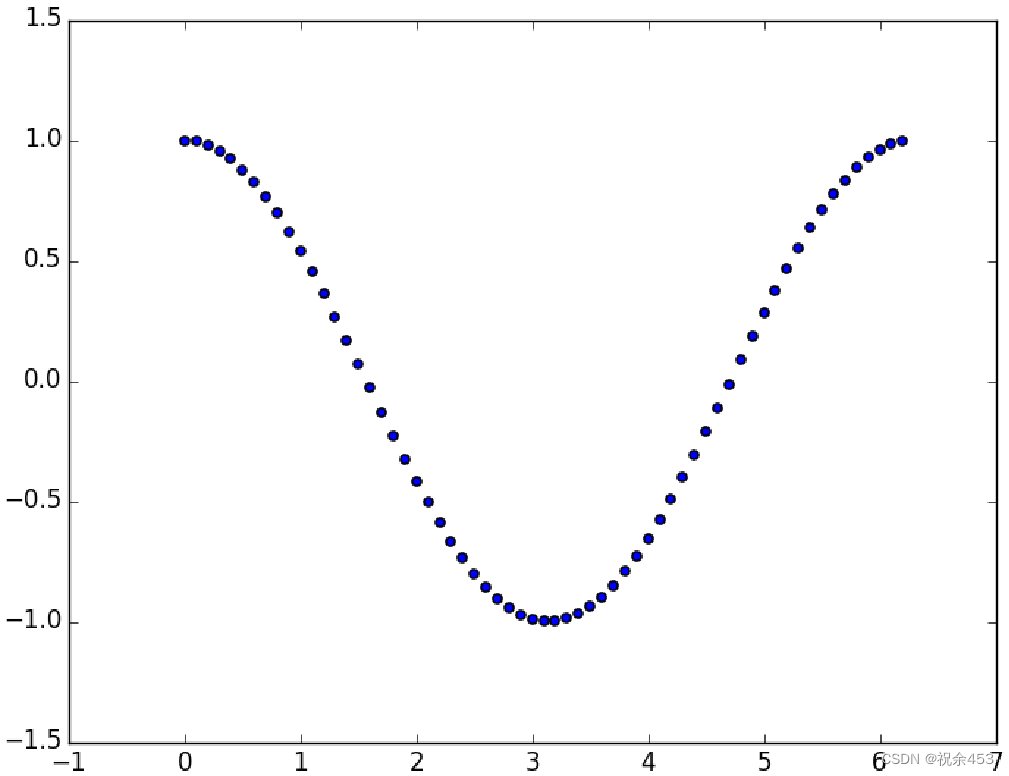
a = np.arange(0, 2.0*np.pi, 0.1)
b = np.cos(a)
pl.scatter(a,b)
pl.show()
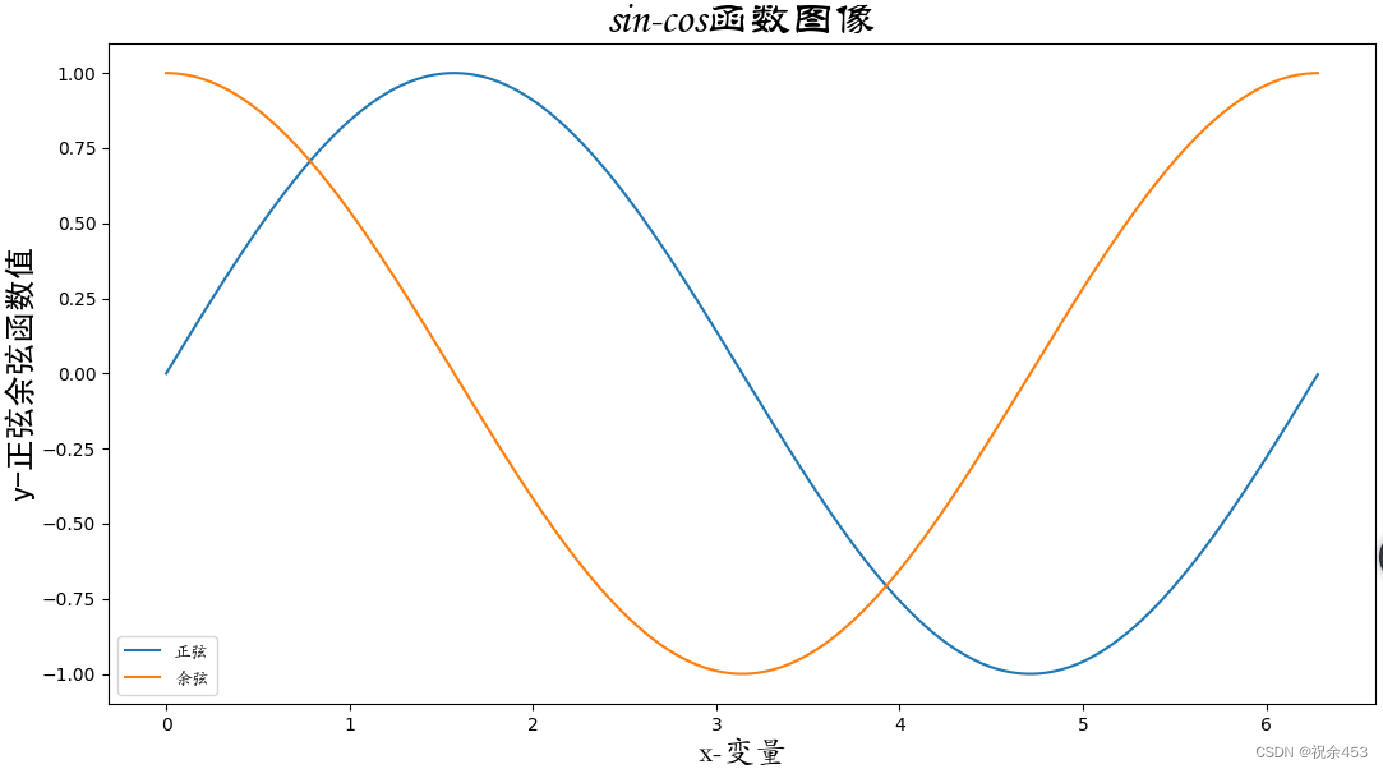
import numpy as np
import pylab as pl
import matplotlib.font_manager as fm
myfont = fm.FontProperties(fname=r'C:\Windows\Fonts\STKAITI.ttf') #设置字体
t = np.arange(0.0, 2.0*np.pi, 0.01) # 自变量取值范围
s = np.sin(t) # 计算正弦函数值
z = np.cos(t) # 计算余弦函数值
pl.plot(t, s, label='正弦')
pl.plot(t, z, label='余弦')
pl.xlabel('x-变量', fontproperties='STKAITI', fontsize=18) # 设置x标签
pl.ylabel('y-正弦余弦函数值', fontproperties='simhei', fontsize=18)
pl.title('sin-cos函数图像', fontproperties='STLITI', fontsize=24)
pl.legend(prop=myfont) # 设置图例
pl.show()


























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









