






import jieba
excludes = {}
txt = open("D:\Pythonwork\西游记.txt", "r", encoding='gb18030').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
elif word == "孙猴子" or word == "美猴王"or word == "孙行者"\
or word == "弼马温"or word == "石猴"or word == "齐天大圣"or word == "大师兄"\
or word == "老孙":
rword = "孙悟空"
elif word == "玄奘" or word == "三藏"or word == "圣僧"or word == "三藏法师"\
or word == "唐长老"or word == "江流"or word == "御弟"or word == "师父":
rword = "唐僧"
elif word == "猪刚鬣" or word == "净坛使者"or word == "天蓬元帅"\
or word == "老猪"or word == "二师兄"or word == "悟能":
rword = "猪八戒"
elif word == "沙悟净" or word == "沙僧"or word == "金身罗汉"\
or word == "卷帘大将"or word == "仙佛"or word == "沙师弟":
rword = "沙和尚"
elif word == "龙马" or word == "白马"or word == "孽龙"\
or word == "八部天龙马":
rword = "白龙马"
else:
counts[word] = counts.get(word,0) + 1
for word in excludes:
del(counts[word])
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
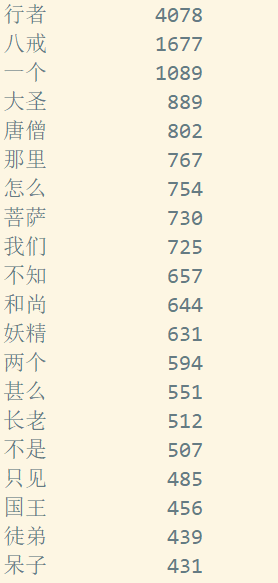
for i in range(20):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))运行结果:















 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









