






Fuck!
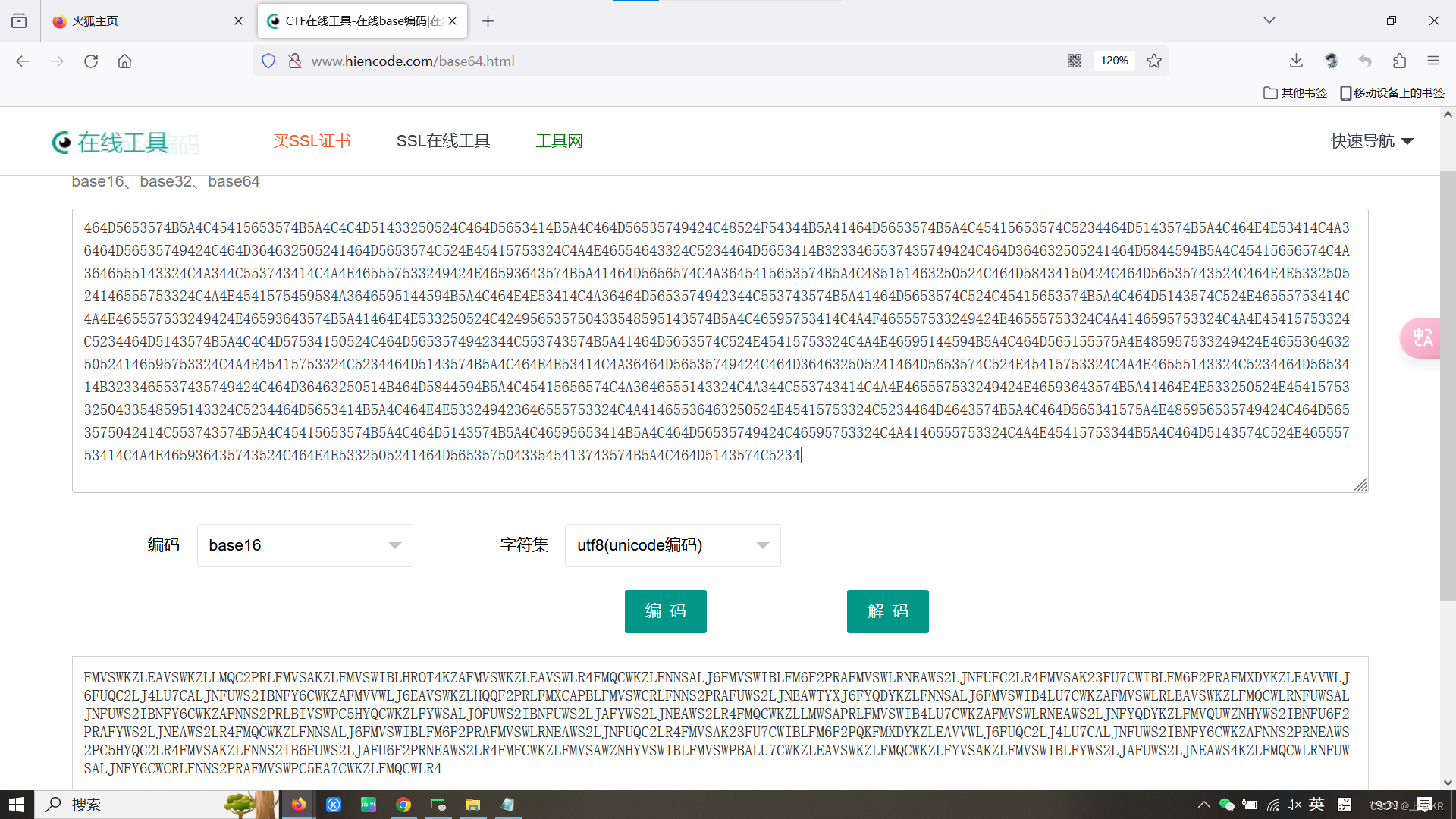
看上去是base编码,先尝试用base64解码,解码失败。然后从base16开始尝试,解码成功,得到另一串编码。
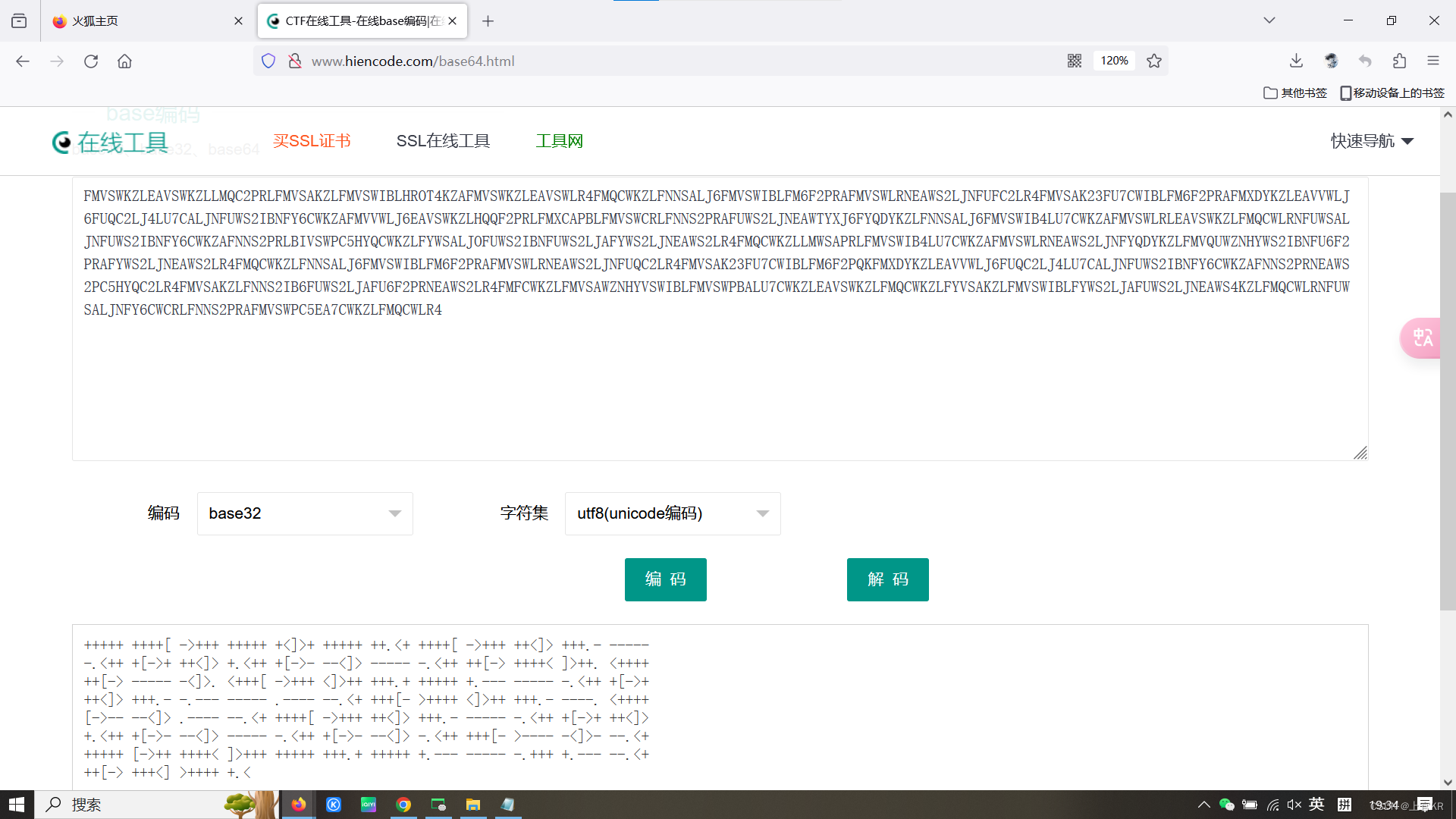
得到的第二个编码也是base编码,从base16开始尝试,解码失败,尝试base32,解码成功,得到一串brainfuck编码。

解码,得到flag
XX+CC

根据题目可知,这题是XXencode密码加上凯撒密码,先解码得到凯撒
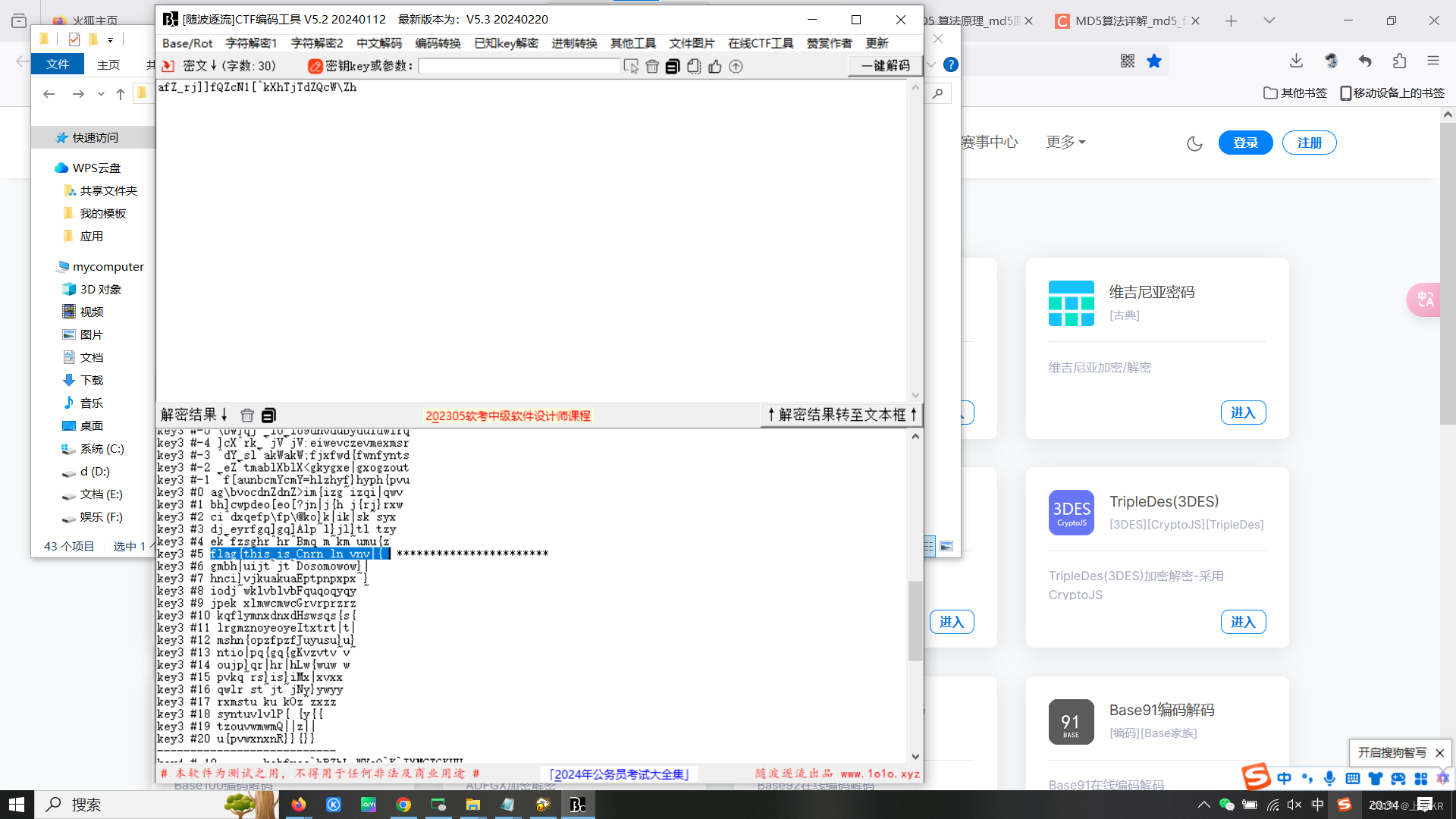
尝试直接把凯撒放到随波逐流里跑,得到的flag是错的,观察发现后半段是乱码,查阅资料后发现是变异凯撒。
普通的凯撒是字母与字母之间偏移,这里的凯撒有特殊字符,应该是ASCII代码偏移。
方法一:

判断偏移量:
text1="afZ_rj]]fQZcN1"
text2="flag{this_is_C"
text3="h"
text4="}"
for i in range(0,len(text1)):
offset=ord(text2[i])-ord(text1[i])
print(offset)
for j in range(0,len(text3)):
offset=ord(text4[j])-ord(text3[j])
print(offset) python计算一下前后两段的偏移量

前半段解码:
text="afZ_rj]]fQZcN1"
flag=""
for i in range(0,len(text)):
flag+=chr(ord(text[i])+(i+5))
print(flag)由第一个py得,前半段偏移量是从5开始依次递增,解码得flag{this_is_C
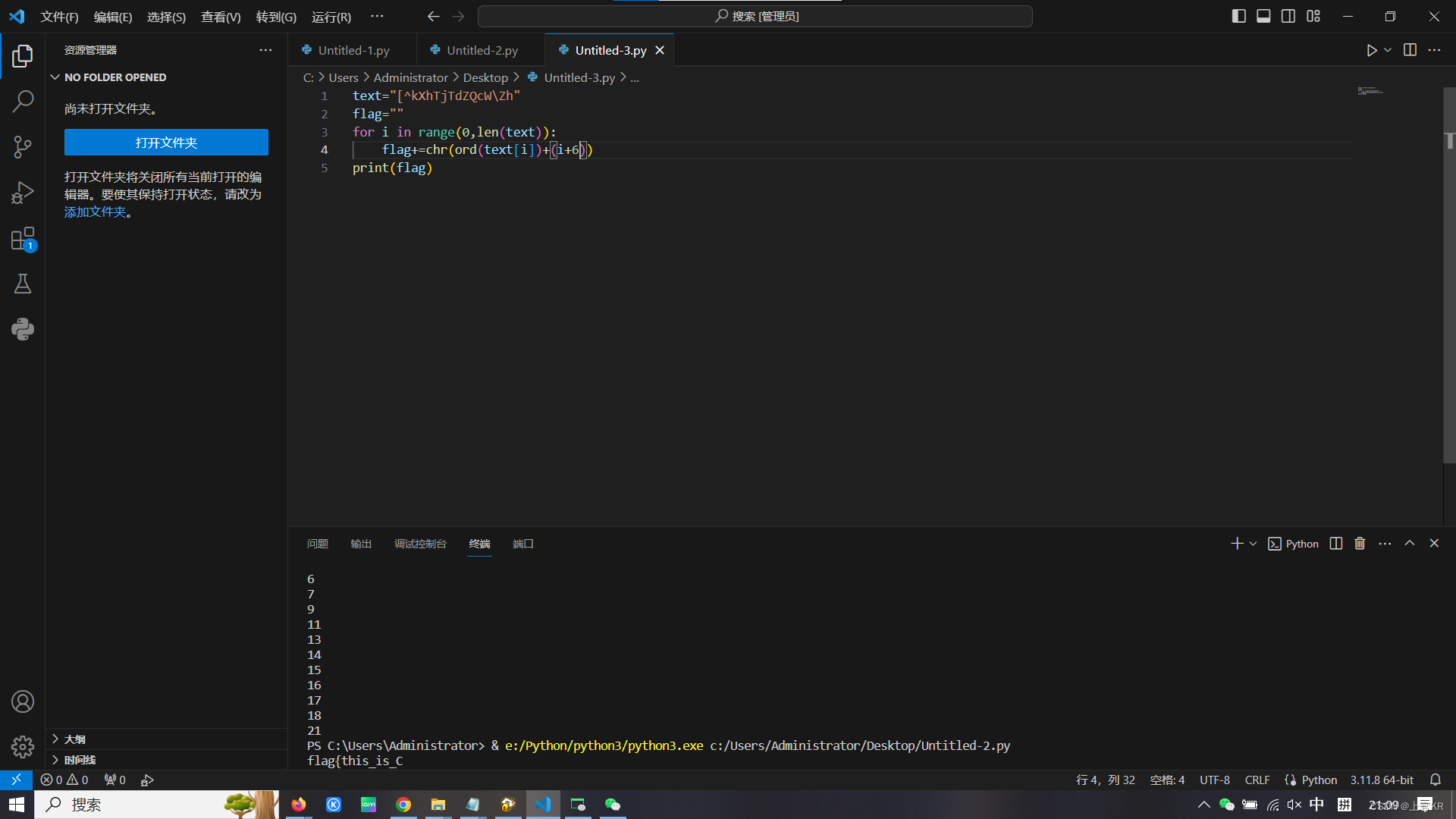
后半段解码:
text="[^kXhTjTdZQcW\Zh"
flag=""
for i in range(0,len(text)):
flag+=chr(ord(text[i])+(i+6))
print(flag)根据前半段逐个加一的规律,尝试解码后半段,发现后半段从偏移量6开始逐个加一,解码得aesar_variation}
方法二:(师姐的方法)
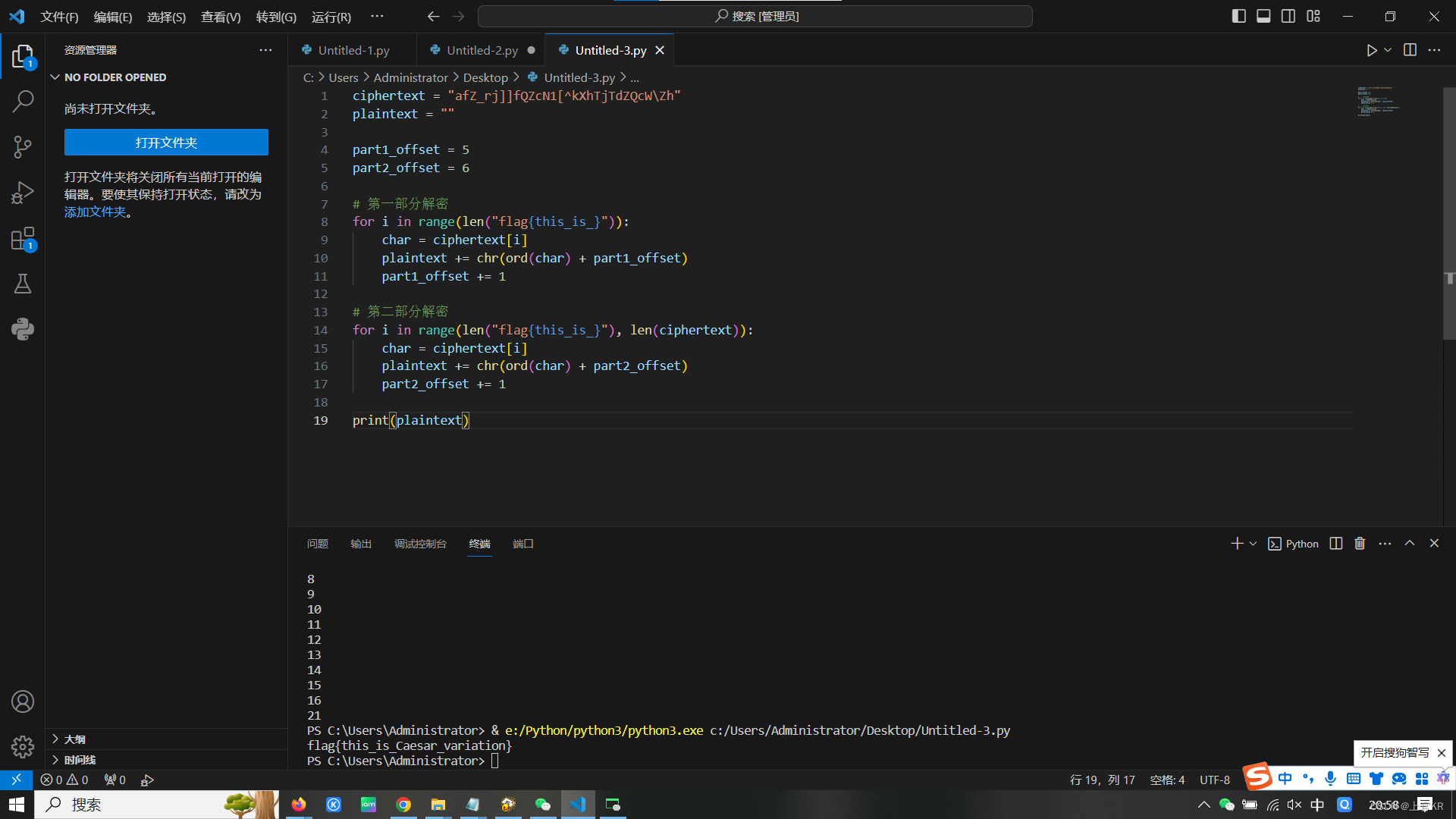
将前半段和后半段放在一起,更便捷,直接得到完整flag
ciphertext = "afZ_rj]]fQZcN1[^kXhTjTdZQcW\Zh"
plaintext = ""
part1_offset = 5
part2_offset = 6
# 第一部分解密
for i in range(len("flag{this_is_}")):
char = ciphertext[i]
plaintext += chr(ord(char) + part1_offset)
part1_offset += 1
# 第二部分解密
for i in range(len("flag{this_is_}"), len(ciphertext)):
char = ciphertext[i]
plaintext += chr(ord(char) + part2_offset)
part2_offset += 1
print(plaintext)解释:
这段代码是一个简单的解密程序,它接受一个密文(ciphertext)并尝试将其解密为明文(plaintext)。程序分为两部分,每部分使用不同的偏移量进行解密。
首先,我们看一下代码中的变量和它们的初始化:
ciphertext:这是待解密的密文字符串。
plaintext:这是用于存储解密后的明文字符串的变量,初始化为空字符串。
part1_offset 和 part2_offset:这两个变量分别用于存储第一部分和第二部分的解密偏移量。代码的逻辑如下:
第一部分解密:
遍历密文中与"flag{this_is_}"字符串长度相等的部分。
对于每个字符,将其ASCII码值加上part1_offset,然后将结果转换为字符。
将解密后的字符添加到plaintext字符串中。
每次迭代,part1_offset增加1。第二部分解密:
从密文中"flag{this_is_}"字符串长度的下一个字符开始遍历到密文的末尾。
对于每个字符,将其ASCII码值加上part2_offset,然后将结果转换为字符。
将解密后的字符添加到plaintext字符串中。
每次迭代,part2_offset增加1。最后,打印解密后的plaintext字符串。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









