







Redis(Remote Dictionary Server)
-
特征:
- 数据间没有必然的关联关系
- 内部采用单线程机制进行工作
- 高性能。官方提供测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000次/s。
- 多数据类型支持:string(字符串类型)、list(列表类型)、hash(散列类型)、set(集合类型)、sorted_set(有序集合类型)
- 持久化支持。可以进行数据灾难恢复
-
应用:
- 为热点数据加速查询(主要场景)、如热点商品、热点新闻、热点资讯、推广类等提高访问量信息等。
- 任务队列、如秒杀、抢购、购票等
- 即时信息查询,如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等
- 时效性信息控制,如验证码控制,投票控制等
- 分布式数据共享,如分布式集群构架中的session分离
- 消息队列
- 分布式锁
-
数据类型:对应了java中的数据类型
- string --> String
- hash --> Hashmap
- list --> LinkList
- set --> HashSet
- sorted_set --> TreeSet
-
redis数据储存格式:
- redis自身是一个Map,其中所有的数据都是采用key:value的形式存储
- 数据类型指的是存储的数据的类型,也就是value部分的类型,key部分永远都是字符串
-
String类型:
-
分类:
-
string:普通字符串
int:整数类型,可以做自增、自减操作
float:浮点类型,可以做自增、自减操作
-
-
不管是那种格式,底层都是字节数组形式存储,只不过编码方式不同
-
字符串类型的最大空间不能超过512m
-
String类型的常见命令:
-
- SET:添加或者修改已经存在的一个String类型的键值对 - GET:根据key获取String类型的value - MSET:批量添加多个String类型的键值对 - MGET:根据多个key获取多个String类型的value - INCR:让一个整型的key自增1 - INCRBY:让一个整型的key自增并指定步长,例如:incrby num 2 让num值自增2 - SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行 - SETEX:添加一个String类型的键值对,并且指定有效期
-
-
-
Hash类型:
-
HSET key field value:添加或修改hash类型key的field的值 HGET key field:获取一个hash类型key的field值 HMSET:批量添加多个hash类型key的field的值 HMGET:批量获取多个hash类型key的field的值 HGETALL:获取一个hash类型的key中的所有的field和value HKEYS:获取一个hash类型的key中所有的field HVALS:获取一个hash类型的key中所有的value HINCRBY:让一个hash类型key的字段值自增并指定步长 HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
-
-
List类型:
-
特征与LinkedList类似:
有序 元素可以重复 插入和删除快 查询速度一般List常见命令:
-
LPUSH key element ...:向列表左侧插入一个或多个元素 LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil RPUSH key element ...:向列表右侧插入一个或多个元素 RPOP key:移除并返回列表右侧的第一个元素 LRANGE key star end:返回一段角标范围内的所有元素 BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil。如果本来没有元素,但是在等待的时候元素插入进来,就可以返回插入的这个元素
总结:
如何利用List结构模拟一个栈?
入口和出口在同一边如何利用List结果模拟一个队列?
入口和出口在不同边如何利用List结果模拟一个阻塞队列?
入口和出口在不同边 出队时采用BLPOP或BRPOP -
-
-
Set类型
-
具备与HashSet类似的特征:
无序 元素不可重复 查找快 支持交集、并集、差集等功能Set类型的常见命令
-
SADD key member ...:向set中添加一个或多个元素 SREM key member ...:移除set中的指定元素 SCARD key:返回set中元素的个数 SISMEMBER key member:判断一个元素是否存在于set中 SMEMBERS:获取set中的所有元素 SINTER key1 key2 ...:求key1和key2的交集 SDIFF key1 key2 ...:求key1和key2的差集 SUNION key1 key2 ...:求key1和key2的并集
-
-
-
SortSet类型:
-
Redis的SortedSet是一个可排序的set集合,与java中的TreeSet有些类似,但底层数据结构却差别很大。
SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加hash表
SortedSet具备下列特性:
可排序 元素不重复 查询速度快因为SortedSet的可排序特性,经常被用来实现排行榜这样的功能
SortedSet类型的常见命令:
-
ZADD key score member:添加一个或多个元素到sorted set,如果已经存在则更新其score值 ZREM key member:删除sorted set中的一个指定元素 ZSCORE key member:获取sorted set中的指定元素的score值 ZRANK key member:获取sorted set中的指定元素的排名 ZCARD key:获取sorted set中的元素个数 ZCOUNT key min max:统计score值在给定范围内的所有元素的个数 ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值 ZRANGE key min max:按照score排序后,获取指定排名范围内的元素 ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素 ZDIFF、ZINTER、ZUNION:求差集、交集、并集 注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可
-
-
-
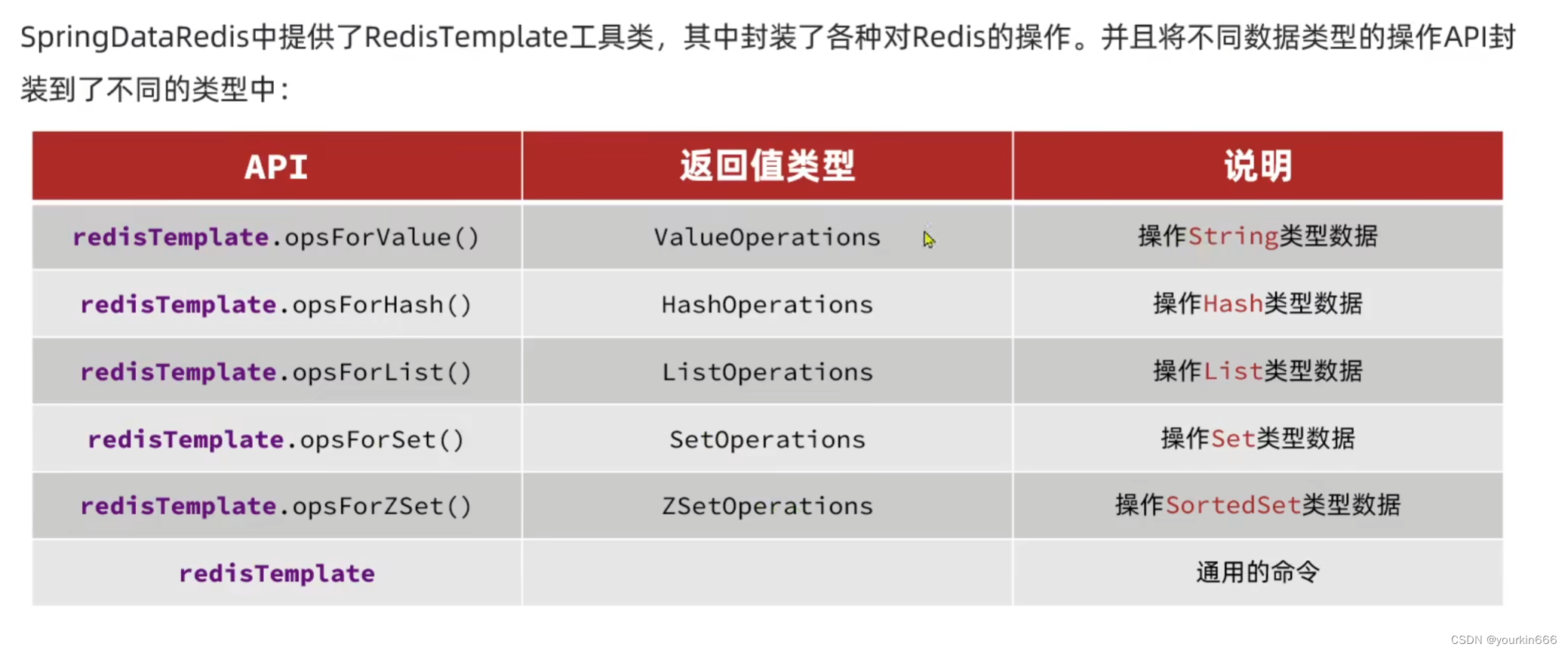
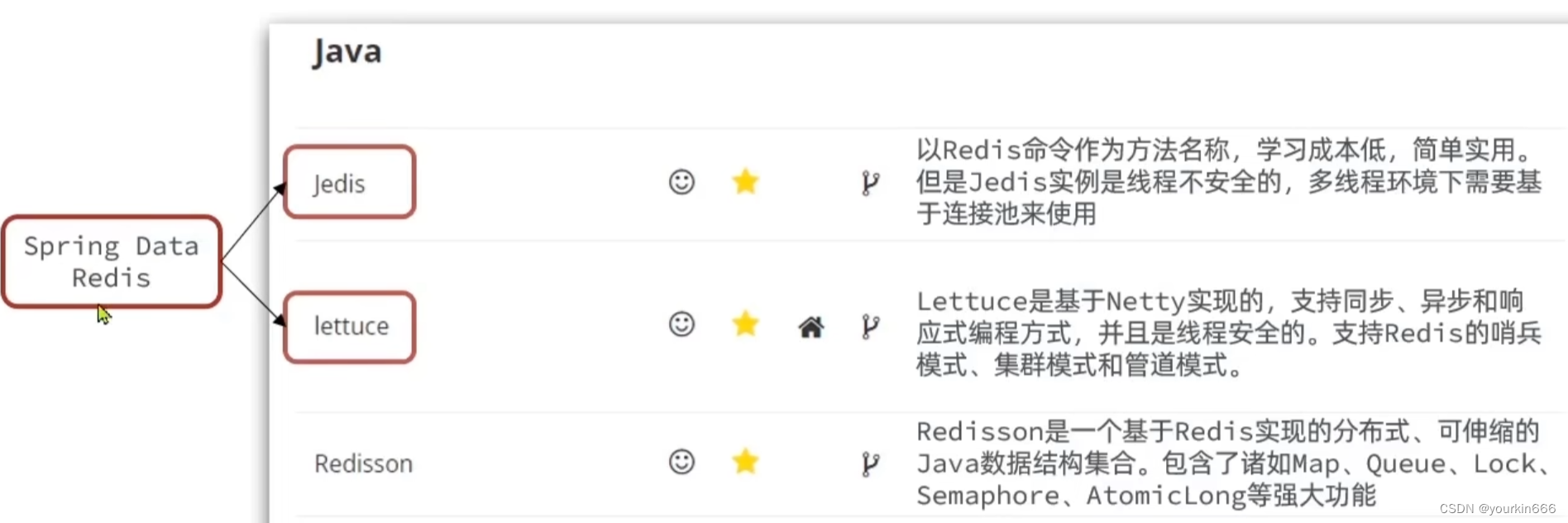
Redis的java客户端:
-
Spring Data Redis:
- 提供了对不同Redis客户端的整合(lettuce和jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、字符串、String对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
-
-
SpringDataRedis的序列化方式:
-
RedisTemplate可以接收任意Object作为值写入Reids,只不过在写入前会将Object序列化为字节的形式,默认为JDk序列化
- 缺点:可读性差,内存占用较大(变长了)、
-
相应的也有两种序列化处理方法:“
-
自定义RedisTemplate,修改序列化器为GenericJacksonRedisSerializer
-
直接就使用StringRedisTemplate,写入对象时去手动序列化为JSON,读取就反序列化
//要用到JSON或者FastJSOn工具 private static final ObjectMapper mapper = new ObjectMapper(); //比如你要存入一个User对象 User user = new User("yourkin666", 20); //你要去用JSON工具去序列化 String jsom = mapper.writeValueAsString(user); //直接存这个json stringRedisTemplate.opsForValue().set("user:1", json); //再来演示一边取出来的步骤 String jsonUser = stringRedisTemplate.opsForValue().get("user:1"); User user1 = mapper.readValue(jsonUser, User.class);
-
-
原理:










































 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









