







Apache Sqoop 是一个用于在 Hadoop 和关系型数据库之间高效传输数据的工具。
它支持从关系型数据库(如 MySQL、Oracle、PostgreSQL 等)导入数据到 Hadoop 的 HDFS、Hive 或 HBase 中,同时也支持从 Hadoop 导出数据到关系型数据库。
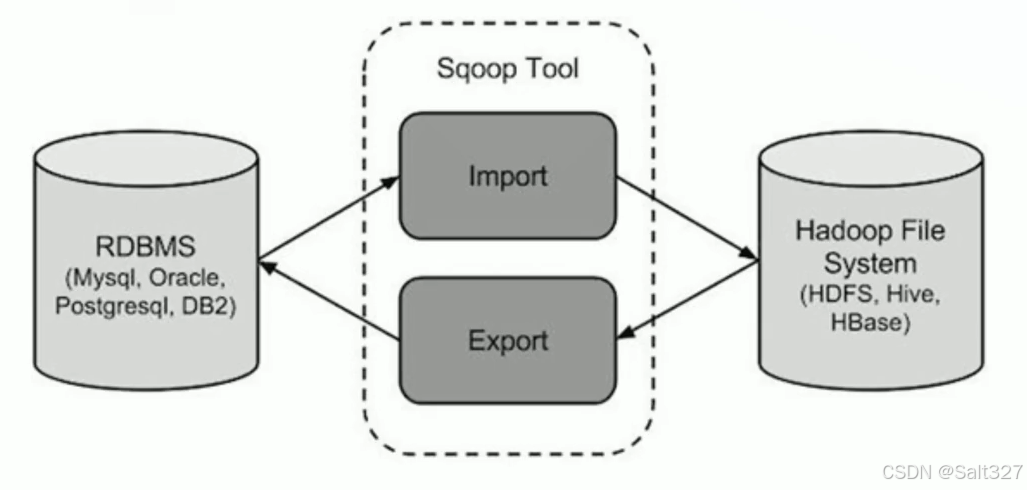
下面我以mysql的导入和导出作为演示
查看MySQL的数据库
sqoop list-databases \
--connect jdbc:mysql://localhost:3306 \
--username root \
--password 123456反斜杠[ \ ]:
- 换行继续输入代码
sqoop list-databases:
- 打印数据库列表
--connect jdbc:mysql://localhost:3306:
- --connect:指定数据库的 JDBC 连接字符串
- 这里为连接MySQL,端口号3306
--username root:
- --username:数据库的用户名
- 这里为我的用户名root
--password 123456:
- --password:数据库的密码
- 这里为我的密码123456
+--------------------+
| Database |
+--------------------+
| information_schema |
| hivedb |
| mysql |
| performance_schema |
| sys |
+--------------------+
查看MySQL的数据库中的表
sqoop list-tables \
--connect jdbc:mysql://localhost:3306/mysql \
--username root \
--password 123456通过文件传递参数(脚本)
在执行Sqoop命令时,如果每次执行的命令都相似,那么可以把相同的参数抽取出来,放在一个文本文件中,把执行时的参数加入到这个文本文件为参数即可,这个文本文件可以用 --options-file 来指定,平时可以用定时任务来执行这个脚本,避免每次手工操作
导入数据
| 通用参数 | 作用 |
| --connect | 指定数据库的 JDBC 连接字符串。 |
| --username | 数据库的用户名 |
| --password | 数据库的密码 |
| --table | 要导入的表名 |
| --target-dir | HDFS 上的目标目录 |
| --fields-terminated-by | 字段之间的分隔符 |
| --lines-terminated-by | 行之间的分隔符 |
基本导入
sqoop import \
--connect jdbc:mysql://<MySQL服务器地址>:<端口号>/<数据库名> \
--username <用户名> \
--password <密码> \
--table <表名> \
--target-dir <HDFS目标目录> \
--fields-terminated-by <字段分隔符> \
--lines-terminated-by <行分隔符> \
--num-mappers <Map任务数量>
- --connect:指定数据库的 JDBC 连接字符串。
- --username 和 --password:数据库的用户名和密码。
- --table:要导入的表名。
- --target-dir:HDFS 上的目标目录。
- --fields-terminated-by:字段之间的分隔符。
- --lines-terminated-by:行之间的分隔符。
- --num-mappers:并行处理的 Map 任务数量。
导入成功了以后默认导入的为txt文件
例子:
假设要导入的表是这样的
+----+--------+------------+------------+---------+
| id | name | position | department | salary |
+----+--------+------------+------------+---------+
| 1 | 张三 | 软件工程师 | 技术部 | 8000.00 |
| 2 | 李四 | 产品经理 | 产品部 | 9500.00 |
| 3 | 王五 | UI设计师 | 设计部 | 7500.00 |
| 4 | 赵六 | 项目经理 | 项目管理部 | 10000.00|
+----+--------+------------+------------+---------+
导入数据到hdfs
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table emp \
--target-dir sqoop.test/emp反斜杠[ \ ]:
- 换行继续输入代码
sqoop list-databases:
- 打印数据库列表
--connect jdbc:mysql://localhost:3306:
- --connect:指定数据库的 JDBC 连接字符串
- 这里为连接MySQL,端口号3306
--username root:
- --username:数据库的用户名
- 这里为我的用户名root
--password 123456:
- --password:数据库的密码
- 这里为我的密码123456
--table emp:
- 要导入的表名
- 这里我要导入的表名为
--target-dir sqoop.test/emp:
- 导入到 HDFS 上的目标目录(可以没有,导入会自动生成)
- 这里我导入到 /sqoop.test/emp
导入完成后的文件(.txt)是这样的
1,张三,软件工程师,技术部,8000.00
2,李四,产品经理,产品部,9500.00
3,王五,UI设计师,设计部,7500.00
4,赵六,项目经理,项目管理部,10000.00因为在导入的时候没有设置字段分隔符和行分隔符
字段分隔符默认为 (,)
行分割符默认为 换行符(\n)
有条件的导入
指定列导入
如果想导入某几列,可以使用 --columns
--columns '列名1,列名2'
假如有一个mysql的表,内容如下:
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
position VARCHAR(100),
department VARCHAR(100),
salary DECIMAL(10, 2)
);
INSERT INTO employees (name, position, department, salary) VALUES
('张三', '软件工程师', '技术部', 8000.00),
('李四', '产品经理', '产品部', 9500.00),
('王五', 'UI设计师', '设计部', 7500.00),
('赵六', '项目经理', '项目管理部', 10000.00);
导入 name 和 salary 列,参数如下
--columns 'name,salary' 指定条件导入
导入表的时候也可以通过指定的条件来导入,具体参数使用 --where
--where '条件'
例如 要导入id大于20的记录:
--where 'id>20'指定SQL导入
Sqoop还可以通过自定义的SQL来进行导入,通过 --query 参数以代替 --table、--colums、--where 来进行导入,这样就最大化的用到了SQL的灵活性
注意:在通过 --query 导入数据时,必须要指定 --target-dir
如果你想通过并行的方式导入结果,每个map task需要执行SQL语句的副本,结果会根据Sqoop推测的边界条件分区。query必须包含$CONDITIONS。这样每个Sqoop程序都会被替换为一个独立的条件。同时你必须指定 --split-by 分区
例子:
这是正常使用--table、--colums、--where 来进行导入
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table emp \
--columns 'id, name, salary' \
--where 'salary>5000.00' \
--target-dir sqoop.test/emp通过 --query 参数以代替 --table、--colums、--where 来进行导入:
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--query "SELECT id, name, salary FROM emp WHERE salary > 5000.00 AND \$CONDITIONS" \
--target-dir /sqoop.test/emp \注意事项:单双引号区别
单引号 (')
在导入数据时,默认的字符引号时单引号,这样Sqoop在解析的时候就安装字面量来解析,不会做转移
- 字面值:单引号内的所有字符都会被当作字面值处理,不会进行变量替换或转义字符解析。
- 转义字符:单引号内不能使用转义字符,包括 \、\' 等。
- 变量替换:单引号内的变量不会被替换。
双引号 (")
如果使用了双引号,用特殊字符的时候就需要在特殊字符前面加上转义字符 \ 进行解析
- 变量替换:双引号内的变量会被替换为其值。
- 转义字符:双引号内可以使用转义字符,如 \n、\t、\" 等。
- 特殊字符:双引号内的某些特殊字符,如 $
导入到hive中
Sqoop的导入工具的主要功能的时将数据上传到HDFS中的文件中。如果您有一个与HDFS集群相关联的Hie,Sqoop还可以通过生成执行CREATE TABLE语句来定义Hive中的数据,从而将数据导入到Hive中。将数据导入到Hive中就需要在Sqoop命令行中添加 --hive-import 选项。
如果Hive表已经存在,则可以指定 --hive-overwrite,以代表必须替换单元中的现有表。在将数据导入成HDFS或省略此步骤之后,Sqoop将生成一个Hive脚本,其中包含使用Hive的类型定义列的CREATE表操作,并生成 LOAD Data INPATH 语句将数据文件移动到Hive的仓库目录中。
| 参数 | 作用 |
| --hive-home | 覆盖环境配置中的 $HIVE_HOME,默认可以不配置 |
| --hive-import | 指定导入数据到Hive中 |
| --hive-overwrite | 覆盖当前已有的数据 |
| --create-hive-table | 是否创建hive表,如果已有则失败 |
| --hive-table | 设置要导入的Hive中的表名 |
例子:
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table emp \
--hive-import \
--hive=-overwrite \
--hive-table "emp3" \
--hive-database db2这里就不许需要填写 --target-dir 参数了,因为要导入到Hive中
导出数据
| 通用参数 | 作用 |
| --connect | 指定数据库的 JDBC 连接字符串。 |
| --username | 数据库的用户名 |
| --password | 数据库的密码 |
| --table | 要导出的表名 |
| --export-dir | HDFS 上的源目录 |
| --fields-terminated-by | 字段之间的分隔符 |
| --lines-terminated-by | 行之间的分隔符 |
前面我们讲解了如何导入,导入和导出操作类似,只需要修改一些参数,快速了解如何导出数据
sqoop export \
--connect jdbc:mysql://<MySQL服务器地址>:<端口号>/<数据库名> \
--username <用户名> \
--password <密码> \
--table <表名> \
--export-dir <HDFS源目录> \
--input-fields-terminated-by <字段分隔符> \
--input-lines-terminated-by <行分隔符>
- --connect:指定数据库的 JDBC 连接字符串。
- --username 和 --password:数据库的用户名和密码。
- --table:要导出的表名。
- --export-dir:HDFS 上的源目录。
- --input-fields-terminated-by:字段之间的分隔符。
- --input-lines-terminated-by:行之间的分隔符。
例如:
导入与导出案例
假设在MySQL上有一个员工表,它位于名为test的数据库下,如下
-- 创建员工表
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
position VARCHAR(100),
department VARCHAR(100),
salary DECIMAL(10, 2)
);
-- 插入10行示例数据
INSERT INTO employees (name, position, department, salary) VALUES
('张三', '软件工程师', '技术部', 8000.00),
('李四', '产品经理', '产品部', 9500.00),
('王五', 'UI设计师', '设计部', 7500.00),
('赵六', '项目经理', '项目管理部', 10000.00),
('孙七', '运维工程师', '运维部', 8500.00),
('周八', '数据分析师', '数据分析部', 9000.00),
('吴九', '市场专员', '市场部', 6500.00),
('郑十', '销售经理', '销售部', 11000.00),
('钱十一', '财务主管', '财务部', 12000.00),
('陈十二', '人力资源经理', '人力资源部', 10500.00);
+----+----------+------------+------------+---------+
| id | name | position | department | salary |
+----+----------+------------+------------+---------+
| 1 | 张三 | 软件工程师 | 技术部 | 8000.00 |
| 2 | 李四 | 产品经理 | 产品部 | 9500.00 |
| 3 | 王五 | UI设计师 | 设计部 | 7500.00 |
| 4 | 赵六 | 项目经理 | 项目管理部 | 10000.00|
| 5 | 孙七 | 运维工程师 | 运维部 | 8500.00 |
| 6 | 周八 | 数据分析师 | 数据分析部 | 9000.00 |
| 7 | 吴九 | 市场专员 | 市场部 | 6500.00 |
| 8 | 郑十 | 销售经理 | 销售部 | 11000.00|
| 9 | 钱十一 | 财务主管 | 财务部 | 12000.00|
| 10 | 陈十二 | 人力资源经理| 人力资源部 | 10500.00|
+----+----------+------------+------------+---------+
步骤1:导入
导入这个员工表到hdfs中的 sqoop.data/emp 目录下
sqoop import \
--connect jdbc:mysql://localhost:3306/test \
--username root \
--password 123456 \
--table employees \
--target-dir sqoop.data/emp \
--m 1因为在导入的时候没有设置字段分隔符和行分隔符
字段分隔符默认为 (,)
行分割符默认为 换行符(\n)
导入完成后,HDFS 的 /sqoop.data/emp 目录下会生成一个数据文件,文件名类似于 part-m-00000
HDFS 文件内容:
1,张三,软件工程师,技术部,8000.00
2,李四,产品经理,产品部,9500.00
3,王五,UI设计师,设计部,7500.00
4,赵六,项目经理,项目管理部,10000.00
5,孙七,运维工程师,运维部,8500.00
6,周八,数据分析师,数据分析部,9000.00
7,吴九,市场专员,市场部,6500.00
8,郑十,销售经理,销售部,11000.00
9,钱十一,财务主管,财务部,12000.00
10,陈十二,人力资源经理,人力资源部,10500.00使用 hadoop fs -mv 命令将文件重命名
将 part-m-00000 重命名为 employees.csv:
hadoop fs -mv /sqoop.data/emp/part-m-00000 /sqoop.data/emp/employees.csv
步骤2:导出
导出hdfs上的员工表到MySQL中的 sqoop数据库中的 employees表格下
sqoop export \
--connect jdbc:mysql://10.10.10.160:localhost:3306/sqoop \
--username root \
--password 123456 \
--table employees \
--export-dir sqoop.data/emp \
--input-fields-terminated-by ',' \
--input-lines-terminated-by '\n'
设置字段分隔符为 (,)
设置行分割符为 换行符(\n)
导出后的表:
+----+----------+------------+------------+---------+
| id | name | position | department | salary |
+----+----------+------------+------------+---------+
| 1 | 张三 | 软件工程师 | 技术部 | 8000.00 |
| 2 | 李四 | 产品经理 | 产品部 | 9500.00 |
| 3 | 王五 | UI设计师 | 设计部 | 7500.00 |
| 4 | 赵六 | 项目经理 | 项目管理部 | 10000.00|
| 5 | 孙七 | 运维工程师 | 运维部 | 8500.00 |
| 6 | 周八 | 数据分析师 | 数据分析部 | 9000.00 |
| 7 | 吴九 | 市场专员 | 市场部 | 6500.00 |
| 8 | 郑十 | 销售经理 | 销售部 | 11000.00|
| 9 | 钱十一 | 财务主管 | 财务部 | 12000.00|
| 10 | 陈十二 | 人力资源经理| 人力资源部 | 10500.00|
+----+----------+------------+------------+---------+
就此导入与导出操作就完成了,如果你喜欢这篇文章,可以点赞关注支持一下

















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









