






1.整数在内存中的存储
众所周知,计算机只能识别二进制的语言,即0和1,整数在内存中的存储就是以二进制的形式存储的,int类型的整数占4个字节,是32个bit位

而在内存中,实质上存储的是二进制的补码形式。
原码
整数的原码就是将整数的二进制形式写出来。第一位是符号位,如果是正数,那么第一位为0,如果是负数,第一位是1。
反码
正数的反码就是它本身,负数的反码是符号位不变依然是1,其余各位取反(0变为1,1变为0)。
补码
正数的补码依旧是本身,负数的补码就是其反码在加上一个1.
例如
5的原反补码形式

-5的原反补码形式

在计算机中存储的都是补码的形式。
在调试窗口为了显示方便,显示的是16进制的形式,VS中采用的是小端字节序方式显示。
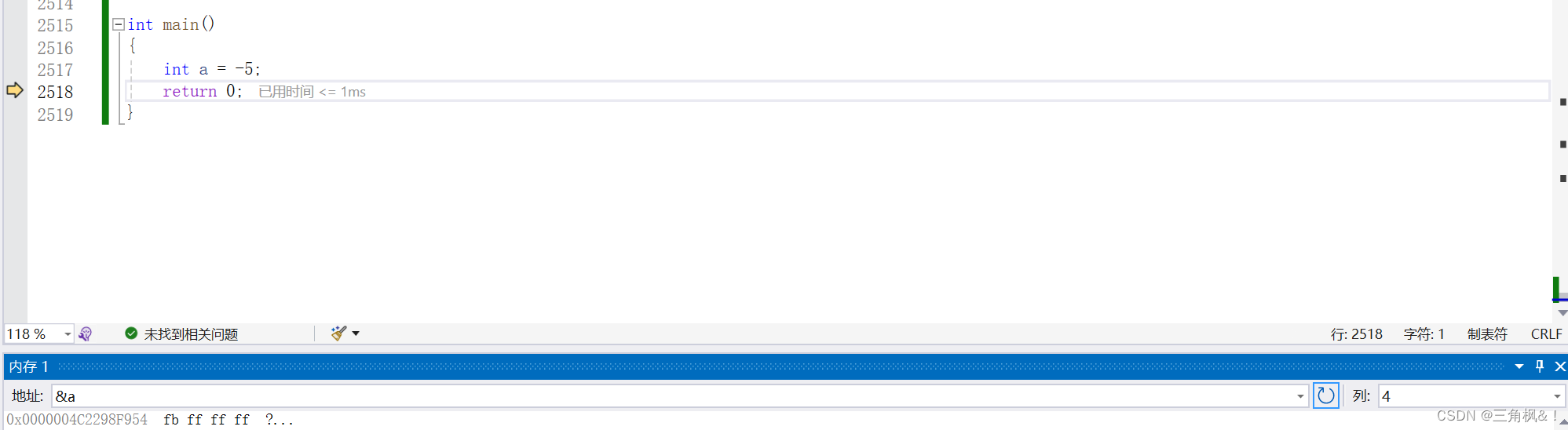
16进制很好理解,四个二进制为一组转换成16进制,32位二进制就变成了8个

正常来说应该是这样表示,那为什么是fbffffff的形式?是因为小端字节序方式是让原本的低位(个位)存储到了高地址处的存储形式,所以就有了倒置的写法,那大端字节序就是让原本的高位存储到高地址处,低位存储到低地址处。
判断大小端的方式
#include<stdio.h>
int judge()
{
int n = 1;
int ret = *(char*)&n; //把n的地址拿出来 然后转换成char*类型的 再解引用 取出来的就是它的第一个字节
return ret;
}
int main()
{
int ret=judge();
if(ret==1)
printf("小端");
else
printf("大端");
return 0;
}函数内部创建一个int变量赋值为1,然后将其地址拿出来强转成char*类型的,这样就能取出一个字节的地址

如果是小端取出来那一个字节应该是01,那么返回值应该是1,如果是大端取出来的一个字节应该是00,那么返回值应该是0,所以根据这个可以判断是大端还是小端。
ps:这里不能直接强转int类型,因为int类型强转成char无论怎么取都是默认取低位上的数(个位),那一直取得就都是1了,就无法分辨了。
2.浮点数在内存中的存储
| 符号位 | s | (-1)^s |
| 数字位 | m | m(1.xxxxx) |
| 科学计数法位 | e | 2^e |
浮点数的存储与整数的有所不同,具体存储方式分为上述表格中的三种形式。
32位的浮点数

第一个bit位是符号位 s为0是正数,s为1是负数
后8个位置用来存储e
剩下的23个位置用来存放有效的数字位
64位的浮点数
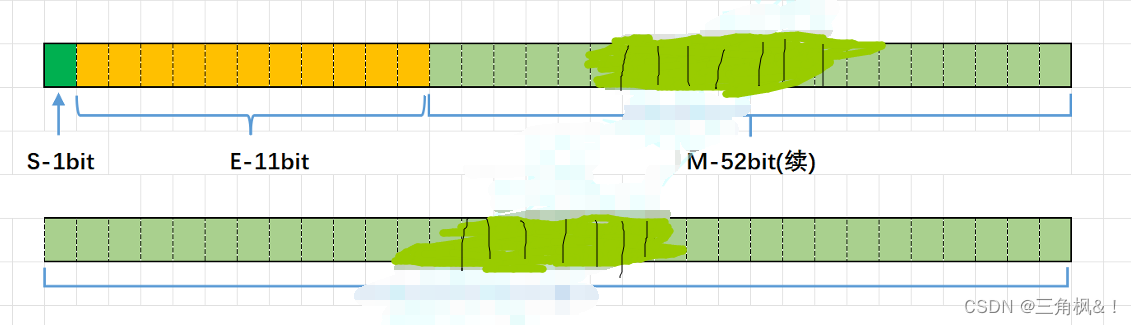
(忽略图片马赛克)
唯一的改变就是11个位置存储e
后52个位置存储有效数字位
例如十进制的5.0写成二进制就是101.0,写成科学计数法的方式就是1.01*2^2
此时s=0,m=1.01,e等于2
S符号位
第一个符号位就是正数保存0,负数保存1即可。
M有效数字位
1<=m<2,其实就是默认为1,那存储时就可以忽略这一位,直接保存小数点后面的位数,在用的时候再给1补回来即可。
E科学计数法位
因为科学计数法是可以出现负数的,32位中浮点数E有8位,范围在0~255之间,64位中E有11位,范围在0~2047之间。所以规定在存储E时要加上一个中间值,对于8位的E,这个中间数是127;对于11位的E,这个中间数是1023。比如32位下2^10,存储这个10时,就要变成137,2^-10,存储时就变成了117,变成了正数。
E取出时还分为三种情况
1.E不全为0或1
指数E的值减去127(1023),然后再给有效值M前加上一个1。
例如0.5

127+(-1)即为126(01111110),然后有效值就是0,补齐23位最后在内存中就是这种形式,取出时126-127,-1,然后给M加一个1即为1.0*2^(-1)即为0.5。
2.E全为0
浮点数E为1-127(1023),给有效值M前加上一个0,代表无穷接近0
3.E全为1
这时如果有效数字M全为0,那么代表无穷。
例题演示
#include <stdio.h>
int main()
{
int n = 9;
float* pFloat = (float*)&n;
printf("%d\n",n);
printf("%f\n",*pFloat);
* pFloat = 9.0;
printf("%d\n",n);
printf("%f\n",*pFloat);
return 0;
}分析:int n=9;n的类型是整形,那么存储在内存中应该是00000000000000000000000000001001,
强制转化成浮点型的存储方式,那么第一个符号位S=0,而E全是0,后面23位M是0000000000
0000000001001,那转换成浮点数就是0.00000000000000000001001*2^(-126)是一个很接近0的值,所以打印出来应该是0。
把pFloat改成9.0,然后打印小数就是9.0,存储为0 10000010 00100000000000000000000,
转换成整数形式就是1091567616。















 1950
1950

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









