






目录
一、引言
- Hadoop在大数据处理中的地位和优势
Hadoop是一个开源的分布式计算框架,它在大数据处理中扮演着举足轻重的角色。Hadoop之所以如此重要,主要有以下几个优势:
- 可扩展性:Hadoop可以处理大规模的数据集,无论是几百TB还是PB级别的数据,Hadoop都能轻松应对。其分布式计算架构使得数据可以在集群中的多个节点上进行并行处理,大大提高了处理效率。
- 成本效益:Hadoop使用普通的硬件设备就能构建大规模的集群,因此其成本相对较低。这使得中小企业甚至个人开发者也能利用Hadoop来处理大数据。
- 容错性:Hadoop采用了数据冗余和自动备份的机制,即使在某些节点出现故障时,也能保证数据的完整性和可用性。此外,Hadoop还能自动检测和修复数据错误,确保数据的准确性。
- 灵活性:Hadoop支持多种编程语言和数据处理工具,如Java、Python、Hive、Pig等。这使得开发者可以根据自己的需求和技能选择合适的工具和技术来处理大数据。
- 生态系统:Hadoop生态系统非常庞大和丰富,包括了许多与大数据处理相关的工具和项目,如HBase、ZooKeeper、Sqoop等。这些工具和项目为开发者提供了强大的支持和帮助,使得大数据处理变得更加容易和高效。
二、Hadoop概述
- Hadoop生态系统概览(HDFS、MapReduce、YARN等)
- Hadoop与其他大数据技术的比较(如Spark、Flink等)
三、Hadoop分布式文件系统(HDFS)
- HDFS的架构和原理
- 数据块(Block)和副本(Replication)
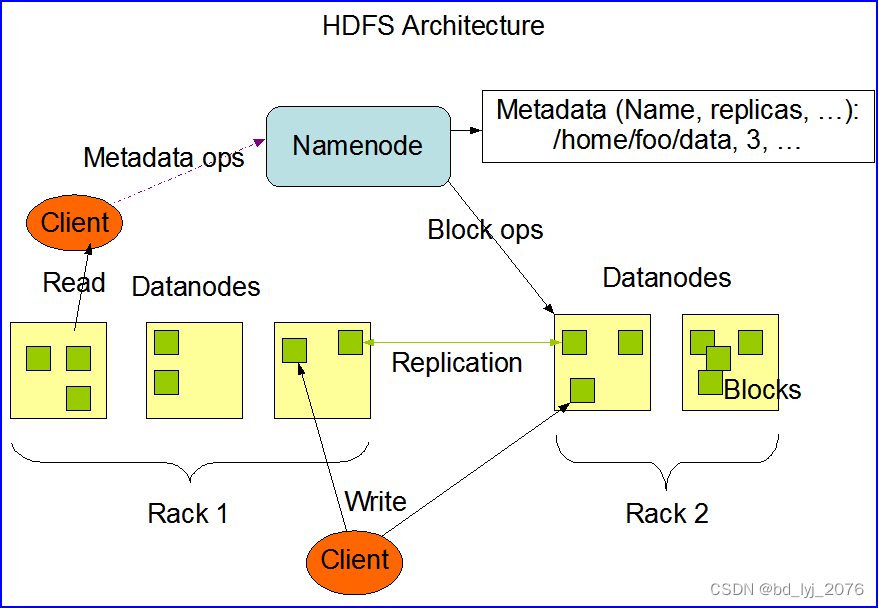
- NameNode和DataNode的角色
- NameNode:即是master:
- 管理HDFS的命名空间
- 配置副本策略
- 惯例数据块Blocks的映射欣喜
- 处理客户端读写请求
- DataNode:即是slave:
- master下达命令,DataNode执行操作
- 存储实际的数据块
- 执行数据块的读/写操作
- HDFS的特点和优势
- 高容错性
- 高扩展性
- 适合批处理
- HDFS的操作和API使用
- 文件创建、读取、删除等
- Java API和Hadoop Shell的使用示例
四、Hadoop MapReduce编程模型
- MapReduce的概念和原理
- 定义:MapReduce是一个分布式运算程序的编程框架,其核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
- 一个基本完整的MapReduce程序流程,包括:数据分片-数据映射-数据混洗-数据归约-数据输出
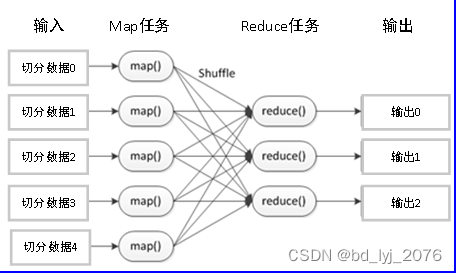
五、Hadoop生态系统工具
- Hive
- Hive的定义
hive是基于hadoop生态圈组件之一,它是一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为mapreduce任务进行运行。
hive的本质是将sql语句转换为mapreduce任务,使不熟悉java mapreduce开发人员也能编写数据查询程序。它定义了简单的类sql查询语言,称为hql,它允许熟悉sql的用户在hadoop上进行数据查询。同时,hive允许用户编写自己的map和reduce函数来处理内建函数无法处理的数据,扩展了hive的功能。
访问hive的三种方式:
- 设置内嵌模式
- 直连数据库模式
- 远程模式
下面是直连数据库模式的安装修改密码的例子:
- 安装mysql
1.拖动msql和hive的安装包到linux系统的/opt目录下
2.进入/opt目录,解压mysql安装包,命令:tar -xvf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar -C /opt
3.卸载系统自带的mariadb:rpm -qa | grep mariadb | xargs sudo rpm -e --nodeps
4.安装mysql几个包,命令:
| rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm |
| rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm |
| rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm |
| rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm |
| rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm |
5.启动mysql:systemctl start mysqld
6.查看初始密码,并复制它: cat /var/log/mysqld.log | grep password
7.使用初始密码登录mysql:mysql -uroot -p'xxxxxx'
8.更改mysql密码策略,并修改简单的密码(带分号;结尾,不然回车后提示未完成输入):
set global validate_password_policy=0;
set global validate_password_length=4;
9.设置简单的密码,如123456:set password=password("123456");
10.使用命令quit;退出,然后重新登录:mysql -uroot -p123456
11.设置root远程登录权限:grant all privileges on *.* to 'root'@'%' identified by '123456' with grant option;
12.重新加载授权表:flush privileges;
13.使用quit;退出mysql,在linux里设置mysql开启自启动:chkconfig mysqld on
六、Hadoop集群部署和管理
- 集群的启动和关闭
- 前置工作:在master里,修改/etc/ssh/sshd_config文件,把注释了在文件去掉#,PermitRootLogin yes 、PubkeyAuthentication yes、PasswordAuthentication yes
- 使用命令hdfs namenode -format开启集群
启动集群:
1.进入Hadoop安装目录:cd $HADOOP_HOME,分别使用以下语句启动集群:
使用命令sbin/start-dfs.sh,开启HDFS
2.重新执行命令sbin/start-dfs.sh,结果如下表示成功。
3.使用命令sbin/start-yarn.sh,开启yarn
4.开启日志mapred --daemon start historyserver
5.最后,在master、slave1、slave2、slave3使用jps查看,显示下图,说明Hadoop集群启动成功。
关闭集群:
- 仍然需要进入cd $HADOOP_HOME关闭集群命令:
- 使用命令sbin/stop-yarn.sh
- 使用命令sbin/stop-dfs.sh
- 使用命令mapred --daemon stop historyserver
监控Hadoop集群:
http://master:9870/

http://master:8088/
http://master:19888/

注意,重新开机后要重新启动Hadoop集群
七、总结和展望
- Hadoop在大数据领域的地位和趋势:
- 云化:将Hadoop处理系统迁移到云端将成为未来的趋势。云计算可以为企业提供更高效的资源利用、更快的部署速度和更低的维护成本。同时,云厂商还可以提供各种存储和计算服务,以满足不同的业务需求。
- 与机器学习和人工智能的整合:随着人工智能和机器学习的逐步普及,Hadoop处理系统也需要适应这个趋势。未来的Hadoop需要能够支持更多的机器学习算法和深度学习框架,以便更好地处理和分析复杂的数据集。
- 数据安全和隐私保护:随着大数据技术的广泛应用,数据安全和隐私保护成为了越来越重要的问题。Hadoop需要加强对数据的安全性和隐私性的保护,包括数据加密、访问控制、审计等功能。
- 性能和扩展性的提升:随着数据量的不断增长,Hadoop需要具有更高的性能和更好的扩展性来应对不断增长的数据需求。未来的Hadoop需要采用更加先进的算法和架构,以提高数据处理的速度和效率。
- Hadoop未来的发展方向和挑战:
- 性能优化:随着数据量的增长和复杂度的提高,Hadoop需要不断优化其性能以满足用户的需求。这包括优化数据存储、计算、传输等方面的性能。
- 易用性:Hadoop的复杂性和学习曲线较高,对于初学者来说不太友好。未来Hadoop需要提高其易用性,降低学习门槛,使得更多的用户可以轻松地使用Hadoop进行大数据处理和分析。
- 安全性:数据安全和隐私保护是Hadoop面临的重要挑战之一。未来Hadoop需要加强对数据的安全性和隐私性的保护,防止数据泄露和攻击。
- 对读者学习和使用Hadoop的建议:
- 明确学习目标:在学习Hadoop之前,需要明确自己的学习目标,例如掌握Hadoop的核心概念、架构和原理,学会使用Hadoop进行大数据处理和分析等。
- 系统学习:建议读者系统地学习Hadoop的相关知识,包括Hadoop的基础、HDFS、MapReduce、YARN等方面的内容。可以通过阅读Hadoop的官方文档、参加线上或线下的培训课程、参与实践项目等方式进行学习。
- 注重实践:学习Hadoop的过程中需要注重实践,通过编写MapReduce程序、使用Hive进行数据分析等方式来加深对Hadoop的理解和应用。
- 持续学习:Hadoop是一个不断发展的技术,需要不断学习和跟进最新的技术动态和最佳实践。建议读者定期关注Hadoop的官方博客、技术社区和开源项目等渠道,以获取最新的信息和资源。
通过以上架构组织博客内容,可以确保读者能够系统地了解Hadoop大数据开发的基础知识,并激发他们深入学习和实践Hadoop的兴趣。















 875
875

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









