






目录
工业互联网的兴起为制造业带来了前所未有的数据财富。如何利用这些数据,尤其是在Python的帮助下进行深入的数据分析,成为提升制造业效率和竞争力的关键。以下是详细的一课一得解析,我们将通过步骤分解,配以代码和图表,深入探讨Python在工业互联网数据分析中的应用。
一、环境搭建与数据准备
在开始之前,我们需要搭建Python数据分析环境,并准备数据。
1.环境搭建
我们需要安装Python以及相关的数据分析库,如下:
pip install numpy pandas matplotlib scikit-learn pymysql

2.数据准备
以某制造企业的设备运行数据为例,我们需要从数据库中提取数据。以下是数据准备的代码:
import pandas as pd
import pymysql
# 连接数据库
db_config = {
'host': 'localhost',
'user': 'root',
'password': '123456',
'db': 'industry_data',
'charset': 'utf8'
}
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 执行SQL查询
query = "SELECT * FROM equipment_data WHERE timestamp BETWEEN '2021-01-01' AND '2021-12-31'"
data = pd.read_sql(query, conn)
# 关闭连接
cursor.close()
conn.close()
# 数据预处理
data.dropna(inplace=True) # 处理缺失值
# 更多预处理步骤...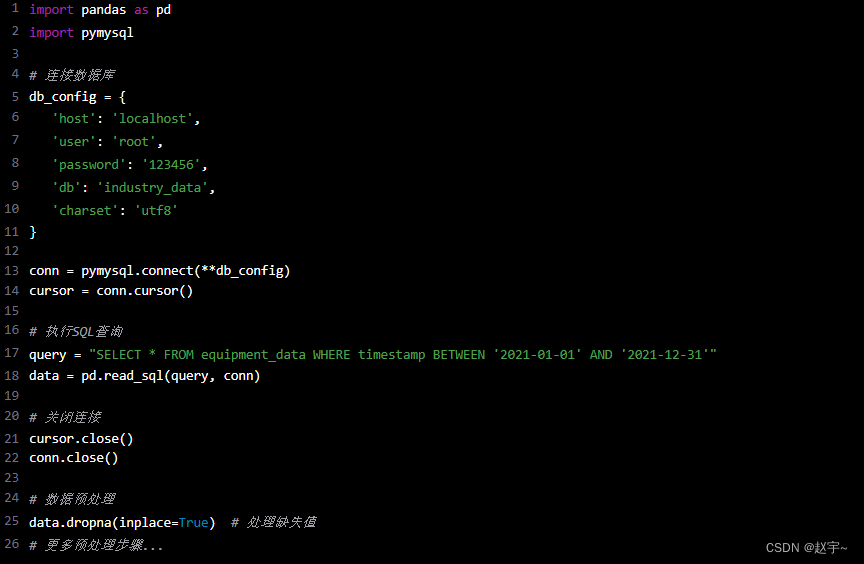
二、数据探索与可视化
数据准备完成后,我们进入数据探索和可视化阶段。
1.数据探索
我们首先对数据进行基本的统计描述:
# 查看数据描述
print(data.describe())![]()
2.数据探索
接下来,我们使用matplotlib进行数据可视化,以便更直观地理解数据。
import matplotlib.pyplot as plt
# 绘制设备运行时间的直方图
plt.figure(figsize=(10, 6))
plt.hist(data['run_time'], bins=20, color='blue', alpha=0.7)
plt.title('设备运行时间分布')
plt.xlabel('运行时间(小时)')
plt.ylabel('频数')
plt.grid(True)
plt.savefig('run_time_distribution.png')
plt.show()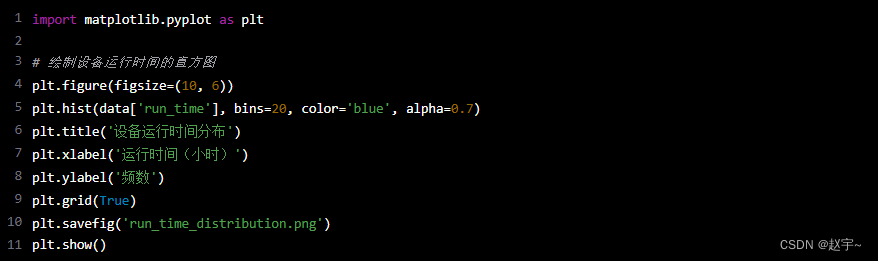
三、数据分析与模型构建
常见的数据分析为: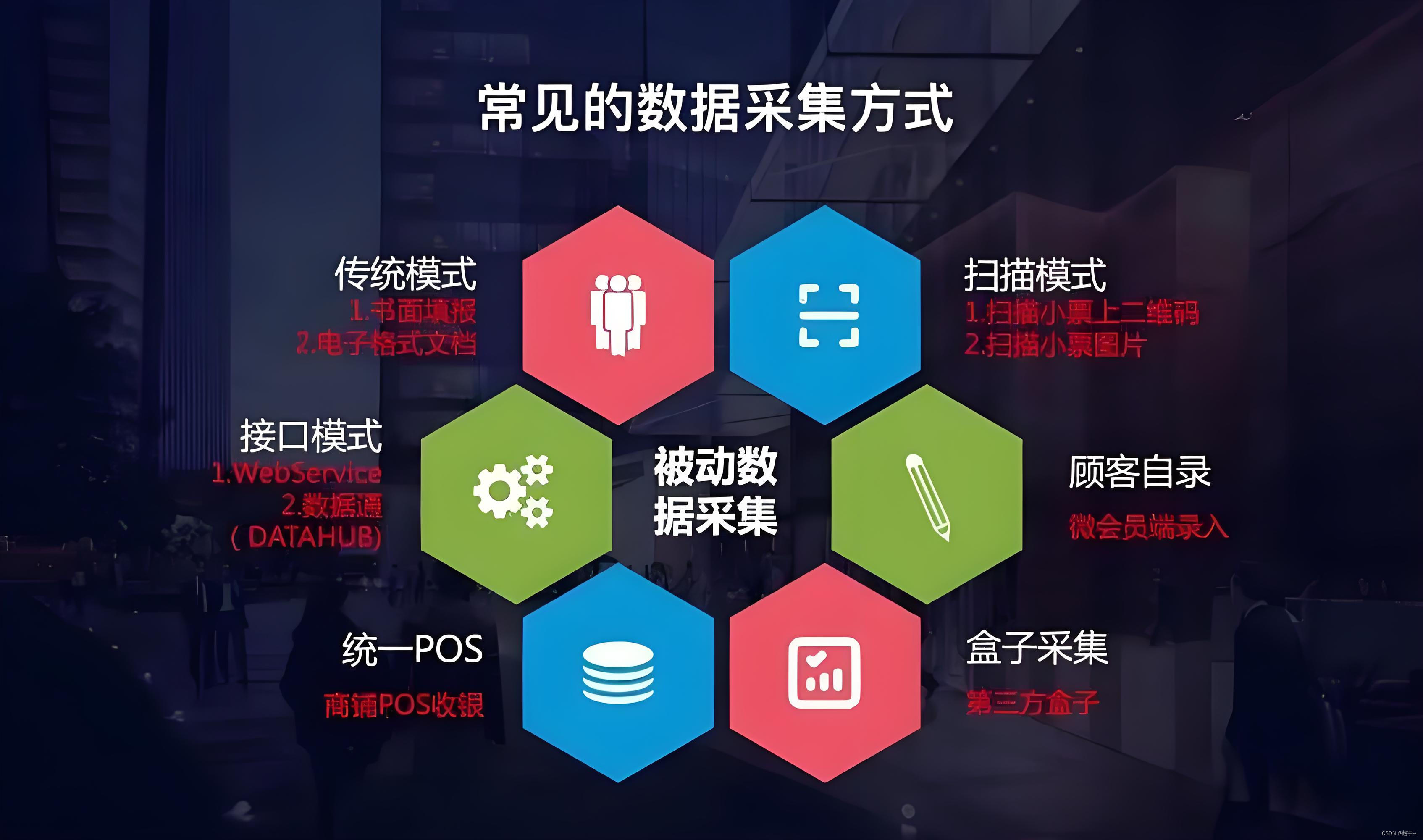
现在,我们开始深入数据分析,并构建预测模型。
数据分析通常包括以下几个步骤:
1. 数据采集
从不同的数据源获取数据,可能是数据库、文件、在线API或直接从设备收集的数据流。
2. 数据清洗
数据往往是不完整的,包含噪声和异常值。数据清洗包括:
- 填充或删除缺失值
- 识别和处理异常值
- 标准化或转换数据格式
3. 数据探索
通过统计和可视化手段,对数据进行初步探索,以了解数据的基本特征和分布情况。这可能包括:
- 描述性统计分析
- 数据可视化(例如,使用matplotlib或seaborn库)
- 探索数据之间的关系(例如,使用相关性分析)
4. 假设生成
基于数据探索的结果,生成关于数据背后潜在关系的假设。
模型构建
模型构建包括以下步骤:
1. 特征工程
特征工程是选择和构造有助于模型学习的特征的过程。包括:
- 特征选择:选择与目标变量相关的特征
- 特征提取:从原始数据中提取新特征
- 特征转换:对特征进行归一化、标准化等转换
2. 数据切分
将数据集切分为训练集、验证集和测试集:
- 训练集:用于训练模型
- 验证集:用于调整模型超参数
- 测试集:用于评估模型性能
3. 模型选择
选择适当的算法来构建模型。常见的机器学习算法包括:
- 线性回归
- 决策树
- 随机森林
- 支持向量机
- 梯度提升机
- 深度学习网络
4. 模型训练
使用训练数据集对模型进行训练。
5. 模型评估
使用验证集和测试集对模型进行评估。评估指标可能包括:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1分数
- ROC曲线和AUC值
6. 超参数调优
调整模型的超参数,以优化模型性能。常见的方法有网格搜索(Grid Search)、随机搜索(Random Search)和贝叶斯优化。
7. 模型部署
将训练好的模型部署到生产环境,进行实时预测或批量预测。
以下是一个简单的Python代码示例,演示了使用scikit-learn库进行数据切分、模型选择、训练和评估的过程:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 数据切分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化模型
model = RandomForestClassifier(n_estimators=10, random_state=42)
# 训练模型
model.fit(X_train, y_train)
# 预测
predictions = model.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, predictions)
print(f"Model accuracy: {accuracy:.2f}")四、结果解释与业务应用
模型的准确率是我们评估模型性能的一个指标。基于模型的结果,我们可以为业务提供以下建议:
- 根据模型预测,对即将发生故障的设备进行提前维护;
- 分析模型中的重要特征,优化设备的设计和运行参数;
- 定期更新模型,以适应新的数据和业务需求。
五、总结
通过本课程的学习,我们了解了如何使用Python进行工业互联网数据分析。从环境搭建、数据准备到数据探索、模型构建,每一步都是挖掘工业数据价值的关键。掌握这些技能,制造业企业和工程师们可以更好地利用数据,提高生产效率,降低成本,增强竞争力。















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









