






一:常见模块
1.1:常见模块
1.1.1:OS模块
OS模块>>>是与操作系统交互的一个接口!
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示 *
os.environ 获取系统环境变量 *
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果目标文件存在,返回True;如果path不存在,返回False *
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False *
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False *
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小1.1.2:SYS模块
在Python的标准库中,sys模块是一个常用而强大的工具,它提供了与Python解释器交互的函数和变量 !
sys.argv 命令行参数List,第一个元素是程序本身路径
*args=argument string 字符串参数
*argc =argument count 参数的个数
*argv =argument value 参数的值
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称sys.argv是一个变量,专门用来向python解释器传递参数,类似于shell脚本脚本编程中的位置变量;
import sys
print ("脚本文件是:",sys.argv[0]) //sys.argv[0]表示的是脚本的名字
print ("用户输入的参数数量是:",len(sys.argv)-1)
print ("所有的参数是:",sys.argv)
print ("用户输入的第一个参数",sys.argv[1])
print ("用户输入的第二个参数",sys.argv[2])
print ("用户输入的第三个参数",sys.argv[3])python test.py hello python kingimport sys
if len(sys.argv) !=2:
print "正确的使用方法",sys.argv[0],"IP列表文件"
print "例如: ./test.py /root/ip.txt"
sys.exit("参数数量不对")
C:\Users\26629\Desktop>python test.py 1
C:\Users\26629\Desktop>python test.py 1 2 -》出现报错需要使用异常处理来解决!
姝g‘鐨勪娇鐢ㄦ柟娉?test.py IP鍒楄〃鏂囦欢
渚嬪锛?./test.py /root/ip.txtTraceback (most recent call last):
File "test.py", line 12, in <module>
print "渚嬪锛?./test.py /root/ip.txt"
IOError: [Errno 28] No space left on device1.1.3:Time模块
时间模块:time与datatime
Python中表示时间的方式:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
import time
print(time.time()) # 时间戳:1487130156.419527
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串
print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time计算机认识的时间只能是'时间戳'格式,但是程序员可处理的或者说人类能看懂的时间有: '格式化的时间字符串','结构化的时间' ,则产生了不同时间格式之间的转换,转换关系如图:
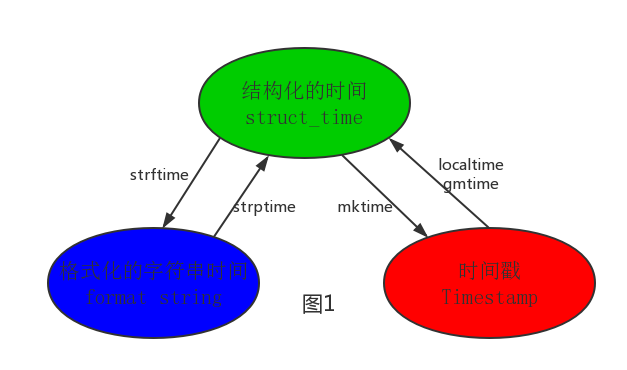
--------------------------按图1转换时间-------------------------------
localtime([secs])
# 将一个时间戳转换为当前时区的struct_time。secs参数未提供,则以当前时间为准。
time.localtime()
time.localtime(1473525444.037215)
# gmtime([secs]) 和localtime()方法类似,gmtime()方法是将一个时间戳转换为UTC时区(0时区)的struct_time。
# mktime(t) : 将一个struct_time转化为时间戳。
print(time.mktime(time.localtime()))#1473525749.0
# strftime(format[, t]) : 把一个代表时间的元组或者struct_time(如由time.localtime()和
# time.gmtime()返回)转化为格式化的时间字符串。如果t未指定,将传入time.localtime()。如果元组中任何一个
# 元素越界,ValueError的错误将会被抛出。
print(time.strftime("%Y-%m-%d %X", time.localtime()))#2016-09-11 00:49:56
# time.strptime(string[, format])
# 把一个格式化时间字符串转化为struct_time。实际上它和strftime()是逆操作。
print(time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X'))
#time.struct_time(tm_year=2011, tm_mon=5, tm_mday=5, tm_hour=16, tm_min=37, tm_sec=6,
# tm_wday=3, tm_yday=125, tm_isdst=-1)
#在这个函数中,format默认为:"%a %b %d %H:%M:%S %Y"。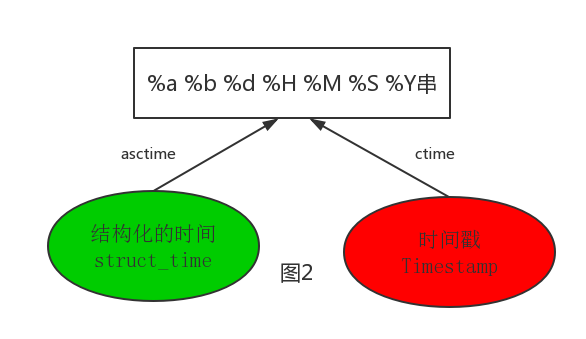
--------------------------按图2转换时间--------------------------------------------------------
# asctime([t]) : 把一个表示时间的元组或者struct_time表示为这种形式:'Sun Jun 20 23:21:05 1993'。
# 如果没有参数,将会将time.localtime()作为参数传入。
print(time.asctime())#Sun Sep 11 00:43:43 2016
# ctime([secs]) : 把一个时间戳(按秒计算的浮点数)转化为time.asctime()的形式。如果参数未给或者为
# None的时候,将会默认time.time()为参数。它的作用相当于time.asctime(time.localtime(secs))。
print(time.ctime()) # Sun Sep 11 00:46:38 2016
print(time.ctime(time.time())) # Sun Sep 11 00:46:38 2016时间加减
import datetime
print(datetime.datetime.now()) #返回 当前时间
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式
print(datetime.datetime.now() )
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2)) #时间替换1.1.4:Random模块
import random
print(random.random())#(0,1)----float 大于0且小于1之间的小数
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数
print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5]
print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合
print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌"
print(item)import random
def make_code(n):
res=''
for i in range(n):
s1=chr(random.randint(65,90))
s2=str(random.randint(0,9))
res+=random.choice([s1,s2])
return res
print(make_code(9))1.1.5:argparse模块
argsparse是python的命令行解析的标准模块,内置于python,不需要安装。这个库可以让我们直接在命令行中就可以向程序中传入参数并让程序运行 ,使用该模块定义程序所需的命令行参数和选项,以及它们的类型、默认值、帮助信息等。然后argparse会解析用户提供的命令行输入,并将其转换为易于使用的Python对象
# 代码案例
import argparse
# 创建一个ArgumentParser对象
parser = argparse.ArgumentParser(description='这是一个命令行参数解析的示例程序')
# 添加一个位置参数
parser.add_argument('name', type=str, help='你的名字')
# 添加一个可选参数
parser.add_argument('--age', type=int, default=18, help='你的年龄')
# 解析命令行输入
args = parser.parse_args()
# 打印解析的参数(执行任务)
print('你好,{}!你的年龄是{}'.format(args.name, args.age))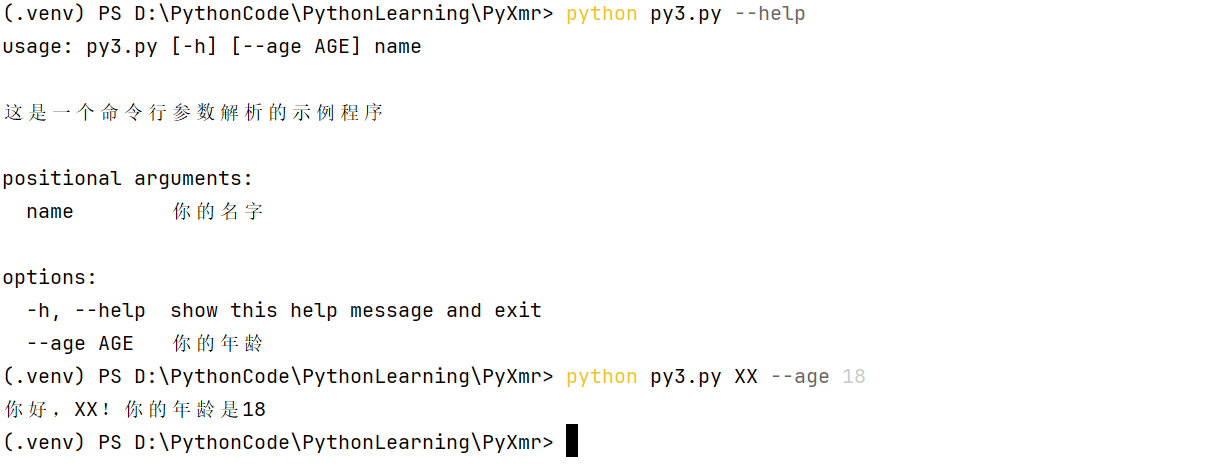
》》》组成部分《《《
# argparse 模块的主要组成部分:
(1)创建 ArgumentParser 对象:用于创建命令行解析器对象。如:定义程序可以接受的命令行参数,并设置参数的名称、类型、默认值和帮助信息等。
(2)使用 add_argument() 方法:向解析器中添加命令行参数及其相关的属性。如参数名称、缩写、类型、默认值、帮助信息等。
(3)调用 parse_args() 方法:解析命令行参数,该方法会返回一个命名空间对象,其包含了解析后的参数及其对应的值。该方法会自动根据定义的参数规则解析命令行输入,并将参数值存储在命名空间对象中供程序使用。
(4)使用命名空间对象中的属性,获取命令行参数的值。
# 创建命令行解析对象:parser = argparse.ArgumentParser()
"""######################################################################################
# 函数功能:用于创建一个命令行参数解析器的对象。
# 函数说明:argparse.ArgumentParser([prog=None, usage=None, description=None, epilog=None,
# formatter_class=argparse.HelpFormatter, prefix_chars='-',
# fromfile_prefix_chars=None, argument_default=None,
# conflict_handler='error', add_help=True, allow_abbrev=True])
# 参数说明:
# - prog: 程序的名称
# - usage: 用法说明
# - description: 描述参数作用的文字
# - epilog: 描述参数作用的结尾文字
# - formatter_class: 自定义帮助信息输出格式
# - prefix_chars: 用于标识可选参数的前缀字符
# - fromfile_prefix_chars: 用于从文件中读取参数的前缀字符
# - argument_default: 参数的默认值
# - conflict_handler: 解决参数冲突的方式
# - add_help: 是否自动添加'-h'和'--help'选项来显示帮助信息
# - allow_abbrev: 是否允许参数缩写
######################################################################################"""
# 添加命令行参数和选项:parser.add_argument()
"""#####################################################################################
# 函数功能:向命令行参数解析器中添加命令行参数。
# 函数说明:parser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
# 参数说明:
- name or flags: 命令行参数的名称或标志,可以是一个字符串或一个包含多个字符串的列表。例如 foo 或 -f, --foo。
(1)位置参数: 直接输入一个字符串,代表位置参数,是必传值。
(2)命令标志: 在字符串前加一个短横线(-),在命令中表示该参数。
(3)可选参数: 在字符串前加两个短横线(--),在命令行中代表可选参数,可输入也可不输入。
- action: 指定命令行参数的动作,默认为'store'。将命令行参数值存储到相应的参数名中。
(1)'store':存储参数值。
(2)'store_const':存储常量值。
(3)'store_true':存储True值。
(4)'store_false':存储False值。
(5)'append':将参数值添加到列表中。
(6)'append_const':将常量值添加到列表中。
(7)'count':计算参数出现的次数,存储到参数名中。
(8)'help':显示帮助信息并退出。
- nargs: 命令行参数的数量,默认为None。
- const: 常量值,用于一些特殊的动作,默认为None。
- default: 命令行参数的默认值,默认为None。
- type: 命令行参数的数据类型,默认为None。
(1)int:整数。
(2)float:浮点数。
(3)str:字符串。
(4)bool:布尔值。
- choices: 命令行参数允许的值的列表,默认为None。
- required: 命令行参数是否为必选,默认为False。
- help: 命令行参数的帮助文本,默认为None。
- metavar: 命令行参数在帮助文本中的名称,默认为None。
- dest: 命令行参数存储在解析结果中的属性名称,默认为None。
(1)默认情况下,参数名称与属性名称相同。
(2)若指定dest,则使用dest指定的参数名称作为属性名称。
#####################################################################################"""
# 解析命令行参数:args = parser.parse_args()
函数功能:根据 parser.add_argument() 添加的参数信息,来解析命令行参数。
输出参数:返回一个命名空间对象,其中包含了解析后的参数及其对应的值。
# 获取命令行参数:epochs = args.epochs
代码功能:通过命名空间对象访问相应的属性,以获取参数的值。
代码详解:通过 args.epochs 获取了命令行参数 --epochs 的值,并将其赋值给了变量 epochs。然后可以使用 epochs 变量来访问参数值,以完成后续的操作。import argparse
parser = argparse.ArgumentParser(description="Evaluate validation data.")
parser.add_argument("-m", "--model", type=str, default="../model/yolo_v3.cfg", help="Path to model")
parser.add_argument("-w", "--weights", type=str, default="../weights/yolo_v3.weights", help="Path to weights")
parser.add_argument("-d", "--data", dest='Data', type=str, default="../data/coco.data", help="Path to data")
# parse.add_argument("短选项","长选项",type=数据类型,default="默认值")
args = parser.parse_args()
print(f"arguments: {args}")
print(f"model = {args.model}")
print(f"weights = {args.weights}")
print(f"data = {args.Data}") # 由于指定了dest,故命令行参数 --data 被解析后存储在dest指定的参数名称 args.Data 中。
"""
arguments: Namespace(model='../model/yolo_v3.cfg', weights='../weights/yolo_v3.weights', Data='../data/coco.data')
model = ../model/yolo_v3.cfg
weights = ../weights/yolo_v3.weights
data = ../data/coco.data
"""
# "../model/yolo_v3.cfg" :表示文件位于当前工作目录的父目录的 model 子目录中,文件名为 yolo_v3.cfg。
# "./model/yolo_v3.cfg" :表示文件位于当前工作目录的 model 子目录中,文件名为 yolo_v3.cfg。
# "/model/yolo_v3.cfg" :表示文件位于根目录的 model 子目录中,文件名为 yolo_v3.cfg。
1.1.6:Json&Pickle模块
把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等.序列化可以使数据持久保存状态以及进行跨平台数据交互
json序列化
import json
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=json.dumps(dic)
print(type(j))#<class 'str'>
f=open('序列化对象','w')
f.write(j) #等价于json.dump(dic,f)
f.close()
#反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
ps:json序列化使用单引号会报错Pickle序列化 [ˈpɪkl]
import pickle
dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'>
j=pickle.dumps(dic)
print(type(j))#<class 'bytes'>
f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #等价于pickle.dump(dic,f)
f.close()
#反序列化
import pickle
f=open('序列化对象_pickle','rb')
data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data['age'])
ps:只能用于Python,并且可能不同版本的Python彼此都不兼容1.2:异常处理
异常就是程序运行时发生错误的信号(在程序出现错误时,则会产生一个异常,若程序没有处理它,则会抛出该异常,程序的运行也随之终止)。错误分类:
- 语法错误
- 逻辑错误
>>>常见异常<<<
AttributeError 试图访问一个对象没有的树形,比如foo.x,但是foo没有属性x
IOError 输入/输出异常;基本上是无法打开文件
ImportError 无法引入模块或包;基本上是路径问题或名称错误
IndentationError 语法错误(的子类) ;代码没有正确对齐
IndexError 下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError 试图访问字典里不存在的键
KeyboardInterrupt Ctrl+C被按下
NameError 使用一个还未被赋予对象的变量
SyntaxError Python代码非法,代码不能编译(个人认为这是语法错误,写错了)*
TypeError 传入对象类型与要求的不符合
UnboundLocalError 试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,
导致你以为正在访问它
ValueError 传入一个调用者不期望的值,即使值的类型是正确的>>>异常处理<<<
为了保证程序的健壮性与容错性,即在遇到错误时程序不会崩溃,我们需要对异常进行处理,错误发生的条件是可预知的,我们需要用if进行处理:在错误发生之前进行预防
AGE=10
while True:
age=input('>>: ').strip()
if age.isdigit(): #只有在age为字符串形式的整数时,下列代码才不会出错,该条件是可预知的
age=int(age)
if age == AGE:
print('you got it')
break
ps:错误发生的条件是不可预知的,则需要用到try...except:在错误发生之后进行处理>>>基础语法<<<
try:
被检测的代码块
except 异常类型:
try中一旦检测到异常,就执行这个位置的逻辑
try:
f=open('a.txt')
g=(line.strip() for line in f)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
except StopIteration:
f.close()>>>异常总结<<<
#1 异常类只能用来处理指定的异常情况,如果非指定异常则无法处理。
s1 = 'hello'
try:
int(s1)
except IndexError as e: # 未捕获到异常,程序直接报错
print e
#2 多分支
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
#3 万能异常Exception
s1 = 'hello'
try:
int(s1)
except Exception as e:
print(e)
4多分支异常与万能异常
无论出现什么异常,我们统一丢弃,或者使用同一段代码逻辑去处理则只需要有一个Exception。
对于不同的异常我们需要定制不同的处理逻辑,需要使用到多分支异常。
5 也可以在多分支后来一个Exception
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
except Exception as e:
print(e)
#6 异常的其他机构
s1 = 'hello'
try:
int(s1)
except IndexError as e:
print(e)
except KeyError as e:
print(e)
except ValueError as e:
print(e)
#except Exception as e:
# print(e)
else:
print('try内代码块没有异常则执行我')
finally:
print('无论异常与否,都会执行该模块,通常是进行清理工作')
#7 主动触发异常
try:
raise TypeError('类型错误')
except Exception as e:
print(e)
#8 自定义异常
class EgonException(BaseException):
def __init__(self,msg):
self.msg=msg
def __str__(self):
return self.msg
try:
raise EgonException('类型错误')
except EgonException as e:
print(e)
#9 断言:assert 条件
assert 1 == 1
assert 1 == 2
ps:try..except优势
把错误处理和真正的工作分开来
代码更易组织,更清晰,复杂的工作任务更容易实现;
毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了;>>>其他语法结构<<<
语法1:try-except-else
try:
a = b
print(a)
except SyntaxError:
print("<<< SytaxError")
except SystemExit:
print("<<< SystemExit")
else:
print("That's good,no error.")
语法2:try-finally
try:
a = b
print(a)
finally:
print("123")try, except, else, finally是可以全部组合在一起用的。
1.3:多线程
多线程是指在同一个程序中,将一个程序划分为若干个子任务,每个子任务作为一个独立的线程并发执行。 线程是CPU分配资源的基本单位。从一个程序开始运行,这个程序就变成了一个进程,而一个进程相当于一个或者多个线程。当没有多线程编程时,一个进程也是一个主线程,但有多线程编程时,一个进程包含多个线程和一个主线程。使用线程可以实现程序的并发。
学习目的:提升代码执行效率,原来代码执行需要20分钟...学习并发编程后可以将执行速度加快到1分钟执行完毕!
情景类比:
- 一个工厂,至少有一个车间,一个车间至少有一个工人,最终是工人在工作!
- 一个程序,至少有一个进程,一个进程至少有一个线程,最终是线程在工作!
使用Python xxx.py运行时,内部就创建一个进程(主进程),在进程中创建了一个线程(主线程),由线程逐行运行代码!
* 进程:是计算机资源分配的最小单元(进程为线程提供资源)
* 线程:是计算机中可以被CPU调度的最小单元(真正在工作)
一个进程中可以有多个线程,同一个进程中的线程可以共享此进程中的资源。》》》案例代码《《《
import time
result = 0
for i in range(1000000000):
result +=1
print(result)
以前我们开发的程序中所有的行为都只能通过串行的形式运行,排队逐一执行,前面未完成且后面也无法继续!import time
url_list = [("东北F4模仿秀.txt","URL地址A1"),
("四大天王合唱.txt","URL地址A2"),
("四大名著讲解.txt","URL地址A3")]
print(time.time())
for name,url in url_list:
with open(name,mode="a+") as f:
f.write(url)
print(name,time.time())
通过线程和进程都可以将串行的程序变为并发,对于上述示例来说同时读写文件,这样就可以在很短的时间处理完成!1.3.1:并发-多线程处理
基于多线程对上述示例进行优化:
- 一个工厂,创建一个车间,这个这件中创建三个工人,并行处理任务!
- 一个程序,创建一个进程,这个进程中创建三个线程,并行处理任务!
开启线程方式一:创建线程要执行的函数,把这个函数传递进Thread对象里,让它来执行
from threading import Thread
import time
def test(param):
time.sleep(2)
print('Hello %s'%param)
if __name__ == '__main__':
t=Thread(target=test,args=('World',))
t.start()
print('main threading')开启线程方式二:继承thread类,重写run方法与Java的多线程非常类似
from threading import Thread
import time
class Test_Thread(Thread):
def __init__(self,param):
super().__init__()
self.param=param
def run(self):
time.sleep(2)
print('Hello %s' % self.param)
if __name__ == '__main__':
t = Test_Thread('Python')
t.start()
print('main Threading') # 案例代码
import time
import threading
url_list = [("东北F4模仿秀.txt","URL地址A1"),
("四大天王合唱.txt","URL地址A2"),
("四大名著讲解.txt","URL地址A3")]
def task(name,url):
with open(name, mode="a+") as f:
f.write(url)
print(name, time.time())
for name,url in url_list:
# 创建线程,让每个线程都去执行task函数(参数不同)
t = threading.Thread(target=task,args=(name,url))
t.start()1.3.2:并发-多进程处理
基于多线程对上述串行示例进行优化:
- 一个工厂,创建三个车间,每个车间一个工人(共3人),并行处理任务!
- 一个程序,创建三个进程,每个进程一个线程(共3人),并行处理任务!
import time
import multiprocessing
url_list = [("东北F4模仿秀.txt","URL地址A1"),
("四大天王合唱.txt","URL地址A2"),
("四大名著讲解.txt","URL地址A3")]
def task(name,url):
with open(name, mode="a+") as f:
f.write(url)
print(name, time.time())
if __name__ == '__main__':
print(time.time())
for name,url in url_list:
p = multiprocessing.Process(target=task,args=(name,url))
p.start()* 多进程的开销比多线程大,是不是多线程要比多进程要好?1.3.3:GIL解释器锁
GIL,全局解释锁(Global Interpreter Lock),是CPython解释器的一个玩意,让一个进程中同一时刻只能有一个线程可以被CPU调用!
GIL全称Global Interpreter Lock(全局解释器锁)。GIL和Python语言没有任何关系,只是因为历史原因导致在官方推荐的解释器Cpython中遗留的问题。(多线程)每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程可以执行代码,但是当遇到IO阻塞会自动的释放GIL锁,所以使用多线程还是比单线程的效率要高。如果想发挥多核CPU资源,可以使用多进程。为了避免受GIL的影响可以不用官方推荐的Cpython,或者用其他语言来实现,或者使用多进程。
》》》多线程&多进程《《《
常见的程序开发中计算操作需要使用CPU多核优势,IO操作不需要利用CPU的多核优势,所以就有这样一句话:
- 计算密集型用多进程,例如:大量的数据计算【累加计算示例】
- IO密集型用多线程,例如:文件读写/网络数据传输【网页访问示例】
# 累加计算示例:
* 串行处理
import time
start = time.time()
result = 0
for i in range(1000000000):
result = result + i
print(result)
end = time.time()
print("耗时:",end - start)
* 多进程处理
import time
import multiprocessing
def task(start,end,queue):
result = 0
for i in range(start,end):
result += i
queue.put(result)
if __name__ == '__main__':
queue = multiprocessing.Queue()
start = time.time()
p1 = multiprocessing.Process(target=task,args=(1,50000000,queue))
p1.start()
p2 = multiprocessing.Process(target=task,args=(50000000,10000000,queue))
p2.start()
v1 = queue.get(block=True)
v2 = queue.get(block=True)
print(v1,v2)
end = time.time()
print("耗时:",end - start)# 当然,在程序开发中多线程和多进程时可以结合使用,例如:创建2个进程,每个进程中创建三个线程!
import threading
import multiprocessing
def thread_task():
pass
def task(start,end):
t1 = threading.Thread(target=thread_task)
t1.start()
t2 = threading.Thread(target=thread_task)
t2.start()
t3 = threading.Thread(target=thread_task)
t3.start()
if __name__ == '__main__':
p1 = multiprocessing.Process(target=task, args=(1,5000000))
p1.start()
p2 = multiprocessing.Process(target=task, args=(5000000,10000000))
p2.start()1.3.4:多线程方法
import threading
def task(arg)
pass
# 创建一个Thread对象(线程),并封装线程被CPU调度时应该执行的任务和相关参数!
t = threading.Thread(target=task,args=(xxx,))
t.start()
print('继续执行') #主线程程序执行完所有代码,不结束(等待子线程)| t.start() | 当前线程准备就绪(等待CPU调度,具体时间是由CPU来决定) |
| t.join() | 等待当前线程的任务执行完毕后再向下继续执行 |
| t.setName() | 线程名称的设置 |
| t.getName() | 线程名称的获取 |
# threading模块提供的一些方法:
threading.currentThread(): 返回当前的线程变量。
threading.enerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enerate())有相同的结果。- join()方法
主线程x中,创建了子线程y,并且在主线程x中调用了y.join(),则主线程x会在调用的地方等待,直到子线程y完成操作后,才会接着往下执行。(对主线程来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕主线程等待子线程结束)
from threading import Thread
import time
def test(param):
time.sleep(2)
print('Hello %s' %param)
if __name__ == '__main__':
t=Thread(target=test,args=('Python',))
t.start()
t.join()
print('main threading')
print(t.is_alive())- setDaemon()方法
主线程x中创建了子线程y,并且在主线程x中调用了y.setDaemon(),则子线程y设置为守护线程,如果主线程x执行束,不论子线程y是否完成,一并和主线程x退出.
ps:必须在start() 方法调用之前设置,如果不设置为守护线程,程序会被无限挂起。(主线程不等待子线程结束即守护线程)
from threading import Thread
import time
def test(param):
time.sleep(2)
print('Hello %s' %param)
if __name__ == '__main__':
t=Thread(target=sayhi,args=('World',))
# 必须在t.start()之前设置
t.setDaemon(True)
t.start()
print('main threding')
print(t.is_alive())# t.start() 当前线程准备就绪(等待CPU调度,具体时间是由CPU来决定)
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += i
t = threading.Thread(target=_add, args=(loop,))
t.start()
print(number) # 打印数值随机,原因是因为创建的子线程并没有执行完就来到了主线程打印number
# t.join() 等待当前线程的任务执行王毕后再向下继续执行
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += i
t = threading.Thread(target=_add, args=(loop,))
t.start()
t.join() #主线程等待中
print(number) #多次打印结果执行一致为49999995000000
# t.setName()线程名称的设置和获取
import time
import threading
def task(arg):
name = threading.current_thread().getName()
print(f'{name} start')
for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.setName('Job1-{}'.format(i)) #在.start()之前设置线程名称
t.start()
# 自定义线程类,直接将线程需要做的事写入到run方法中。
import threading
class MyThread(threading.Thread):
def run(self):
print('执行此线程',self._args) # 可进行的多线程操作!
t = MyThread(args=(100,))
t.start()1.3.3:线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法即加锁与解锁,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间即可。
>>>同步锁<<<
锁通常被用来实现对共享资源的同步访问。为每一个共享资源创建一个Lock对象,当你需要访问该资源时,调用acquire方法来获取锁对象(如果其它线程已经获得了该锁,则当前线程需等待其被释放),待资源访问完后,再调用release方法释放锁
import threading
R=threading.Lock()
R.acquire()
'''
对公共数据的操作
'''
R.release()#并发执行变成串行,牺牲了执行效率保证了数据安全
from threading import Thread,Lock
import os,time
def work():
global nbers
lock.acquire()
temp=nbers
time.sleep(0.1)
nbers=temp-1
lock.release()
if __name__ == '__main__':
lock=Lock()
nbers=66
list=[]
for i in range(66):
t=Thread(target=work)
list.append(t)
t.start()
for t in list:
t.join()
print(nbers)过程分析:
第一步:66个线程去抢GIL锁,即抢执行权限
第二部:肯定有一个线程先抢到GIL(暂且称为线程一),然后开始执行,一旦执行就会拿到lock.acquire()
第三步:极有可能线程一还未运行完毕,就有另外一个线程二抢到GIL,然后开始运行,但线程二发现互斥锁lock还未被线程一释放,于是阻塞,被迫交出执行权限,即释放GIL
第四步:直到线程一重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复以上的过程# GIL VS Lock
Python已经存在一个GIL但是来保证同一时间只能有一个线程来执行了,但是为什么这里还需要lock? 首先需要明确的是锁的目的是为了保护共享的数据,保证同一时间只能有一个线程来修改共享的数据而且保护不同的数据就应该加不同的锁。GIL与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理,即Lock。>>>互斥锁与Join()方法的区别<<<
加锁会让运行变成串行,那么如果在start之后立即使用join,就不需要加锁而且也是串行的效果。
但是在start之后立刻使用join,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,数据是安全的。
但问题是start之后立即join:任务内的所有代码都是串行执行的,而加锁只是加锁的部分即修改共享数据的部分是串行的,这就是两者的区别。
如果单从保证数据安全方面,二者都可以实现,但很明显是加锁的程序执行效率显然比使用join()方法更高*不加锁:并发执行,速度快,但是数据是不安全
from threading import current_thread,Thread,Lock
import os,time
def task():
global n
print('%s is running' %current_thread().getName())
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
----------------------------------------------------
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:0.5216062068939209 n:99
*不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,但是数据安全
from threading import current_thread,Thread,Lock
import os,time
def task():
#未加锁的代码并发运行
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
#加锁的代码串行运行
lock.acquire()
temp=n
time.sleep(0.5)
n=temp-1
lock.release()
if __name__ == '__main__':
n=100
lock=Lock()
threads=[]
start_time=time.time()
for i in range(100):
t=Thread(target=task)
threads.append(t)
t.start()
for t in threads:
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
----------------------------------------------------------
Thread-1 is running
Thread-2 is running
......
Thread-100 is running
主:53.294203758239746 n:0
*使用join()方法,数据安全,但是串行执行
from threading import current_thread,Thread,Lock
import os,time
def task():
time.sleep(3)
print('%s start to run' %current_thread().getName())
global n
temp=n
time.sleep(0.5)
n=temp-1
if __name__ == '__main__':
n=100
lock=Lock()
start_time=time.time()
for i in range(100):
t=Thread(target=task)
t.start()
t.join()
stop_time=time.time()
print('主:%s n:%s' %(stop_time-start_time,n))
-----------------------------------------
Thread-1 start to run
Thread-2 start to run
......
Thread-100 start to run
主:350.6937336921692 n:0 #耗时是多么的恐怖>>>死锁<<<
是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,如果没有外力进行干预则程序就无法继续执行,此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程就称为死锁进程。死锁,由于竞争资源或者由于彼此的通信造成的一种阻塞现象!
from threading import Thread,Lock
import time
X=Lock()
Y=Lock()
class Lock_Thread(Thread):
def run(self):
self.actionX()
self.actionY()
def actionX(self):
X.acquire()
print('\033[41m%s 拿到X锁\033[0m' %self.name)
Y.acquire()
print('\033[42m%s 拿到Y锁\033[0m' %self.name)
Y.release()
X.release()
def actionY(self):
Y.acquire()
print('\033[43m%s 拿到Y锁\033[0m' %self.name)
time.sleep(2)
X.acquire()
print('\033[44m%s 拿到X锁\033[0m' %self.name)
X.release()
Y.release()
if __name__ == '__main__':
for i in range(10):
t=Lock_Thread()
t.start()
----------------------------------------------------------
Thread-1 拿到X锁
Thread-1 拿到Y锁
Thread-1 拿到Y锁
Thread-2 拿到X锁
然后就卡住,死锁了>>>递归锁<<<
即死锁解决方法,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,
其他的线程才能获得资源。如果使用RLock代替Lock,则不会发生死锁.
即X=Y=threading.RLock()如果一个线程拿到锁,counter加1,该线程内又碰到加锁的情况,则counter继续加1,这期间所有其他线程都只能等待,等待该线程释放所有锁,
即counter递减到0为止
import threading
import time
class Lock_Thread(threading.Thread):
def actionX(self):
r_lcok.acquire() #count=1
print(self.name,"gotX",time.ctime())
time.sleep(2)
r_lcok.acquire() #count=2
print(self.name, "gotY", time.ctime())
time.sleep(1)
r_lcok.release() #count=1
r_lcok.release() #count=0
def actionY(self):
r_lcok.acquire()
print(self.name, "gotY", time.ctime())
time.sleep(2)
r_lcok.acquire()
print(self.name, "gotX", time.ctime())
time.sleep(1)
r_lcok.release()
r_lcok.release()
def run(self):
self.actionX()
self.actionY()
if __name__ == '__main__':
r_lcok=threading.RLock()
L=[]
for i in range(5):
t=Lock_Thread()
t.start()
L.append(t)
for i in L:
i.join()
print("ending....")》》》Lock与RLock《《《
# Lock()与RLock()不同
1.Lock()不支持锁的嵌套而RLock()则支持 如果Lock()使用锁的嵌套则会出现"死锁"!
2.Lock()执行效率要比RLock()的效率高,即Lock()是锁一次解一次!
3.RLock()支持多次申请锁和多次释放,但Lock不支持# Rlock开发场景
import threading
lock = threading.RLock()
# 程序员A开发了一个函数,函数可以被其他开发者调用,内部需要基于锁保证数据安全
def func():
with lock:
pass
# 程序员B开发了一个函数,可以直接调用这个函数
def run():
print("其他功能")
func() # 调用程序员A写的func函数,内部用到了锁
print("其他功能")
# 程序员C开发了一个函数,自己需要加锁,同时也需要调用func函数
def process():
with lock:
print("其他功能")
func() # 此时就会出现多次锁的情况,只有RLock支持嵌套锁
print("其他功能")二:面向对象
- 面向过程:根据业务逻辑从上到下写垒代码
- 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
- 面向对象:对函数进行分类和封装,让开发“更快更好更强...”
面向过程编程最易被初学者接受,其往往用一长段代码来实现指定功能,开发过程中最常见的操作就是粘贴复制,即:将之前实现的代码块复制到现需功能处。
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接随着时间的推移,开始使用了函数式编程,增强代码的重用性和可读性,就变成了这样:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警') 今天我们来学习一种新的编程方式:面向对象编程(Object Oriented Programming,OOP,面向对象程序设计)
创建类和对象
面向对象编程是一种编程方式,此编程方式的落地需要使用 “类” 和 “对象” 来实现,所以,面向对象编程其实就是对 “类” 和 “对象” 的使用。
类就是一个模板,模板里可以包含多个函数,函数里实现一些功能
对象则是根据模板创建的实例,通过实例对象可以执行类中的函数

- class是关键字,表示类
- 创建对象,类名称后加括号即可
- ps:类中的函数第一个参数必须是self(详细见:类的三大特性之封装)
类中定义的函数叫做 “方法”
# 创建类
class Foo:
def Bar(self):
print 'Bar'
def Hello(self, name):
print 'i am %s' %name
# 根据类Foo创建对象obj
obj = Foo()
obj.Bar() #执行Bar方法
obj.Hello('wupeiqi') #执行Hello方法 诶,你在这里是不是有疑问了?使用函数式编程和面向对象编程方式来执行一个“方法”时函数要比面向对象简便
- 面向对象:【创建对象】【通过对象执行方法】
- 函数编程:【执行函数】
观察上述对比答案则是肯定的,然后并非绝对,场景的不同适合其的编程方式也不同。
总结:函数式的应用场景 --> 各个函数之间是独立且无共用的数据
面向对象三大特性
面向对象的三大特性是指:封装、继承和多态。
一、封装
封装,顾名思义就是将内容封装到某个地方,以后再去调用被封装在某处的内容。
所以,在使用面向对象的封装特性时,需要:
- 将内容封装到某处
- 从某处调用被封装的内容
第一步:将内容封装到某处
#创建类
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
#根据类Foo创建对象
#自动执行Foo类的__init__方法
obj1 = Foo('luze',18)
#根据类Foo创建对象
#自动执行Foo类的__init__方法
obj2 = Foo('zhangsan',80)self 是一个形式参数,当执行 obj1 = Foo('luze', 18 ) 时,self 等于 obj1
当执行 obj2 = Foo('zhangsan', 80) 时,self 等于 obj2
所以,内容其实被封装到了对象 obj1 和 obj2 中,每个对象中都有 name 和 age 属性,在内存里类似于下图来保存。

第二步:从某处调用被封装的内容
调用被封装的内容时,有两种情况:
- 通过对象直接调用
- 通过self间接调用
1、通过对象直接调用被封装的内容
上图展示了对象 obj1 和 obj2 在内存中保存的方式,根据保存格式可以如此调用被封装的内容:对象.属性名
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
obj1 = Foo('luze', 18)
print(obj1.name) # 直接调用obj1对象的name属性
print(obj1.age) # 直接调用obj1对象的age属性
obj2 = Foo('zhangsan', 80)
print(obj2.name) # 直接调用obj2对象的name属性
print(obj2.age) # 直接调用obj2对象的age属性
2、通过self间接调用被封装的内容
执行类中的方法时,需要通过self间接调用被封装的内容
class Foo:
def __init__(self, name, age):
self.name = name
self.age = age
def detail(self):
print self.name
print self.age
obj1 = Foo('luze', 18)
obj1.detail() # Python默认会将obj1传给self参数,即:obj1.detail(obj1),所以,此时方法内部的 self = obj1,即:self.name 是 luze ;self.age 是 18
obj2 = Foo('zhangsan', 73)
obj2.detail() # Python默认会将obj2传给self参数,即:obj1.detail(obj2),所以,此时方法内部的 self = obj2,即:self.name 是 zhangsan ; self.age 是 78
综上所述,对于面向对象的封装来说,其实就是使用构造方法将内容封装到 对象 中,然后通过对象直接或者self间接获取被封装的内容。
练习一:在终端输出如下信息
- 小明,10岁,男,上山去砍柴
- 小明,10岁,男,开车去东北
- 小明,10岁,男,最爱大保健
- 老李,90岁,男,上山去砍柴
- 老李,90岁,男,开车去东北
- 老李,90岁,男,最爱大保健
- 老张...
def kanchai(name, age, gender):
print("%s,%s岁,%s,上山去砍柴" %(name, age, gender))
def qudongbei(name, age, gender):
print("%s,%s岁,%s,开车去东北" %(name, age, gender))
def dabaojian(name, age, gender):
print("%s,%s岁,%s,最爱大保健" %(name, age, gender))
kanchai('小明', 10, '男')
qudongbei('小明', 10, '男')
dabaojian('小明', 10, '男')
kanchai('老李', 90, '男')
qudongbei('老李', 90, '男')
dabaojian('老李', 90, '男')
class Foo:
def __init__(self, name, age ,gender):
self.name = name
self.age = age
self.gender = gender
def kanchai(self):
print("%s,%s岁,%s,上山去砍柴" %(self.name, self.age, self.gender))
def qudongbei(self):
print("%s,%s岁,%s,开车去东北" %(self.name, self.age, self.gender))
def dabaojian(self):
print("%s,%s岁,%s,最爱大保健" %(self.name, self.age, self.gender))
xiaoming = Foo('小明', 10, '男')
xiaoming.kanchai()
xiaoming.qudongbei()
xiaoming.dabaojian()
laoli = Foo('老李', 90, '男')
laoli.kanchai()
laoli.qudongbei()
laoli.dabaojian()
上述对比可以看出,如果使用函数式编程,需要在每次执行函数时传入相同的参数,如果参数多的话,又需要粘贴复制了... ;而对于面向对象只需要在创建对象时,将所有需要的参数封装到当前对象中,之后再次使用时,通过self间接去当前对象中取值即可。
二、继承
继承,面向对象中的继承和现实生活中的继承相同,即:子可以继承父的内容。
例如:
猫可以:喵喵叫、吃、喝、拉、撒
狗可以:汪汪叫、吃、喝、拉、撒
如果我们要分别为猫和狗创建一个类,那么就需要为 猫 和 狗 实现他们所有的功能,如下所示:
class 猫:
def 喵喵叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
class 狗:
def 汪汪叫(self):
print '喵喵叫'
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
上述代码不难看出,吃、喝、拉、撒是猫和狗都具有的功能,而我们却分别的猫和狗的类中编写了两次。如果使用 继承 的思想,如下实现:
动物:吃、喝、拉、撒
猫:喵喵叫(猫继承动物的功能)
狗:汪汪叫(狗继承动物的功能)
class 动物:
def 吃(self):
# do something
def 喝(self):
# do something
def 拉(self):
# do something
def 撒(self):
# do something
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 猫(动物):
def 喵喵叫(self):
print '喵喵叫'
# 在类后面括号中写入另外一个类名,表示当前类继承另外一个类
class 狗(动物):
def 汪汪叫(self):
print '喵喵叫'
class Animal:
def eat(self):
print("%s 吃 " %self.name)
def drink(self):
print("%s 喝 " %self.name)
def shit(self):
print("%s 拉 " %self.name)
def pee(self):
print("%s 撒 " %self.name)
class Cat(Animal):
def __init__(self, name):
self.name = name
self.breed = '猫'
def cry(self):
print('喵喵叫')
class Dog(Animal):
def __init__(self, name):
self.name = name
self.breed = '狗'
def cry(self):
print('汪汪叫')
# ######### 执行 #########
c1 = Cat('小白家的小黑猫')
c1.eat()
c2 = Cat('小黑的小白猫')
c2.drink()
d1 = Dog('胖子家的小瘦狗')
d1.eat()所以,对于面向对象的继承来说,其实就是将多个类共有的方法提取到父类中,子类仅需继承父类而不必一一实现每个方法。
注:除了子类和父类的称谓,你可能看到过 派生类 和 基类 ,他们与子类和父类只是叫法不同而已。

那么问题又来了,多继承呢?(不做重点)
- 是否可以继承多个类
- 如果继承的多个类每个类中都定了相同的函数,那么那一个会被使用呢?
1、Python的类可以继承多个类,Java和C#中则只能继承一个类
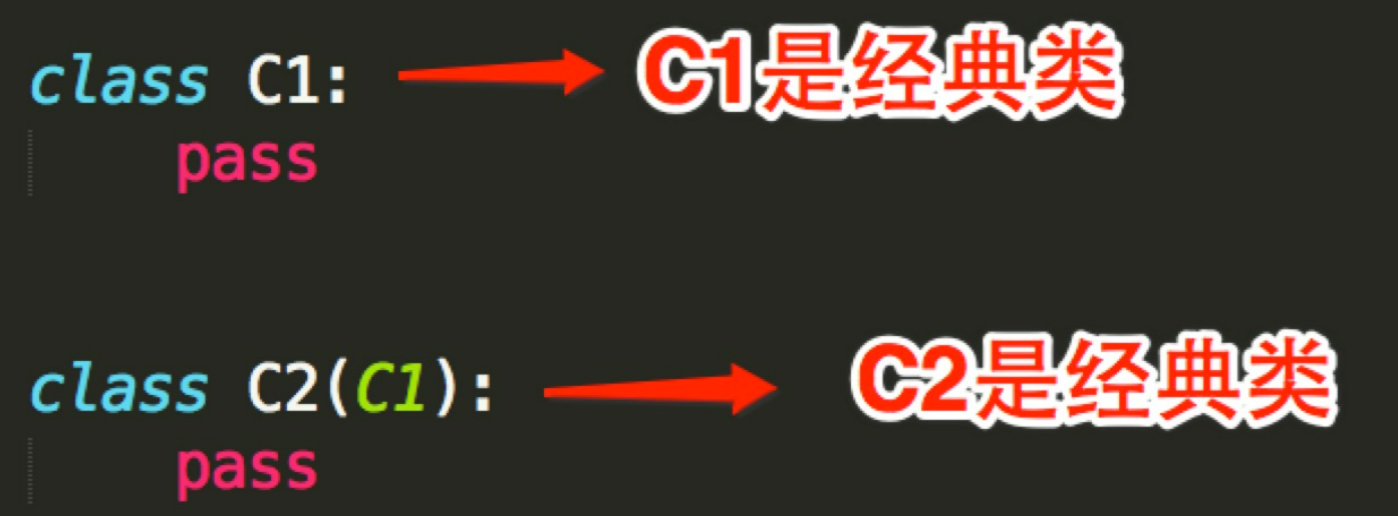
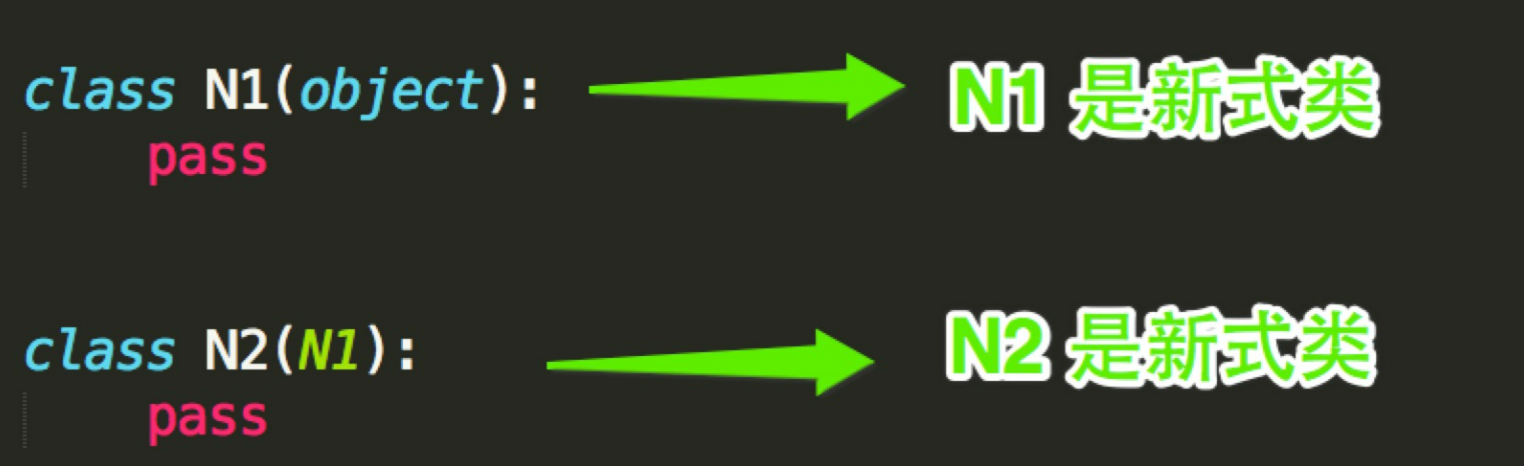
2、Python的类如果继承了多个类,那么其寻找方法的方式有两种,分别是:深度优先和广度优先
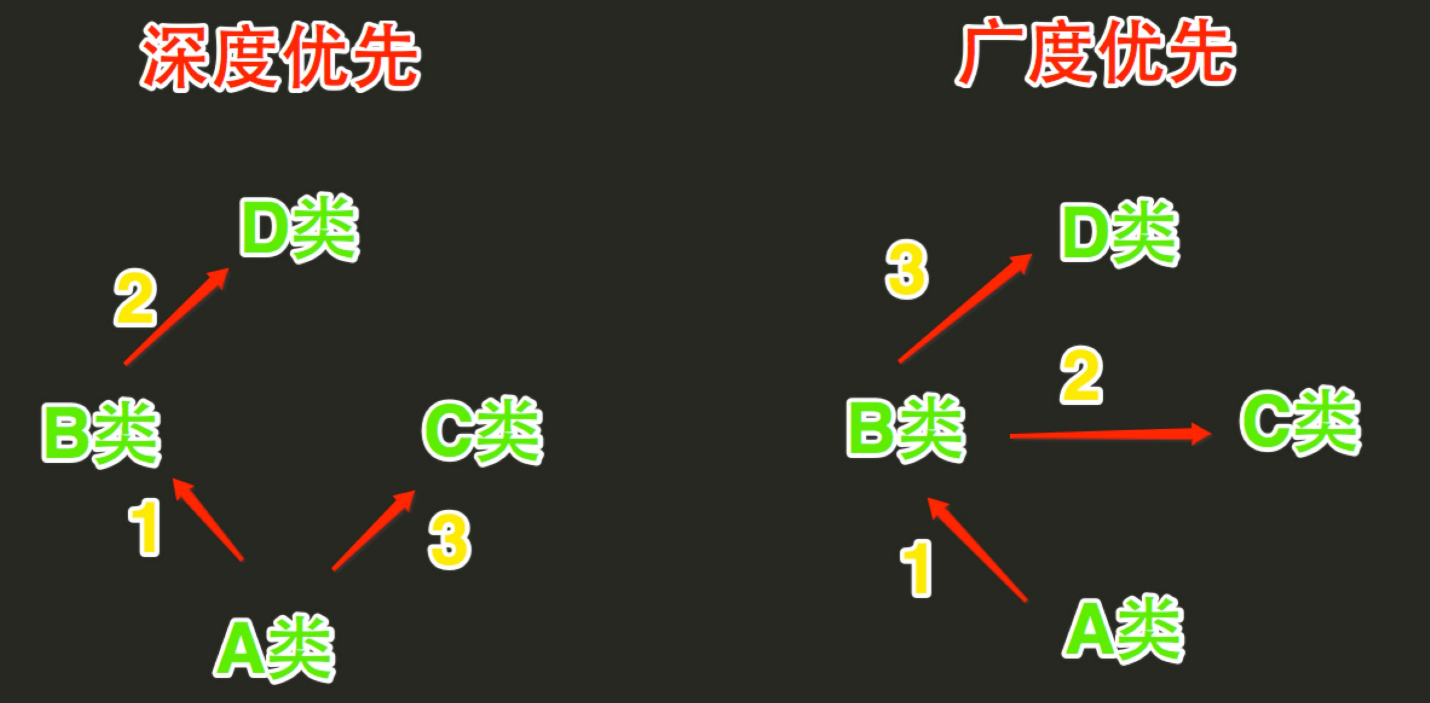
- 当类是经典类时,多继承情况下,会按照深度优先方式查找
- 当类是新式类时,多继承情况下,会按照广度优先方式查找
经典类和新式类,从字面上可以看出一个老一个新,新的必然包含了跟多的功能,也是之后推荐的写法,从写法上区分的话,如果 当前类或者父类继承了object类,那么该类便是新式类,否则便是经典类。
三、多态
多态,简单理解为多种形态。对于同一个方法(该方法为父类方法,子类继承而来),可以有不同的行为,从而执行结果也不一样。
这种不同的行为的产生,是由于真正的子类实例的这个方法的实现不同而造成的。而这些不同的子类就形成了多种形态。
多态的分类:
多态性分为静态多态性和动态多态性,
静态多态性:在运行之前就知道该用哪个类型的实例,例如,任何类型都可以用运算符+进行运算
动态多态性:在运行过程中,才知道使用哪个类的实例。例如,下面的例子。
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
#Persion类
class Persion:
age = 1;
sex = True; #True:男; False:女
def __init__(self):
self.age = 1;
print("[Persion][init]==age==",self.age);
def getAge(self):
return self.age;
def getSex(m):
return m.sex;
def sayHello(self):
print("hello world!");
def eat(self):
print("Hi !!!");
def eat(self): #吃饭
pass;
class Boy(Persion):
__name = '';
def __init__(self):
super().__init__();
print("[Boy][init]==age==",self.age);
def setName(self,name):
self.__name = name;
def eat(self): #男孩喜欢吃肉
super().eat(); #调用父类的eat方法
print("[Boy] like eat meat !!!");
class Girl(Persion):
__name = '';
def __init__(self):
super().__init__();
print("[Girl][init]==age==",self.age);
def setName(self,name):
self.__name = name;
def eat(self): #女孩喜欢吃米饭
super().eat(); #调用父类的eat方法
print("[Girl] like eat rice !!!");
def eat(persion): #多态的体现,既可以是boy,也可以是个girl
persion.eat();
boy = Boy();
girl = Girl();
eat(boy);
eat(girl)















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









