







对五种排序方法可以分成6大类:
存储介质:内部排序和外部排序
比较器个数:串行排序和并行排序
主要操作:比较排序和基数排序
辅助空间:原地排序和非原地排序
稳定性:稳定排序和非稳定排序
自然性:自然和非自然排序(自然排序是指输入的数据越有序,排序的速度就越快的方法,而非自然排序是指一开始输入的数据比较有序,排序的速度反而变慢的方法)
以下排序方法都以顺序存储表存储:
#define MAXSIZE 20 //设记录不超过20个
typedef int KeyType;//关键字为整型量
typedef struct {//记录每个(数据元素)的结构
KeyType key;//数据项
}RedType;
typedef struct {
RedType r[MAXSIZE + 1];//r[0]一般为哨兵位或者缓冲区
int length;
}Sqlist;
插入排序分2种:
1.直接插入排序
提示直接插入排序中数组中第一个位置为哨兵位 L.r[0]=L[i]
算法:
//直接插入排序算法
void InserSort(Sqlist& L) {
int i, j;
for (i = 2; i <= L.length; ++i) {
if (L.r[i].key < L.r[i - 1].key) {//
L.r[0] = L.[i];//复制哨兵位
for (j = i - 1; L.r[0].key < L.r[j].key; --j) {
L.r[j + 1] = L.r[j];//比哨兵位大的值都往后移动
}
L.r[j + 1] = r.[0];//将哨兵位的值插入
}
}
}根据算法可以分析出:
时间效率:
最好情况: O(n)
最坏情况:O(n的二次方)
平均情况:O(n的二次方)
空间效率:O(1)
只额外使用了哨兵r[0]空间
算法特点:
(1)稳定排序
(2)也适用链式存储结构,只需要在链表上无需移动记录,只需要修改相关指针
(3)更适合初始记录基本有序(正序),n相对较小的情况
2.折半插入排序(二分法定位插入排序)
直接查找是根据顺序查找然后插入数据,而折半插入排序是根据折半查找然后插入排序(如果不太理解折半查找可以看一下数据结构中的五大查找方法)
/折半插入排序
void BlnsertSort(Sqlist& L) {
for(i=2;i<=L.length;++i){
L.r[0] = L.r[i];//将当前位置插入哨兵位
low = 1;//采用二分查找法找到插入位置
hight = i - 1;
while (low <= high)
{
mid = (low + high) / 2;
if (L.r[0].key < L.r[mid].key) {
high = mid - 1;
}
else {
low = mid + 1;
}
}
for (j = i - 1; j > high + 1; --j) {
L.r[j + 1] = L.r[j];//移动元素
}
L.r[high + 1] = L.r[0];//插入到正确位置
}
}根据算法可以分析出:
时间效率:
最好情况: O(n)
最坏情况:O(n的二次方)
平均情况:O(n的二次方)
空间效率:O(1)
只额外使用了哨兵r[0]空间
算法特点:
(1)稳定排序
(2)也适用链式存储结构,只需要在链表上无需移动记录,只需要修改相关指针
(3)更适合初始记录基本有序(正序),n相对较小的情况
3.希尔排序法
基本思想:
先将整个待排序记录序列分割成若干子序列,分别进行直接插入序列,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序
特点:
1.缩小增量
2.多遍插入排序
思路:
1.定义增量序列Dk:Dm>Dm-1>....>D1=1
2.对每个Dk进行Dk-间隔“插入排序
希尔排序算法:
void ShellSort(Sqlist& L, int dlta[], int t) {
//按增量序列dlta[0...t-1]对顺序表L作希尔排序
for (k = 0; k < t; ++k) {
Shelllnsert(L, dlta[k]);
}
}
void Shelllnsert(Sqlist& L, int dk) {
for (i = dk + 1; i <= L.lengthl; ++1) {
if (r[i].key < r[i - dk].key) {
r[0] = r[i];
for (j = i - dk; j > 0 && (r[0].key < r[j].key); j = j - dk)
r[j + dk] = r[j];
r[j + dk] = r[0];
}
}
}根据算法可以分析出:
时间效率:
最好情况: O(n)
最坏情况:O(n的二次方)
平均情况:~O(n的1.3次方)
空间效率:O(1)
只额外使用了哨兵r[0]空间
算法特点:
(1)不稳定排序
(2)只适用顺序结构
(3)最后一个增量值必须是1
(4)适合初始记录无序,n较大的情况
交换排序:
冒泡排序:
基本思想:冒泡排序是最简单的交换排序方法,它通过两两比较相邻记录的关系关键字,如果为逆序,则进行交换,从而使关键字小的记录如气泡一般逐渐向上”漂浮“,或者使关键字大的记录如石块一样逐渐向下”坠落“(右移)
算法:
//改进版冒泡排序
void bubble_sort(Sqlist& L) {
int m, j, i,flag=1;//flag作为是否有交换的标记
RedType x;//为交换创建临时空间
for (m = 1; m < n - 1 && flag == 1) {
flag = 0;
for (j = 1; j < m; j++) {
if (L.r[j].key > L.r[j + 1].key) {
flag = 1;
x = L.r[j];
L.r[j] = L.r[j + 1];
L.r[j + 1] = x;
}
}
}
}快速排序:
快速排序是由冒泡排序改进而来,在冒泡排序中,只对相邻的两个记录进行比较,因此每次交换两个相邻的记录时只能消除一个逆序排列,如果能通过两个(不相邻)记录的一次交换,消除多个逆序,则会大大加快排序速度,快速排序方法一次可能交换多个逆序排列
算法:
//快速排序
int Partition(Sqlist& L, int low, int high) {//对顺序表中的子表r.[low.high]进行一趟排序,返回中心位置
L.r[0] = L.r[low];
pivotkey = L.r[low].key;
while (low < high) {
while (low < high && L.r[high].key >= pivotey) {
--high;
}
L.r[low] = L.r[high];
while (low < high && L.r[high].key <= pivotey)
{
++low;
}
L.r[high] = L.r[low];
}
L.r[low] = L.r[0];
return low;
}选择排序:
冒泡排序是通过两两比较并交换每次冒出一个最大的“泡泡”放最后,而选择排序是从待排记录中选择一个最小的放在最前面,只不过找最小的记录的方法和冒泡排序不同
简答选择排序:
简单选择排序又称为直接排序,是一种最简单选择排序方法,每次从待排序序列中选择一个最小的放在最前面的位置
void SeLectSort(Sqlist& L) {
for (i = 1; i < L.length; i++) {
k = i;
for (j = i + 1; j <= L.length; j++) {
if (L.r[j].key < L.r[k].key) {
k = j;
}
}
if (k != i) {
L.r[i]<-->L.r[k];
}
}
}堆排序:
堆排序是一种树形选择排序,在排序过程中,将待排序的记录放在r[1...n]看成一颗完全二叉树的顺序结构,利用完全二叉树中双亲结点和孩子结点之间的内在关系,在当前无序的列表中选择关键字最大(最小)记录
算法:
/本函数调整R[s]的关键字,使R[s...m]成为大根堆
void HeapAdjust(elem R[], int s, int m) {
rc = R[s];
for (j = 2 * s; j <= m; j *= 2) {
if (j < m && R[j] < R[j + 1])
++j;
if (rc >= R[j])
break;
R[s] = R[j];
}
R[s] = rc;
}
//堆排序
void HeapSort(elem R[]) {
int i;
for (i = n / 2; i >= 1; i--) {
HeapAdjust(R, i, n);//初建堆
for (i = n; i > 1; i--) {
Swap(R[1], R[i]);
HeapAdjust(R, 1, i - 1);//对R[1]到R[i-1]重新建堆
}
}
}各种排序性能比较:
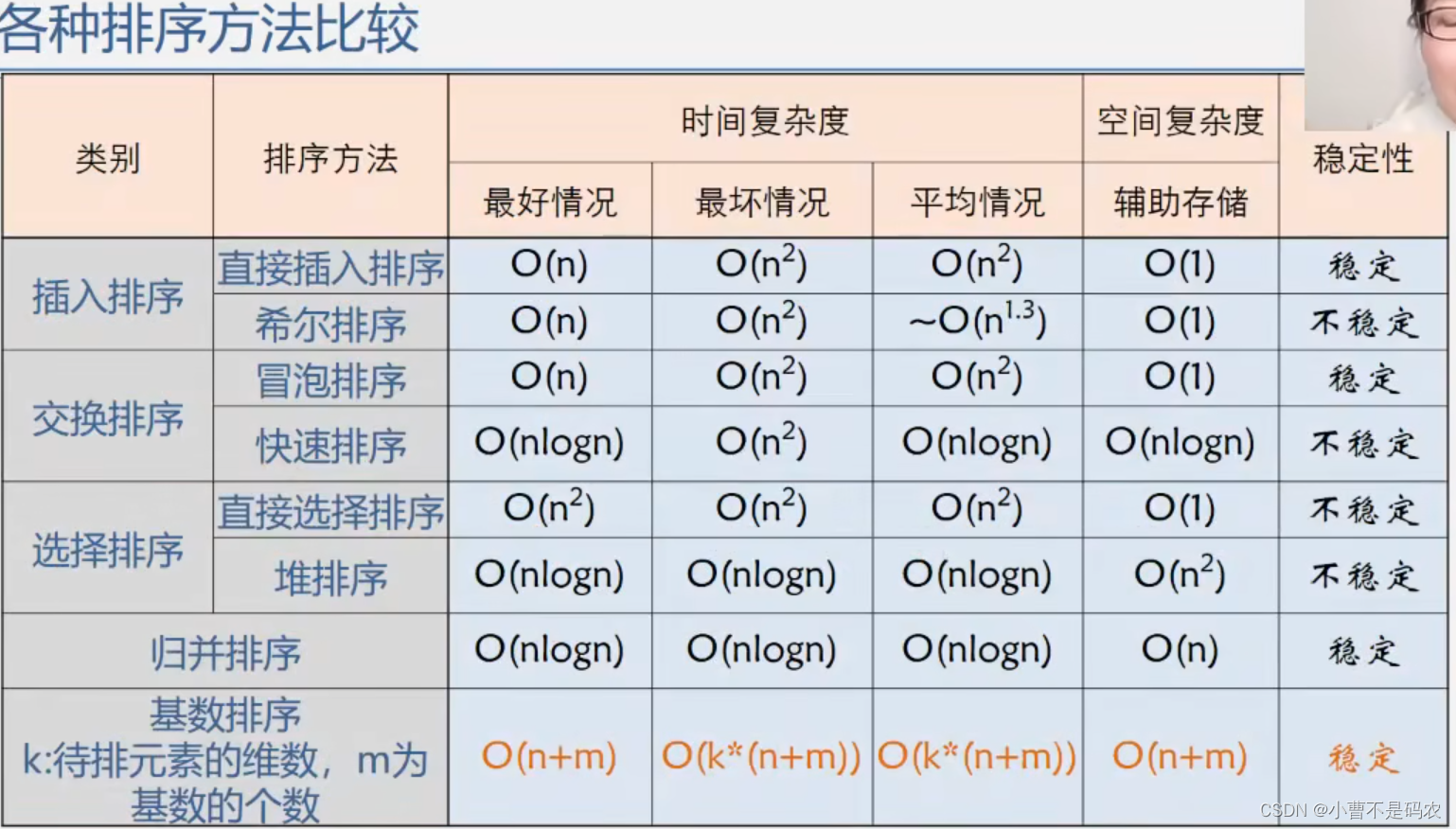
对归并排序和基数排序在这里不在叙述,如果感兴趣的话可以找相关视频观看















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









