






YOLOv4——概念篇
YOLOV4原版论文获取网站:https://arxiv.org/abs/2004.10934
在 arXiv 页面上,点击 “PDF” 链接即可直接下载。
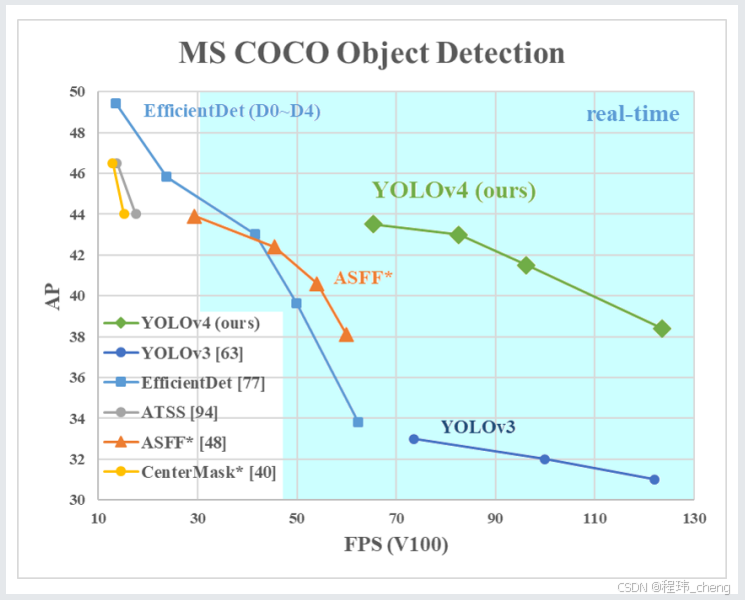
相比于前3版,整体框架无太大变化,在一些细节上面进行了优化,主要体现在数据增强、损失计算、特征提取及网络优化等方面,下面会具体的来看看其优化之处,并深入的学习其中的优秀思想。
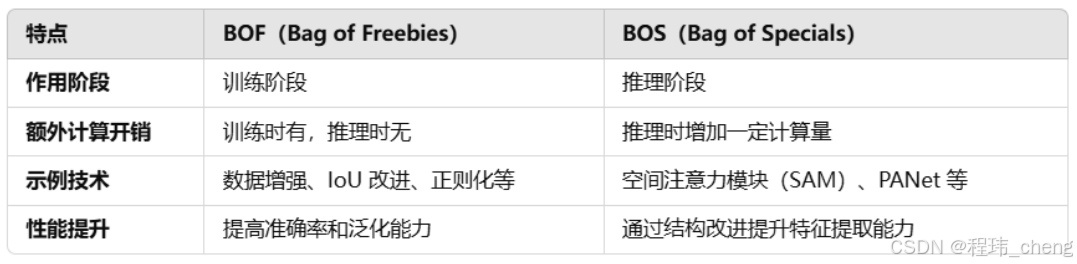
主要在BOF(Bag of Freebies)和BOS(Bag of Specials)2类处理方法进行改进优化,下面就具体的说说。
BOF方法
BOF(Bag of Freebies)是 YOLOv4 论文中提出的一个概念,指的是在不增加推理时间的前提下,提升模型性能的方法。这些方法主要在训练阶段引入,目的是通过更优的训练策略和技巧,改善网络的性能(准确率),而不会增加推理阶段的计算成本或时间开销。

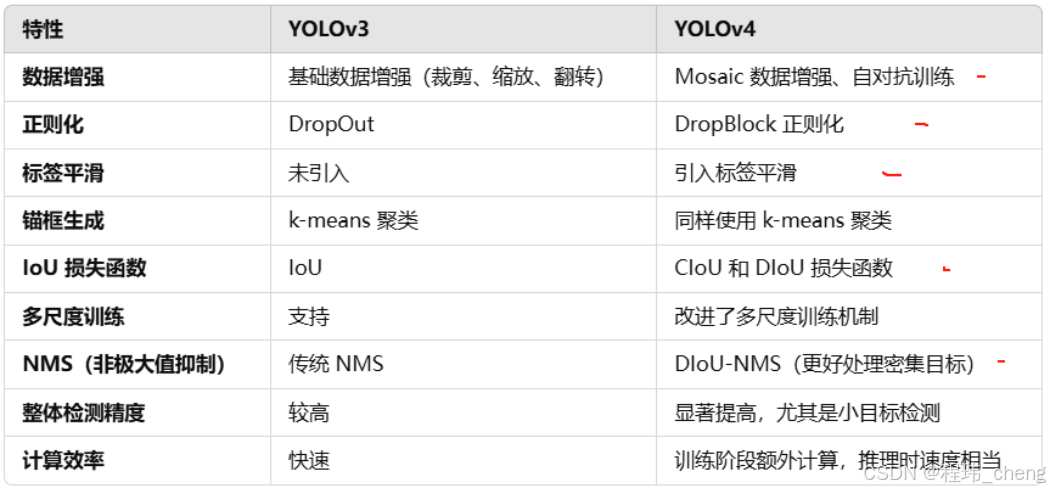
以下是在YOLOv4中主要用到的 Bag of Freebies 技巧:
数据增强(Data Augmentation)
在训练阶段对数据进行变换,增强数据的多样性,帮助模型提升泛化能力。主要应用了一下几种处理方法:
拼接数据增强(Mosaic Data Augmentation)
方法很简单,顾名思义就是把多个图像拼接为一个图片,就和手机相册里面的拼图操作一样,在这里将拼接后的图像数据用来训练,可以简化训练的复杂度,训练一次相当于原来四次,而且一个图片中的类别也增加了,便于提高模型的泛化能力。当然这个是理论上面的,实际情况要尝试才知道,可能YOLOV4的作者经过大量的试验得出这个设想是可行的。

图6中左侧的是其他类似的处理方法。
-
CutMix:将两幅图像按照一定比例混合,生成一幅新的图像
-
- 标签:Dog 0.5,Cat 0.5(置信度按比例混合)
-
Cutout:在图像中随机遮挡一块区域(用黑色块替代),增加模型对遮挡的鲁棒性
-
- 标签:Dog 1.0(不改变标签分布)
-
CutMix:将一幅图像的区域随机裁剪并粘贴到另一幅图像中,同时标签也按区域比例进行混合。
-
- 标签:Dog 0.6,Cat 0.4(置信度按区域比例混合)
随机擦除(Random Erasing)
通过在训练图片中用随机值或训练集的平均像素值替换图像的部分区域,迫使网络学习更全面的特征,使得网络不能只依赖局部特征,而是需要结合上下文信息来完成任务,以此来达到增强网络对遮挡的鲁棒性和避免过拟合的问题。

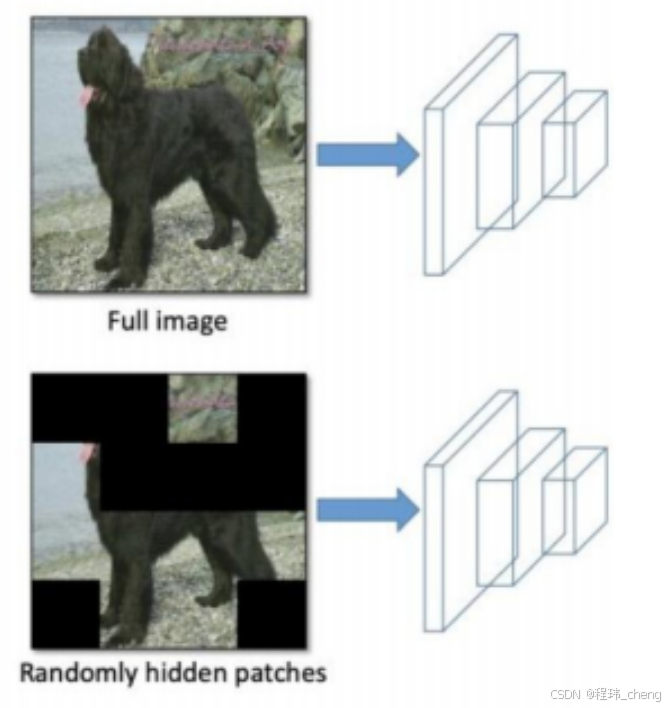
捉迷藏数据增强(Hide and Seek)
Hide and Seek是一种遮挡增强技术,根据概率设置随机隐藏一些补丁来遮挡图像的某些小块区域,让模型尝试在缺失信息的情况下仍然能够识别目标。通过“隐藏”部分信息,训练模型学会从非关键区域提取特征的能力。
自对抗训练(Self-Adversarial Training)
简单的说就是通过引入噪音点来增加游戏难度,具体分为2个阶段:
-
第一阶段:网络尝试生成错误的预测,扰乱输入图像的特征。
-
第二阶段:网络根据自己“错误的预测”进行自我校正,从而提升对目标特征的学习能力。
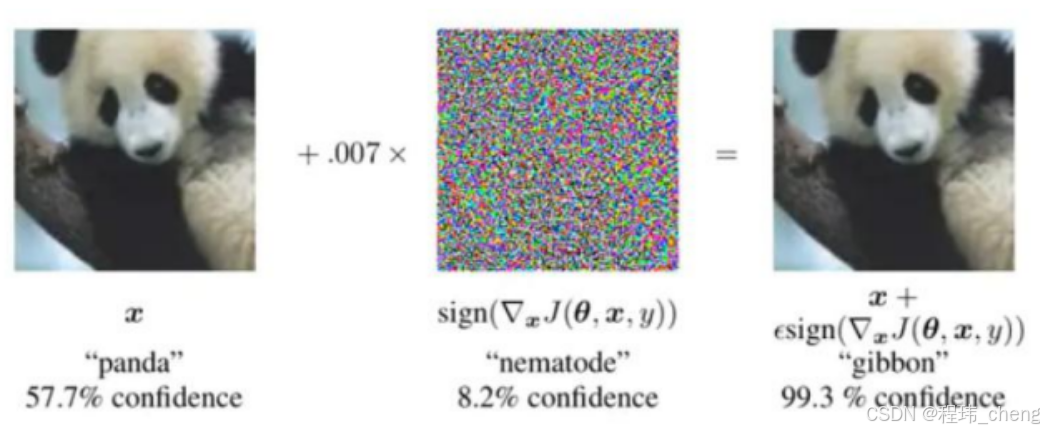
图9通过FGSM攻击展示了对抗样本的生成过程,强调了神经网络在面对微小扰动时的脆弱性,其最小化人类视觉差异而最大化神经网络的误导(如梯度方向扰动),来训练提高模型的泛化能力。
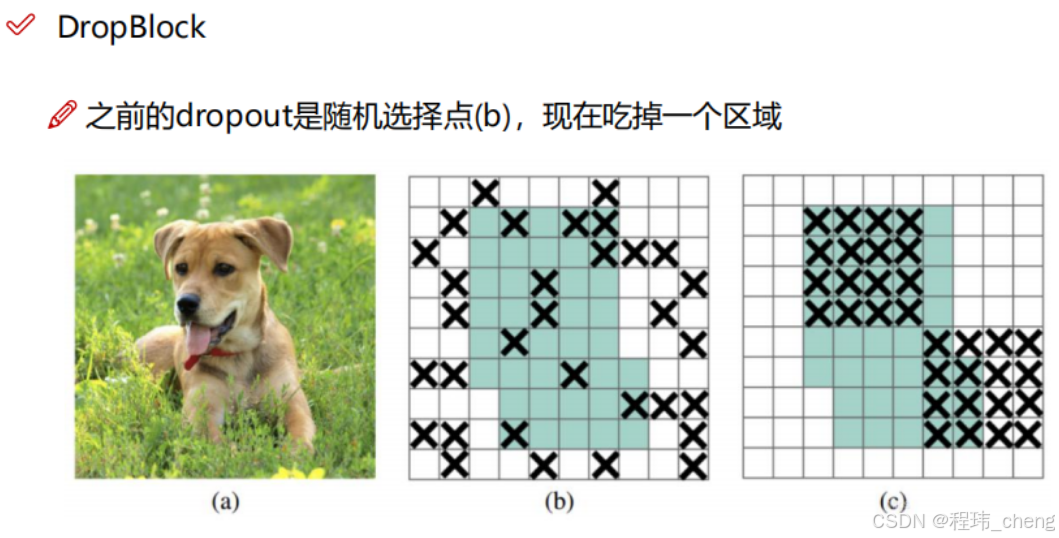
随机块丢弃(DropBlock)
DropBlock是Dropout的改进版本,从单个像素点置0改为一个小区域置0,从而防止模型依赖局部特征。
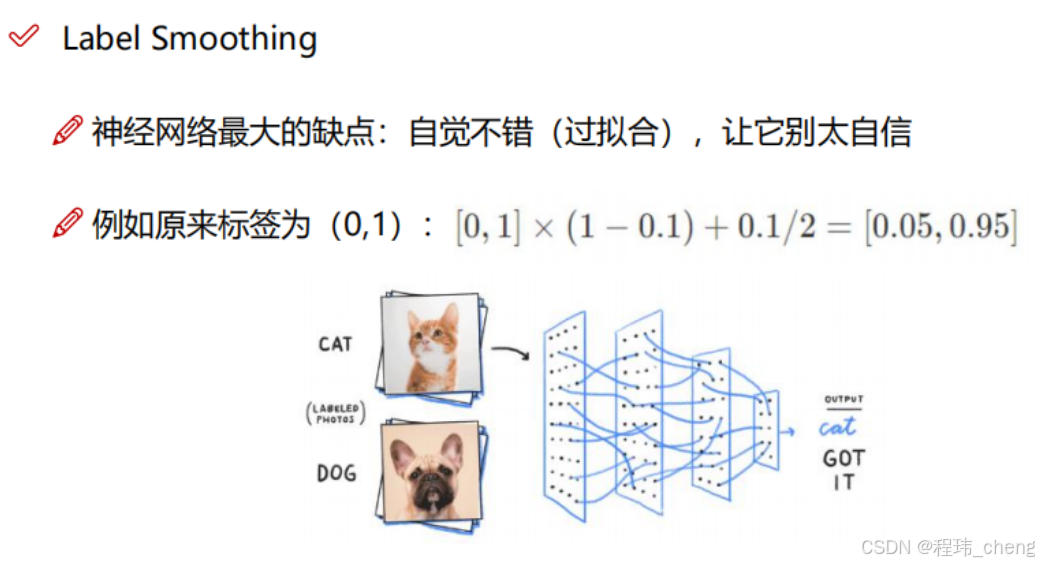
标签平滑(Label Smoothing)
平滑训练标签,降低模型对错误预测的惩罚,提升泛化能力。例如:将标签[0,1,0]平滑为[0.1,0.8,0.1],就是降低模型对于某一类判断的置信度,以减小过拟合的风险。
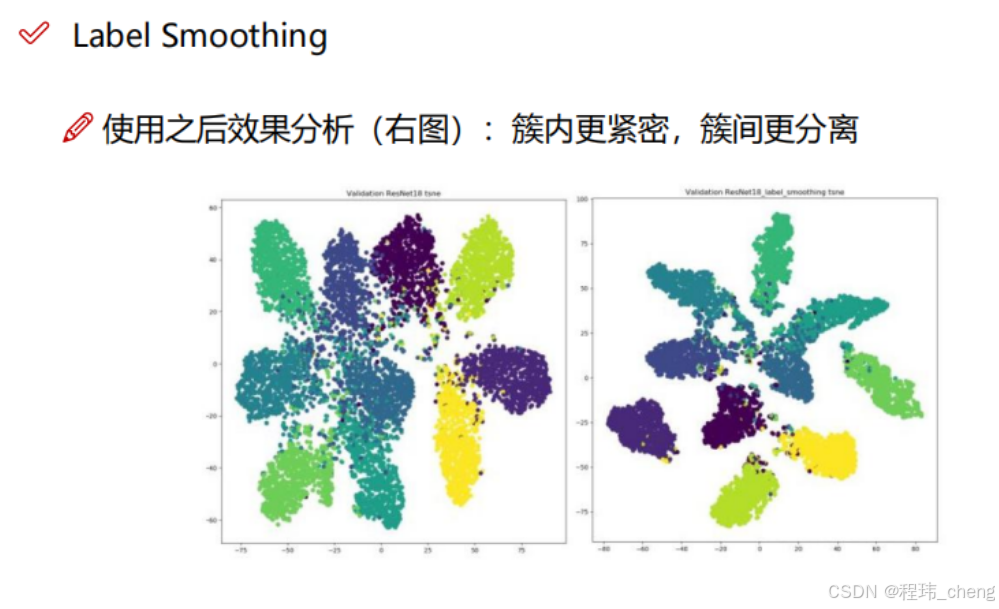
从图12中可以看出各个类别中间确实分的更开了,说明确实能够使得模型过拟合的风险降低——类簇重叠部分变少。
IoU损失函数改进
IOU -> GIOU -> DIOU -> CIOU的改进过程,其中CIOU即YOLO系列中采用的损失计算方法。
(1)IoU(Intersection over Union)—— 交并比
即YOLO之前采用的目标检测评价指标,通过计算两个边界框的重叠程度来判断检测的精度。
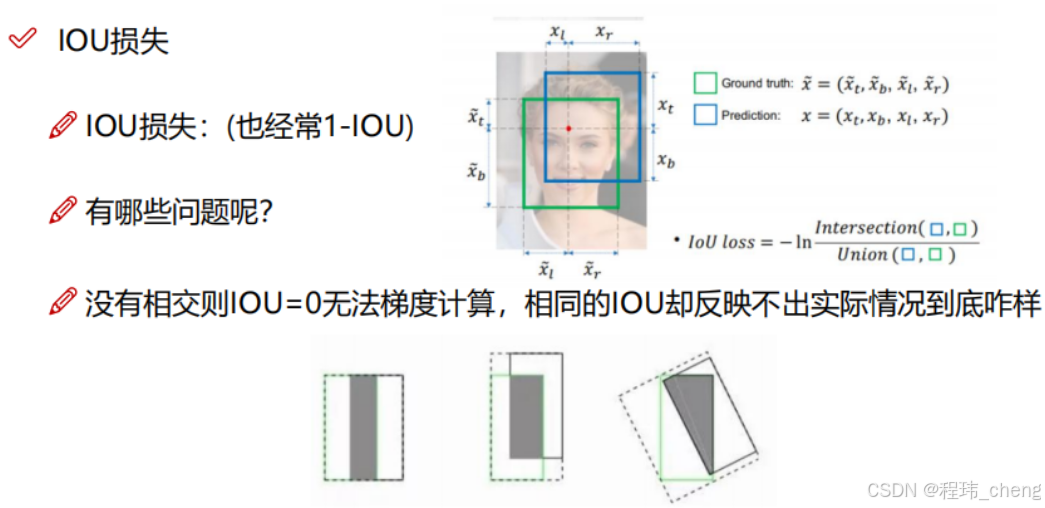
- 缺点一:当先验框与检测框不重叠的时候,IOU为0,因梯度消失无法进行梯度的反向传播,则无法进一步的优化。
- 缺点二:如图13下方的几种情况,其IOU相同,模型无法区分进而无法确定优化的方向,导致训练效果不佳。
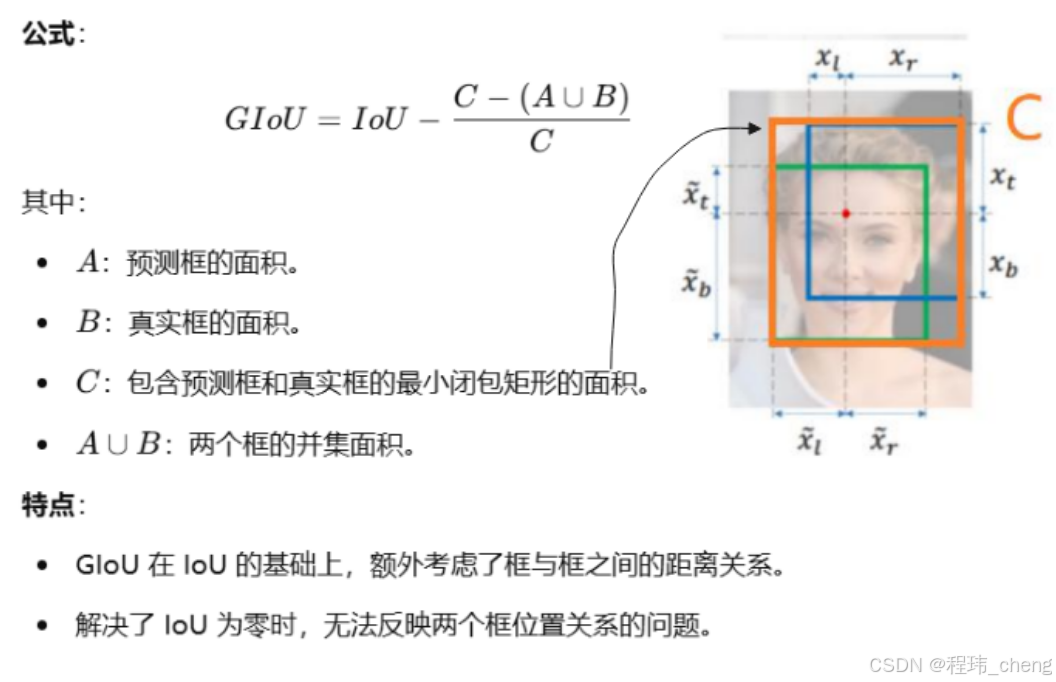
(2)GIoU(Generalized IoU)—— 广义交并比
在IOU的基础上面多考虑了距离,即针对IoU在没有重叠区域时为零的问题,GIoU引入了最小闭包矩形的概念,适用于边界框无重叠的情况,从而区分刚刚说到的交并比相同的情况。
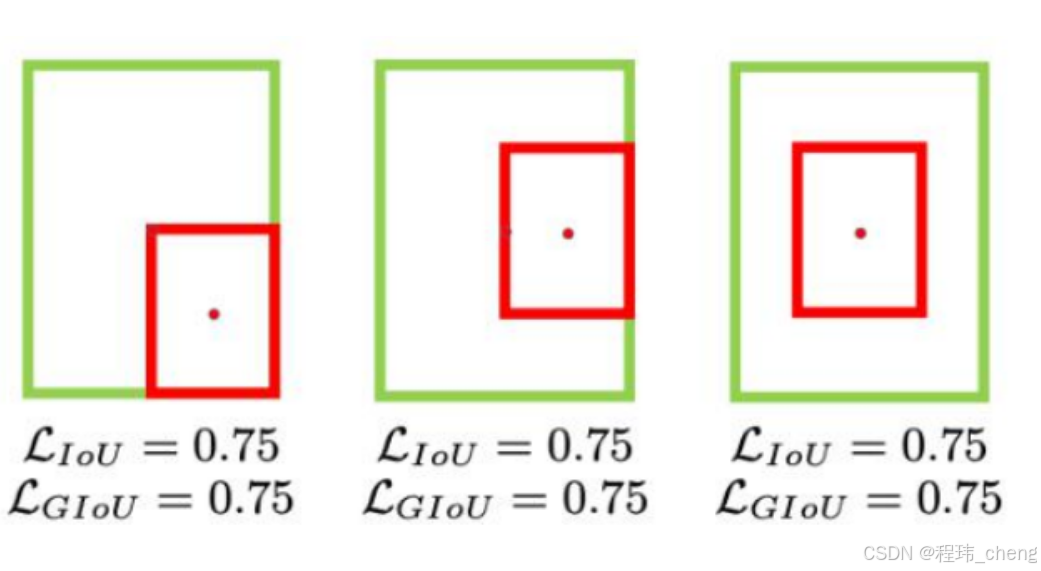
- 缺点:当先验框与检测框重叠的时候GIOU又相同了,出现和IOU类似的情况,就像下图所示。
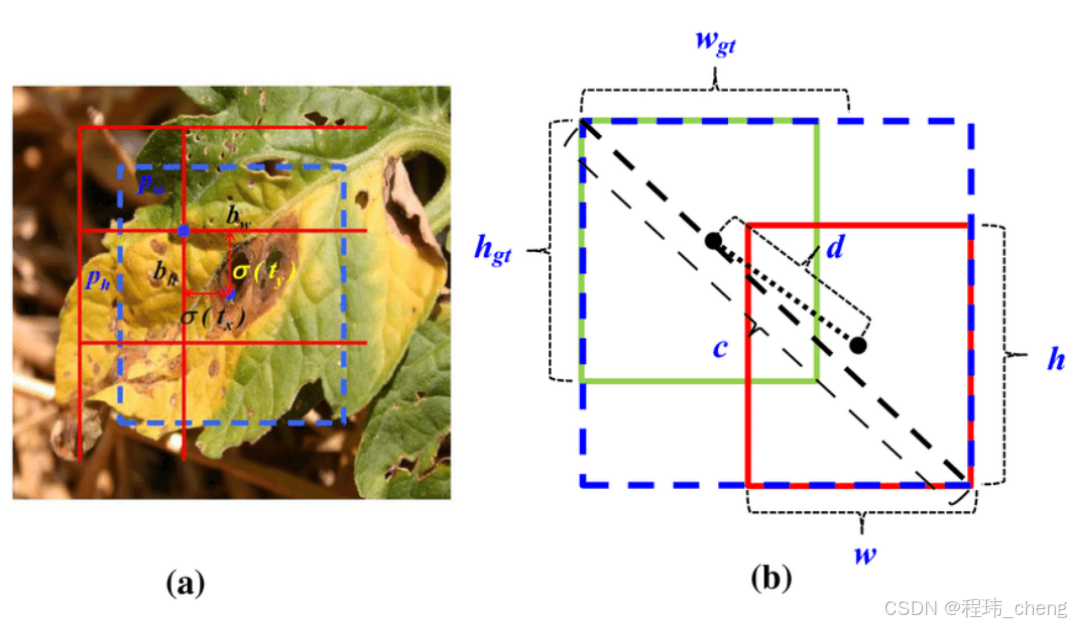
(3)DIoU(Distance IoU)—— 距离交并比

(4)CIoU(Complete IoU)—— 完全交并比

上面的了解一下就可以了,知道YOLOv4用的是CIOU,然后知道CIOU考虑了三个几何因素:重叠面积,中心点距离,长宽比,即可。
非极大值抑制方法(NMS)的改进
在目标检测中,NMS(Non-Maximum Suppression,非极大值抑制) 是常用的后处理方法,主要用于去除重叠较大的预测框,保留最优的边界框。
距离IoU非极大值抑制(DIoU-NMS
通过引入中心点距离作为筛选标准,适用于密集目标检测,定位更精准,适合需要严格筛选边界框的场景。
相比于NMS采用IOOU为检测精度指标,DIOU-NMS以DIOU为指标即判断检测框与先验框是否重叠的能力更强,依然是保留经排序后置信度最大的检测框为保留。

软非极大值抑制(Soft-NMS)
无论是NMS还是DIOU-NMS,如果两个框的IoU值大于设定阈值,置信度较低的框会被直接剔除,经过不断的筛选仅仅保留置信度最大的检测框。而Soft-NMS 改变了这一机制,而是对重叠较小的边界框降低置信度,而不是直接移除。

通过置信度衰减,而非剔除边界框,适合多目标检测和密集目标场景,避免丢失潜在目标框。
以上即YOLOv4在数据预处理层面的改进与优化,让模型能够得到并利用更高质量与高难度的训练数据,从而提升其泛化能力。
BOS方法
通过添加特殊的网络结构模块来增强模型的性能.

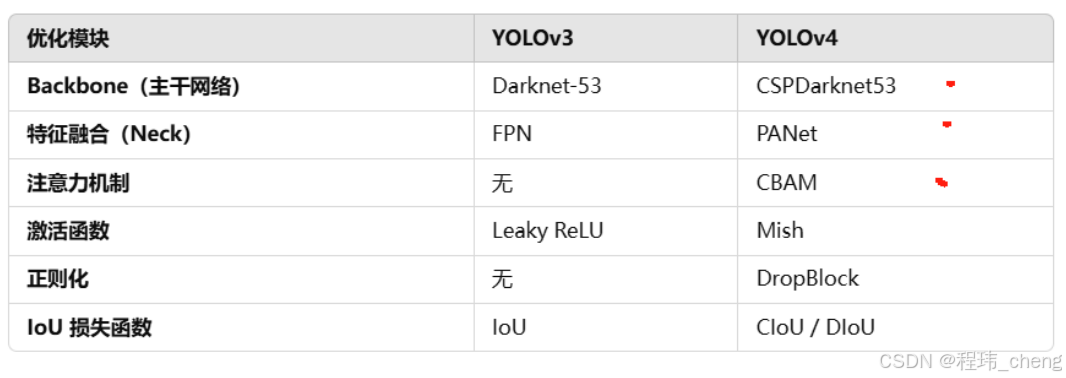
空间金字塔池化(SPPNet)
论文网址:https://arxiv.org/abs/1406.4729
YOLOv3中对于输入数据的维度有明确的要求,因为全连接层对输入特征维度有限制。而SPPNet则可以解决这一问题,通过引入多尺度池化机制,实现了对任意尺寸输入图像的处理,同时保留了多尺度特征——全局(大池化核)和局部(小池化核)的信息,有助于提高模型的泛化性能和准确度。下面具体的说说其是如何实现的:
具体而言,其将不同维度的特征图直接同时进行全局平均池化、2*2的平均池化、4*4的平均池化,最后在将各池化处理的结果拼接在一起,得到带有各层级信息的固定维度的特征图/特征向量(展平)。其能够实现对于不同维度输入的同维度输出主要是因为其直接进行池化,而前面卷积处理相同得到同样个数的特征图,从而使得明显能够处理不同维度的输入,具有更高是适应性。
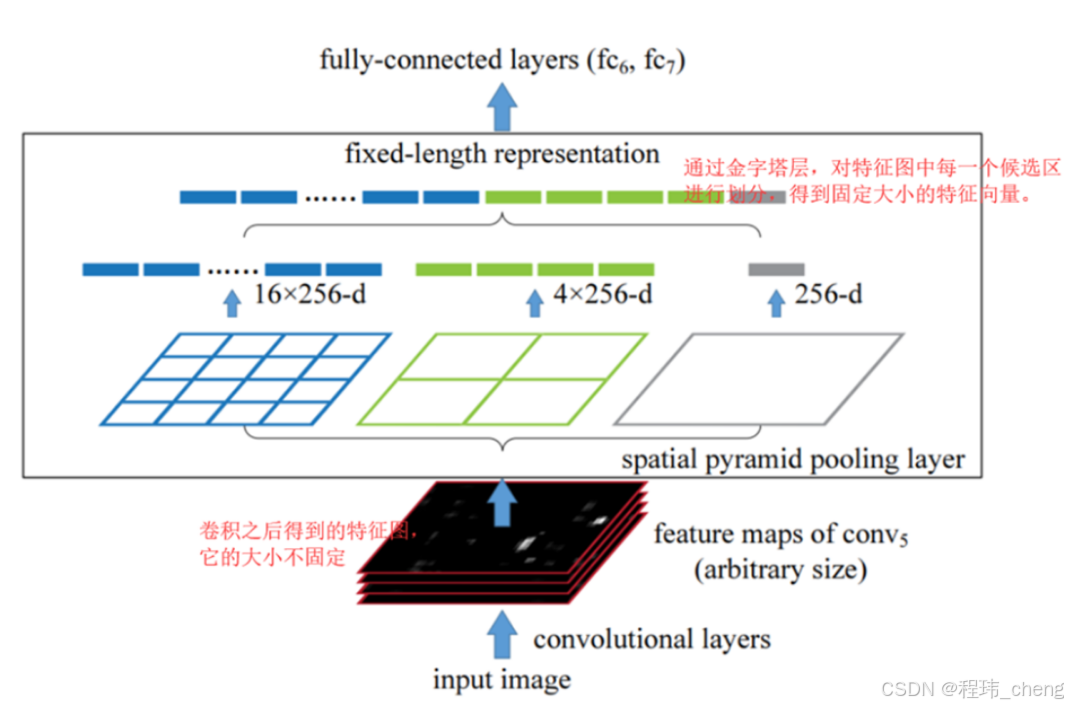
交叉阶段部分网络(CSPNet)
论文网址:https://arxiv.org/abs/1807.06521
简单的说,就是通过将特征分块,部分特征直接传递到下一阶段,部分特征正常走,从而减少重复计算和特征冗余,提升效率。
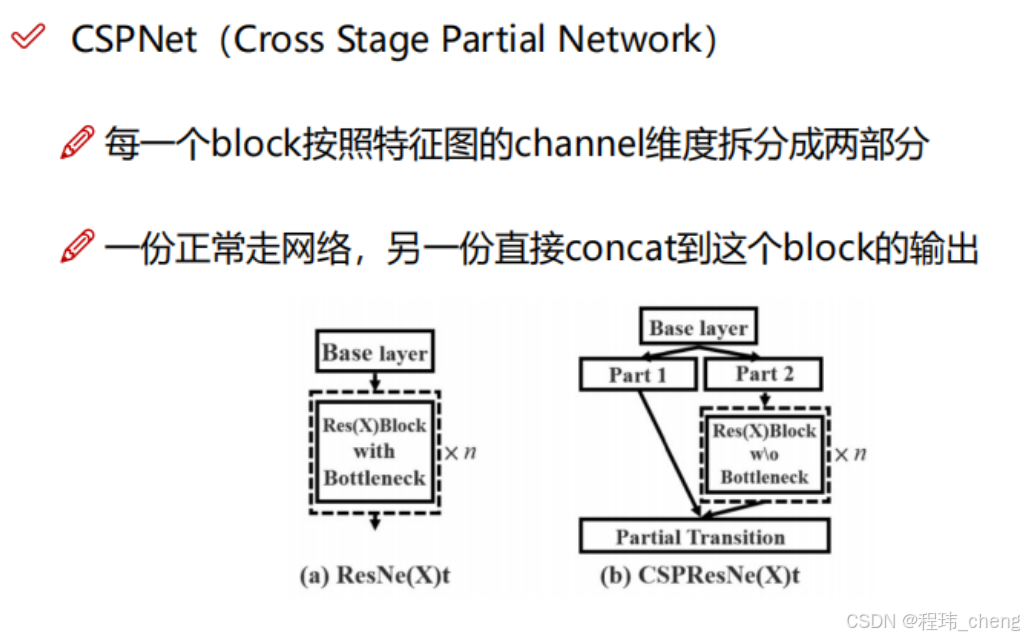
卷积块注意力模块(CBAM)
论文网址:https://arxiv.org/abs/1807.06521
CBAM 是一种注意力机制模块,结合了通道注意力(Channel Attention)和空间注意力(Spatial Attention)。通过对重要通道和重要空间位置的特征加权,提升网络关注关键区域的能力。
下面分开CAM与SAM来讲并且说说在YOLOv4中又做了哪些改进。
通道注意力模块(CAM)
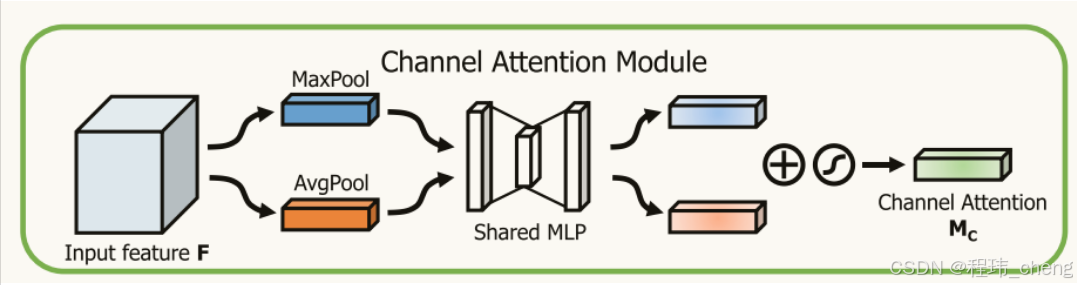
通过对通道维度(即特征图个数维度)上的特征进行加权,学习出哪些通道更加重要。其关注的是“哪些通道(特征图)更重要”,通过全局平均池化和最大池化学习通道级的权重。具体流程如下:
-
池化操作:对输入特征图分别进行全局平均池化和全局最大池化,获得两个通道级(1*1*特征图个数)的描述向量。
-
共享的MLP(多层感知机):将两个描述向量通过MLP处理,学习通道注意力权重。
-
融合与激活:将池化得到的两个结果加和,再通过Sigmoid激活函数生成通道注意力权重。
-
加权输入特征:通道注意力权重与输入特征图进行通道维度的逐元素乘法(⊗),得到调整后的特征图。
得到的权重是描述各个特征图对于模型训练更有意义的程度。
假设输入一个狗和猫的图像,经过卷积神经网络提取特征,产生C=4个通道的特征图,每个通道捕捉不同的特征:
- 通道 1:主要捕捉边缘信息(例如猫和狗的轮廓)。
- 通道 2:捕捉毛发纹理。
- 通道 3:捕捉背景的颜色信息。
- 通道 4:捕捉狗的特征区域。
效果:
- CAM 可能会为通道1和4(边缘信息和狗的特征)分配较高的权重,突出重要的特征通道。
- 对 通道3(背景信息)分配较低的权重,降低其影响。
空间注意力模块(SAM)
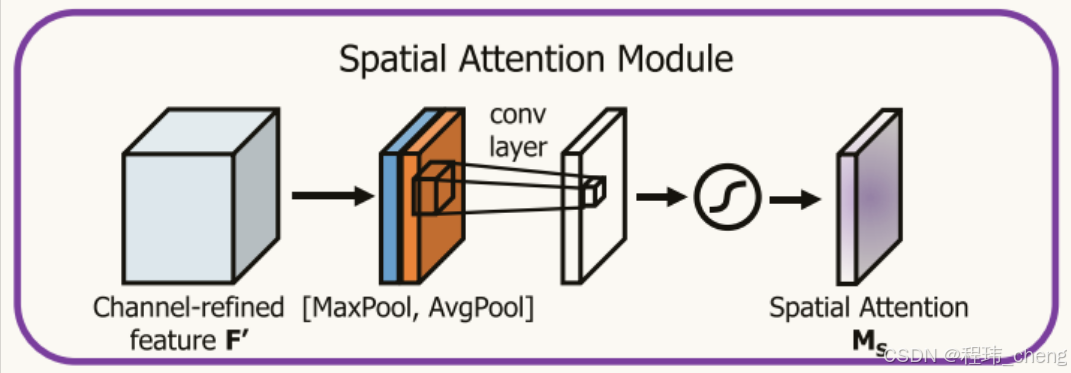
其根据不同的空间位置的重要性,分配不同的权重,从而突出关键区域,此外其关注的是“哪些空间位置更重要”,通过空间维度的平均池化和最大池化提取出权重。具体流程如下:
-
通道压缩:将经过通道注意力的特征图进行通道维度的最大池化和平均池化,分别生成两个单通道特征图。
-
拼接操作:将两个单通道特征图拼接成一个新的特征图。
-
卷积操作:对拼接的特征图使用一个7×7卷积核进行卷积操作,学习出空间注意力权重。
-
加权特征图:通过 Sigmoid 激活函数生成空间注意力权重,并与输入特征图进行逐元素乘法(⊗)。
额外说明:通道压缩的时候是对于所有的特征图进行平均池化、最大池化。

但是在YOLOv4中对于SAM进行了简化,如下图:
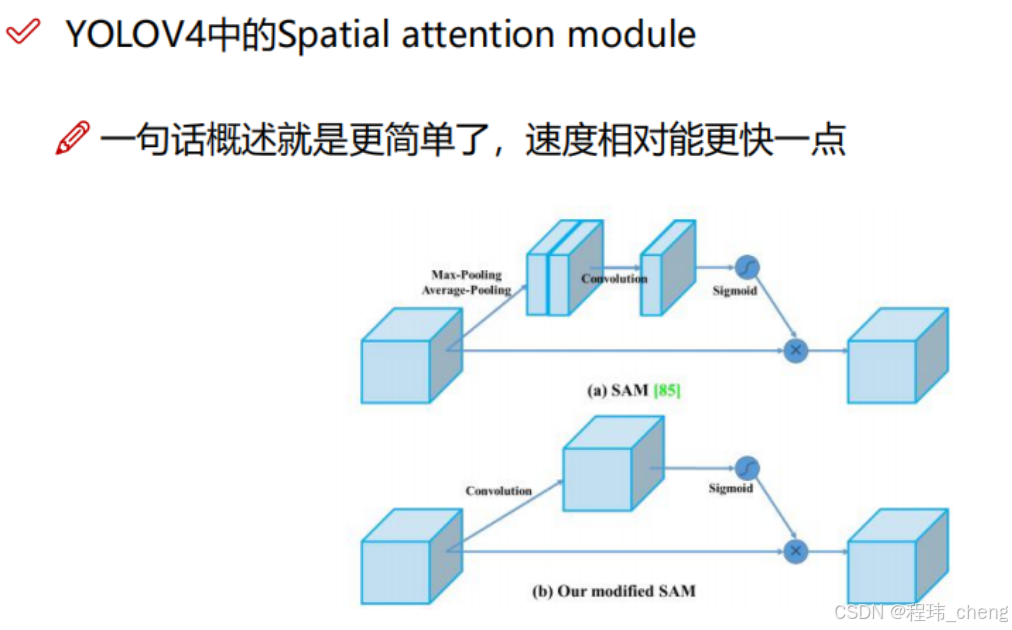
继续上述示例,输入特征图(经过 CAM 后的输出):
- 重点位置:狗的头部区域。
- 次要位置:背景区域。
效果:
- SAM 可能会对狗的头部区域(所有图像的同一部分)赋予较高权重,突出关键位置。
- 对背景区域赋予较低权重,降低背景对网络的干扰。
路径聚合网络(PAN)
论文网址:https://arxiv.org/abs/1803.01534
在说PAN之前,先介绍一下FPN,因为PAN是其的升级版,都是用于融合提取高低层特征的模块。
特征金字塔网络(FPN)
论文网址:https://arxiv.org/abs/1612.03144
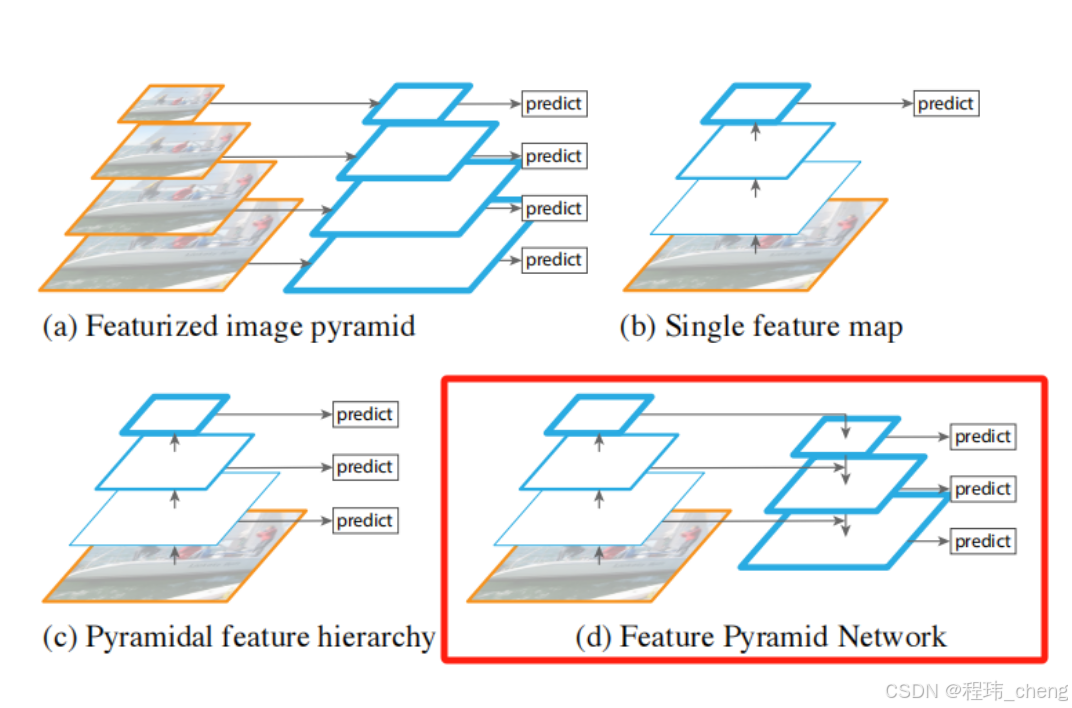
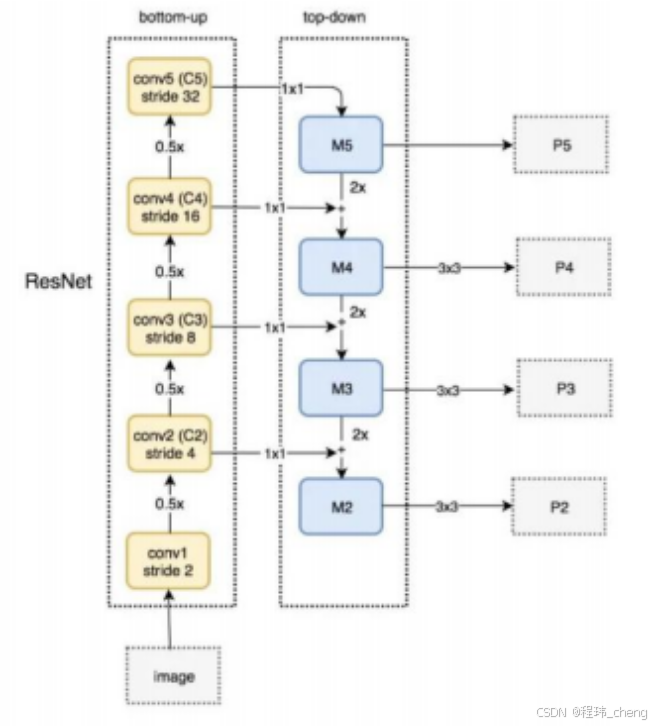
如上图所示,简单点说就是通过上采样自顶向下的与对于层的特征图进行横向连接融合,以补充细节信息,最后生成多个尺度的特征图,每一层特征图都可用于目标检测。
但是其仅仅让底层特征接收到了传递下来的顶层信息,而没有充分的让顶层接受到底层的信息,即局限于传递的单向性。从而提出了双向传递的PAN网络,更好的融合底层顶层信息。
具体而言,PAN中的双向并不是真正的双向,而是继续了简化,通过新的路径连接使得底层的信息通过卷积、池化等操作逐步融合到高层。具体流程如下图所示:
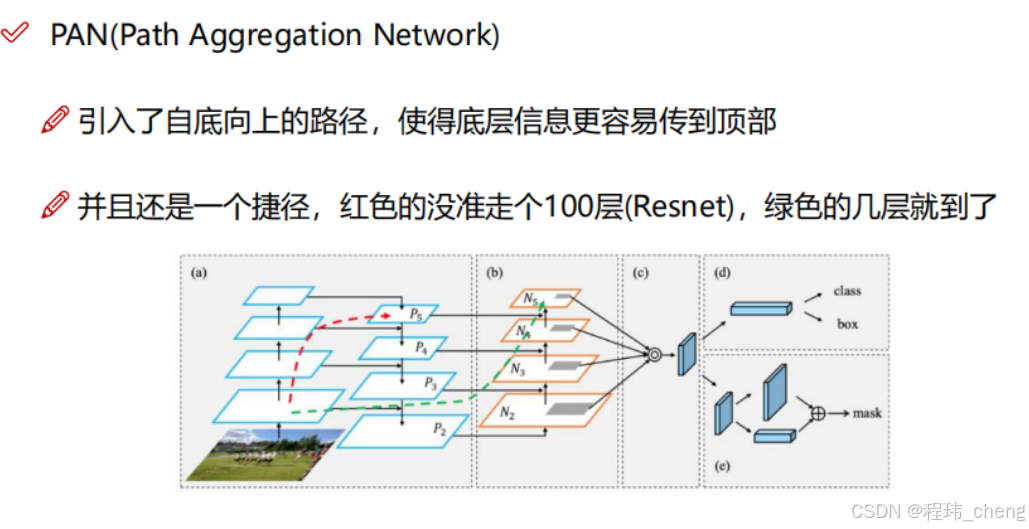
- 通过红线、绿线将最初的底层信息经卷积池化连接到顶层处。
- 在经过下采样之后,直接在进行上采样并且融合横向连接传递的特征,避免了在原特征图上的重复操作,结合了多尺度信息。
- 最终融合多层特征,实现多尺度目标的检测与分割。
此外在YOLOv4中还进行了如下修改:
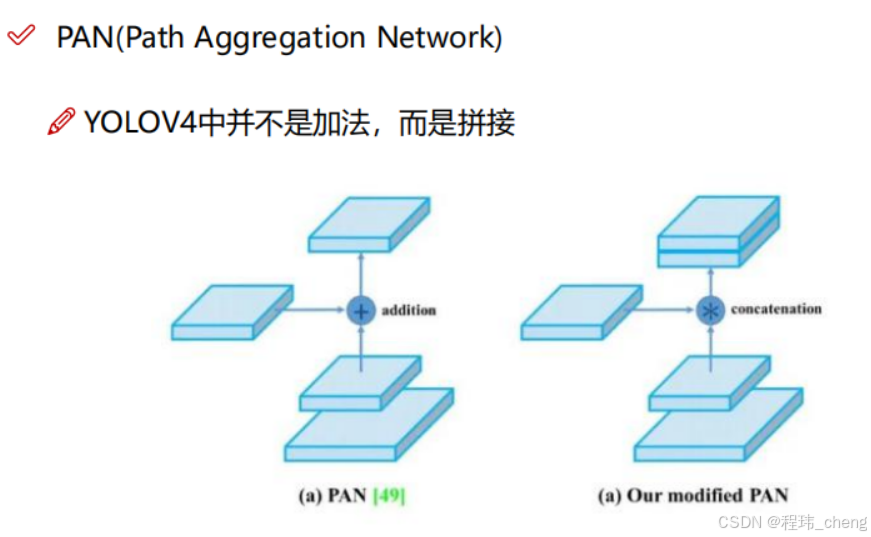
消除网格敏感性(Eliminate Grid Sensitivity)

整体流程

这张图描述了YOLOv4从数据准备到模型训练,再到最终推理和评估的完整流程。关键点包括:
- 数据准备阶段的标注和增强。
- 数据划分和预训练权重的使用。
- 模型训练过程中的超参数设置和验证。
- 测试和性能评估以验证模型的泛化能力。
最终检测结果的输出。
这一流程反映了YOLOv4在实际应用中的标准工作流程,可以作为实践目标检测任务的参考。
整体框架示意
能够看懂下面的示意图、知道整体的流程即可,主要学习的是源码。
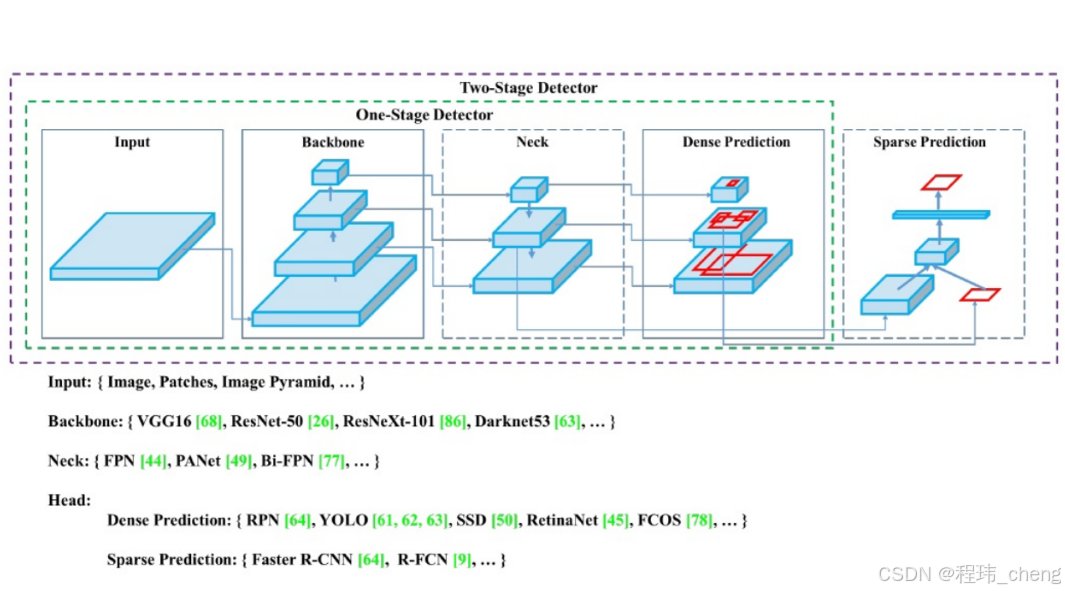
补充说明:
-
Dense Prediction(密集预测):每个像素点都参与预测目标类别和位置,生成密集的预测。
-
Sparse Prediction(稀疏预测):先生成少量的候选区域(Proposals),然后在候选区域中进行精细预测。
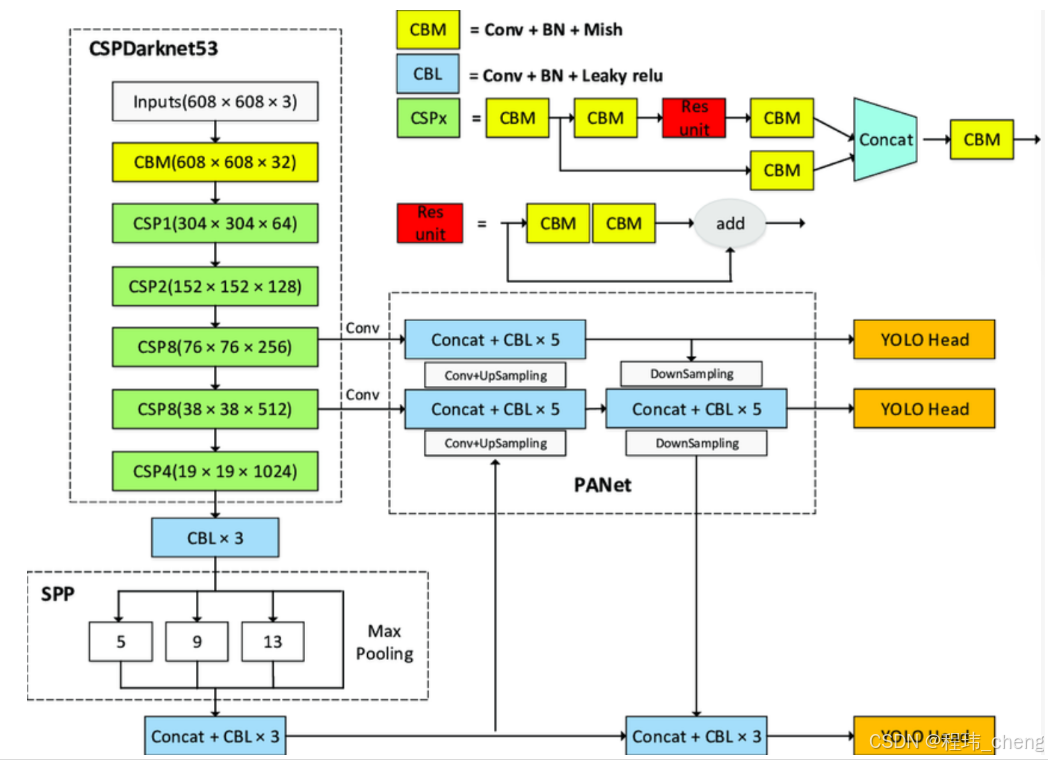
** 关键模块解析**:
-
主干网络(CSPDarknet53):
负责提取基础特征,使用 CSP 和 ResNet 结合的高效特征提取网络。 -
- CSP2代表有2个CSPX模块。
-
特征融合网络(PANet):
对 Backbone 输出的多尺度特征进行融合,增强网络对多尺度目标的检测能力。 -
预测头(YOLOv3 Head):
基于多尺度特征进行检测,输出类别和边界框。
通过这种结构,YOLOv4 实现了对不同尺度目标的高效检测,同时兼顾了检测精度和推理速度,非常适合实际应用场景。
以上即YOLO v4的概念部分。更加详细的模块说明可以参考如下的博客及视频:
https://blog.csdn.net/hgnuxc_1993/article/details/120724812?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522266f53686759d55db60e71c8fc0a71a2%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=266f53686759d55db60e71c8fc0a71a2&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-120724812-null-null.142^v100^pc_search_result_base9&utm_term=yolo%20v4&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_42454048/article/details/107014616?ops_request_misc=&request_id=&biz_id=102&utm_term=yolo%20v4&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-3-107014616.142^v100^pc_search_result_base9&spm=1018.2226.3001.4187
https://www.bilibili.com/video/BV1NF41147So/?spm_id_from=333.1387.search.video_card.click&vd_source=485a3ba55b82ab1e9f0d8386e3dd8fcc
推荐一个GitHub项目,里面有非常全面的文档及视频讲解:
https://github.com/WZMIAOMIAO/deep-learning-for-image-processing


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









