






目录
一、引言
希尔排序(Shell Sort)是插入排序的一种改进版本,也称为“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
该方法是由唐纳德·希尔(Donald Shell)于1959年提出的一种排序算法。希尔排序是基于插入排序的以下两点性质而提出改进方法的:
1 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率。
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
2 希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列(由相隔某个“增量”的记录组成的)分别进行直接插入排序,
然后依次缩减增量再进行排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
二、希尔排序的基本原理
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,
待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
- 选择一个增量序列 t1,t2,…,tk,其中 ti > tj, tk = 1。
- 按增量序列个数 k,对序列进行 k 趟排序。
- 每趟排序,根据对应的增量 ti,将待排序序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。
仅增量因子因子发生变化,而排序算法不变,各趟排序后,整个序列基本有序了,再对全体记录进行一次直接插入排序。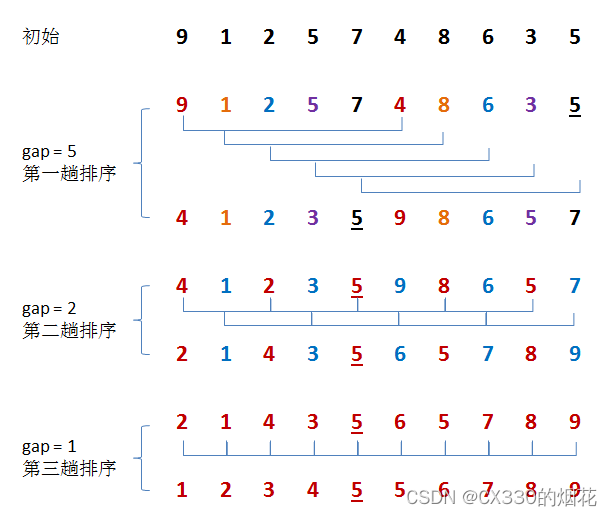
三、希尔排序的实现步骤
- 选择一个增量序列 t1,t2,…,tk,其中 ti > tj, tk = 1。
- 按增量序列个数 k,对序列进行 k 趟排序。
- 每趟排序,根据对应的增量 ti,将待排序序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子因子发生变化,而排序算法不变,各趟排序后,整个序列基本有序了,再对全体记录进行一次直接插入排序。
具体实现可以参考以下代码:
public class ShellSort {
public static void shellSort(int[] arr) {
int n = arr.length;
int gap = n / 2; // 初始步长
// 开始循环,直到步长为1
while (gap > 0) {
// 进行插入排序
for (int i = gap; i < n; i++) {
int temp = arr[i];
int j = i;
// 插入排序,比较并交换元素
while (j >= gap && arr[j - gap] > temp) {
arr[j] = arr[j - gap];
j -= gap;
}
arr[j] = temp;
}
// 缩小步长
gap /= 2;
}
}
public static void main(String[] args) {
int[] arr = {9, 8, 3, 7, 5, 1, 4, 2, 6};
shellSort(arr);
System.out.println("Sorted array: ");
for (int i : arr) {
System.out.print(i + " ");
}
}
}
四、适用场景
1.中等规模的数据:
希尔排序对于中等规模的数据集(例如,几百到几千个元素)通常表现良好。在这种情况下,它比简单的插入排序或冒泡排序更快,但可能不如针对大规模数据设计的算法(如快速排序、归并排序或堆排序)高效。
2.基本有序的数据:
如果数据集已经是部分有序的,希尔排序可以非常高效。因为它通过比较较远的元素来工作,所以它可以在数据已经基本有序的情况下快速完成排序。
3.外部排序:
希尔排序也适用于外部排序,即当数据集太大,无法一次性加载到内存中时。在这种情况下,可以将数据分割成小块,对每块进行希尔排序,然后合并结果。
4.稳定排序不是必要条件:
如果应用程序不需要稳定排序(即相等的元素在排序后保持原有的相对顺序),希尔排序是一个合理的选择。
5.低开销的数组访问:
希尔排序适用于可以通过索引快速访问的数组类型数据结构。如果数据结构不支持快速索引访问(例如链表),则希尔排序可能不是最佳选择。
五、如何选择合适的增量序列
选择合适的增量序列对于希尔排序的性能至关重要。增量序列的选择决定了算法中各个阶段的排序效率和整体排序速度。以下是一些常用的增量序列选择策略:
1.Hibbard 增量序列:
Hibbard 增量序列定义为 Ti = 2^k - 1,其中 k 是从 0 开始递增的整数。这个序列的优点是它在每个阶段都会将元素分成大致相等的两部分,有助于减少比较次数。但是,Hibbard 增量序列可能不是最优的,尤其是在处理某些特定类型的数据时。
2.Sedgewick 增量序列:
Sedgewick 增量序列定义为 Ti = 9 * 4^i - 9 * 2^i + 1,其中 i 是从 0 开始递增的整数。这个序列的优点是它在开始时使用较大的增量,这有助于快速地将元素移动到它们应该在的位置,然后在后面使用较小的增量进行微调。Sedgewick 增量序列在实践中通常比 Hibbard 增量序列表现更好。
3.自定义增量序列:
除了上述两种常用的增量序列外,还可以根据具体的应用场景和需求来自定义增量序列。例如,可以根据数据的特性或分布来选择合适的增量,或者通过实验来找到最优的增量序列。
需要注意的是,选择合适的增量序列并没有固定的规则或标准。通常需要根据具体的数据集、排序要求(如稳定性、时间复杂度等)以及实验结果来做出决策。因此,在实际应用中,可能需要尝试不同的增量序列来找到最适合特定场景的解决方案。
六、总结
希尔排序是一种基于插入排序的改进算法,通过引入增量序列来提高排序效率。在实际应用中,希尔排序的性能通常优于直接插入排序,特别是在待排序序列基本有序时。然而,希尔排序也存在一些局限性,如稳定性较差、性能受增量序列选择影响等。因此,在选择排序算法时需要根据具体的应用场景和需求进行权衡和选择。















 3591
3591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









