







本文是记录专业课“程序语言理论与编译技术”的部分笔记。
LECTURE 13(初步设计编译器)
1、现代编译器使用流水线式的结构,每个步骤只做一点点工作。分为前端和后端。
2、词法分析器(Scanner/Lexer),把源代码symbols转成tokens(为了和word区分,就是单词)。可以隐藏一些麻烦的东西,比如空格和注释,方便后续的语法分析。
语法分析器(Paser)检查并输出tokens是否是well-formed的,并将其翻译为IR(一种语法树,intermediate representation)。
下图的第一个箭头是词法分析,第二个是语法分析:
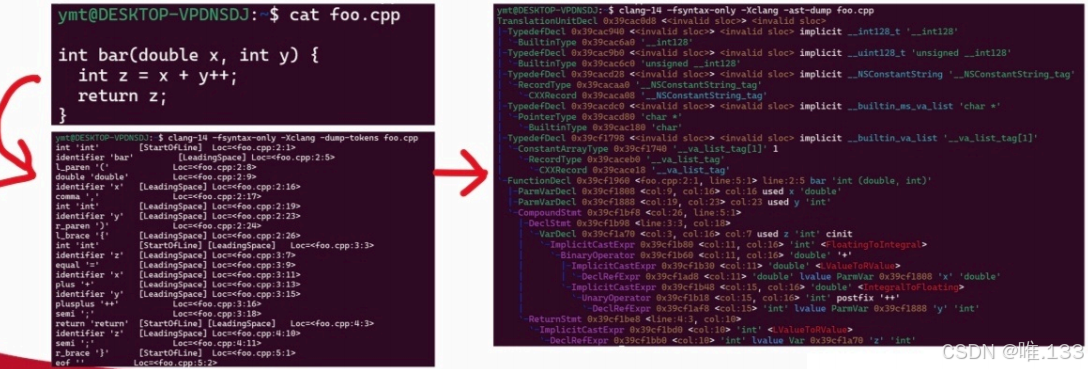
这里的语法树可以写成:

3、怎么生成词法分析器?通过正则表达式写语言的词法,据此转换为自动机,就可以自动生成词法分析器。C++推荐手写(很灵活但难写),OCaml则推荐用这个工具(更方便):
https://ocaml.org/manual/5.3/lexyacc.html
4、举一种词法分析自动机的变体,这里只识别两种单词,一个是标识符(a代表字母,0代表数字),一个是++和+。
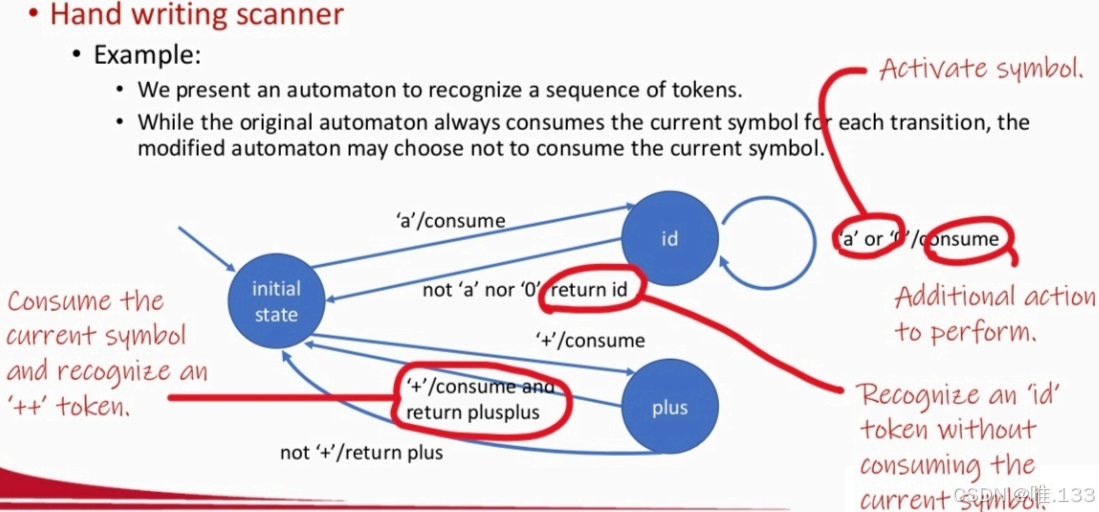
注意,这里有斜杠“/”,前面是接受符号(正则表达式),后面是动作(如consume是吃掉当前的符号)。
具体的代码(OCaml语言实现,效率很低,只适合理论学习)如下图:
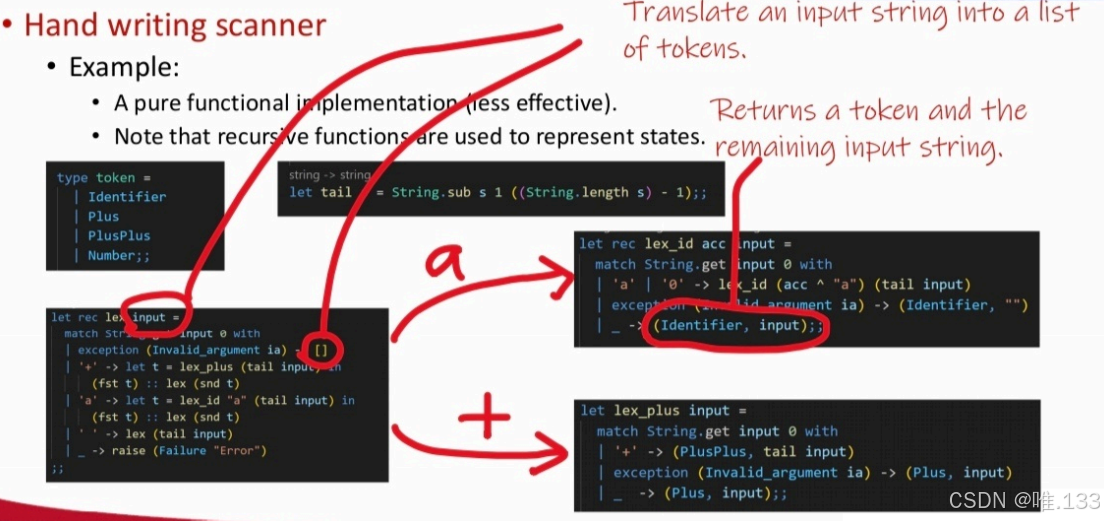
注意,这里的Identifier是标识符的意思,tail用于吃掉当前字符。String.get input 0只取左侧第一个符号(不存在的话,这个函数会抛出意外,故exception (Invalid_argument ia)对应[])。
此外,由于函数式不能修改变量,lex_plus函数返回一个pair,分别是单词和剩余的串,因此才有( fst t ):: lex ( snd t )。
5、那么怎么做一个语法分析器呢?回顾一下推自动机,是带栈的,但实际上不是tractable的,太难算了。我们需要找“正确”的路径,形一个成确定性的下推自动机。
6、递归下降分析器,原理如图:

这里A要匹配的如果是aβ,那么就去找A的产生式中哪个能产生出a开头的串。a就是look ahead symbol。

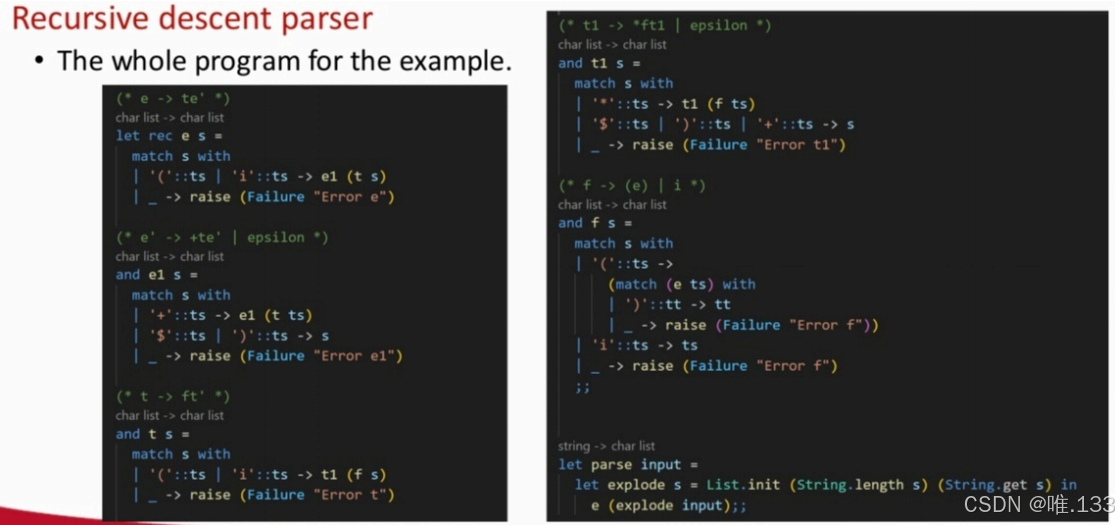
7、举例,这个文法和表达式文法等价:

这里explode将字符串转换为字符链表。

e1(t s)是先T匹配,然后剩下的再E'匹配。

and让函数可以互相递归调用。

完整示例如下图:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









