







本文是记录专业课“程序语言理论与编译技术”的部分笔记。
LECTURE 19(实现一个解释器)
一、Evaluation
1、Evaluation是继续简化抽象语法树(AST)的过程,直到它只是一个值(value)。换句话说,它是语言动态语义的实现。Evaluator使表达式一次采取一个step来简化自己,经过多个step后,表达式最终将成为一个值。我们称这种策略为small-step或single-step,因为我们每次只走一步。
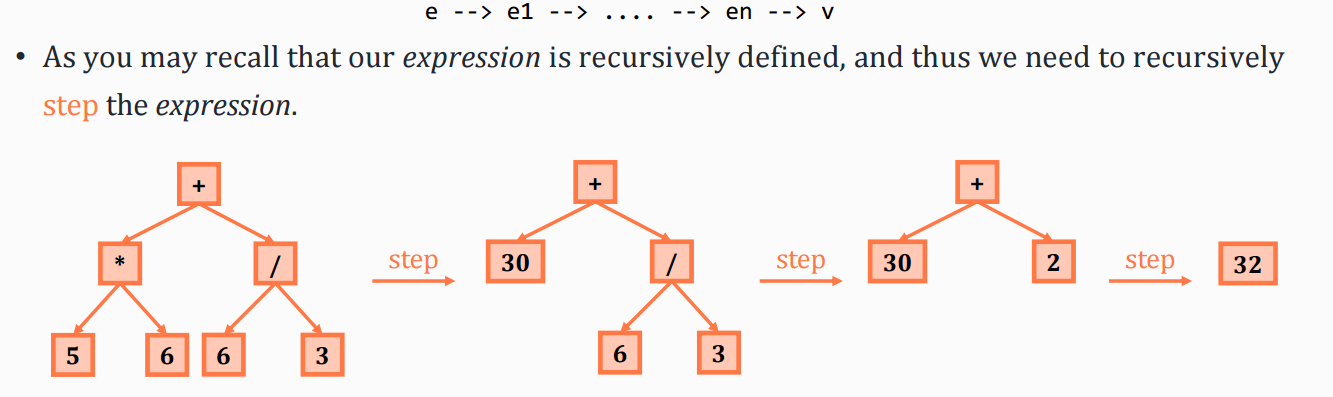
2、这是简单数学表达式的BNF语法:

我们据此建立以下步骤规则(--> 表示单步):
(1)常量:常量(在本例即整数)已经是值,因此我们不能再对它们进行step。
(2)二元运算符:二元运算符形如e1 bop e2 ,有两个子表达式e1和e2。由于e1和e2也可以是值,我们需要考虑三种不同的情况:
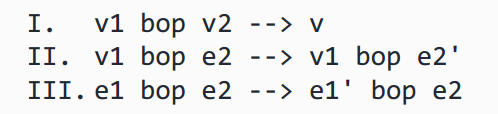
注意,我们建立这些规则是基于e1和e2是steppable的,这对于操作 + * / 是正确的。反之,如果不是这种情况,那么e1或e2应该是一个值,并被早期规则consume掉。这里的规则 I 代表原始操作处理,这与 II 和 III 略有不同,表明我们不仅需要语法,还需要语义来进行一些“计算”。
有趣的是,e1 bop v2 --> e1' bop v2 表示当我们对整个表达式进行step时,我们实际上是递归地对e1进行step。而我们不考虑得e1 bop v2 --> e1' bop v2,实际上包含在 III 中。
3、现在,让我们在自己的解释器中实现single-step。首先,我们需要一个函数来检查一个表达式是否已经是一个值,因为我们不能对值进行step。或者我们也可以说,这个函数是用于检查一个表达式是否是steppable的:

4、接下来,让我们实现small-step的规则。由于我们需要递归地对表达式进行步骤,我们需要一个递归函数。此外,鉴于规则 II 和 III 只需要语法,而规则 I 还需要语义。因此,我们需要一个特殊的step函数:


5、最后,我们需要用一个eval和一个interp函数将它们连接起来。
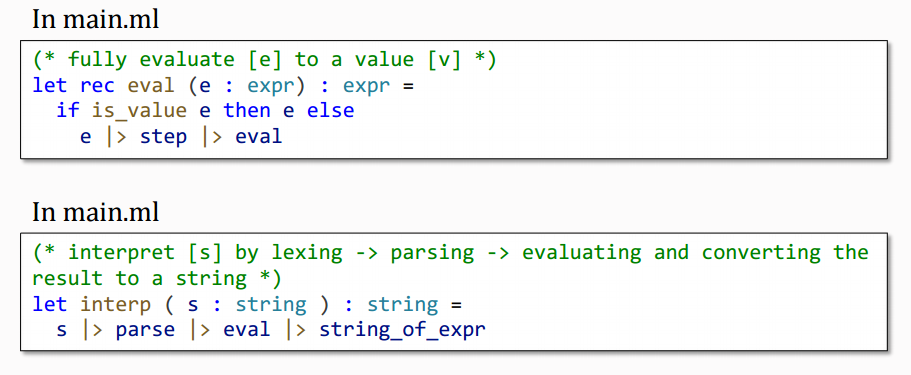
至此,我们已经完成了一个用于数学表达式的小解释器。不过这里,由于我们只有整数,所以到目前为止我们不需要类型检查和类型推断。
6、不过,你可能注意到我们一直只提及single-step或small-step,那么有没有big-step呢?有的兄弟,有的。让我们先给一个定义:

请注意,两种step都有其重要性:小步语义在建模复杂语言特性时往往更容易处理,而大步语义则更类似于解释器的实际实现方式。
7、现在,让我们为大步建立规则:
(1)常量:常量big-step到它们自己:i ==> i
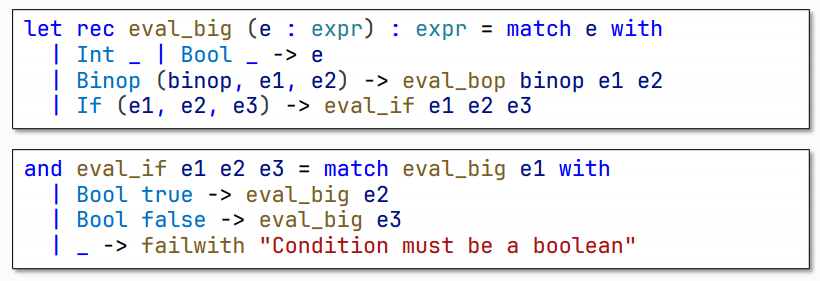
(2)二元运算符:二元运算符只big-step其两个子表达式,然后应用原始运算符:e1 bop e2 ==> v 如果 e1 ==> v1 和 e2 ==> v2 并且 v 是原始操作 v1 bop v2 的结果。
8、接下来,我们可以实现函数eval_big和eval_bop ,前者进行大步Evaluation,而后者进行与语义相关的Binop的big-step。当然,它们使用一个interp_big函数来相互连接:

二、SimPL Interpreter
1、作为一个例子,我们将使用一种非常简单的编程语言,即SimPL它的BNF语法如下图。你可以在https://github.com/AugustineYang/OCaml-Interpreter中找到SimPL Interpreter – Dev-Ready,这是一个可以用于学习补充的半成品代码。Interpreter是解释器的意思。

为了简单起见,我们只考虑SimPL支持以下三种结构:
(1)值:整数、布尔值和标识符(由英文字母组成)。
(2)二元运算符:+(加)、*(乘)和 <=(小于等于)。
(3)语句:let 语句和 if 语句。
在实践中,我们需要补充其代码,让其至少能识别、分析诸如 let x = 3110 in x + x和 if x <= 3 then true else false的语句。
2、你为 if 表达式设计的小步规则应该是这样的:

注意,规则 III 表明 e1 是steppable的。如果不是,那么它应该是 true 或 false,并且应该已经被规则 I 或规则 II consume掉。下图是应该在小步函数中添加的内容,你也可以在这里增加代码以进行类型检查:

你需要在函数 is_value 中添加一些检查,以便处理布尔值和 if 表达式:

此外,我们还需要在函数 step_binop 中为 “ <= ” 操作符添加一个step规则:

3、你为 if 表达式设计的大步规则应该是这样的:

下图是应该在大步函数中添加的内容。如果你愿意,也可以在这里进行类型检查。此外,也不要忘记布尔值和" <= "的处理:

到目前为止,我们的Evaluator已经能够解释没有变量的简单 if 表达式了,其完整代码可在之前给的github仓库中找到。但当我们来看 let 表达式,发现我们必须处理变量的问题。这,就涉及到了一个新的问题,替换(Substitution)。
三、Substitution
1、Substitution是用相应的值或计算形式替换变量或表达式的过程。这是处理变量绑定、函数应用或宏扩展的基本机制。我们需要引入一个新的符号 e' { e / x } ,意思是在表达式 e' 中用 e 来替换 x。直观上,在 x 出现在 e' 的任何地方,我们都应该用 e 来替换 x。例如:
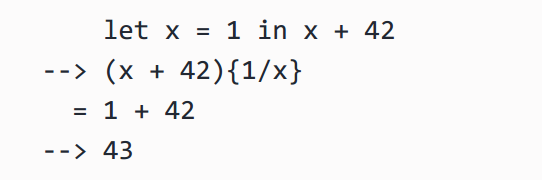
2、现在,我们可以为 let 表达式制定small-step规则:

请记住,如果规则 II 中的 e1 不是一个steppable的表达式,那么 let 表达式应该已经被规则 I consume掉。这就是我们可以安全地step e1 的原因。上述规则还说明了一个事实,x 作为一个变量,不是一个值,并且也是unsteppable的。如果我们试图step一个变量而不是对其进行替代,这意味着该变量是未绑定的(即,之前没有被适当的替代消耗),在这种情况下应该引发错误。就像这段简单的 OCaml 代码一样:

当然了,这实际上是一个类型检查错误。我们可以暂时不考虑错误类型,只在Evaluator尝试step一个变量时,这里引发错误。
此外,我们也可以为 let 表达式制定一些big-step规则:

3、现在我们已经通过 let 表达式在 SimPL 中引入了替换。让我们看看应该如何在 let x = v1 in e2 > e2 { v1 / x } 中处理 e2 { v1 / x } 。换言之,我们可以给出 SimPL 表达式的替换的仔细定义了:
(1)常量:整数和布尔值中没有出现变量,因此替换不会改变它们:
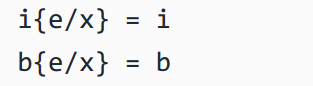
(2)变量:要么我们遇到相同的变量 x,这意味着我们应该进行替换,要么我们遇到其他不同名称的变量,比如 y,简单地,在这种情况下我们就不应该进行替换:
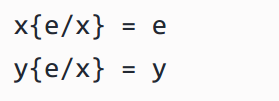
(3)二元运算符:我们应该在子表达式内部,递归地进行替换:

(4) if 表达式:我们应该像对待二元运算符一样在内部递归:

(5) let 表达式:对于这种情况,假设我们有两个更复杂的情况:

这里还有一些额外的例子,帮助你更好地理解在 let 表达式上的替换:

四、Lambda Calculus Interpreter
1、考虑一个语法如下图:

眼熟吗?这个语法正是 lambda 计算。它只有三种表达式:变量、函数应用和匿名函数,其中唯一的值是匿名函数。虽然这个语法甚至没有类型,但它可以表达任何可计算的函数。现在,让我们在我们的解释器中添加对 lambda 计算语法的支持。
2、有几种方法可以为 lambda 演算定义Evaluation语义。下图是一个与OCaml非常接近的规则:

记得吗?这是之前笔记中涵盖的按值调用(call-by-value)语义,它要求在应用函数之前将参数reduce为值。当然,我们也可以尝试定义按名调用(call-by-name)的语义,在按名调用语义中,e2 不必reduce到值。如果 e2 的值从未被需要,这可以带来很大的效率:

3、现在我们需要为 lambda 演算定义替换操作。我们可以做一个适用于按名称调用或按值调用的定义。受到 SimPL 替换的启发,制定这些规则应该没有太大困难。以下是我们定义的开始:

那么函数呢?在 SimPL 中,当我们遇到同名的有界变量时停止替换;否则,我们继续。在 lambda 演算中,或许我们也可以这样做:

4、不过,这真的正确吗?让我们考虑下图这两个表达式,它们都应该忽略参数并返回 x(即,分配给 x 的值):

我们可以看到,表达式 I 忽略参数并返回 z,它绑定到 x,结果是正确的。而表达式 II 变成了一个标识函数,该函数返回传来的值,而不是 x 的值,显然,结果出了点问题。
这里,我们需要重新考虑第二个例子。这一次,我们用不同的颜色给不同的 z 上色:

我们发现蓝色的 z 消失了,这正是错误的源头。实际上,这种 z 的消失被称为捕获。破损的替换捕获了 z,并使其与 z 成为同一个变量。它破坏了变量的作用域。这就是替换未能完成其工作的原因。因此,我们需要增强我们的替换以避免捕获的发生:



















 3271
3271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









