









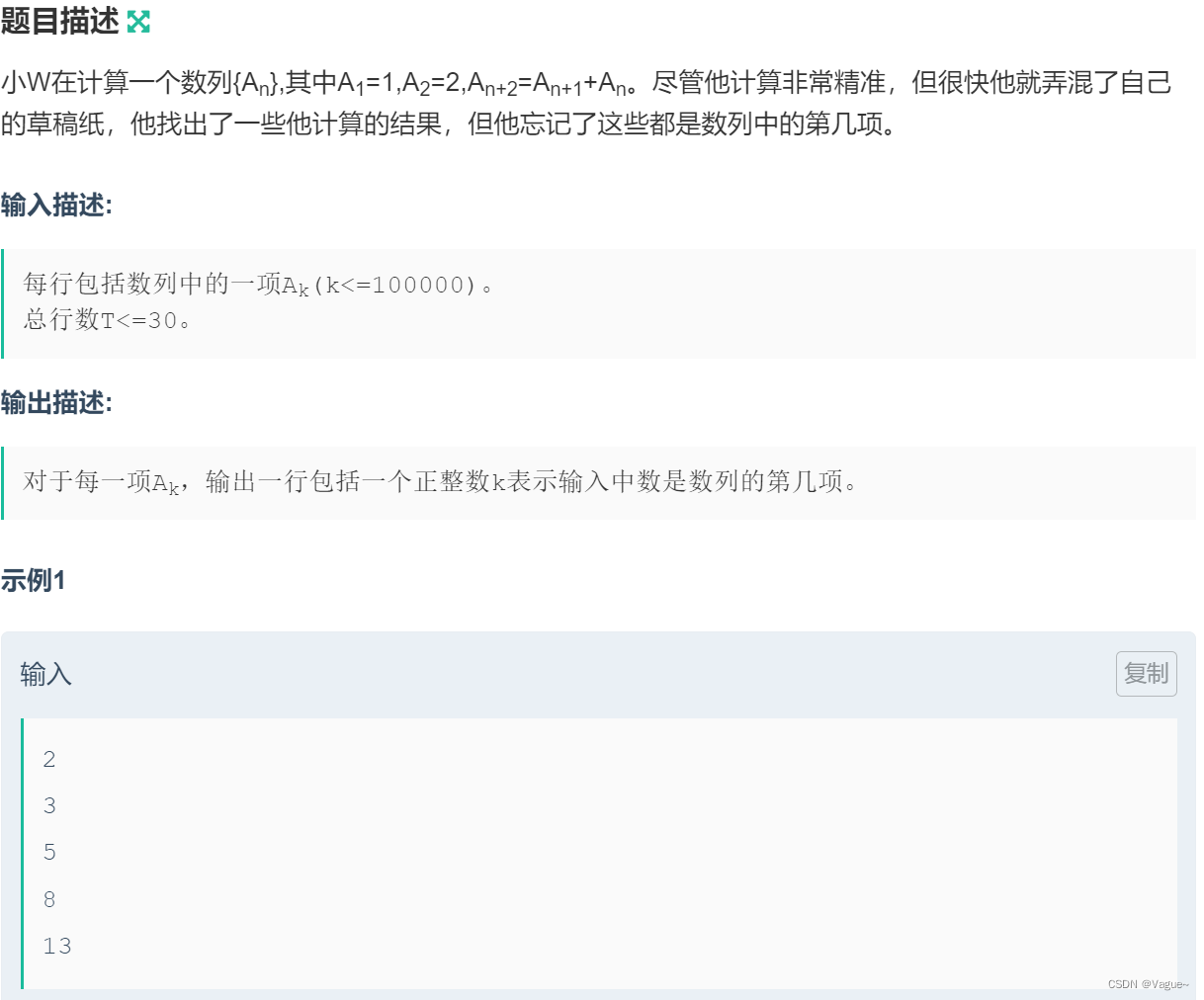
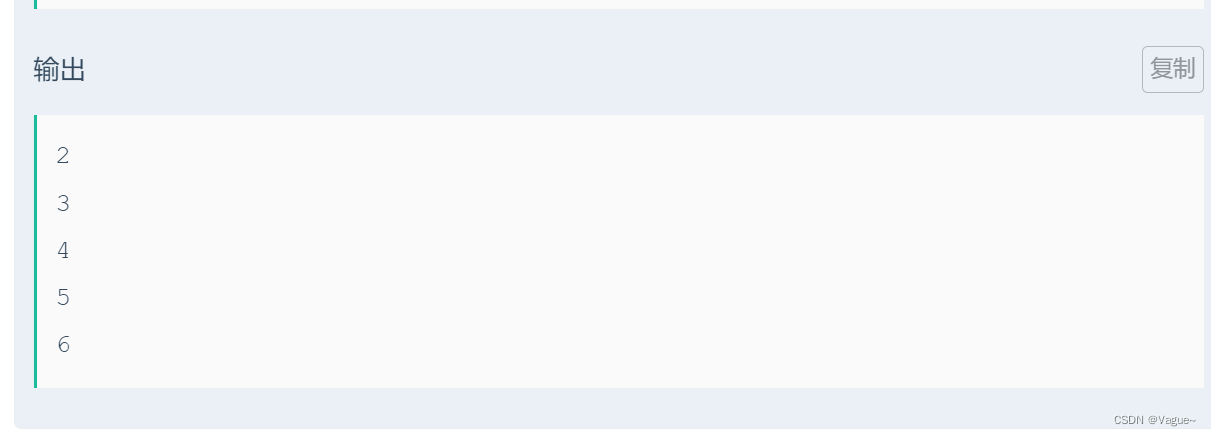
思想:利用unordered_map,其底层实现是哈希表,查询O(1),插入(logn);
#include<iostream>
#include<unordered_map>
using namespace std;
typedef long long ll;
const int N = 1e5 + 10;
const ll mod = 92540646808111039LL;//避免哈希碰撞
//由于可能超出 long long 的范围,所以需要对其取模。
ll a[N];
int main(){
a[1] = 1, a[2] = 2;
unordered_map<ll, int> q;
q[a[1]] = 1, q[a[2]] = 2;
for(int i = 3; i <= N; i++)
{
a[i] = (a[i - 1] + a[i - 2]) % mod;
q[a[i]] = i;
}
string n;//会爆long long
while(cin >> n)
{
ll num = 0;
for(int i = 0; i < n.size(); i++)
{
num = (num * 10 + n[i] - '0') % mod;
}
cout << q[num] << endl;
}
return 0;
}为什么选择92540646808111039?
以下是Claude3的回答:
在 C++ 中,整数字面量的类型由编译器根据其值的范围来决定,如果该值超出了int类型的范围,则默认为long int类型;如果连long int类型也无法容纳该值,则会被识别为long long int类型。
92540646808111039这个数字非常大,已经超出了long int类型的最大值,因此为了明确告诉编译器将其视为long long int类型,需要在数字后面添加LL后缀。如果不加LL后缀,编译器可能会将其解释为unsigned long int类型,导致不符合预期。
至于为什么选择92540646808111039这个质数作为取模的基数,有以下几个原因:
- 足够大的范围。该质数有19位,能够容纳绝大多数情况下斐波那契数列可能达到的范围。
- 减小取模损失。由于取模运算会损失部分精度,选择一个质数作为模数可以最大程度地减小这种损失。
- 避免整数溢出。在进行大数运算时,选择一个足够大的质数作为取模基数,可以避免整数溢出的发生。
需要注意的是,这种或整数溢出,只是在一定程度上降低了这取模的方式并不能完全避免精度损失种风险。对于一些极端情况,可能还需要采用更加精确的数学方法,如高精度计算或使用大数类型等。















 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









