






引言
在数据科学的世界里,数据可视化不仅仅是一种工具,它是一种艺术,一种将复杂数据转化为直观信息的能力。本文将分享我在学习数据可视化过程中的心得体会,包括理论学习、实践操作、以及如何将数据可视化应用到实际工作中。我的目标是让每一位读者都能从中获得启发,提升自己的数据可视化技能,达到95分的水平。
数据可视化的重要性
数据可视化是数据分析中的关键环节,它能够帮助我们快速识别数据中的模式、趋势和异常。一个好的数据可视化作品,不仅能够传递信息,还能够激发思考和讨论。
学习路径与资源
1. 理论学习
理论是实践的基石。我建议从以下资源开始学习:
- 书籍:《The Visual Display of Quantitative Information》by Edward Tufte 和 《Data Visualization: A Practical Introduction》by Kieran Healy。
- 在线课程:Coursera 和 edX 上的数据可视化课程,这些课程通常包含视频讲解和实战练习。
2. 实践操作
理论知识需要通过实践来巩固。以下是我在学习过程中使用的工具和实践方法:
- 工具学习:学习使用数据可视化工具,如 Tableau、Power BI、以及编程库如 Matplotlib、Seaborn 和 D3.js。
- 项目实践:通过 Kaggle 竞赛或个人项目实践数据可视化技能,将理论应用到实际问题中。
3. 社区交流
参与数据可视化社区,如 CSDN、GitHub 和 Stack Overflow,可以学习他人的经验,也可以分享自己的作品,获取反馈。
图表类型与应用场景
了解不同图表类型及其适用场景是数据可视化的关键。以下是一些常见图表及其使用场景:
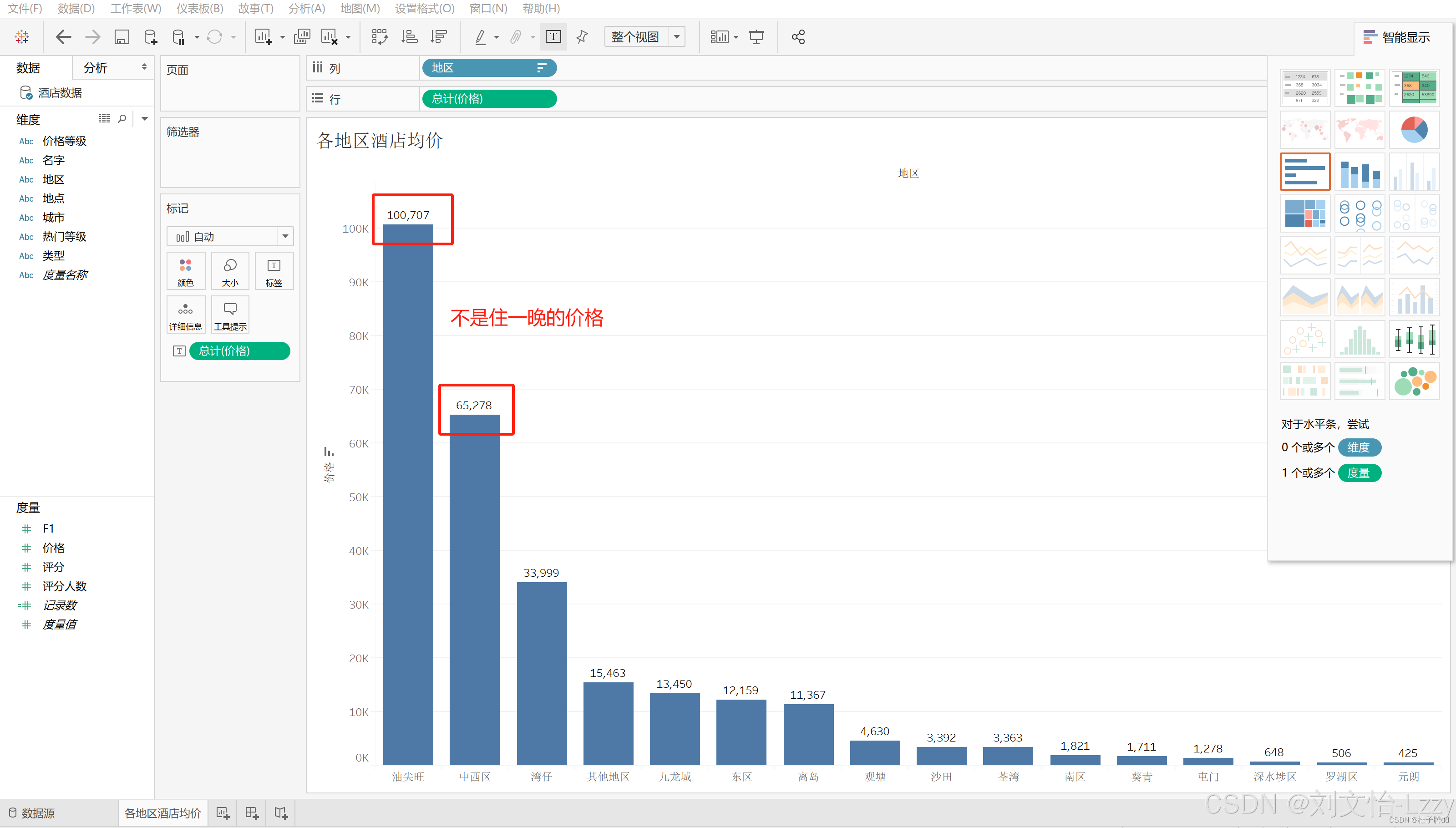
- 条形图:适用于比较不同类别的数据。
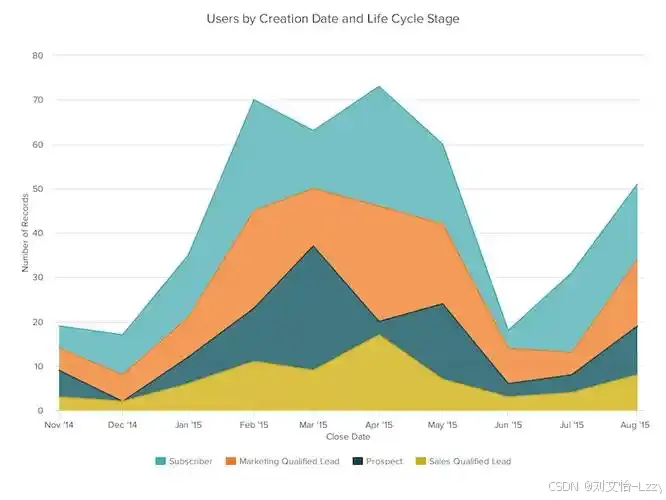
- 折线图:展示数据随时间变化的趋势。
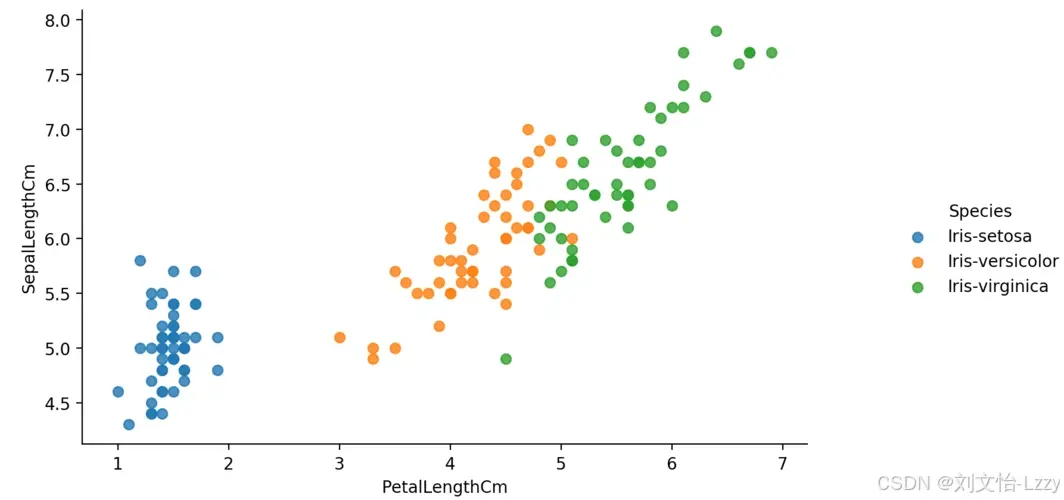
- 散点图:展示两个变量之间的关系。
- 饼图:展示各部分占整体的比例。
代码示例:折线图
import matplotlib.pyplot as plt
# 模拟一些数据
x = [1, 2, 3, 4, 5]
y = [2, 3, 5, 6, 5]
plt.plot(x, y, marker='o') # 折线图
plt.title('Line Chart Example')
plt.xlabel('X-axis')
plt.ylabel('Y-axis')
plt.grid(True)
plt.show()这段代码使用 Matplotlib 库创建了一个简单的折线图,展示了数据随 X 轴变化的趋势。
颜色与样式的应用
颜色和样式是数据可视化中的重要元素,它们可以帮助我们区分不同的数据系列,突出重点信息。在使用颜色时,我们需要注意以下几点:
- 颜色对比:确保颜色之间有足够的对比度,以便用户能够区分不同的数据系列。
- 色盲友好:选择对色盲用户友好的配色方案。
代码示例:使用颜色
import seaborn as sns
# 使用Seaborn库来创建一个带有颜色的散点图
sns.scatterplot(x=x, y=y, color='blue')
plt.title('Scatter Plot with Color')
plt.show()这段代码使用 Seaborn 库创建了一个散点图,并指定了颜色,使得图表更加直观。
交互式可视化
交互式可视化允许用户与图表进行交互,如放大、缩小、筛选等,这可以提供更深入的数据洞察。以下是一些创建交互式可视化的工具:
- Plotly:一个强大的 Python 库,支持创建交互式图表。
- Tableau:一个商业工具,提供丰富的交互式可视化功能。
代码示例:交互式散点图
import plotly.express as px
df = px.data.iris() # 使用Plotly内置的鸢尾花数据集
fig = px.scatter(df, x="sepal_width", y="sepal_length", color="species")
fig.show()这段代码使用 Plotly 创建了一个交互式散点图,用户可以悬停在数据点上查看详细信息。
数据的准确性与完整性
在进行数据可视化时,我们必须确保数据的准确性和完整性。错误的数据会导致错误的结论,而遗漏的数据可能会影响分析的全面性。
代码示例:数据清洗
import pandas as pd
# 假设我们有一组包含缺失值的数据
data = {'Product': ['A', 'B', 'C', 'D'],
'Sales': [200, None, 300, 500]}
df = pd.DataFrame(data)
df['Sales'] = df['Sales'].fillna(df['Sales'].mean()) # 用平均值填充缺失值
print(df)这段代码使用 Pandas 库来处理包含缺失值的数据,通过填充缺失值来确保数据的完整性。
结论
数据可视化是一门艺术,也是一门科学。它不仅仅是将数据转换成图表,更是通过视觉元素来传达信息和故事。通过选择合适的图表类型、合理使用颜色和样式、创建交互式图表以及讲述数据故事,我们可以更有效地与他人沟通和分享数据洞察。同时,我们也需要关注数据的准确性和完整性,确保我们的可视化是可靠和有价值的。
通过学习和实践数据可视化,我深刻地认识到了它在数据分析中的重要性。它不仅提高了我的工作效率,也增强了我的数据解读能力。我将继续探索更多的数据可视化技术和工具,以更好地理解和传达数据的价值。

希望这篇博文能够帮助你在数据可视化的学习之路上更进一步。如果你有任何问题或想要进一步讨论,欢迎在评论区交流。让我们一起在数据可视化的世界里探索和成长!
这篇博文通过深入探讨数据可视化的理论基础、实践操作、以及实际应用,旨在帮助读者全面提升数据可视化技能。如果你觉得这篇博文对你有帮助,欢迎点赞和分享。让我们一起在数据可视化的道路上不断进步!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









