









 该博客通过可视化分析了2011-2021年的电影数据,包括各年份总票房的趋势、电影比例、平均票价、片长分布、导演喜爱度、地区分布、发行公司排名、片长与评分的关系、特征相关性以及制片制式和电影类型的偏好。数据预处理步骤包括缺失值处理、单位转换和重复项去除。
该博客通过可视化分析了2011-2021年的电影数据,包括各年份总票房的趋势、电影比例、平均票价、片长分布、导演喜爱度、地区分布、发行公司排名、片长与评分的关系、特征相关性以及制片制式和电影类型的偏好。数据预处理步骤包括缺失值处理、单位转换和重复项去除。
数据介绍
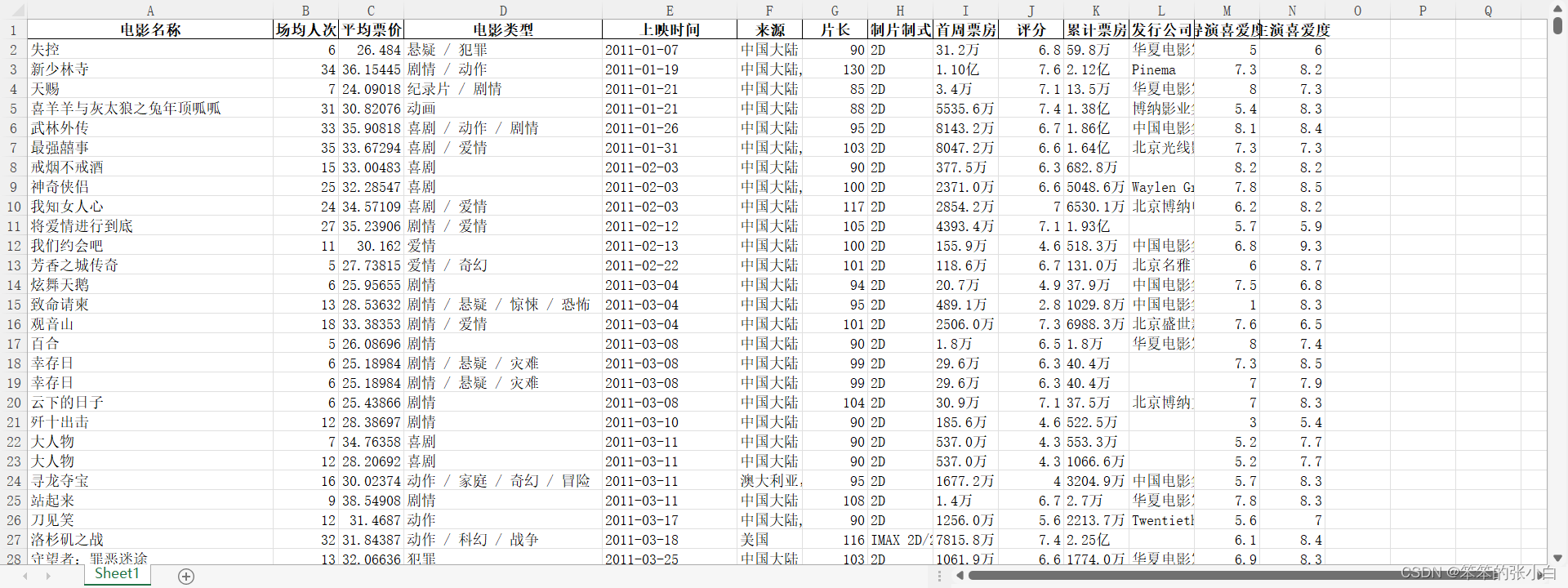
数据为2011-2021电影数据
可视化分析
首先导入本次项目需要的包和数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType
sns.set_style('ticks')
import warnings
warnings.filterwarnings('ignore') # 忽略警告
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
data = pd.read_excel('data.xlsx')
data.head()
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 6929
6929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











