







 超级会员免费看
超级会员免费看
1.Triplet Attention增强
在计算机视觉领域,注意力机制已经成为提升模型性能的关键技术。
本文将深入解析一个结合了Triplet Attention机制的Vision Transformer(ViT)实现,展示如何通过多维度注意力增强标准ViT模型的性能。
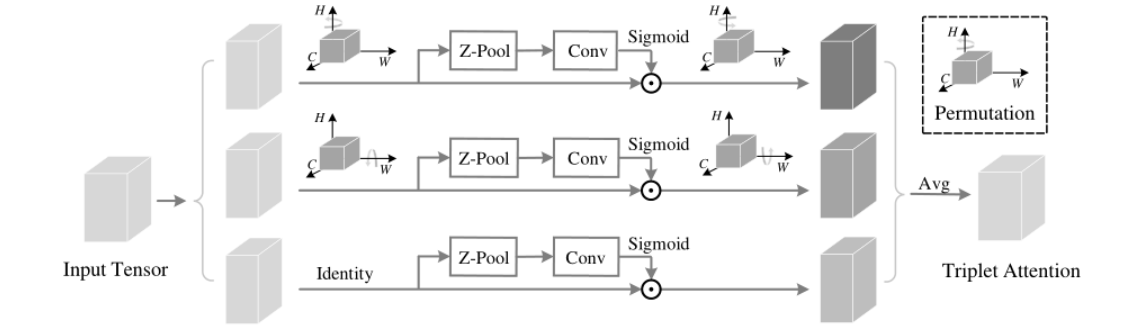
1. 代码概述
这段代码实现了一个改进版的Vision Transformer模型,主要包含两个核心部分:
- TripletAttention模块:一个创新的注意力机制,同时考虑通道、高度和宽度三个维度的注意力
- 改进的ViT模型:在标准ViT的卷积投影层后添加TripletAttention模块
2. TripletAttention模块详解
TripletAttention是一种多维度注意力机制,它同时关注输入特征图的三个关键维度:通道、高度和宽度。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











