






今天给大家分享一个超强的算法模型,Transformer
Transformer 模型是深度学习中一种「基于注意力机制」的模型,广泛应用于自然语言处理(NLP)任务,如机器翻译、文本生成和问答系统。
它由 Vaswani 等人在 2017 年的论文《Attention Is All You Need》中提出,突破了传统序列模型(如RNN和LSTM)的限制,特别是在长距离依赖问题上表现出色。它是 ChatGPT 和所有其他 LLM 的支柱。
https://arxiv.org/pdf/1706.03762
模型架构
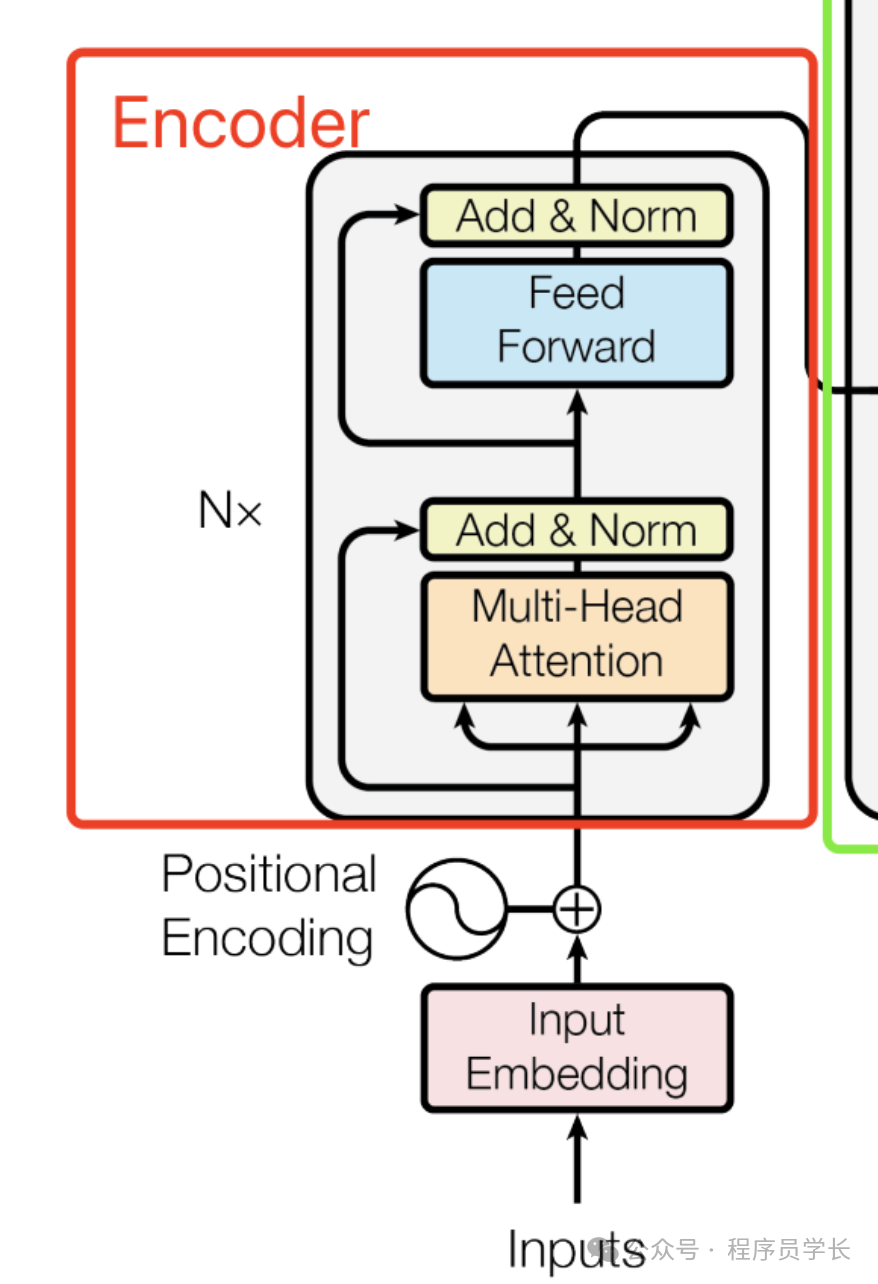
Transformer 模型由编码器(Encoder)和解码器(Decoder)组成。编码器和解码器各由 N 层相同的子层堆叠而成。
以下是编码器和解码器的详细结构。
编码器(Encoder)
每层编码器包含两个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
前馈神经网络(Feed-Forward Neural Network)
解码器(Decoder)
每层解码器包含三个子层:
-
多头自注意力机制(Multi-Head Self-Attention)
-
编码器-解码器注意力机制(Encoder-Decoder Attention)
-
前馈神经网络(Feed-Forward Neural Network)
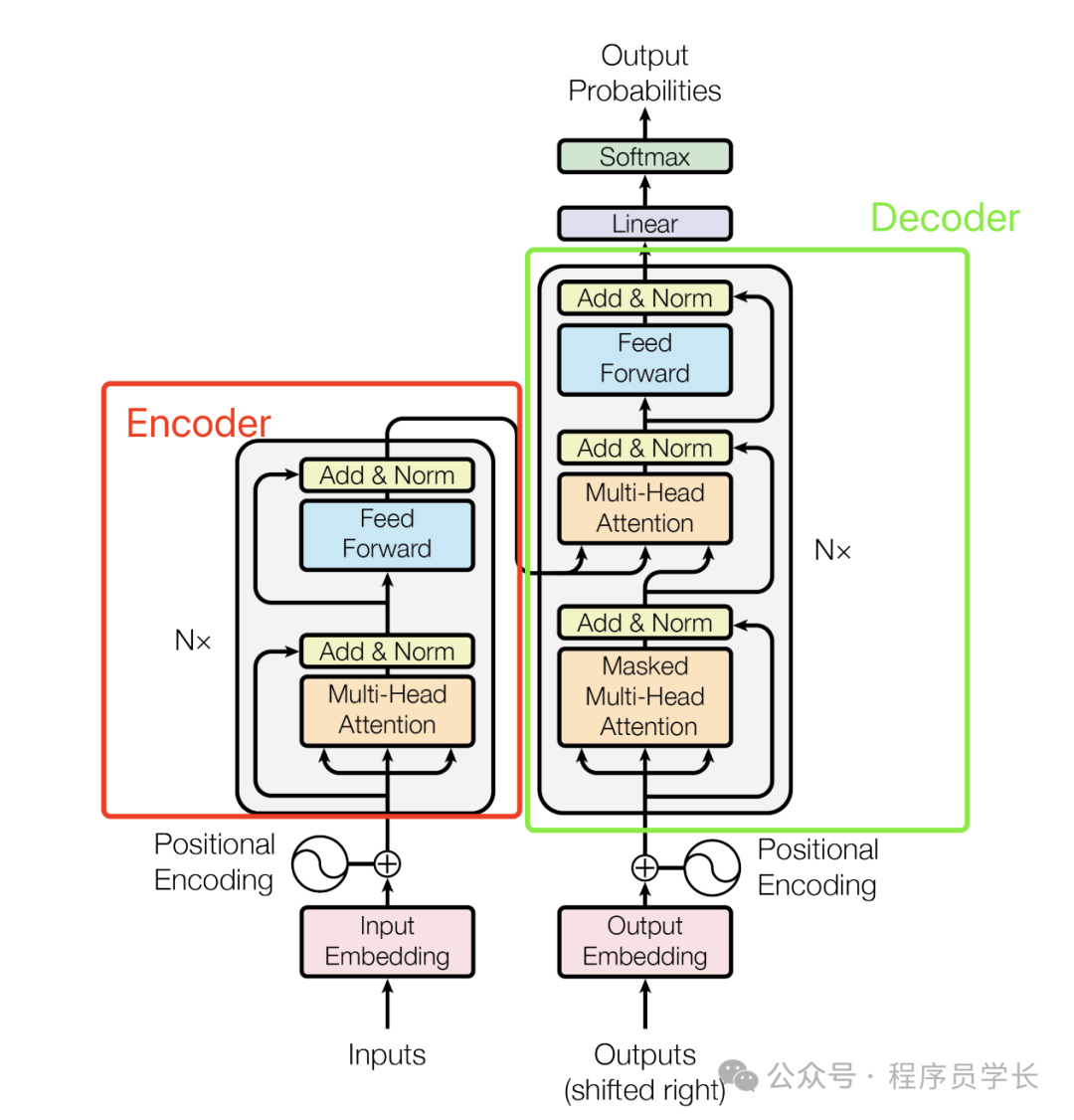
Transformer 核心组件
下面,让我们来看看 Transformer 如何将输入文本序列转换为向量表示,又如何逐层处理这些向量表示得到最终的输出。
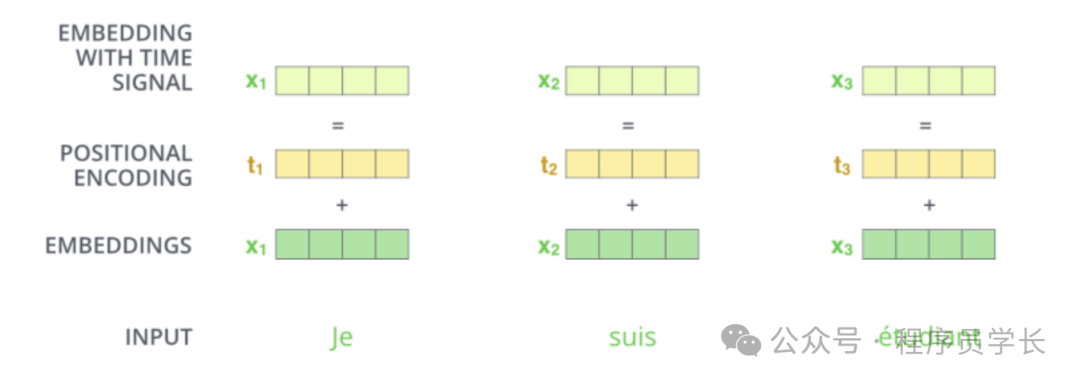
1.输入编码
和常见的 NLP 任务一样,我们首先会使用词嵌入算法(word embedding),将输入文本序列的每个词转换为一个词向量。实际应用中的向量一般是 256 或者 512 维。但为了简化起见,我们这里使用 4 维的词向量来进行讲解。
如下图所示,假设我们的输入文本是序列包含了 3 个词,那么每个词可以通过词嵌入算法得到一个 4 维向量,于是整个输入被转化成为一个向量序列。

2.位置编码
由于 Transformer 模型依赖于自注意力机制,而自注意力机制本质上是无序的,即它不区分输入序列中各个词的位置顺序,因此需要显式地引入位置信息来帮助模型理解序列的顺序关系。
位置编码的具体实现方式有多种,Transformer 模型中采用了一种基于正弦和余弦函数的方式。
对于输入序列中的每个位置 pos 和每个维度 i,位置编码向量的计算公式如下。
其中:
-
pos 表示序列中词语的位置。
-
i 表示位置编码向量的维度索引。
-
是词嵌入向量的维度。
在模型中,位置编码向量会与输入嵌入向量相加,将位置信息显式地引入到输入数据中。
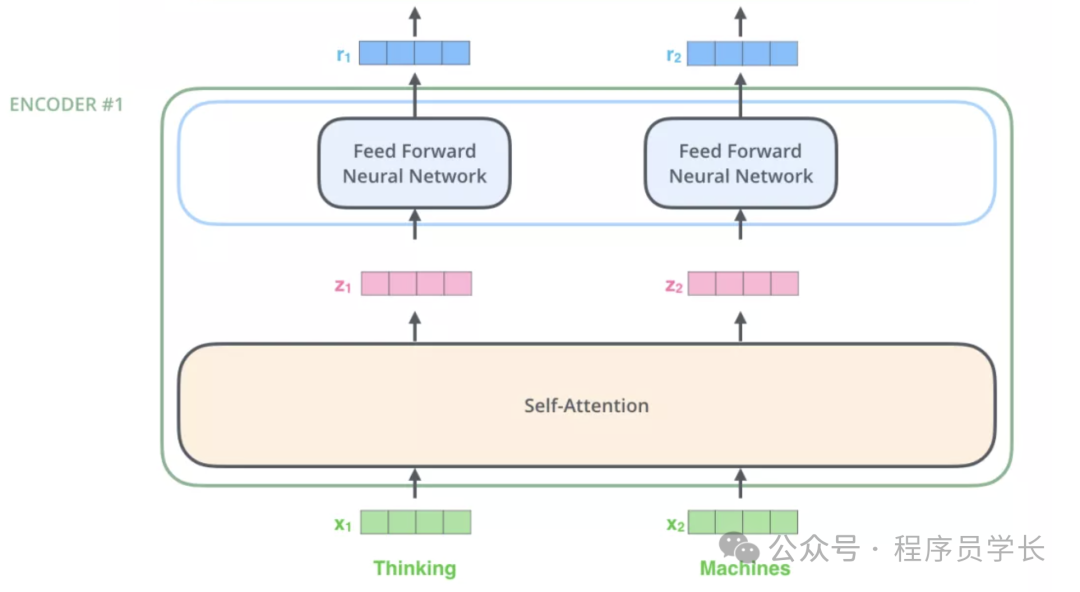
3. 编码器 encoder
输入文本序列经过输入处理之后得到了一个向量序列,这个向量序列将被送入第1层编码器,第1层编码器输出的同样是一个向量序列,再接着送入下一层编码器:第1层编码器的输入是融合位置向量的词向量,更上层编码器的输入则是上一层编码器的输出。
下图展示了向量序列在单层 encoder 中的流动,融合位置信息的词向量进入self-attention 层,self-attention 输出每个位置的向量再输入 FFN 神经网络得到每个位置的新向量。
Self-Attention
注意力机制是神经网络中一个非常吸引人的概念,尤其是在 NLP 等任务中。它就像给模型打了一盏聚光灯,让它专注于输入序列的某些部分,而忽略其他部分,就像我们人类在理解句子时会注意特定的单词或短语一样。
现在,让我们深入研究一种特殊的注意力机制,称为 Self-Attention (自注意力)。想象一下,你正在阅读一个句子,你的大脑会自动突出显示重要的单词或短语以理解其含义。这本质上就是自注意力在神经网络中的作用。「它使序列中的每个单词能够 “注意” 其他单词(包括它自己),以更好地理解上下文。」
Self-Attention 的工作原理
-
计算 Query、Key 和 Value 向量
给定输入序列 X,通过三个不同的线性变换得到 Query(查询向量) 、Key(键向量) 和Value(值向量)。
其中,是可训练的权重矩阵。
-
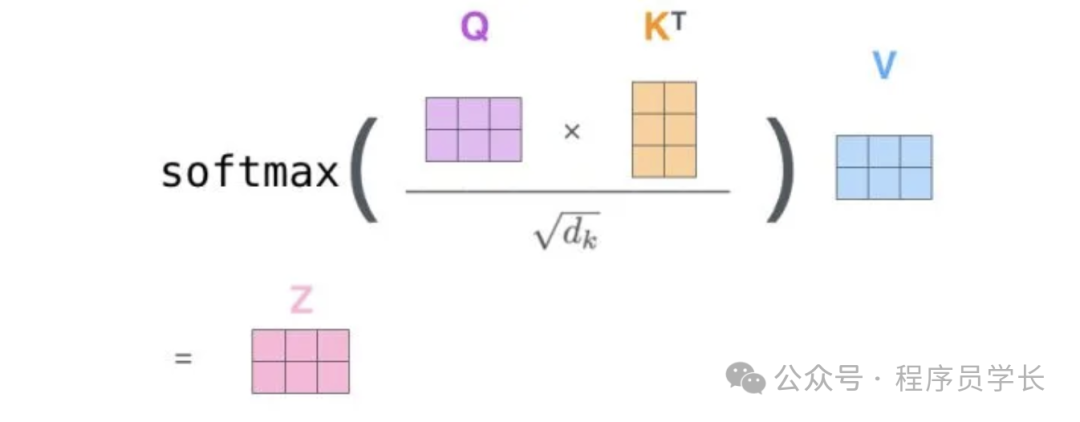
计算注意力得分
通过点积计算 Query 和 Key 之间的相似度,再通过缩放(scaling)以稳定梯度。
其中, 是 Key 向量的维度。
下面,我们通过一个具体的案例进行说明。假设,我们需要对词组 Thinking Machines 进行翻译,其中 Thinking 对应的 embedding 向量用 x1 表示,Machines 对应的 embedding 向量用 x2 表示。
当我们处理 Thinking 这个词时,我们需要计算句子中所有词与它的 Attention Score。首先将当前词作为搜索的 query,去和句子中所有词(包含该词本身)的 key 去匹配,看看相关度有多高。我们用 q1代表 Thinking 对应的 query 向量,k1 及 k2 分别代表 Thinking 以及Machines 对映的 key 向量,则计算 Thinking 的 attention score 的时候我们需要计算 q1 与 k1、k2 的点乘,同理,我们计算 Machines的 attention score 的时候需要计算 q2 与 k1、k2 的点乘。
如下图中所示我们分别得到了q1与 k1、k2 的点乘积,然后我们进行尺度缩放与softmax归一化。
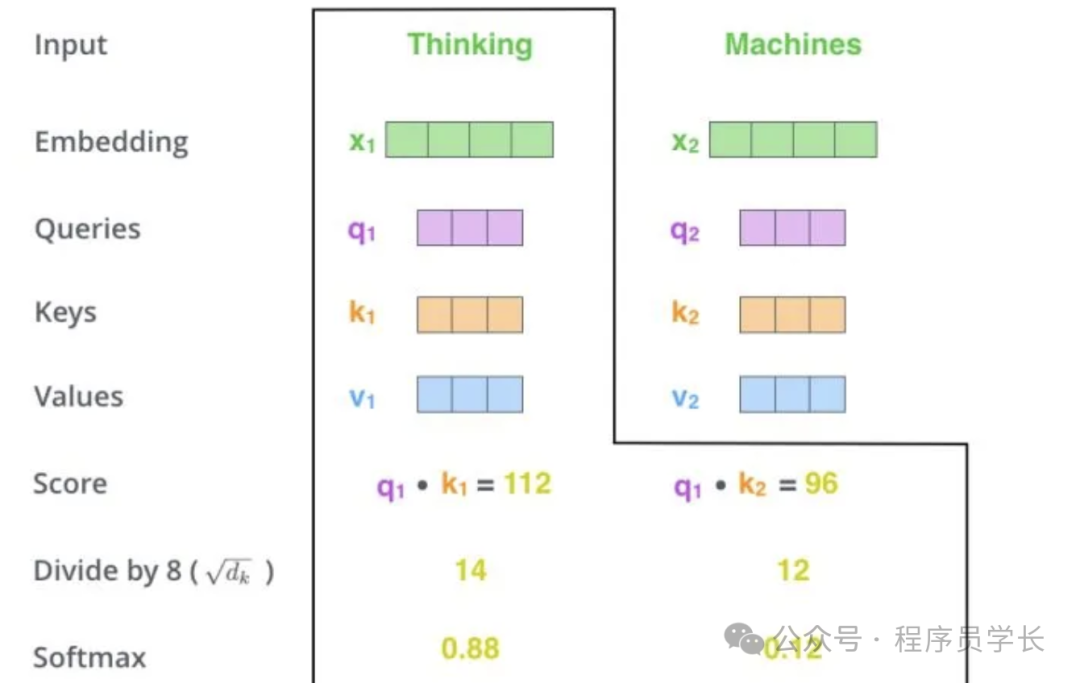
显然,当前单词与自身的注意力得分一般最大,其他单词根据当前单词重要程度有相应的分数。随后我们用这些注意力得分与 Value 向量相乘,得到加权的向量。
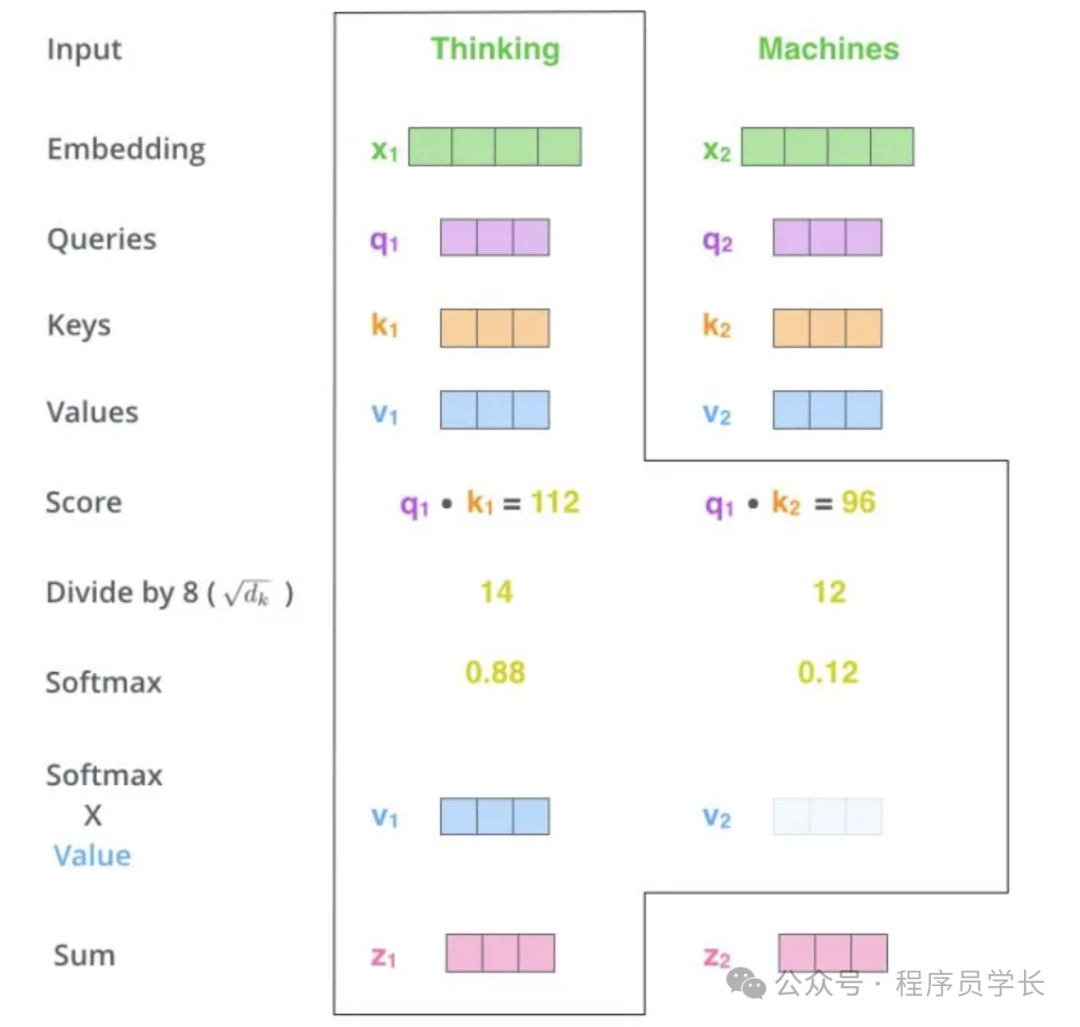
上图中 z1 表示对第一个位置词向量(Thinking)计算 Self Attention 的全过程。最终得到的当前位置(这里的例子是第一个位置)词向量会继续输入到前馈神经网络。
在实际的代码实现中,Self Attention 的计算过程是使用矩阵快速计算的,一次就得到所有位置的输出向量。
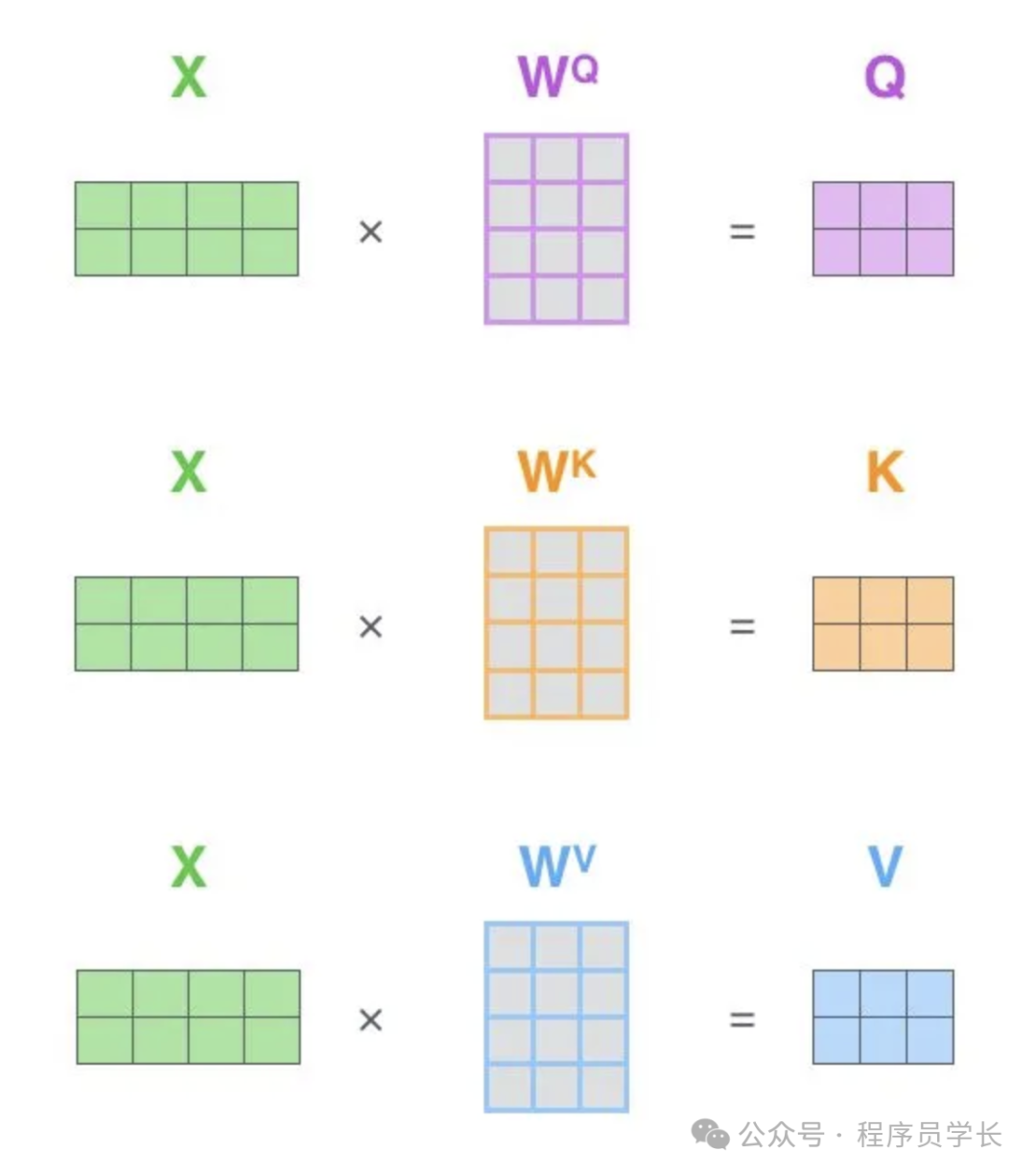
其中
是我们模型训练过程中学习到的合适的参数。
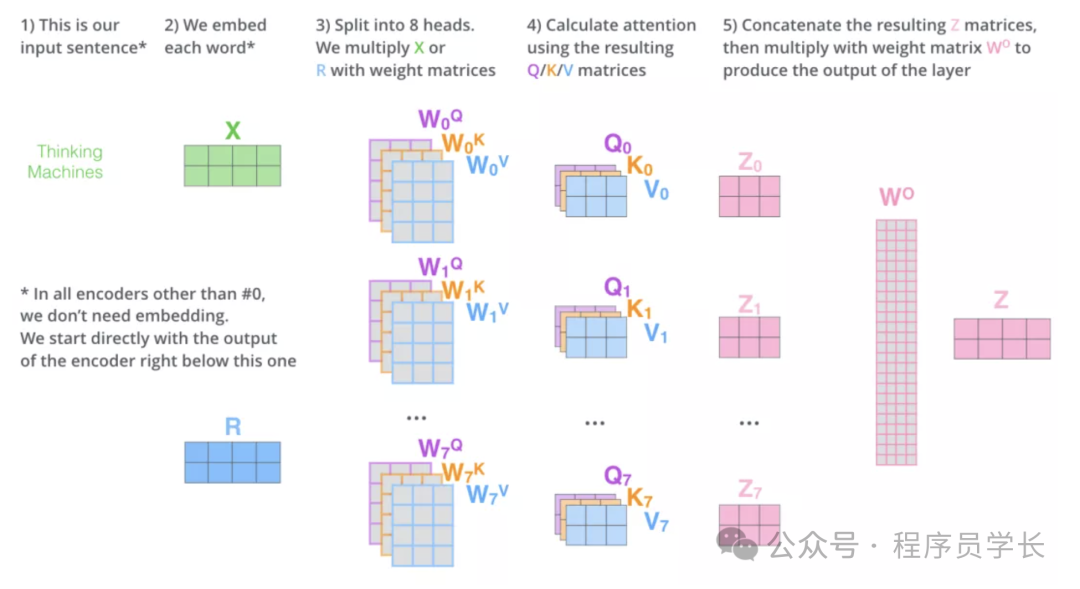
而多头注意力(Multi-Head Attention)就是我们可以有不同的 Q,K,V 表示,之后再将其结果合并起来,如下图所示。
残差连接和层标准化
经过 Multi-head Attention 后会进入 Add & Norm 层,这一层是指残差连接和层标准化。
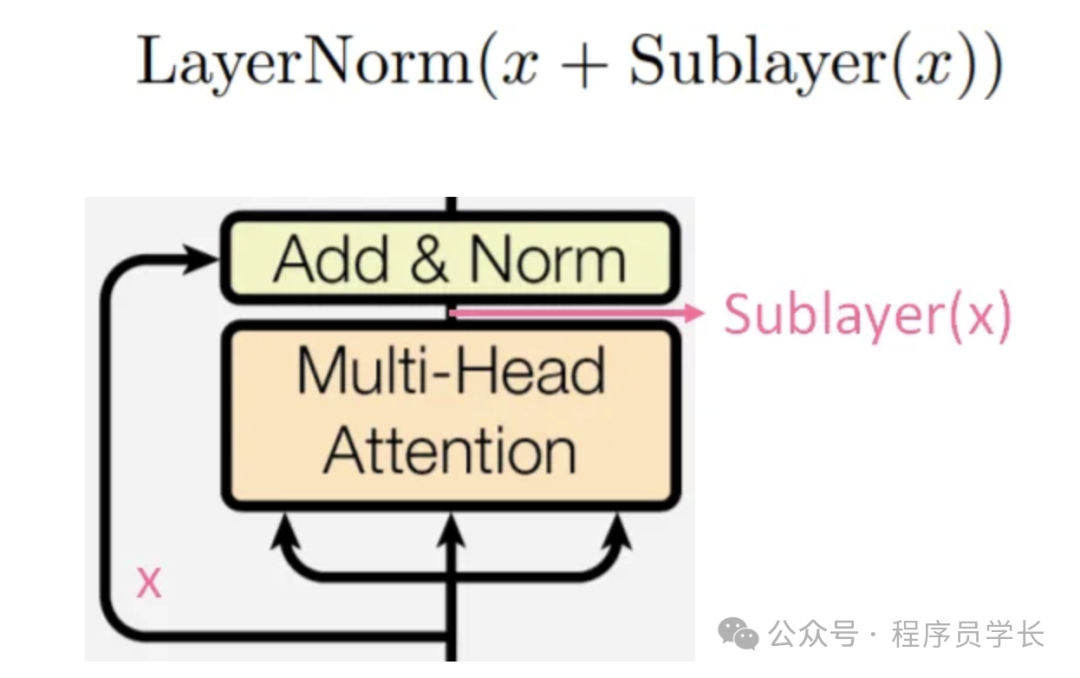
前一层的输出 会与原输入 x 相加(残差连接),以减缓梯度消失的问题,然后再做层标准化。
其中,Sublayer(x) 表示 Multi-head Attention 的输出。
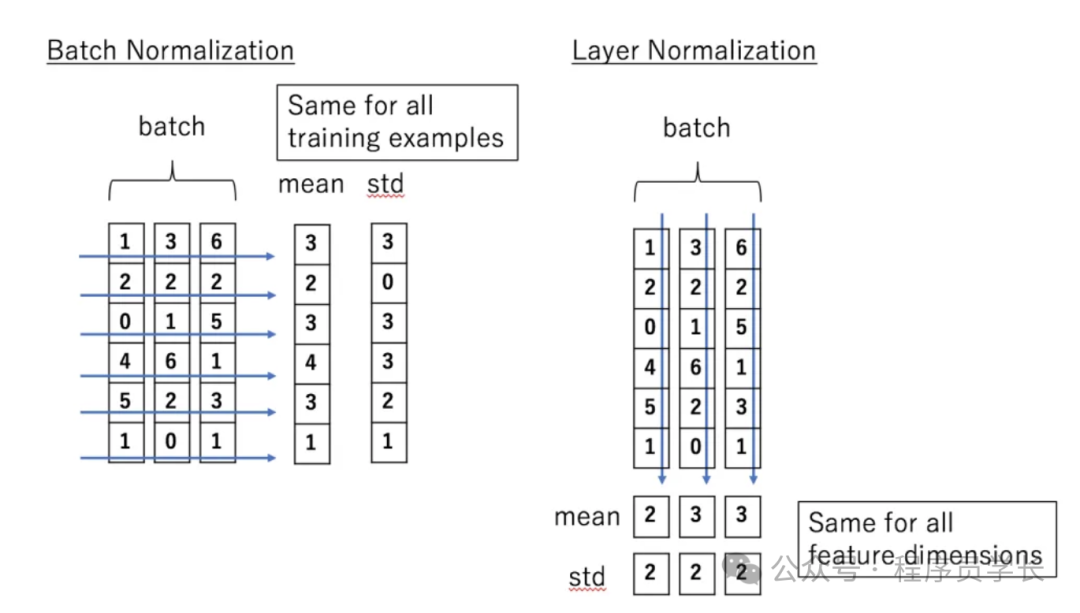
下面,我们来看一下什么是层标准化,和批量标准化有什么区别。
批量标准化是对一个批次中的所有样本进行标准化处理,它是对一个批次中的所有样本的每一个特征进行归一化。而层标准化是对每个样本的所有特征进行标准化处理,独立于同一批次中的其他样本。
层标准化的优点是不受批量大小的影响,可以在小批量甚至单个样本上工作。更适合序列数据。
前馈网络 (FFN)
接着进入到 FFN 层,由下列公式可以看到输入x 先做线性运算后,然后送入 ReLU,之后再做一次线性运算。
在 FFN 后面,也会接一个 Add & Norm 层,这里就不再赘述。
到目前位置,我们已经把 Transformer 中的 Encoder 部分聊完了。对于 Decoder 部分,我们下期再见。















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









