






在 MySQL 数据库的世界里,数据类型是构建高效、可靠数据库的基石。选择合适的数据类型,不仅能节省存储空间,还能提升数据查询和处理的性能
目录
一、MySQL 数据类型总览
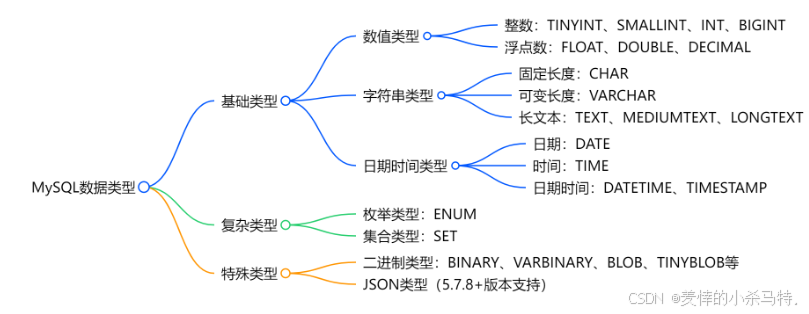
MySQL 的数据类型主要分为数值类型、字符串类型、日期时间类型等。合理使用这些数据类型,能优化数据库性能,确保数据的准确存储和高效检索。
二、数值类型
整数类型
TINYINT:小整数类型,有符号范围 -128 到 127,无符号范围 0 到 255,占用 1 字节。常用于存储如年龄分段(如 0 - 1,代表儿童)等数据。
SMALLINT:中等大小整数,有符号范围 -32768 到 32767,无符号范围 0 到 65535,占用 2 字节。可用于存储商品库存数量。
INT(INTEGER):标准整数类型,有符号范围 -2147483648 到 2147483647,无符号范围 0 到 4294967295,占用 4 字节。常用来存储用户 ID 等数据。BIGINT:大整数类型,用于存储超大整数,占用 8 字节。比如银行交易流水号就适合用它存储。
-- 创建用户表,包含不同整数类型字段
CREATE TABLE users (
user_id INT AUTO_INCREMENT PRIMARY KEY, -- 用户 ID 用 INT 类型
age TINYINT, -- 年龄用 TINYINT 类型
points SMALLINT -- 积分用 SMALLINT 类型
);
-- 插入数据
INSERT INTO users (age, points) VALUES (25, 100);
浮点数类型
FLOAT:单精度浮点数,精确到大约 7 位小数,占用 4 字节。可用于存储如商品价格(如 9.99)等对精度要求不是极高的数据。
DOUBLE:双精度浮点数,精确到大约 15 位小数,占用 8 字节。适用于科学计算中需要高精度数值的场景。
DECIMAL:高精度小数,常用于财务计算,可自定义精度和标度。例如存储货币金额(如 100.00)。
-- 创建商品表,价格字段用 DECIMAL 类型
CREATE TABLE products (
product_id INT AUTO_INCREMENT PRIMARY KEY,
product_name VARCHAR(100),
price DECIMAL(10, 2) -- 总共有 10 位数字,小数部分占 2 位
);
-- 插入数据
INSERT INTO products (product_name, price) VALUES ('笔记本电脑', 5999.99);
三、字符串类型
固定长度字符串
CHAR:固定长度字符串,不足长度自动填充空格,最大 255 字节。比如存储身份证号(固定 18 位)就很合适。
-- 创建地址表,邮政编码用 CHAR 类型
CREATE TABLE addresses (
address_id INT AUTO_INCREMENT PRIMARY KEY,
postal_code CHAR(6) -- 邮政编码固定 6 位
);
-- 插入数据
INSERT INTO addresses (postal_code) VALUES ('100000');
可变长度字符串
VARCHAR:可变长度字符串,根据实际内容长度占用空间,最大 65535 字节。常用于存储用户昵称等长度不固定的数据。
-- 创建用户账号表,用户名和密码字段用 VARCHAR 类型
CREATE TABLE user_accounts (
username VARCHAR(20),
password VARCHAR(60)
);
-- 插入数据
INSERT INTO user_accounts (username, password) VALUES ('john_doe','secure_password123');
长文本类型
TEXT:用于存储大量文本数据,最大 65535 字节。比如博客文章内容就可以用它存储。
MEDIUMTEXT:中等长度文本,最大长度 16777215 字节。
LONGTEXT:长文本,最大长度 4294967295 字节。
-- 创建博客文章表,文章内容用 TEXT 类型
CREATE TABLE blog_posts (
post_id INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(200),
content TEXT
);
-- 插入数据
INSERT INTO blog_posts (title, content) VALUES ('MySQL 数据类型详解', '在 MySQL 中,数据类型是...');
四、日期时间类型
DATE:仅存储日期,格式为 YYYY-MM-DD,占用 3 字节。常用于存储用户生日(如 2000-01-01)、订单日期等。
-- 创建员工表,入职日期用 DATE 类型
CREATE TABLE employees (
employee_id INT AUTO_INCREMENT PRIMARY KEY,
employee_name VARCHAR(100),
hire_date DATE
);
-- 插入数据
INSERT INTO employees (employee_name, hire_date) VALUES ('Alice', '2022-03-15');
TIME:仅存储时间,格式为 HH:MM:SS,占用 3 字节。比如存储课程开始时间(如 09:00:00)。
DATETIME:存储日期和时间,格式为 YYYY-MM-DD HH:MM:SS,占用 8 字节。可用于记录订单创建时间等。
-- 创建订单表,订单创建时间用 DATETIME 类型
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
order_time DATETIME
);
-- 插入数据,记录订单创建时间
INSERT INTO orders (order_time) VALUES ('2023-10-05 14:30:00');
TIMESTAMP:存储日期和时间,范围从 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC,占用 4 字节。会自动更新,适合记录数据最后更新时间。
-- 创建商品评论表,评论时间用 TIMESTAMP 类型
CREATE TABLE product_reviews (
review_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT,
review_text TEXT,
review_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
-- 插入数据
INSERT INTO product_reviews (product_id, review_text) VALUES (1, '这款商品非常好用!');
五、其他数据类型
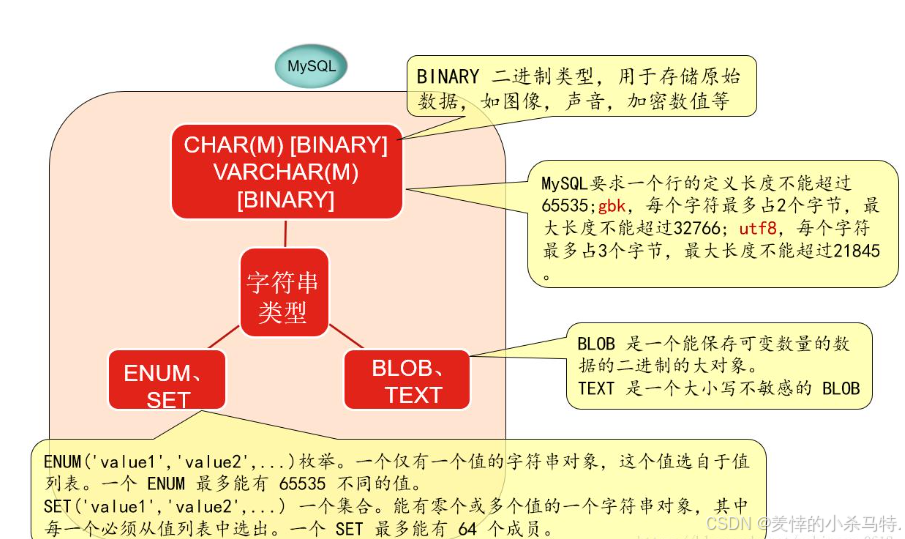
枚举类型(ENUM)用于定义一个预定义的字符串值列表,用户只能从列表中选择一个值。
比如订单状态(待付款、已付款、已发货、已完成、已取消)就适合用 ENUM 类型。
-- 创建订单表,订单状态用 ENUM 类型
CREATE TABLE orders (
order_id INT AUTO_INCREMENT PRIMARY KEY,
order_status ENUM('待付款', '已付款', '已发货', '已完成', '已取消')
);
-- 插入数据
INSERT INTO orders (order_status) VALUES ('待付款');
集合类型(SET)允许从预定义列表中选择多个值。
例如存储用户兴趣爱好(阅读、运动、音乐、绘画等)。
-- 创建用户信息扩展表,兴趣爱好用 SET 类型
CREATE TABLE user_profiles (
user_id INT PRIMARY KEY,
hobbies SET('阅读', '运动', '音乐', '绘画')
);
-- 插入数据,用户有多个兴趣爱好
INSERT INTO user_profiles (user_id, hobbies) VALUES (1, '阅读,音乐,绘画');
二进制类型(BINARY、VARBINARY、BLOB)
BINARY:固定长度二进制字符串,与 CHAR 类似,不足长度自动填充。
VARBINARY:可变长度二进制字符串,与 VARCHAR 类似。
BLOB:二进制大对象,用于存储二进制数据,如图像、文件等。
-- 创建用户头像表,头像数据用 BLOB 类型
CREATE TABLE user_avatars (
user_id INT PRIMARY KEY,
avatar BLOB
);
-- 插入数据(此处仅为示例,实际需处理二进制数据)
INSERT INTO user_avatars (user_id, avatar) VALUES (1, 0x[二进制数据]);
六 、类型汇总
| 数据类型分类 | 具体数据类型 | 描述 | 占用空间 | 适用场景 | 示例 | 注意事项 |
|---|---|---|---|---|---|---|
| 数值类型 | TINYINT | 小整数类型,有符号范围 -128 到 127,无符号范围 0 到 255 | 1 字节 | 存储较小范围的整数,如年龄分段、状态标识(0 表示禁用,1 表示启用)等 | 存储用户年龄(假设年龄范围较小) | 超出范围会导致数据截断或错误 |
| SMALLINT | 中等大小整数,有符号范围 -32768 到 32767,无符号范围 0 到 65535 | 2 字节 | 存储如商品库存数量、评分(范围适中)等数据 | 记录商品库存 | 同样要注意数据范围,否则可能丢失数据 | |
| INT(INTEGER) | 标准整数类型,有符号范围 -2147483648 到 2147483647,无符号范围 0 到 4294967295 | 4 字节 | 存储用户 ID、订单号等常见的整数数据 | 存储用户的唯一标识 ID | 对于可能超出范围的数据,需选择更大的数据类型 | |
| BIGINT | 大整数类型,用于存储超大整数 | 8 字节 | 存储银行交易流水号、区块链高度等需要表示较大数值的数据 | 记录银行账户的交易流水号 | 占用空间较大,按需使用 | |
| FLOAT | 单精度浮点数,精确到大约 7 位小数 | 4 字节 | 存储对精度要求不是极高的数值,如商品价格(如 9.99) | 记录商品的大致价格 | 存在精度误差,不适合财务计算等对精度要求高的场景 | |
| DOUBLE | 双精度浮点数,精确到大约 15 位小数 | 8 字节 | 存储科学计算中的高精度数值 | 科学实验数据存储 | 相比 FLOAT 精度更高,但占用空间也更大 | |
| DECIMAL | 高精度小数,常用于财务计算,可自定义精度和标度 | 自定义(取决于精度) | 存储货币金额、财务报表中的数值等对精度要求高的数据 | 存储商品的精确价格、银行账户余额 | 合理设置精度和标度,否则可能浪费空间或导致精度不足 | |
| 字符串类型 | CHAR | 固定长度字符串,不足长度自动填充空格 | 0 - 255 字节(取决于定义长度) | 存储固定长度的字符串,如身份证号(固定 18 位)、邮政编码等 | 存储用户的身份证号码 | 若实际数据长度远小于定义长度,会浪费空间 |
| VARCHAR | 可变长度字符串,节省存储空间 | 0 - 65535 字节(取决于实际内容) | 存储用户昵称、地址等长度不固定的字符串 | 存储用户输入的地址信息 | 注意设置合适的最大长度,超出长度会导致数据截断 | |
| TEXT | 长文本类型,用于存储大量文本数据 | 0 - 65535 字节 | 存储文章内容、评论内容等较长的文本 | 存储博客文章的正文 | 对长文本的查询和处理性能相对较低 | |
| MEDIUMTEXT | 中等长度文本,最大长度 16777215 字节 | - | 存储较长的小说章节、产品详细描述等 | 存储小说的一个章节内容 | ||
| LONGTEXT | 长文本,最大长度 4294967295 字节 | - | 存储大型文档、电子书全文等超大文本数据 | 存储一本电子书的内容 | ||
| 日期时间类型 | DATE | 仅存储日期,格式为 YYYY-MM-DD | 3 字节 | 存储用户生日、订单日期、活动日期等只需要日期的数据 | 记录用户的生日日期 | 不包含时间信息 |
| TIME | 仅存储时间,格式为 HH:MM:SS | 3 字节 | 存储课程开始时间、活动开始时间等只需要时间的数据 | 记录课程的开始时间 | 不包含日期信息 | |
| DATETIME | 存储日期和时间,格式为 YYYY-MM-DD HH:MM:SS | 8 字节 | 记录订单创建时间、数据更新时间等需要同时存储日期和时间的数据 | 记录订单的创建日期和时间 | 范围有限,适用于 1970 年到 2038 年之间的时间 | |
| TIMESTAMP | 存储日期和时间,范围从 1970-01-01 00:00:01 UTC 到 2038-01-19 03:14:07 UTC | 4 字节 | 记录数据的最后更新时间,自动更新时间戳 | 记录数据的修改时间,自动更新 | 受时区影响,使用时需注意时区设置 | |
| 其他类型 | ENUM | 枚举类型,定义一个预定义的字符串值列表,用户只能从列表中选择一个值 | 1 - 2 字节 | 存储固定选项的数据,如订单状态(待付款、已付款、已发货、已取消)、性别(男、女)等 | 记录订单的状态 | 只能选择预定义列表中的一个值 |
| SET | 集合类型,允许从预定义列表中选择多个值 | 1 - 8 字节(取决于选项数量) | 存储用户兴趣爱好(阅读、运动、音乐等)、商品标签等可以多选的数据 | 存储用户选择的多个兴趣爱好 | 可以选择预定义列表中的多个值 | |
| BINARY | 固定长度二进制字符串 | 自定义(取决于定义长度) | 存储二进制数据,如加密后的用户密码、二进制文件的部分内容等 | 存储加密后的用户登录密码 | 长度固定,不足会填充 | |
| VARBINARY | 可变长度二进制字符串 | 自定义(取决于实际内容长度) | 存储动态的二进制数据,如图片的二进制表示(部分场景) | 存储图片的二进制数据(简单示例) | 长度可变,根据实际数据长度占用空间 | |
| BLOB | 二进制大对象,用于存储二进制数据,如图像、文件等 | 自定义(取决于数据大小) | 存储较大的二进制文件,如图像文件、文档文件等 | 存储一张图片的完整二进制内容 | 适合存储较大的二进制数据,但查询和处理相对复杂 | |
| JSON | 用于存储和处理 JSON 格式的数据,支持嵌套结构和灵活查询 | 自定义(取决于数据内容) | 存储非结构化数据,如用户的个性化设置、产品的详细配置信息等 | 存储用户的个性化设置(如字体大小、主题颜色等 JSON 格式数据) | MySQL 5.7 及以上版本支持,提供丰富的 JSON 函数进行操作 |
七、选择数据类型的注意事项
节省存储空间:根据数据实际范围,选择合适的类型,避免过度占用空间。例如能用 TINYINT 存储的数据,就不要用 BIGINT。
保证数据准确性:对于财务计算等对精度要求高的场景,使用 DECIMAL 类型,防止浮点数误差。
提升性能:合理选择数据类型可加快查询和处理速度。比如整数类型的运算比字符串类型更快。
注意长度限制:使用字符串类型时,要考虑其长度限制,避免数据截断。
时区问题:使用 TIMESTAMP 等日期时间类型时,注意时区设置,确保时间的准确性。
八、MySQL 数据类型的实际应用场景与综合案例
电商平台数据库设计中的数据类型应用
在电商平台开发中,合理选择数据类型能大幅提升系统性能与稳定性。以创建商品表、订单表和用户表为例:
商品价格 使用 DECIMAL 类型确保金额精确,避免因浮点数误差导致财务问题。
订单状态 使用 ENUM 类型限定取值范围,使数据更规范,同时节省存储空间。
手机号 使用 CHAR(11) 固定长度,保证格式统一,提升查询效率。
社交平台数据类型优化实践
以微博类社交平台为例,需要存储用户动态、评论、点赞等数据。以下是核心表结构设计:
-- 创建用户动态表
CREATE TABLE posts (
post_id BIGINT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
content TEXT, -- 动态内容,支持长文本
post_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
like_count INT DEFAULT 0, -- 点赞数,INT类型
comment_count INT DEFAULT 0, -- 评论数,INT类型
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 创建评论表
CREATE TABLE comments (
comment_id BIGINT AUTO_INCREMENT PRIMARY KEY,
post_id BIGINT NOT NULL,
user_id INT NOT NULL,
comment_text VARCHAR(500), -- 评论内容,中等长度可变字符串
comment_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id),
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
-- 创建点赞表(使用SET类型记录用户点赞记录)
CREATE TABLE likes (
like_id BIGINT AUTO_INCREMENT PRIMARY KEY,
post_id BIGINT NOT NULL,
user_ids SET('user1', 'user2', 'user3'...), -- 假设预定义1000个用户ID,实际可扩展
like_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
FOREIGN KEY (post_id) REFERENCES posts(post_id)
);
动态内容 使用 TEXT 类型支持用户发布长文。
点赞表 中的 user_ids 使用 SET 类型,可高效存储多个用户的点赞记录,适用于快速判断某个用户是否点赞。
数据类型在数据分析场景中的应用
在大数据分析场景下,经常需要处理时间序列数据和统计计算。以销售数据分析为例:
-- 创建销售记录表
CREATE TABLE sales (
sale_id INT AUTO_INCREMENT PRIMARY KEY,
product_id INT NOT NULL,
sale_date DATE NOT NULL, -- 销售日期,仅存储日期
sale_amount DECIMAL(10, 2) NOT NULL,
sale_quantity INT NOT NULL,
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
-- 查询某个月的销售总额(使用日期函数)
SELECT SUM(sale_amount)
FROM sales
WHERE YEAR(sale_date) = 2024 AND MONTH(sale_date) = 10;
-- 查询每日销售数量趋势
SELECT sale_date, SUM(sale_quantity)
FROM sales
GROUP BY sale_date
ORDER BY sale_date;
销售日期 使用 DATE 类型,减少不必要的时间存储开销。
通过 SUM 等聚合函数结合日期函数,对数值类型数据进行快速统计分析。
九、MySQL 8.0 新特性中的数据类型增强
MySQL 8.0 版本引入了多项数据类型相关的优化与新特性:
JSON 数据类型的性能提升
MySQL 8.0 对 JSON 数据类型进行了底层优化,支持更高效的索引创建:
-- 创建包含JSON字段的表
CREATE TABLE products_ext (
product_id INT PRIMARY KEY,
details JSON
);
-- 为JSON字段的某个属性创建索引
CREATE INDEX idx_product_features ON products_ext ((details->>'$.features'));
-- 查询包含特定特性的产品
SELECT *
FROM products_ext
WHERE JSON_CONTAINS(details->'$.features', '"5G"');
通过索引,对 JSON 数据的查询效率显著提升,特别是在处理大量非结构化数据时。
增强的二进制数据类型支持
新增 BINARY(255) 和 VARBINARY(65535) 支持,允许存储更大长度的二进制数据。例如,在存储文件哈希值时:
CREATE TABLE files (
file_id INT AUTO_INCREMENT PRIMARY KEY,
file_hash VARBINARY(64), -- 假设哈希值最长64字节
file_content LONGBLOB -- 文件内容
);
数值类型的默认值优化
MySQL 8.0 支持在数值类型上使用表达式作为默认值:
CREATE TABLE counters (
count_id INT AUTO_INCREMENT PRIMARY KEY,
value INT DEFAULT (0), -- 可使用表达式设置默认值
increment INT DEFAULT (1)
);
这一特性使表结构设计更加灵活,减少应用层代码的默认值处理逻辑。
十、MySQL 数据类型迁移与兼容性问题
从 MySQL 5.7 迁移到 8.0 的数据类型注意事项
JSON 类型兼容性:5.7 版本的 JSON 功能有限,升级后需检查原有的 JSON 操作语句是否适配 8.0 的新特性。
时间类型变化:8.0 对 TIMESTAMP 的时区处理更严格,迁移时需确保时间数据的准确性。例如,检查旧系统中的时间数据是否存在时区混乱问题,并通过以下语句修正:
-- 批量更新TIMESTAMP字段的时区
UPDATE your_table
SET your_timestamp_column = CONVERT_TZ(your_timestamp_column, '+00:00', '+08:00');
字符集升级:建议将字符集从 UTF8 升级到 UTF8MB4 以支持 Emoji 等特殊字符,但需注意数据长度可能变化,提前评估表结构。
跨数据库迁移的数据类型映射
当从其他数据库(如 Oracle、SQL Server)迁移到 MySQL 时,常见的数据类型映射如下:
| 原数据库类型 | MySQL 对应类型 | 注意事项 |
|---|---|---|
| Oracle NUMBER(p,s) | DECIMAL(p,s) | 精度需手动确认,避免数据丢失 |
| SQL Server DATETIME | DATETIME 或 TIMESTAMP | TIMESTAMP 范围有限,需注意数据范围 |
| Oracle VARCHAR2 | VARCHAR | 长度限制不同,需调整最大长度设置 |
迁移时建议先在测试环境进行小批量数据迁移,验证数据类型转换后的准确性与完整性。
十一、开发者工具与数据类型实践辅助
Navicat 中的数据类型可视化
Navicat 作为常用的数据库管理工具,提供了直观的数据类型设置界面:
创建表时:在图形化界面中选择数据类型,并可直接设置长度、默认值等属性(如 VARCHAR(50)、INT AUTO_INCREMENT)。
数据导入:导入 CSV 等文件时,Navicat 会自动根据数据内容推荐合适的数据类型,开发者可手动调整确保准确。
Python 与 MySQL 的数据类型交互
使用 pymysql 库操作 MySQL 时,需注意数据类型的转换:
import pymysql
# 连接数据库
conn = pymysql.connect(
host='localhost',
user='root',
password='password',
database='test_db'
)
# 插入数据
with conn.cursor() as cursor:
sql = "INSERT INTO users (username, age) VALUES (%s, %s)"
cursor.execute(sql, ("John", 30))
conn.commit()
# 查询数据
with conn.cursor() as cursor:
sql = "SELECT * FROM users"
cursor.execute(sql)
results = cursor.fetchall()
for row in results:
print(row)
conn.close()
在 Python 代码中,需确保传递的数据类型与 MySQL 表结构匹配,例如将 Python 的 int 类型对应 MySQL 的 INT ,str 对应 VARCHAR 等。
十二、数据类型与索引优化的协同策略
数据类型对索引效率的影响
在 MySQL 中,索引的性能与数据类型的选择密切相关。以常见的用户表为例:
-- 创建用户表并添加索引
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100),
INDEX idx_username (username), -- 为用户名添加索引
UNIQUE INDEX idx_email (email) -- 为邮箱添加唯一索引
);
优化要点:
整数类型索引:INT 类型的 user_id 作为主键,索引效率极高,因为整数比较比字符串快得多。
字符串类型索引:VARCHAR 类型的 username 和 email 建立索引时,应尽量控制字段长度,避免过长的字符串索引影响性能。例如,可通过前缀索引优化:
-- 为email字段的前20个字符创建前缀索引
CREATE INDEX idx_email_prefix ON users (email(20));
复合索引中的数据类型匹配
在创建复合索引时,数据类型的顺序和选择会影响索引的使用效率。例如:
-- 创建包含多个字段的复合索引
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
order_date DATE,
status ENUM('待付款', '已付款', '已发货'),
INDEX idx_user_date_status (user_id, order_date, status)
);
使用建议:
高频查询字段优先:将最常作为查询条件的字段放在前面(如 user_id)。
数据类型一致性:确保查询条件中的数据类型与索引字段完全一致,避免隐式类型转换导致索引失效。例如:
-- 正确:数据类型匹配
SELECT * FROM orders WHERE user_id = 123 AND order_date = '2024-01-01';
-- 错误:可能导致索引失效(假设order_date为DATE类型)
SELECT * FROM orders WHERE order_date = 20240101; -- 数值与DATE类型不匹配
覆盖索引与数据类型选择
合理选择数据类型可有效利用覆盖索引提升查询效率。例如:
-- 创建覆盖索引示例
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(100),
price DECIMAL(10, 2),
category_id INT,
INDEX idx_category_price (category_id, price) -- 复合覆盖索引
);
-- 查询可直接通过索引返回结果,无需回表
SELECT category_id, price FROM products WHERE category_id = 5;
注意事项:
覆盖索引的字段应尽量选择占用空间小的数据类型(如 INT 比 BIGINT 更优)。
避免在覆盖索引中包含 TEXT、BLOB 等大字段,因为这些字段会显著增加索引体积。
十三、高级数据类型应用技巧
自定义数据类型(通过 ENUM 和 SET)
利用 ENUM 和 SET 可实现业务领域的自定义数据类型。例如:
-- 定义用户角色的ENUM类型
CREATE TABLE users (
user_id INT PRIMARY KEY,
role ENUM('admin', 'editor', 'user', 'guest') DEFAULT 'user'
);
-- 定义用户兴趣的SET类型
CREATE TABLE user_profiles (
user_id INT PRIMARY KEY,
interests SET('reading', 'music', 'sports', 'travel', 'cooking')
);
-- 查询喜欢音乐和阅读的用户
SELECT * FROM user_profiles WHERE interests & 'music' AND interests & 'reading';
JSON 类型的高级查询与索引
MySQL 的 JSON 类型支持复杂的嵌套查询和索引优化:
-- 创建包含嵌套JSON的表
CREATE TABLE products (
product_id INT PRIMARY KEY,
details JSON
);
-- 插入嵌套JSON数据
INSERT INTO products VALUES (
1,
'{
"name": "智能手机",
"price": 5999,
"specs": {
"screen": "6.7英寸",
"camera": "108MP",
"battery": "5000mAh"
},
"colors": ["黑色", "白色", "蓝色"]
}'
);
-- 创建JSON字段的索引
CREATE INDEX idx_specs_screen ON products ((details->'$.specs.screen'));
-- 查询特定屏幕尺寸的产品
SELECT * FROM products WHERE details->'$.specs.screen' = '6.7英寸';
-- 使用JSON_TABLE展开数组
SELECT product_id, color
FROM products,
JSON_TABLE(
details,
'$.colors[*]' COLUMNS (color VARCHAR(20) PATH '$')
) AS colors;
时间序列数据的高效存储
对于时间序列数据(如监控指标、传感器数据),可通过分区和合适的数据类型优化:
-- 创建按日期分区的表
CREATE TABLE sensor_data (
timestamp TIMESTAMP,
sensor_id INT,
value FLOAT,
PRIMARY KEY (timestamp, sensor_id)
)
PARTITION BY RANGE (UNIX_TIMESTAMP(timestamp)) (
PARTITION p_202301 VALUES LESS THAN (UNIX_TIMESTAMP('2023-02-01')),
PARTITION p_202302 VALUES LESS THAN (UNIX_TIMESTAMP('2023-03-01')),
...
);
-- 查询特定时间段的数据
SELECT * FROM sensor_data WHERE timestamp BETWEEN '2023-01-01' AND '2023-01-31';
优化要点:
使用 TIMESTAMP 而非 DATETIME 存储时间戳,节省空间。
通过分区快速定位特定时间段的数据,减少扫描范围。
十四、性能调优与数据类型监控
数据类型相关的性能分析工具
MySQL 提供多种工具分析数据类型对性能的影响:
EXPLAIN 语句:分析查询执行计划,检查索引使用情况:
EXPLAIN SELECT * FROM users WHERE age > 30;
SHOW TABLE STATUS:查看表的基本信息,包括平均行长度、数据类型分布:
SHOW TABLE STATUS LIKE 'users';
INFORMATION_SCHEMA:查询系统表获取详细的列信息:
SELECT COLUMN_NAME, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH
FROM INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'users';
数据类型优化案例
优化高并发订单表
原表结构:
CREATE TABLE orders (
order_id VARCHAR(32) PRIMARY KEY, -- 使用UUID字符串作为主键
user_id INT,
amount DECIMAL(10, 2),
create_time DATETIME
);
优化方案:
-- 修改主键为BIGINT自增,提升索引效率
ALTER TABLE orders
DROP PRIMARY KEY,
ADD order_id BIGINT AUTO_INCREMENT PRIMARY KEY FIRST;
-- 添加用户ID和时间的复合索引
CREATE INDEX idx_user_time ON orders (user_id, create_time);
压缩历史数据表
对于历史数据,可通过数据类型转换减少存储空间:
-- 将INT类型的count字段转换为SMALLINT(假设值范围较小)
ALTER TABLE statistics MODIFY count SMALLINT;
-- 将VARCHAR(255)的固定长度字段改为更合适的长度
ALTER TABLE products MODIFY description VARCHAR(100);
定期数据类型审核与优化
建议定期执行以下操作:
检查表空间使用:
SELECT
table_name,
data_length,
index_length,
data_free
FROM INFORMATION_SCHEMA.TABLES
WHERE TABLE_SCHEMA = 'your_database';
分析字段使用频率:
SELECT COLUMN_NAME, COUNT(DISTINCT column_name) AS distinct_count
FROM your_table
GROUP BY COLUMN_NAME;
根据业务变化调整数据类型:
若某个字段值范围扩大,及时调整类型(如从 INT 到 BIGINT)。
对于不再使用的大字段,考虑删除或拆分到单独的表。
十五、MySQL 数据类型的未来发展趋势
与人工智能的深度融合
未来 MySQL 可能会引入更适合 AI 模型训练的数据类型,例如:
张量数据类型:直接支持多维数组存储,简化 AI 模型参数的存储与查询。
概率数据类型:用于存储和处理概率分布,支持贝叶斯推断等统计计算。
对分布式和云原生的优化
随着云原生数据库的普及,MySQL 可能会增强数据类型在分布式环境下的表现:
分布式时间戳:解决分布式系统中的时钟同步问题,提供更可靠的全局时间。
轻量级事务数据类型:优化跨节点事务处理性能,减少分布式事务的开销。
对非结构化数据的进一步支持
未来可能会增强 JSON、空间数据等类型的功能:
JSON 原生索引:提供更高效的 JSON 字段索引机制,支持复杂路径查询。
图数据类型:原生支持图结构数据的存储与查询,简化社交网络、知识图谱等应用开发。
绿色计算导向的数据类型优化
为响应节能减排需求,MySQL 可能会推出更节省存储和计算资源的数据类型:
压缩数据类型:在存储时自动压缩数据,减少磁盘 I/O 和存储空间。
低精度数值类型:针对不需要高精度的场景(如传感器数据),提供更节省空间的数值表示。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











