






如果赶时间请直接看第四大步中的源码,好好看完这篇博客,这里保证大家以后彻底搞懂获得一个网站怎么来爬取!!!!
一、准备
1、安装好BeautifulSoup
二、选入合适的爬取的目标
1、如何看出网站做了反爬
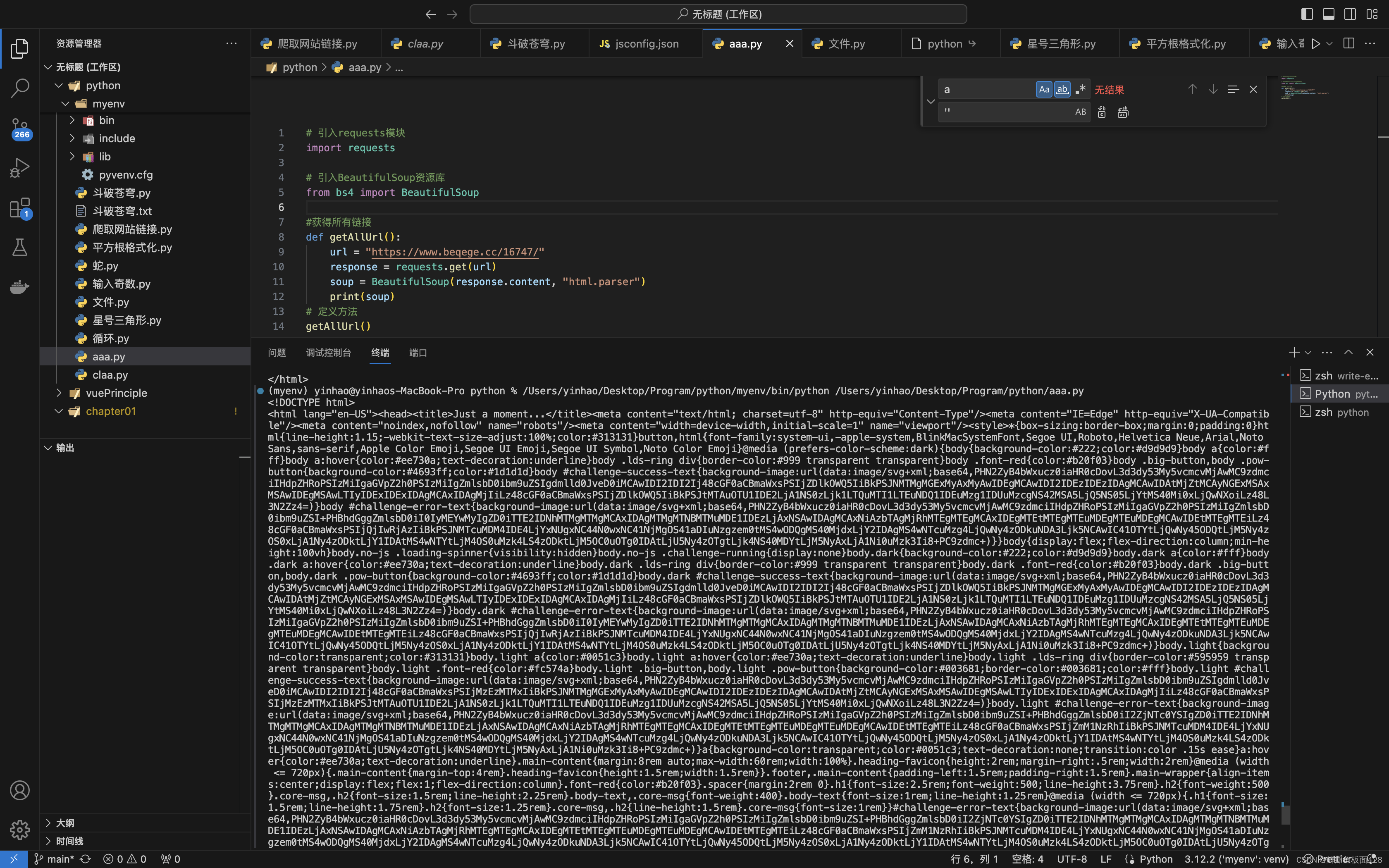
小编第一次搜索搜索到了该网站斗破苍穹
如下,返回的html原文档一串密文,当然你也可以选择试着解析密文!
# 引入requests模块
import requests
# 引入BeautifulSoup资源库
from bs4 import BeautifulSoup
#获得所有链接
def getAllUrl():
url = "https://www.beqege.cc/16747/"
response = requests.get(url)
# 返回html的原文档
soup = BeautifulSoup(response.content, "html.parser")
print(soup)
# 定义方法
getAllUrl()
2、合适的网站
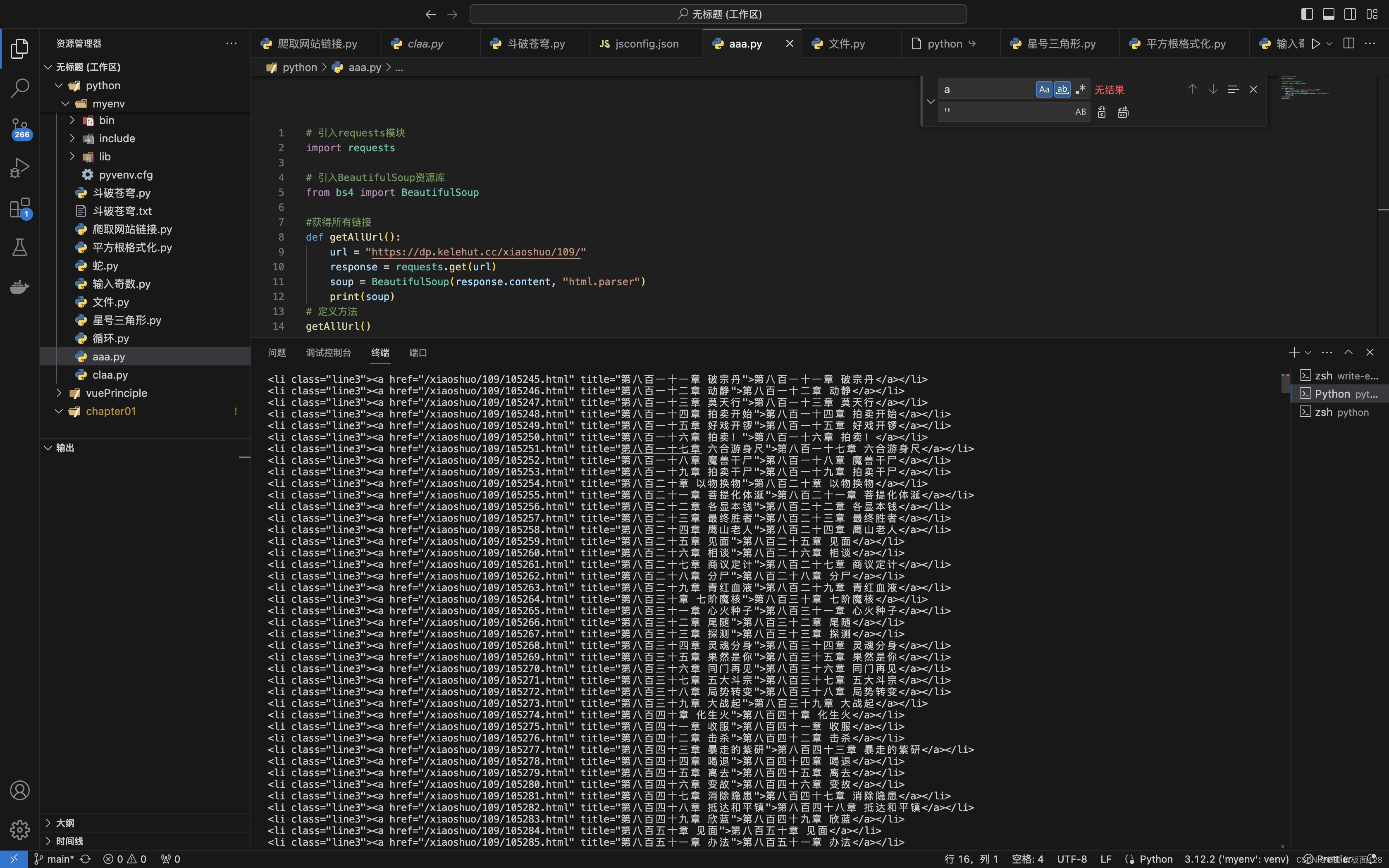
小编又向下找找到了这个网站斗破苍穹,这个网站用BeautifulSoup测试后发现能返回正常的html,那他就是适合的网站。
三、理思路
1、选择合适的页面
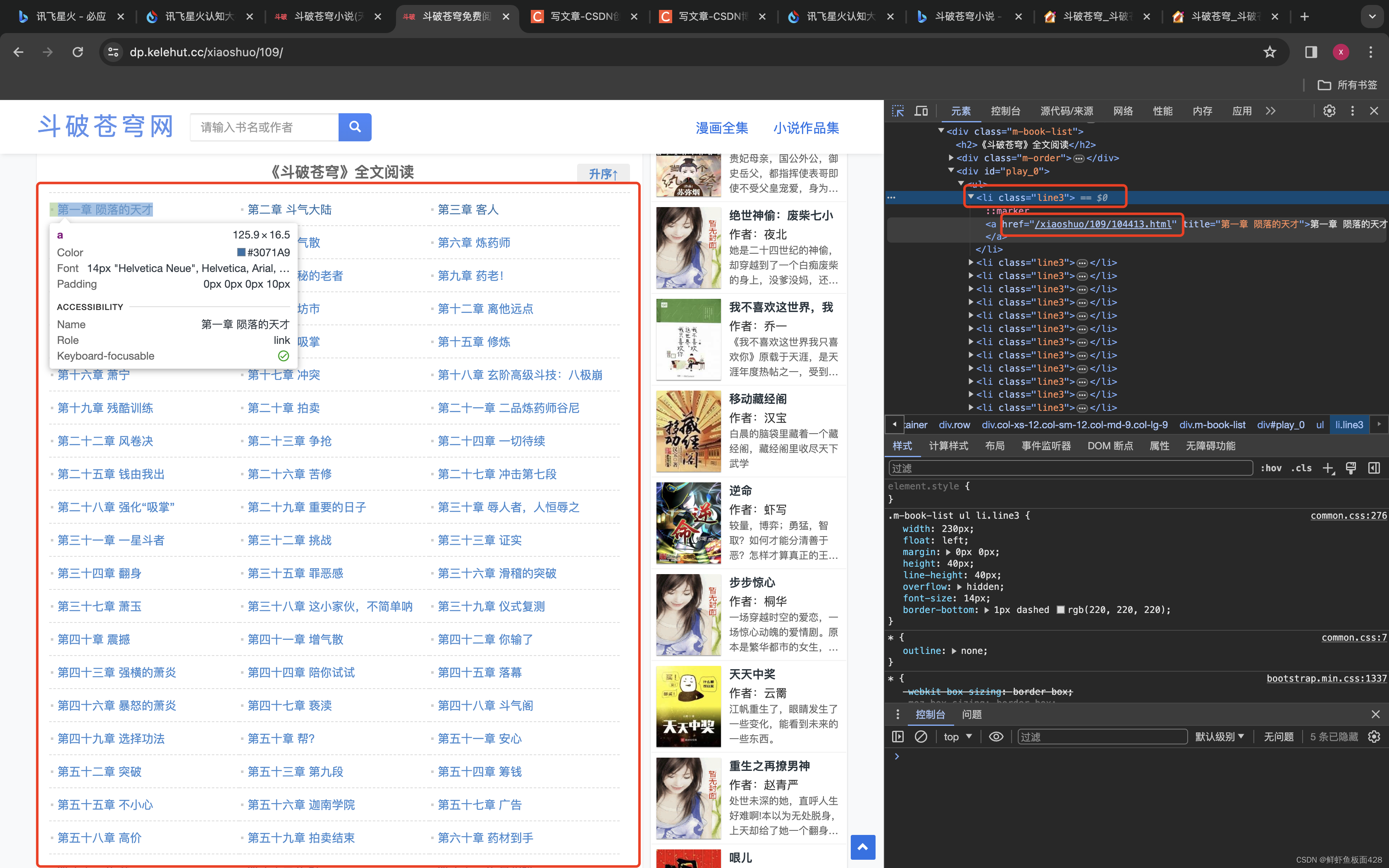
如下,当前这个含有每一章链接的页面就是一个很好的切入网站!!
2、选择合适的元素
咱们查看原html文档发现每一个<a>链接都是由一个<ul>元素包裹
其中这个ul元素的类名是line3
所以咱们可以先获取到所有的line3然后再获取内部的<a>元素
三、爬取
1、获取所有章节的链接
获取网站上链接
# 引入requests模块
import requests
# 引入BeautifulSoup资源库
from bs4 import BeautifulSoup
# 获得所有链接,返回一个数组
def getAllUrl():
url = "https://dp.kelehut.cc/xiaoshuo/109/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
hrefArr = []
# 寻找soup原html文档所有类名是line3的元素
# 然后再把每一个line3中的<a>便利出来,负值给href
# 再将每一个href插入到hrefArr里面
# 最后返回一个url数组
for i in soup.find_all(class_="line3"):
for params in i.find_all("a"):
href = params.get("href")
hrefArr.append(href)
return hrefArr
# 定义方法
print(getAllUrl())
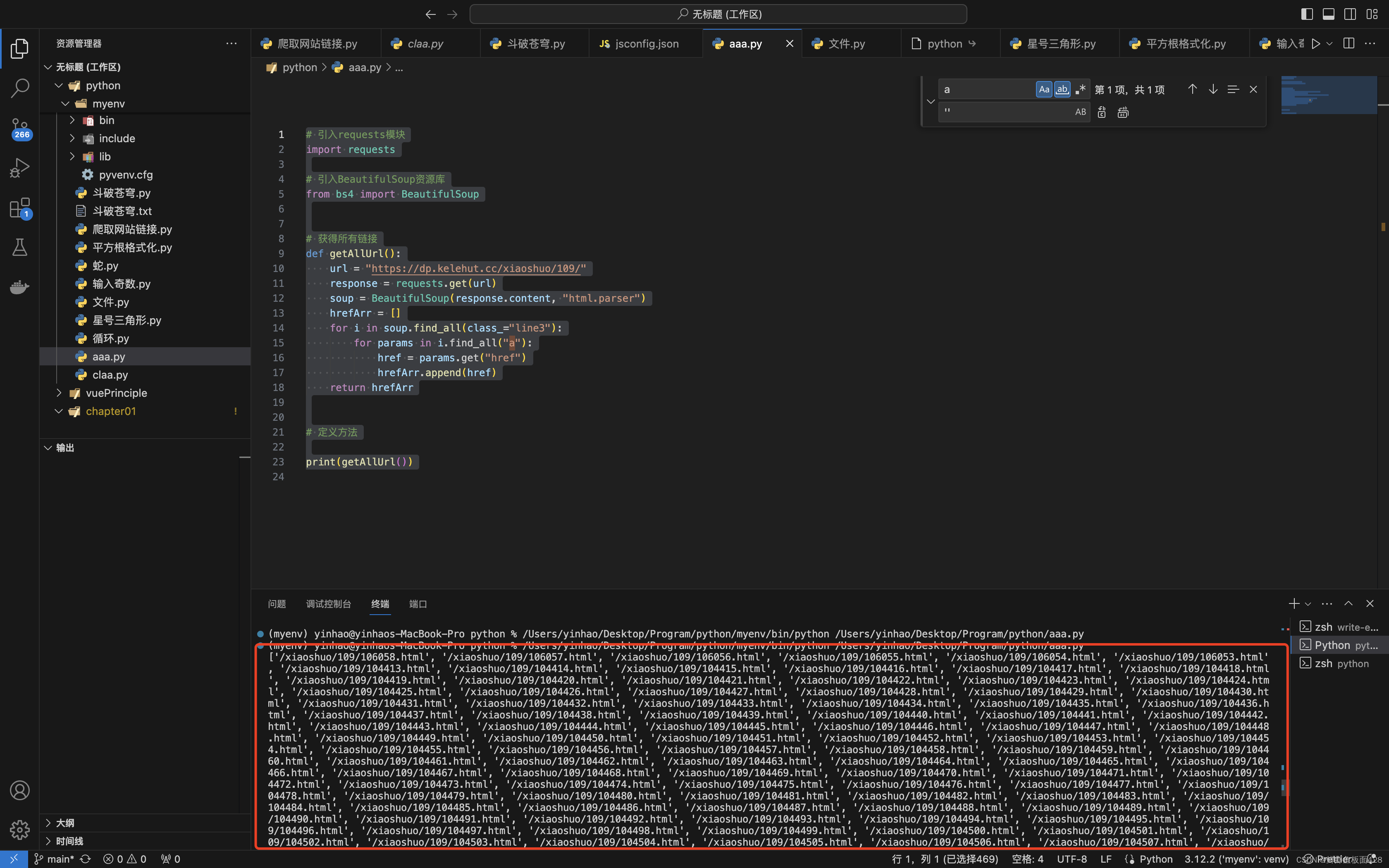
补全链接
我们可以看到第一步获取到的所有的链接都是被省略了域名
所以这里需要我们手动把每一个链接给补全
后来补全的网站可以尝试直接访问了!!!!

# 引入requests模块
import requests
# 引入BeautifulSoup资源库
from bs4 import BeautifulSoup
#获得所有链接
def getAllUrl():
url = "https://dp.kelehut.cc/xiaoshuo/109/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
hrefArr = []
for i in soup.find_all(class_="line3"):
for params in i.find_all("a"):
href = "https://dp.kelehut.cc/" + params.get("href")
hrefArr.append(href)
return hrefArr
# 定义方法
print(getAllUrl())
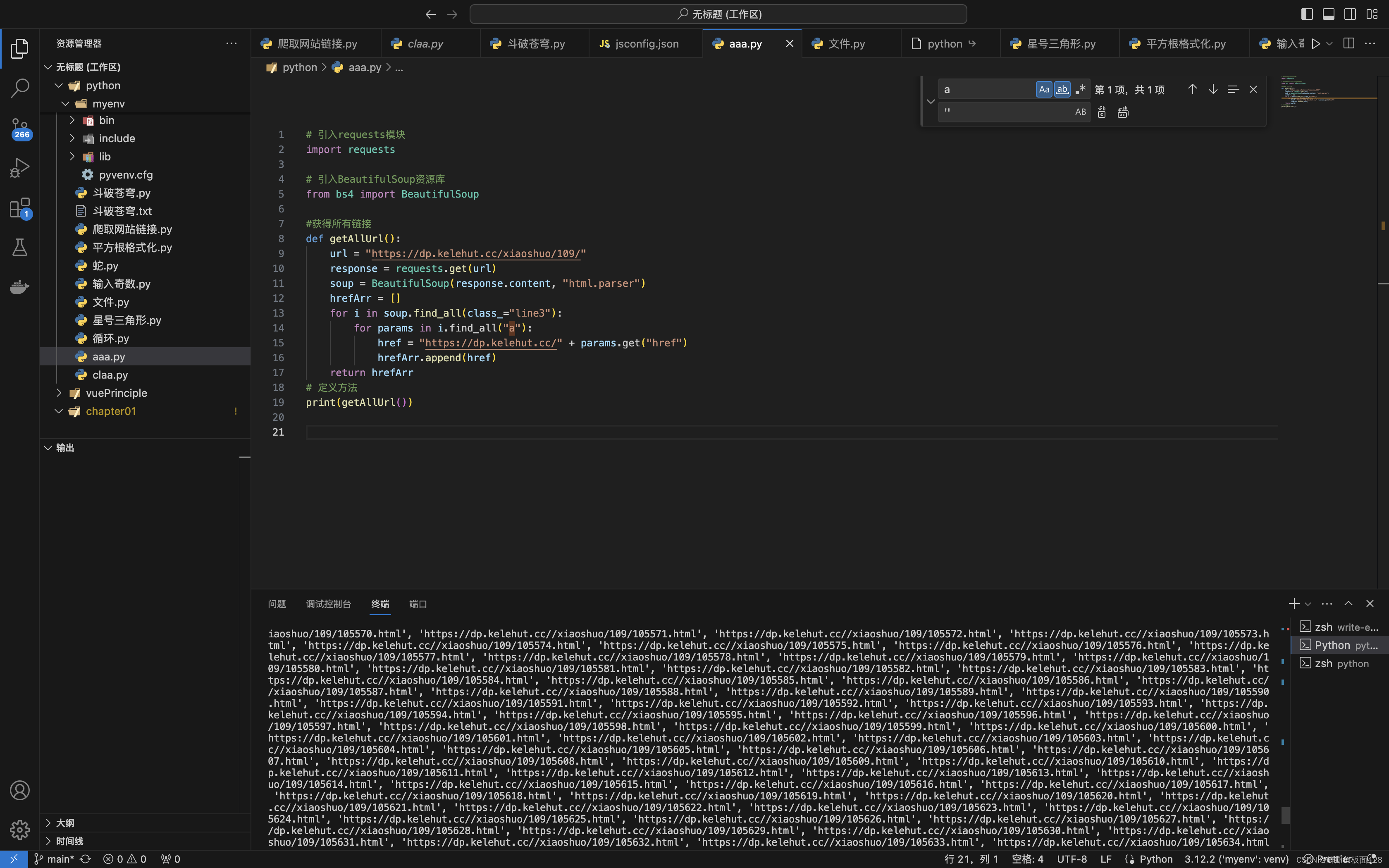
2、获取每一个链接章节的标题和内容
1、获取单个章节内容
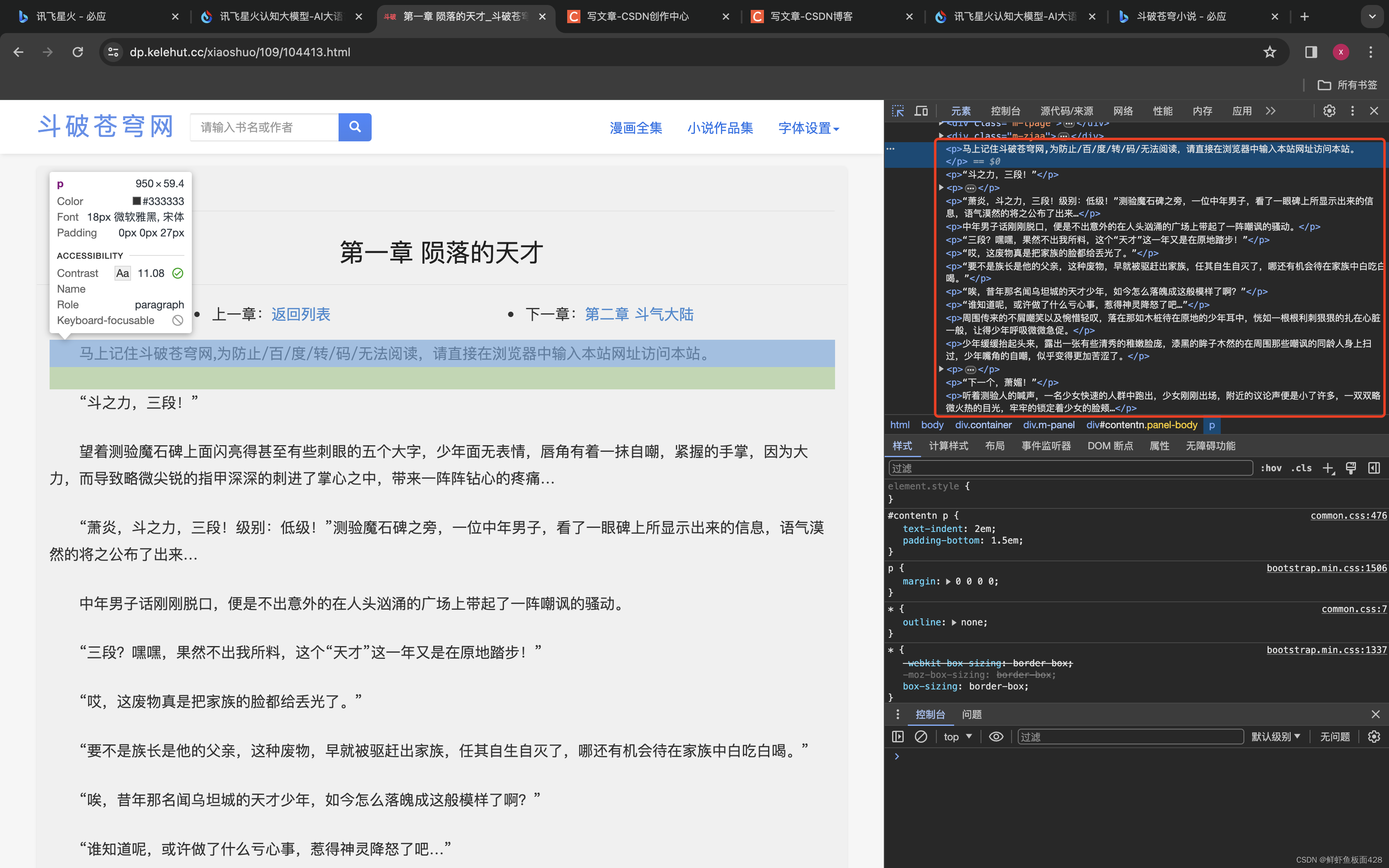
如图通过过第一章我们发现我们需要获取:
*文章标题<h1>元素
*还有所有的<p>
然后将组成一个{ "title": title,"message": message }的对象
最后getText将会是一个传入一个链接
然后返回这个链接章节里面所有内容(text)的方法
由于一次传输的内容过大这里咱们就单个测试一下
# 引入requests模块
import requests
# 引入BeautifulSoup资源库
from bs4 import BeautifulSoup
#获得所有链接
def getAllUrl():
url = "https://dp.kelehut.cc/xiaoshuo/109/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
hrefArr = []
for i in soup.find_all(class_="line3"):
for params in i.find_all("a"):
href = "https://dp.kelehut.cc/" + params.get("href")
hrefArr.append(href)
return hrefArr
# 定义获取章节内容方法
def getText(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 获取<h1>中的title
title = soup.find("h1").getText()
message = ""
# 获取所有的<p>元素
body = soup.find_all("p")
# 去掉第一个对象(因为第一个是额外内容)
body = body[1:]
for i in body:
# 获取每一个<p>的内容并添加换行
message = message + i.getText() + "\n"
# 组成数组插入到text数组里面!
text = ({"title": title, "message": message})
return text
res = getAllUrl()
messageArr = []
messageArr.append(getText(res[0]))
print(messageArr)
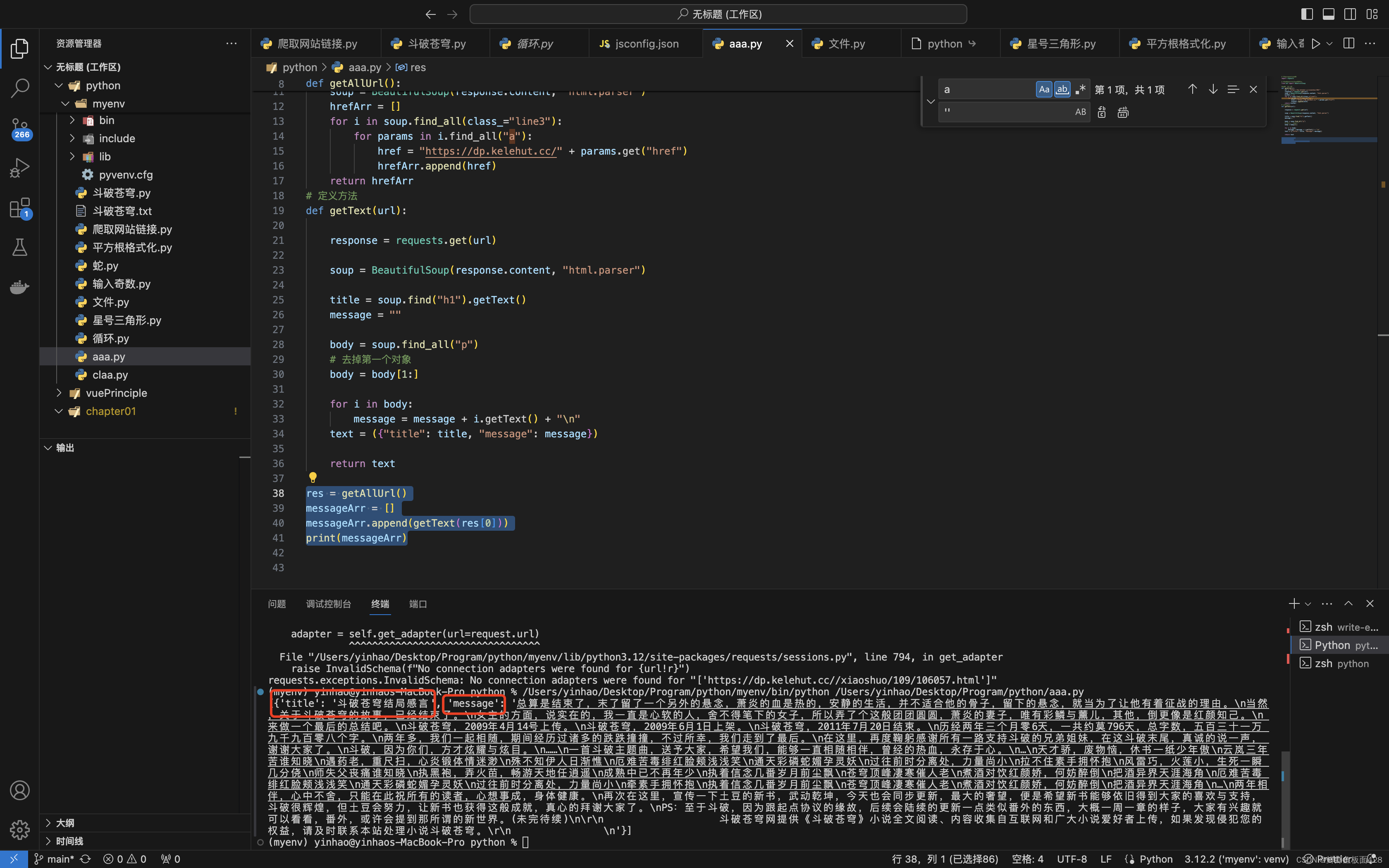
2、获取所有的内容
由于链接一次性获取太大,咱们就试一下6-10的链接章节内容
(小编发现第六个链接才是第一章,有可能是原html文档的问题)
好现在咱们获取了一个所有章节对象的内容的数组
import requests
from bs4 import BeautifulSoup
#获得所有链接
def getAllUrl():
url = "https://dp.kelehut.cc/xiaoshuo/109/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
hrefArr = []
for i in soup.find_all(class_="line3"):
for params in i.find_all("a"):
href = "https://dp.kelehut.cc/" + params.get("href")
hrefArr.append(href)
return hrefArr
# 定义方法
def getText(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
title = soup.find("h1").getText()
message = ""
body = soup.find_all("p")
# 去掉第一个对象(因为这段话没用)
body = body[1:]
for i in body:
message = message + i.getText() + "\n"
text = ({"title": title, "message": message})
return text
# 添加到文件
def addFile(arr):
file_path = "斗破苍穹.txt"
with open(file_path, "a") as file:
for item in arr:
file.write(item["title"] + "\n" + item["message"])
res = getAllUrl()
messageArr = []
for i in range(6, 10):
messageArr.append(getText(res[i]))
addFile(messageArr)
print(messageArr)
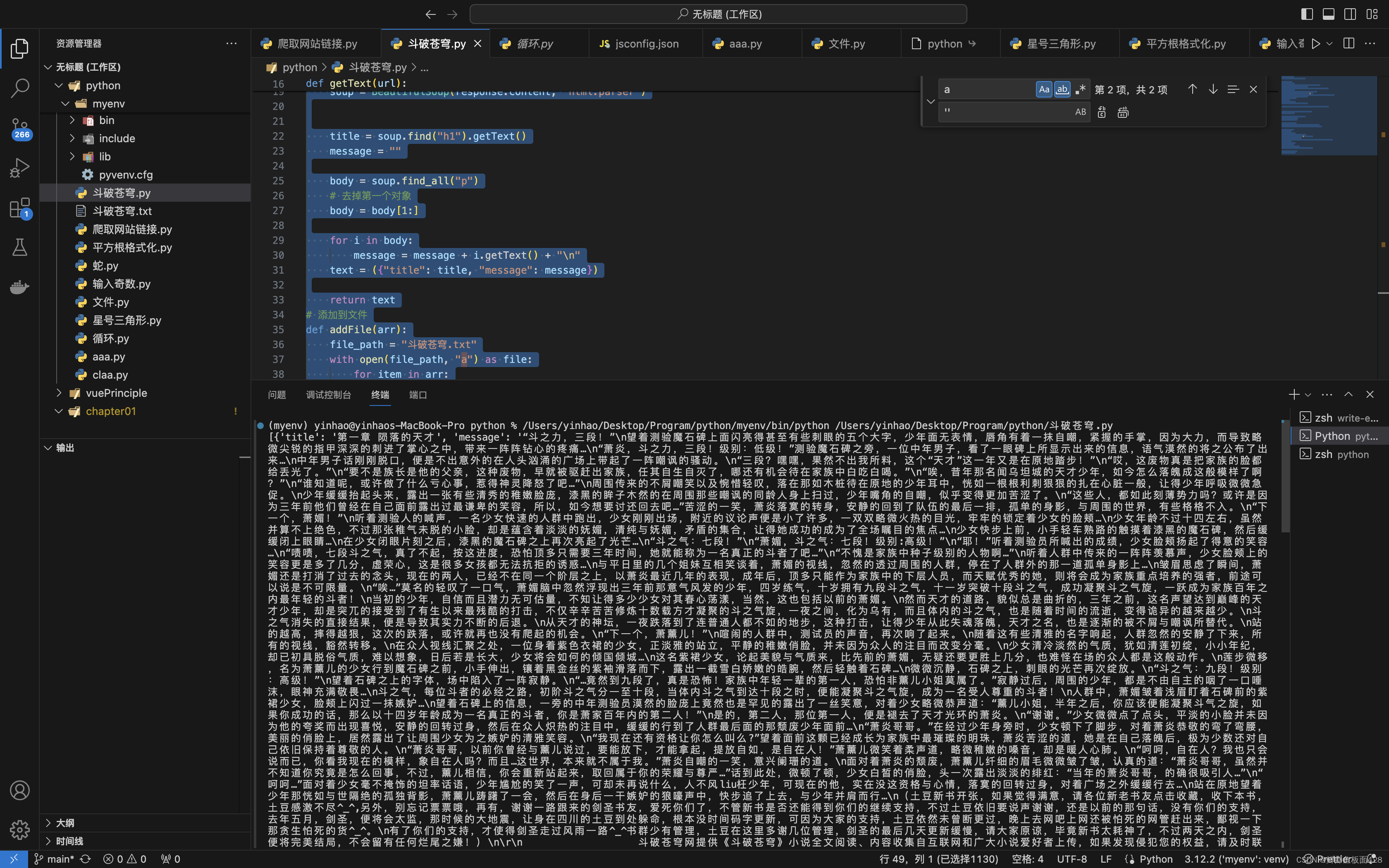
3、添加到文本中
def addFile(arr):
file_path = "斗破苍穹.txt"
with open(file_path, "a") as file:
for item in arr:
file.write(item["title"] + "\n" + item["message"])
res = getAllUrl()
messageArr = []
for i in range(6, 10):
messageArr.append(getText(res[i]))
addFile(messageArr)
四、源码
# 引入requests模块
import requests
# 引入BeautifulSoup资源库
from bs4 import BeautifulSoup
#获得所有链接
def getAllUrl():
url = "https://dp.kelehut.cc/xiaoshuo/109/"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
hrefArr = []
for i in soup.find_all(class_="line3"):
for params in i.find_all("a"):
href = "https://dp.kelehut.cc/" + params.get("href")
hrefArr.append(href)
return hrefArr
# 定义方法
def getText(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
title = soup.find("h1").getText()
message = ""
body = soup.find_all("p")
# 去掉第一个对象
body = body[1:]
for i in body:
message = message + i.getText() + "\n"
text = ({"title": title, "message": message})
return text
def addFile(arr):
file_path = "斗破苍穹.txt"
with open(file_path, "a") as file:
for item in arr:
file.write(item["title"] + "\n" + item["message"])
res = getAllUrl()
messageArr = []
for i in range(6, 10):
messageArr.append(getText(res[i]))
addFile(messageArr)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









