







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
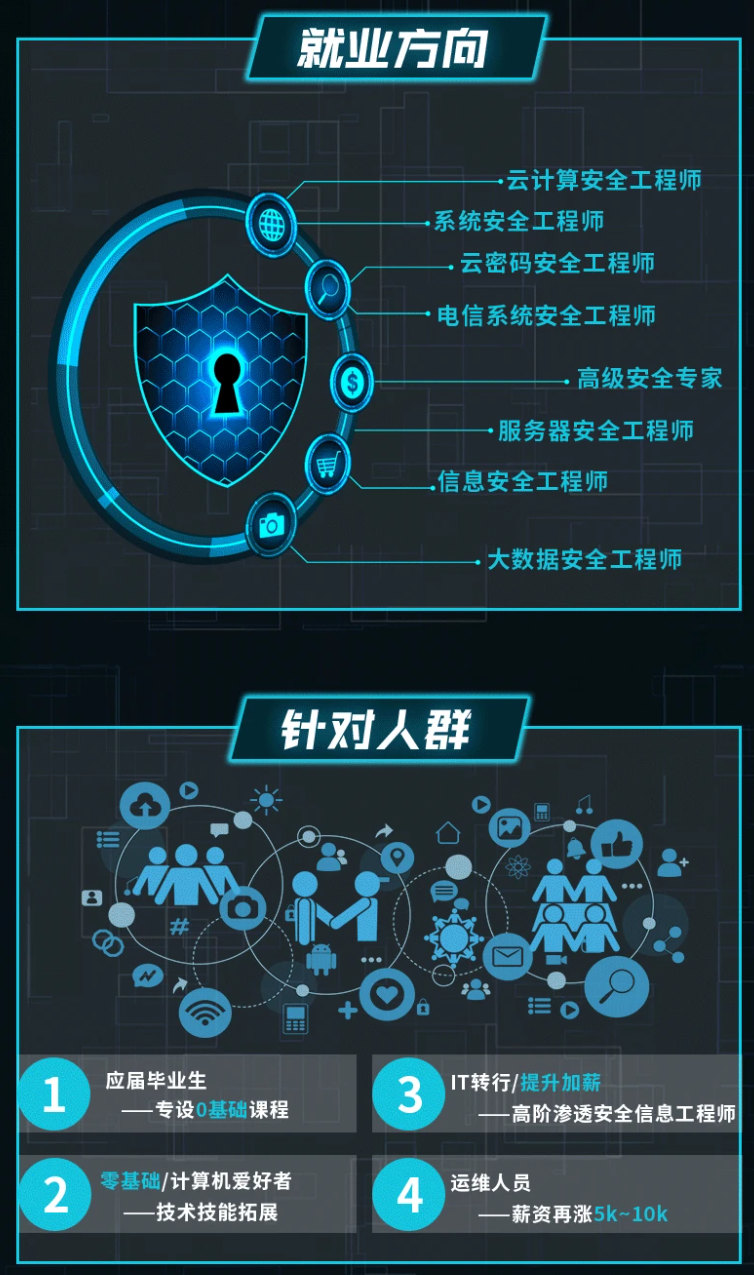
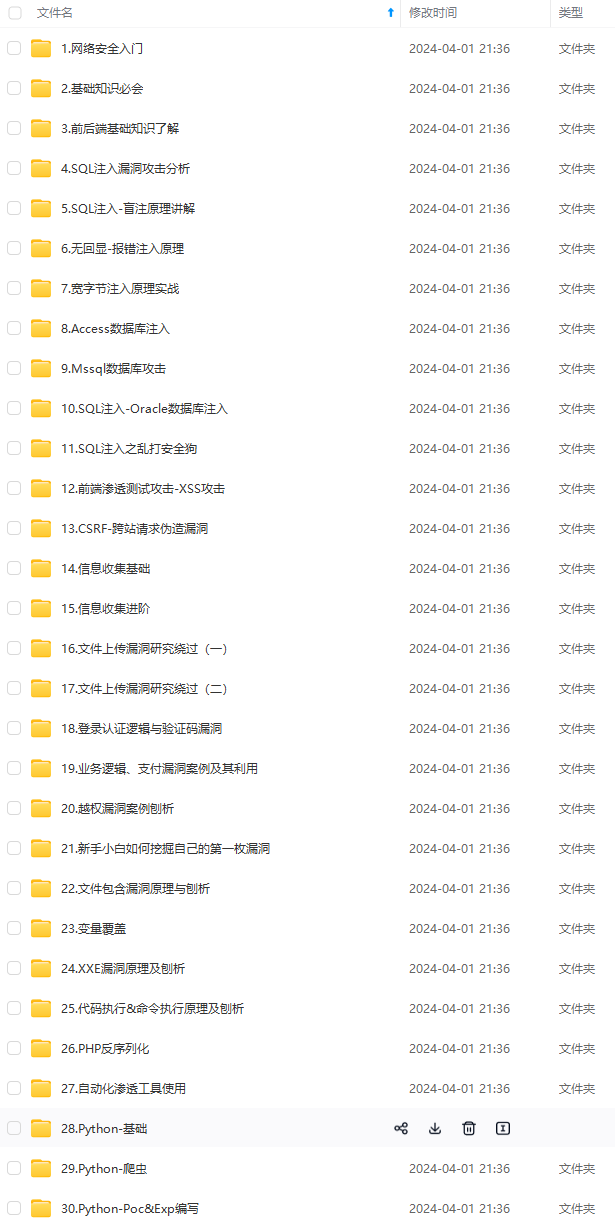
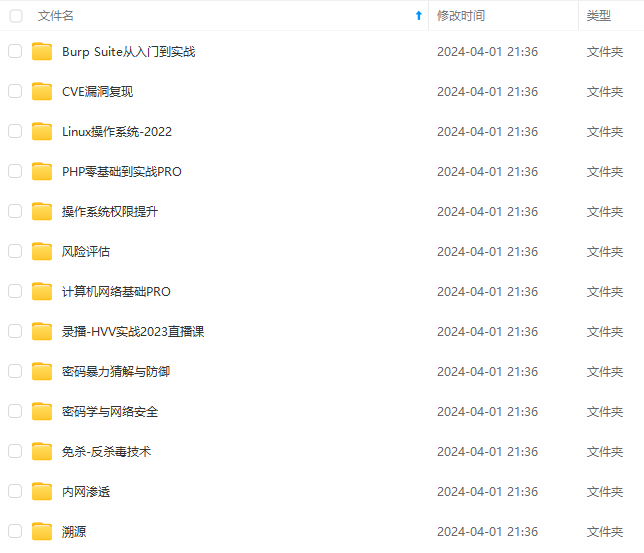
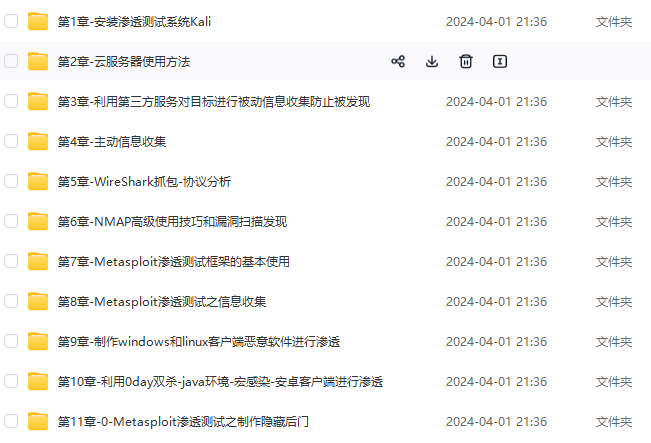
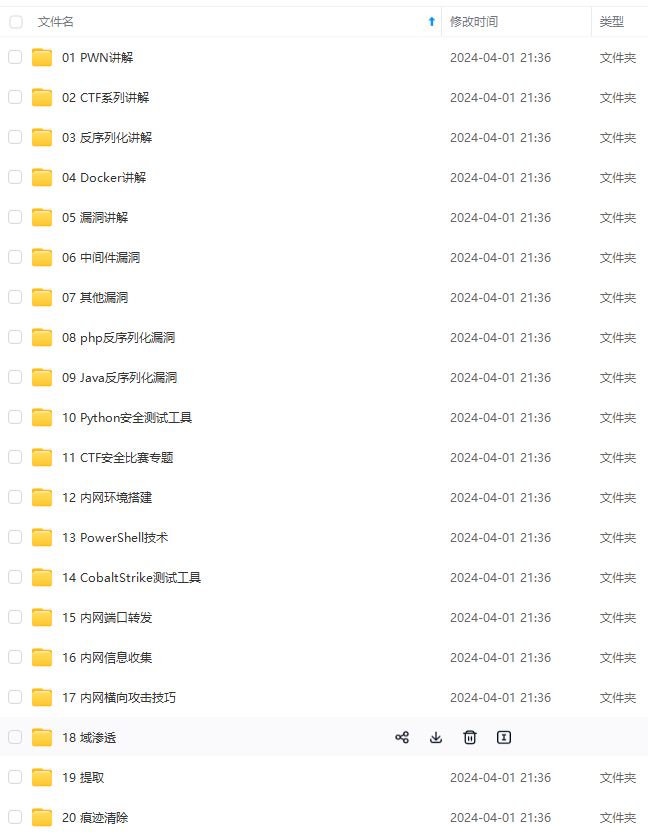
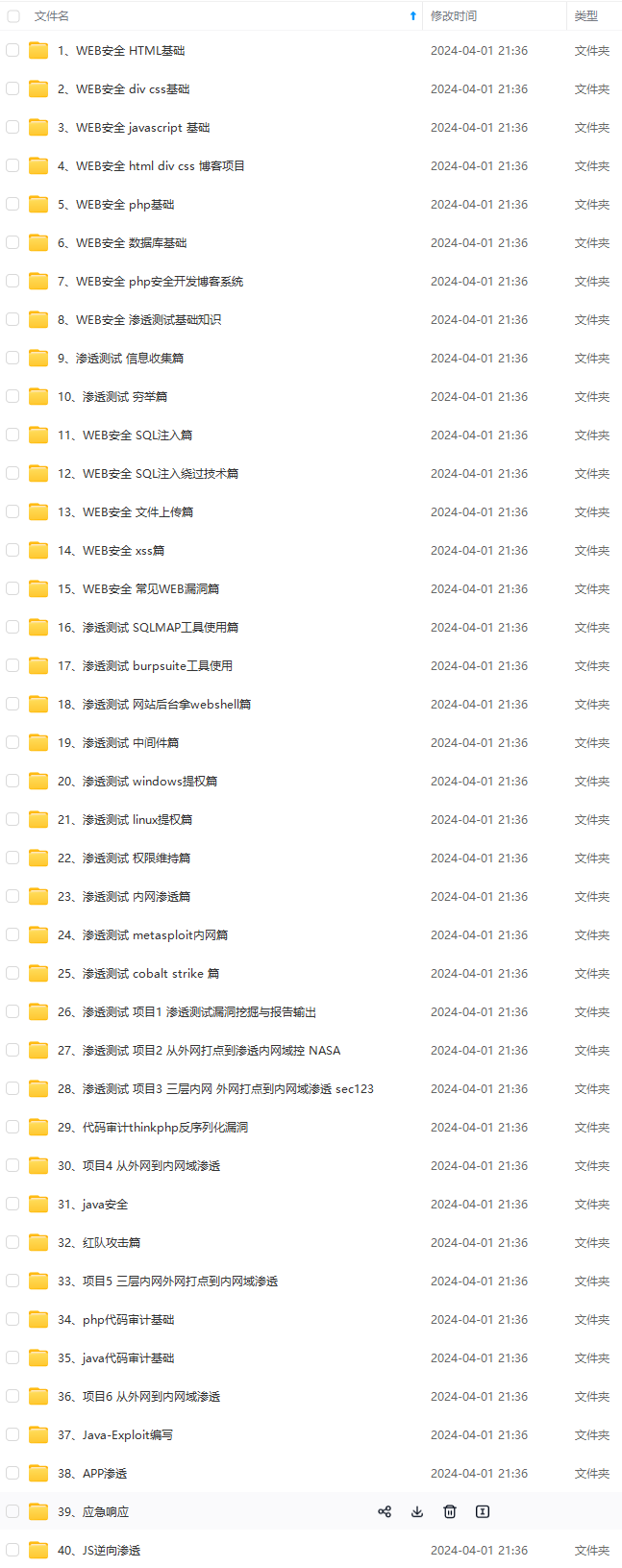
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
−
p
a
t
h
h-path
h−path?](#21hpath_52)
- [2.2、如何减少
h
−
p
a
t
h
h-path
h−path的数量?](#22hpath_55)
- [2.3、哪些h-path将被添加到种子队列?](#23hpath_67)
- [2.4、种子选择算法](#24_75)
- [2.5、资源调度](#25_80)
+ [3、达到的效果](#3_83)
+ - [3.1、一个简单例子的结果(RQ1)](#31RQ1_86)
- [3.2、代码覆盖率和崩溃测量(RQ2)](#32RQ2_91)
- [3.3、LAVA-M数据集(RQ3)的结果](#33LAVAMRQ3_106)
- [3.4、发现现实世界中的漏洞(RQ3)](#34RQ3_111)
+ [4、结论](#4_116)
前言
此博客为PathAFL:Path-Coverage Assisted Fuzzing论文的阅读笔记,本篇论文提出了一种新的跟踪执行路径的方法、路径过滤算法和追踪执行路径的方法,以提高Fuzz的准确性以及Fuzz性能。本文将会从解决的问题和目标、技术路线、达到的效果和结论四个角度来分析本篇论文。以下就是本文的全部内容。
PathAFL:Path-Coverage Assisted Fuzzing
1、解决的问题和目标
现有的覆盖引导fuzzer通常使用所探索的基本块或边的数量来测量代码覆盖,路径覆盖可以提供比基本块和边缘覆盖更准确的覆盖信息。然而,路径的数量随着程序大小的增加而呈指数级增长,几乎不可能追踪真实世界应用程序的所有路径,这也是本文亟待解决的问题。针对此问题,本文完成了以下几个目标:
- 作者提出了一种新的跟踪执行路径的方法,并在跟踪路径覆盖粒度和fuzzing性能之间进行了权衡。研究发现,作者可以用很少的开销来追踪重要的路径
- 作者设计了一种路径过滤算法,它对新的路径做出了快速的判断。只有那些满足特定条件并具有高权重的路径才会添加到种子队列中
- 作者提出了一种追踪执行路径的新方法,并在追踪路径覆盖的细粒度和模糊性能之间进行了权衡。研究发现,作者可以在几乎没有额外开销的情况下追踪重要路径
- 作者开发了PathAFL的开源实现,并将其作为AFL的分支发布在Github上
2、技术路线
关于PathAFL的工作过程如下图所示(紫色的组件显示了作者对原始AFL的改进):

由上图可知,PathAFL是在AFL的基础上进行改进的,而AFL的整个工作流程如下所示:
- 对目标应用插桩
- 向种子队列提供初始输入
- 选择种子。AFL根据种子选择算法从种子队列中选择一个种子,该算法更喜欢更快、更小的种子。种子选择算法采用贪婪算法实现,如下图所示:

- 变异种子。该步骤使用多种变异算法对种子文件进行变异,并在循环中生成大量测试用例
- 测试和跟踪。此步骤以测试用例为输入,执行并跟踪插桩指令的目标应用程序
- 报告崩溃。如果发现崩溃,则可能触发了潜在的漏洞
- 识别种子。如果发现新的边缘覆盖状态,则将测试用例添加到下一个循环的种子队列中
- 如果该种子的fuzzing结束,则转到步骤(3),否则转到步骤(4)
需要注意的是,整个fuzzing处理过程是一个无限循环,只有在手动终止时才会结束循环。此外,因为AFL使用哈希计算来存储边缘覆盖信息(需要通过在每个BBL中插入一个BID随机数来进行哈希计算),不过这样会存在哈希冲突的问题(哈希冲突率通常在30%~70%范围内浮动)。为了解决这个问题,AFL又发展为了CollAFL,CollAFL使用新的哈希计算来存储边缘覆盖信息,这样可以让哈希冲突降低到接近0%(不过CollAFL只使用了边缘覆盖)。此外,CollAFL还遵循以下三个新的种子选择策略:
- 具有更多未受影响的相邻分支的种子将优先进行fuzzing处理
- 更喜欢有更多未受影响的邻居后代的种子
- 更喜欢具有更多内存访问操作的种子
现在我们对AFL和CollAFL已经有了较深的理解,不过上面提到的这两种技术的覆盖率信息又是什么东西呢?覆盖率信息可以看作是评判fuzzer的能力的一项指标,覆盖率越高,说明fuzzer探索到的路径越多,故越有可能发现漏洞;反之则说明覆盖率越低,说明fuzzer探索到的路径越少,故越没有可能发现漏洞。目前测量代码覆盖率的方法主要有三种:
- B
B
L
BBL
BBL覆盖率(基本块覆盖率):
B
B
L
BBL
BBL是一个有一个入口和一个出口点的代码片段,BBL中的指令将按顺序执行,并且只执行一次。
B
B
L
BBL
BBL是程序执行的最小相干单元,可以通过第一条指令的地址来识别。通过代码插入和静态分析可以很容易地提取BBL信息。由于这些优点,
B
B
L
BBL
BBL覆盖信息被fuzzer广泛使用。而典型的基于
B
B
L
BBL
BBL的覆盖引导fuzzer只跟踪每个块是否被击中,而不跟踪fuzzing过程中哪些块被击中的顺序,因此详细信息会丢失。如下图所示,在fuzzing过程中,如果首先执行程序路径
1
(
A
,
B
,
C
,
D
)
1(A,B,C,D)
1(A,B,C,D),则与程序路径
2
(
A
,
B
,
D
)
2(A,B,D)
2(A,B,D)相关联的测试用例将永远不会添加到种子队列中,因为路径
2
2
2没有命中新的
B
B
L
BBL
BBL,因此边缘
B
D
BD
BD的信息将丢失。

13. 边缘覆盖率:为了解决
B
B
L
BBL
BBL覆盖的缺点,边缘覆盖跟踪每条边缘是否被击中。在上图的例子中,如果首先执行程序路径
1
(
A
,
B
,
C
,
D
)
1(A,B,C,D)
1(A,B,C,D),fuzzer将记录边缘
A
B
AB
AB、
B
C
BC
BC和
C
D
CD
CD,当执行路径
2
(
A
、
B
、
D
)
2(A、B、D)
2(A、B、D)时将记录新的边缘
B
D
BD
BD,因此与路径
2
2
2相关的测试用例现在将添加到种子队列中。然而,边缘覆盖并不能追踪边缘被命中的顺序,因此一些详细信息可能会丢失。我们使用下图中的简单程序和其控制流图来说明这个问题,该程序以
8
8
8个字符作为输入。当输入为abcd**‼或**cdef!!时,程序将崩溃。

14. 路径覆盖率:基于路径覆盖的方法跟踪整个执行路径,包括命中的顺序边缘,从而记录最丰富的信息。几乎不可能为真实世界的应用程序实现路径覆盖,因为程序中有太多的循环和条件,路径的数量会激增。海量路径将带来较大的运行时开销,并可能降低模糊处理的效率。为了克服这个问题,作者将新探索的路径分为两类:
* 对于之前未触及的边,作者将其表示为
e
−
p
a
t
h
e-path
e−path。
“
e
−
”
“e-”
“e−”表示路径有新的边
* 所有边都已接触的路径,作者将其表示为
h
−
p
a
t
h
h-path
h−path。
“
h
−
”
“h-”
“h−”表示路径有一个新的哈希
关键问题是如何处理大量的
h
−
p
a
t
h
h-path
h−path,作者的解决方案是,不将所有的
h
−
p
a
t
h
h-path
h−path添加到种子队列,而只将那些高权重的
h
−
p
a
t
h
h-path
h−path增加到种子队列。这是一种效率和追踪粒度之间的权衡。
根据上文分析可以发现,目前主要的挑战是路径的数量随着程序大小的增加而呈指数级增长。因此,建议只向种子队列添加重要路径。根据这一思想,作者总结了路径覆盖辅助fuzzer的三个关键问题:
- 如何识别
h
−
p
a
t
h
h-path
h−path?
2. 如何减少
h
−
p
a
t
h
h-path
h−path的数量?
3. 哪些
h
−
p
a
t
h
h-path
h−path将被添加到种子队列?
2.1、如何识别
h
−
p
a
t
h
h-path
h−path?
静态插桩。AFL在编译时对目标程序进行插桩。插桩代码计算边缘哈希并更新边缘覆盖记录到共享内存中。PathAFL维护一个类似AFL的全局哈希表。表索引表示路径哈希,值表示路径是否被覆盖。PathAFL以类似的方式对目标程序进行插桩。它只在AFL原始插桩代码中插入了一小段代码来计算路径哈希。此外,PathAFL扩展了原始共享内存,以存储路径哈希值的4个字节。在程序执行期间,执行路径的哈希值会实时计算并追加到共享内存中。当程序运行完成时,执行路径哈希可用于确定是否已探索新路径。与AFL相比,PathAFL只在插入代码中添加了哈希计算函数,导致开销增加很少。
2.2、如何减少
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
h−path的数量?
3. 哪些
h
−
p
a
t
h
h-path
h−path将被添加到种子队列?
2.1、如何识别
h
−
p
a
t
h
h-path
h−path?
静态插桩。AFL在编译时对目标程序进行插桩。插桩代码计算边缘哈希并更新边缘覆盖记录到共享内存中。PathAFL维护一个类似AFL的全局哈希表。表索引表示路径哈希,值表示路径是否被覆盖。PathAFL以类似的方式对目标程序进行插桩。它只在AFL原始插桩代码中插入了一小段代码来计算路径哈希。此外,PathAFL扩展了原始共享内存,以存储路径哈希值的4个字节。在程序执行期间,执行路径的哈希值会实时计算并追加到共享内存中。当程序运行完成时,执行路径哈希可用于确定是否已探索新路径。与AFL相比,PathAFL只在插入代码中添加了哈希计算函数,导致开销增加很少。
2.2、如何减少
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)
[外链图片转存中…(img-80CufSxJ-1713282487969)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









