






卷积层的定义
-
官方给出的定义为:卷积神经网络中每层卷积层(Convolutionallayer)由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法最佳化得到的。卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
-
我自己的理解是:跟感知机中的全连接层做比较,全连接层中,每个输入层中的都会有一个权值进行连接。对于卷积层,则是部分进行权值连接。
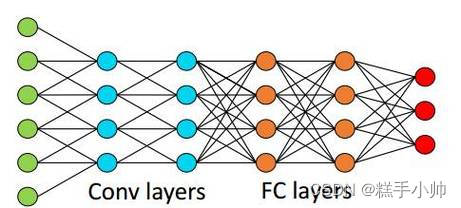
-
绿色到蓝色为卷积层,橙色之间为全连接层。可以清晰的看到,卷积层的计算量有着明显的下降。
使用动画演示:
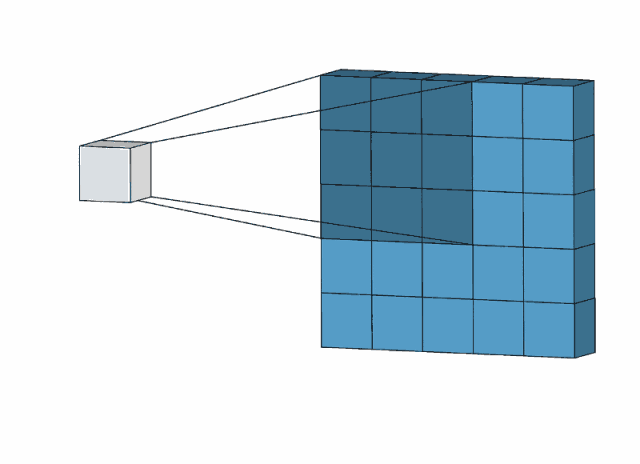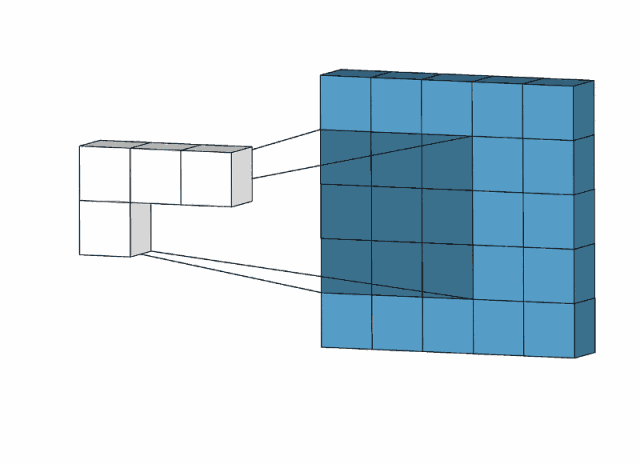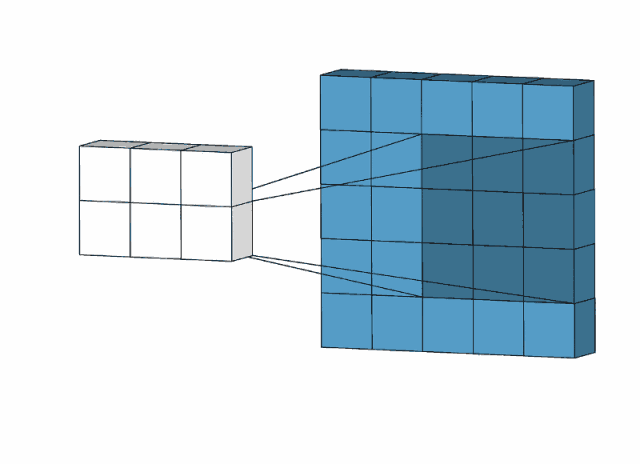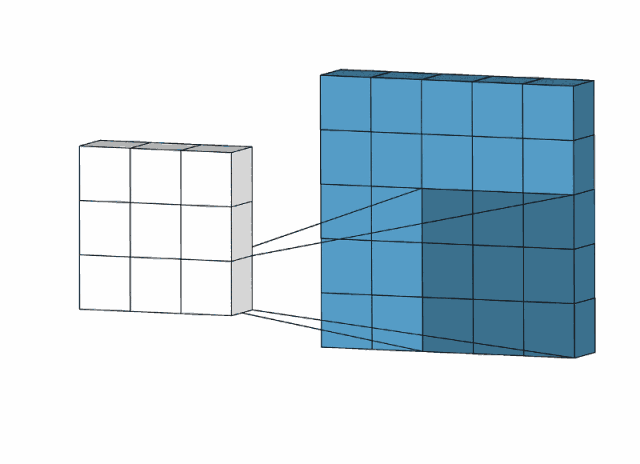
根据动画演示可以大概看出卷积层的工作方式和特点
1.局部连接。得出的数据并非要所有的输入数据参加,只选取局部的数据,通过卷积核来进行计算,极大的减少了运算量的大小。
2.参数共享。卷积核的使用,输入数据都会通过一个卷积核去进行计算得出结果。进一步的减少权重。
卷积的使用
卷积核
- 全连接层中的连接方式为权重连接,卷积层中也有着类似的结构,只不过有着不一样的名字,叫做:卷积核。
- 卷积核不同于权重连接,它更像是对于输入数据的一种映射,缩小数据的体积(大小)。下面是卷积核的工作原理演示。
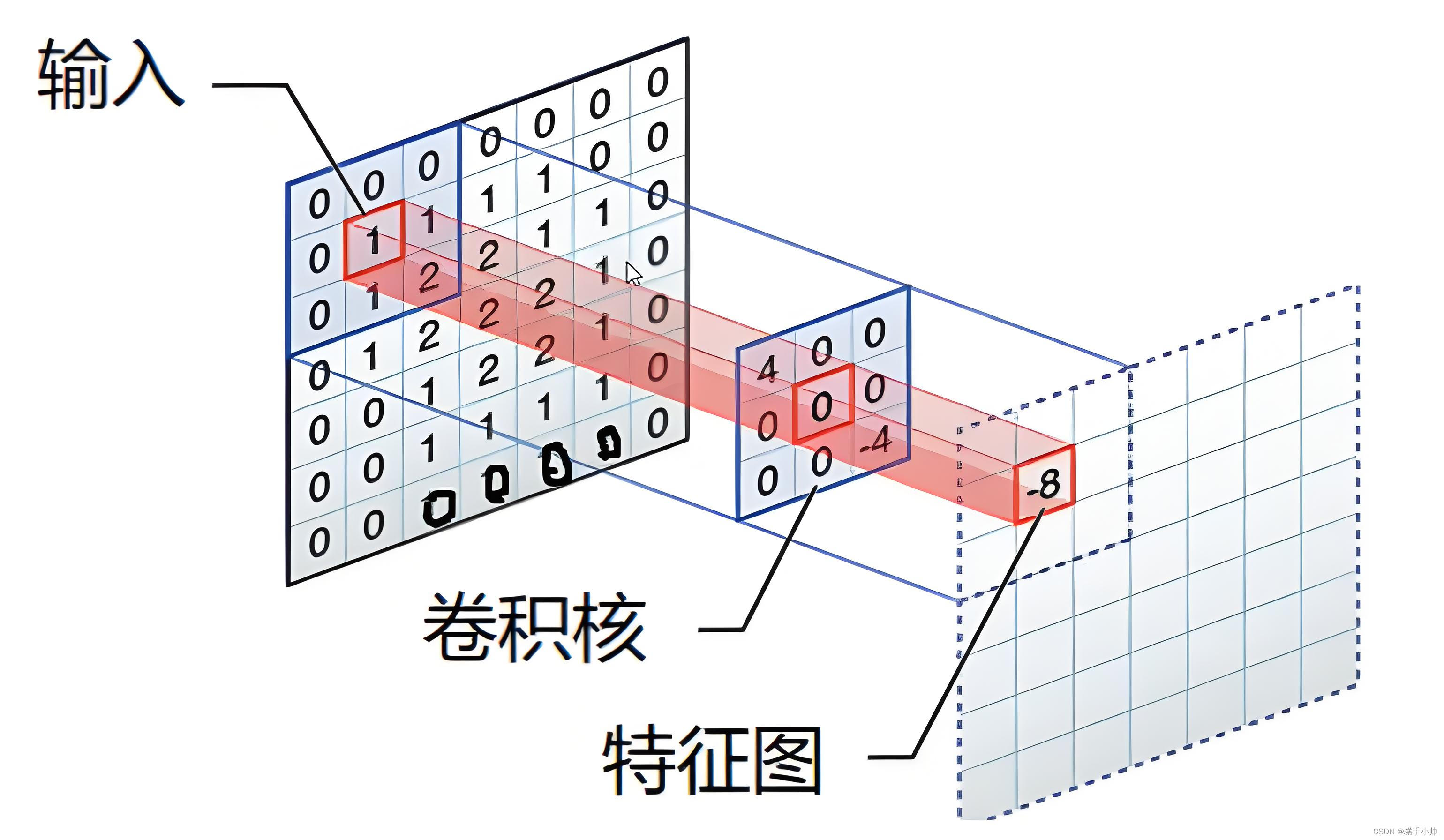
卷积核的运算:answer = 04+00+00+00+10+10+00+10+2*(-4)
通俗说,就是输入层与卷积层的对位相乘。每次计算完成之后,卷积核还会进行移动。
移动的大小称之为步长。
卷积核工作代码实现
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0]])
kernel = torch.tensor([[1, 0, 1],
[0, 1, 0],
[1, 2, 1]])
#更改数据的维度(输入矩阵的个数,矩阵的通道数,矩阵的长,矩阵的宽)
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
#步长为1
output1 = F.conv2d(input, kernel, stride=1)
print(output1)
#步长为2
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
卷积核处理数据的填充问题
- 在处理数据时,会遇到数据的尺寸不满足卷积核的计算大小。这个时候,应当对输入数据进行填充,扩大数据尺寸,利于数据计算。
- 填充效果

填充之后,数据就满足了卷积核的尺寸,不会造成数据丢失的问题
代码实现
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 1, 1, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 1, 1, 1],
[0, 0, 1, 1, 0],
[0, 1, 1, 0, 0]])
kernel = torch.tensor([[1, 0, 1],
[0, 1, 0],
[1, 2, 1]])
#更改数据的维度(输入矩阵的个数,矩阵的通道数,矩阵的长,矩阵的宽)
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
#步长为3,填充为2
output1 = F.conv2d(input, kernel, stride=3, padding=2)
print(output1)
池化层
在对图像进行处理的过程中,要对图像进行缩小或者特征提取等操作。实现这种操作方法就是利用池化层来实现。常见的池化方法有:最大池化和平均池化。
最大池化:选取规定区域的最大值
平均池化:选取规定区域的平均值

代码展示
import torch
input = torch.tensor([[23, 7, 7, 8],
[10, 1, 9, 0],
[4, 4, 11, 6],
[2, 5, 12, 7]], dtype=torch.float32)
mp = torch.nn.MaxPool2d(kernel_size=2)
ap = torch.nn.AvgPool2d(kernel_size=2)
input = torch.reshape(input, (1, 1, 4, 4))
output1 = mp(input)
print(output1)
output2 = ap(input)
print(output2)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









