






目录
4.1.2 DataFrame通过“as[ElementType]”方法转换得到Dataset
7.1DStream 本质上就是一系列时间上连续的 RDD:
7.2 对 DStream 的数据的进行操作也是按照 RDD 为单位来进行的:
一.了解Scala语言
Scala是Scalable Language的缩写,是一种多范式的编程语言,由洛桑联邦理工学院的马丁·奥德斯在2001年基于Funnel的工作开始设计,设计初衷是想集成面向对象编程和函数式编程的各种特性。
Scala 是一种纯粹的面向对象的语言,每个值都是对象。Scala也是一种函数式语言,因此函数可以当成值使用。
由于Scala整合了面向对象编程和函数式编程的特性,因此Scala相对于Java、C#、C++等其他语言更加简洁。
Scala源代码会被编译成Java字节码,因此Scala可以运行于Java虚拟机(Java Virtual Machine,JVM)之上,并可以调用现有的Java类库。
Scala 特性:
- 面向对象
- 函数式编程
- 静态类型
- 可扩展
一.什么是spark
1.Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
二.spark的特点
① Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
② Scala语法简洁,能提供优雅的API。
③ Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
三.Spark运行架构
1.概念
① RDD:是弹性分布式数据集的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
② DAG:是有向无环图的英文缩写,反映RDD之间的依赖关系。
③ Executor:是运行在工作节点上的一个进程,负责运行任务,并为应用程序存储数据。
④ 应用:用户编写的Spark应用程序。
⑤ 任务:运行在Executor上的工作单元。
⑥ 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
⑦ 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
1.特点
每个application都有自己专属的Executor进程,并且该进程在application运行期间一直驻留,executor进程以多线程的方式运行Task
Spark运行过程与资源管理无关,子要能够获取Executor进程并保持通信即可
Task采用了数据本地性和推测执行等优化机制,实现“计算向数据靠拢”
四.RDD
概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
2.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
特性
1.高效的容错性
2.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
依赖关系
1.窄依赖指的是子RDD的一个分区只依赖于某个父RDD中的一个分区
宽依赖指的是子RDD的每一个分区都依赖于某个父RDD中一个以上的分区
运行过程
1)创建RDD对象;
2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
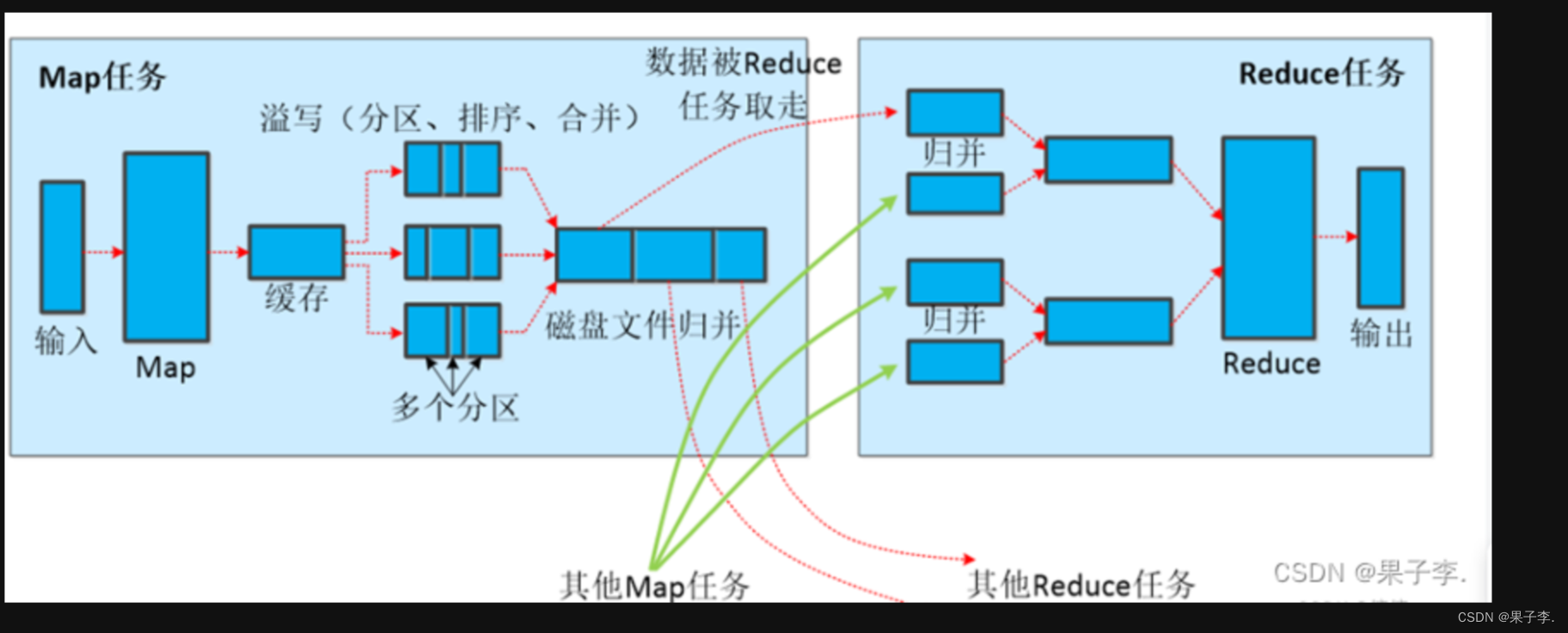
MapReduce核心环节-Shuffle过程
五.Scala安装
(1)在Windows系统上安装Scala
从Scala官网下载Scala安装包,安装包名称为“scala.msi”。

双击scala.msi安装包,开始安装软件。

进入欢迎界面,单击右下角的“Next”按钮后出现许可协议选择提示框,选择接受许可协议中的条款并单击右下角的“Next”按钮。
选择安装路径,本文Scala的安装路径选择在非系统盘的“D:\Program Files (x86)\spark\scala\” ,单击“OK”按钮进入安装界面。
(2)配置环境变量
1.右击此电脑的属性
2.选择高级系统测试

1.点击环境变量,点击path
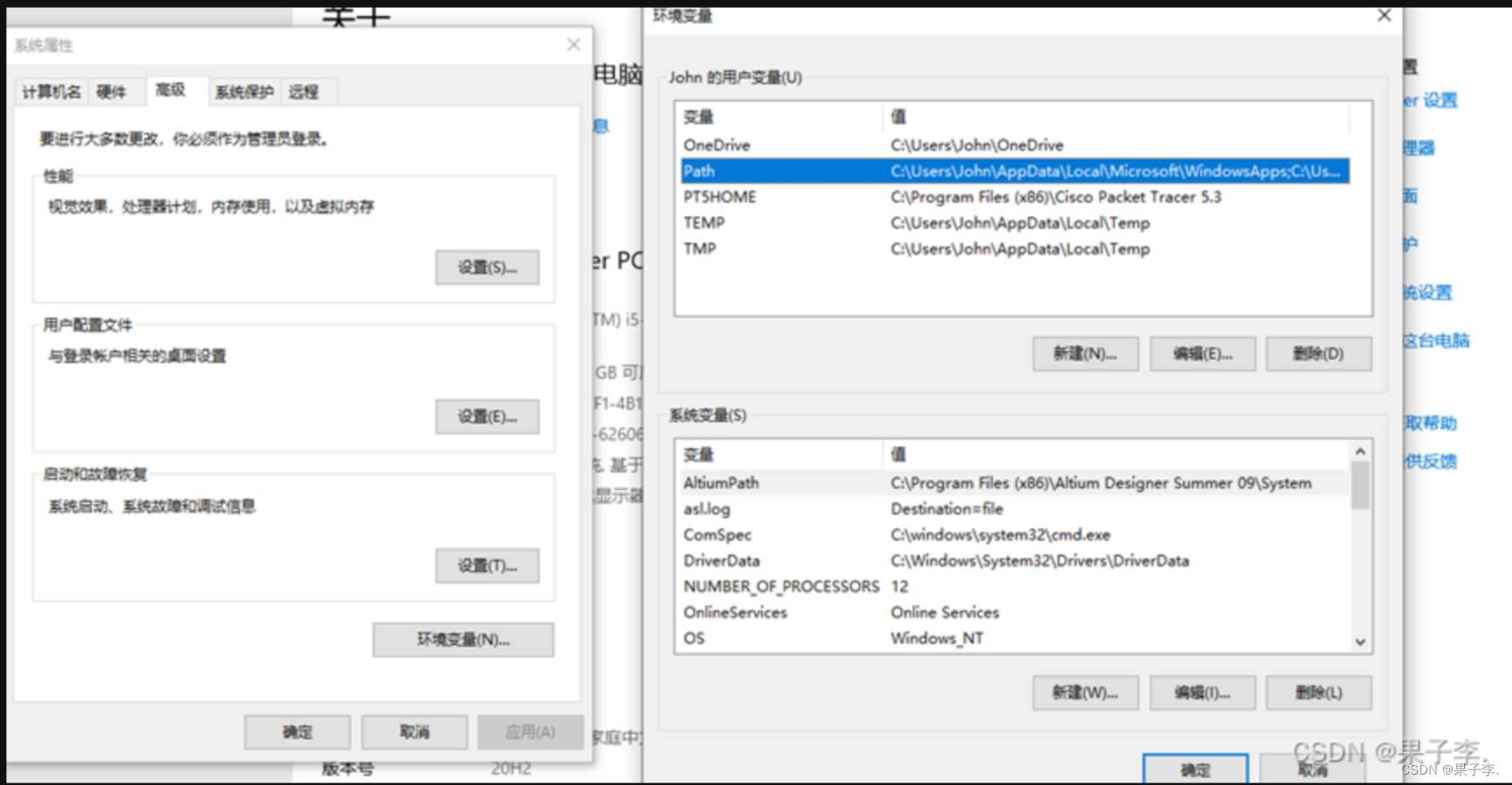
2.点击新建,打开文件夹找到scala目录下的bin
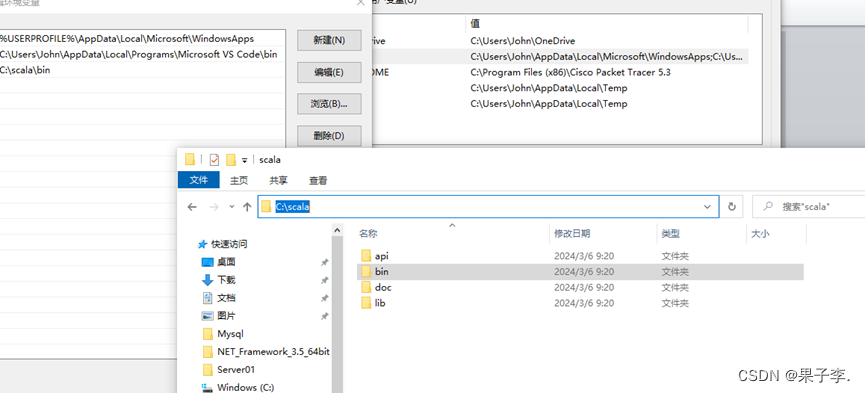
3.最后复制路径到path,点击ok环境配置就完成了
spark部署与安装
1.网上管网查找spark浏览器查看192.168.10.100:8080
2. (1)上传并解压安装spark安装包
tar -zxvf / export/ software/ spark-3.0.3-bin-hadoop2.7.tgz
(2)设置环境变量
vim /etc/profile
#SPARK
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin

source /etc/profile使环境变量生效
(3)修改配置文件.
cd spark/ conf/
先备份文件cp spark env.sh.template spark env.sh
cp slaves. template slaves
vim spark-env.sh

加一些环境变量:
修改spark- env.sh文件,加以下内容:
export SCALA_HOME=/usr/local/soft/scala-2.12.12
export JAVA_HOME=/usr/local/soft/jdk1.8.0_202
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.3/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070
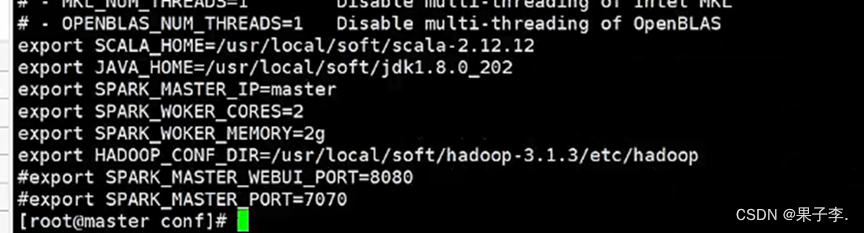
修改从节点ip
vi slaves 修改内容为slave1 slave2(我的子机分别为是slave1 slave2)

(4)分发文件
scp -r /usr/local/soft/spark-3.0.3/ slave1:/usr/local/soft/
(5)分别在slave1 slave2上设置环境变量
vim /etc/profile
#SPARK
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/binexport PATH=$PATH:${SPARK_HOME}/sbin

source /etc/profile使环境变量生效
(6)启动集群:spark目录下:./start-all.sh

查看节点:
Master:
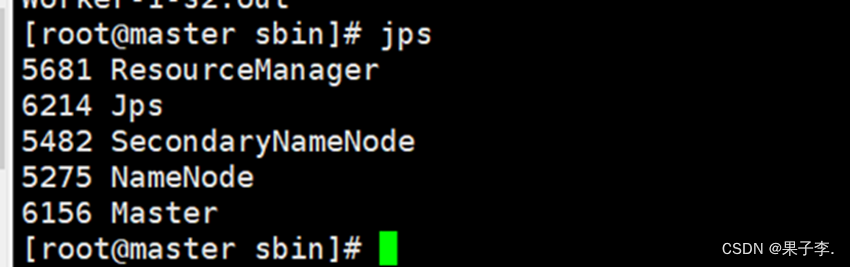
Slave1:
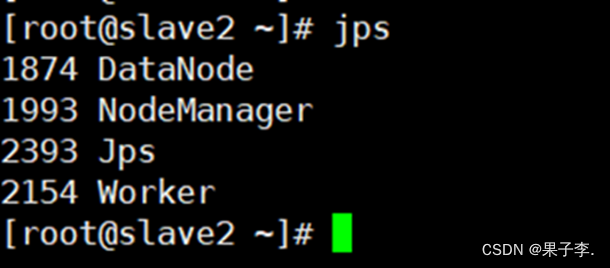
Scala2:

在主节点master上出现Master 在s1上出现Worker在s2上出现Worker Spark-shell
六.定义函数识别号码类型
1.了解数据类型
2. Scala常用数据类型
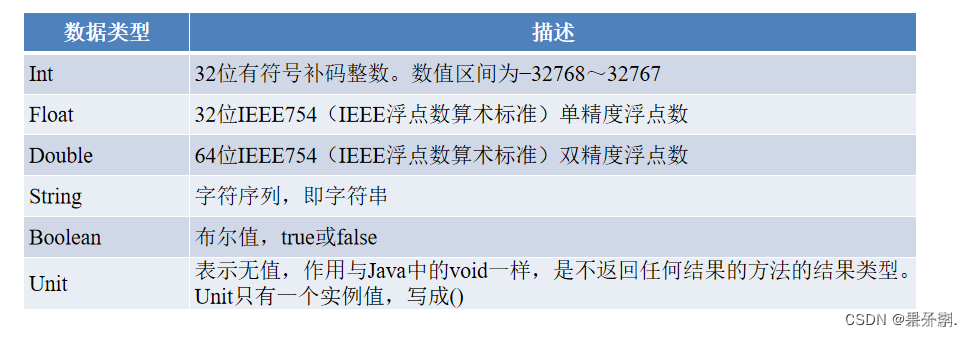
- Scala会区分不同类型的值,并且会基于使用值的方式确定最终结果的数据类型,这称为类型推断
- Scala使用类型推断可以确定混合使用数据类型时最终结果的数据类型
- 如在加法中混用Int和Double类型时,Scala将确定最终结果为Double类型,如下图
-

3.定义与使用常量、变量
常量
在程序运行过程中值不会发生变化的量为常量或值,常量通过val关键字定义,常量一旦定义就不可更改,即不能对常量进行重新计算或重新赋值。
变量
变量是在程序运行过程中值可能发生改变的量。变量使用关键字var定义。与常量不同的是,变量定义之后可以重新被赋值。
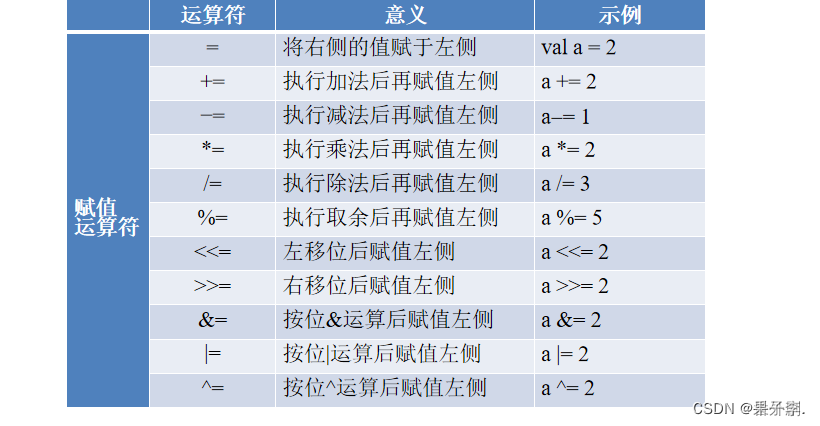
4.使用运算符


数组
七.数组常用的方法
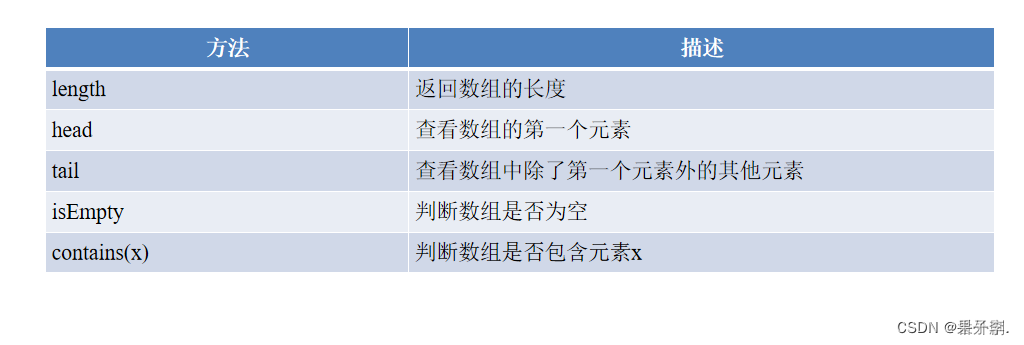
数组的使用

- Scala可以使用range()方法创建区间数组
- 使用range()方法前同样需要先通过命令“import Array._”导入包
1.定义与使用函数
函数是Scala的重要组成部分,Scala作为支持函数式编程的语言,可以将函数作为对象
Scala提供了多种不同的函数调用方式
如果函数定义在一个类中,那么可以通过“类名.方法名(参数列表)”的方式调用
2. 匿名函数
高阶函数指的是操作其他函数的函数
高阶函数可以将函数作为参数,也可以将函数作为返回值
高阶函数经常将只需要执行一次的函数定义为匿名函数并作为参数。一般情况下,匿名函数的定义是“参数列表=>表达式”
由于匿名参数具有参数推断的特性,即推断参数的数据类型,或根据表达式的计算结果推断返回结果的数据类型,因此定义高阶函数并使用匿名函数作为参数时,可以简化匿名函数的写法
3. 高阶函数—函数作为参数
高阶函数指的是操作其他函数的函数
高阶函数可以将函数作为参数,也可以将函数作为返回值
高阶函数经常将只需要执行一次的函数定义为匿名函数并作为参数。一般情况下,匿名函数的定义是“参数列表=>表达式”
由于匿名参数具有参数推断的特性,即推断参数的数据类型,或根据表达式的计算结果推断返回结果的数据类型,因此定义高阶函数并使用匿名函数作为参数时,可以简化匿名函数的写法
4.高阶函数—函数作为返回值
- 高阶函数可以产生新的函数,并将新的函数作为返回值
- 定义高阶函数计算矩形的周长,该函数传入一个Double类型的值作为参数,返回以一个Double类型的值作为参数的函数,如下图


Scala可以使用range()方法创建区间数组。
使用range()方法前同样需要先通过命令“import Array._”导入包
列表操作常用方法
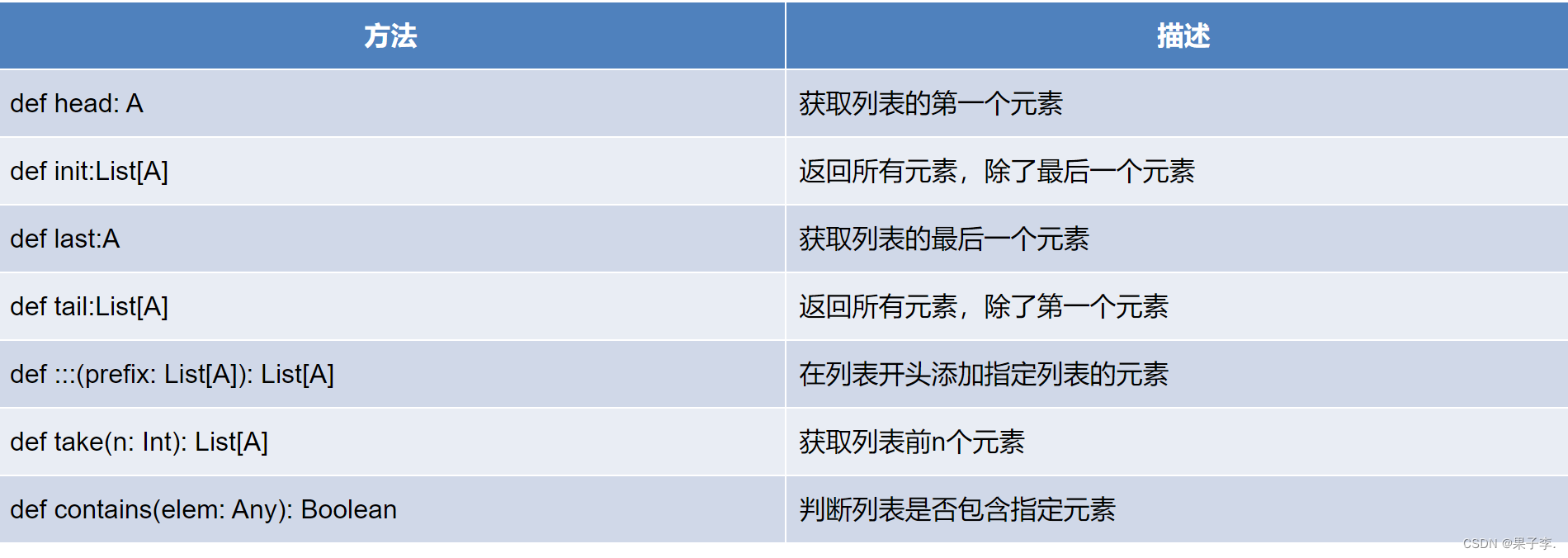
Scala中常用的查看列表元素的方法有head、init、last、tail和take()。
•head:查看列表的第一个元素。
•tail:查看第一个元素之后的其余元素。
•last:查看列表的最后一个元素。
•Init:查看除最后一个元素外的所有元素。
•take():查看列表前n个元素。
合并两个列表还可以使用concat()方法。
用户可以使用contains()方法判断列表中是否包含某个元素,若列表中存在指定的元素则返回true,否则返回false。
Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。
集合操作常用方法
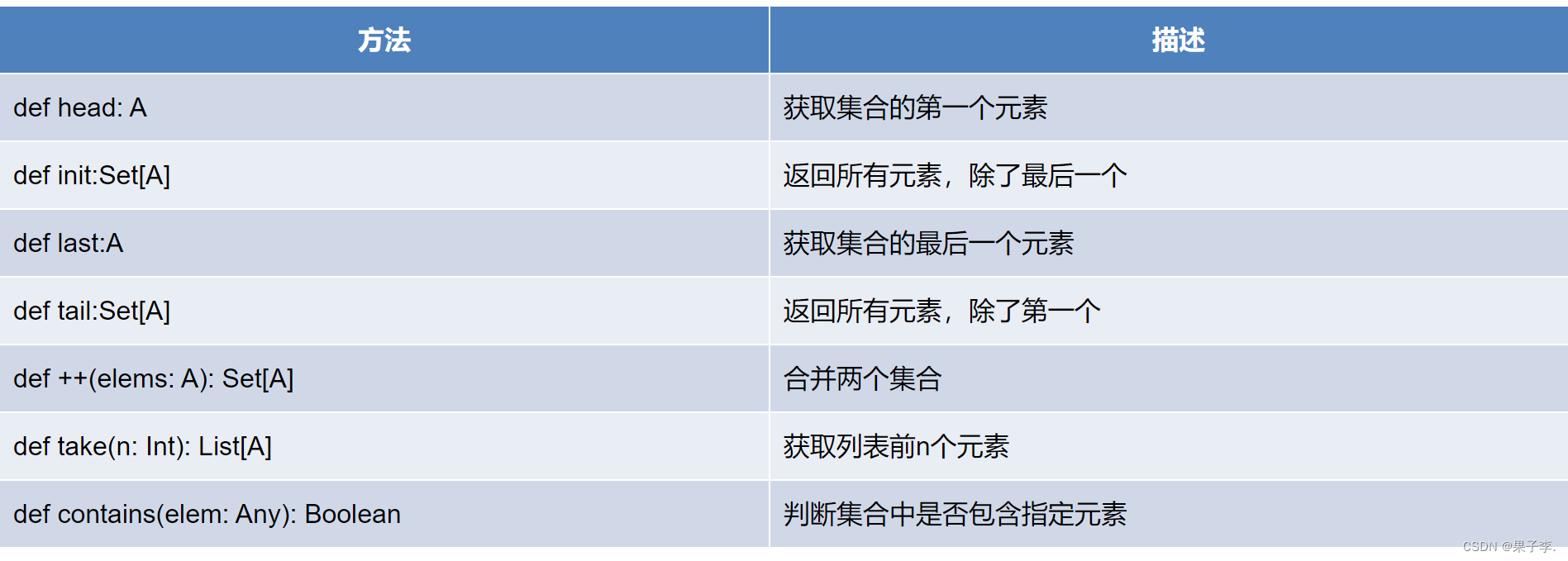
Scala合并两个列表时使用的是:::()或concat()方法,而合并两个集合使用的是++()方法。
map()方法
可通过一个函数重新计算列表中的所有元素,并且返回一个包含相同数目元素的新列表。

foreach()方法
和map()方法类似,但是foreach()方法没有返回值,只用于对参数的结果进行输出。

filter()方法
可以移除传入函数的返回值为false的元素。

flatten()方法
可以将嵌套的结构展开,即flatten()方法可以将一个二维的列表展开成一个一维的列表。

flatMap()方法
结合了map()方法和flatten()方法的功能,接收一个可以处理嵌套列表的函数,再对返回结果进行连接。

groupBy()方法
可对集合中的元素进行分组操作,返回的结果是一个映射。

groupBy()方法
从原始数据中抽取4条数据,并存放至列表phone中,使用groupBy()方法根据归属地对列表中的元素进行分组。

八.Spark SQL
1.1 Spark SQL的简介
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象结构叫做DataFrame的数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrames API和Datasets API三种方式实现对结构化数据的处理。
Spark SQL主要提供了以下三个功能:
Spark SQL可从各种结构化数据源中读取数据,进行数据分析。
Spark SQL包含行业标准的JDBC和ODBC连接方式,因此它不局限于在Spark程序内使用SQL语句进行查询。
Spark SQL可以无缝地将SQL查询与Spark程序进行结合,它能够将结构化数据作为Spark中的分布式数据集(RDD)进行查询。
Hive 是将 SQL 转为 MapReduce。
SparkSQL 可以理解成是将 SQL 解析成:“RDD + 优化” 再执行
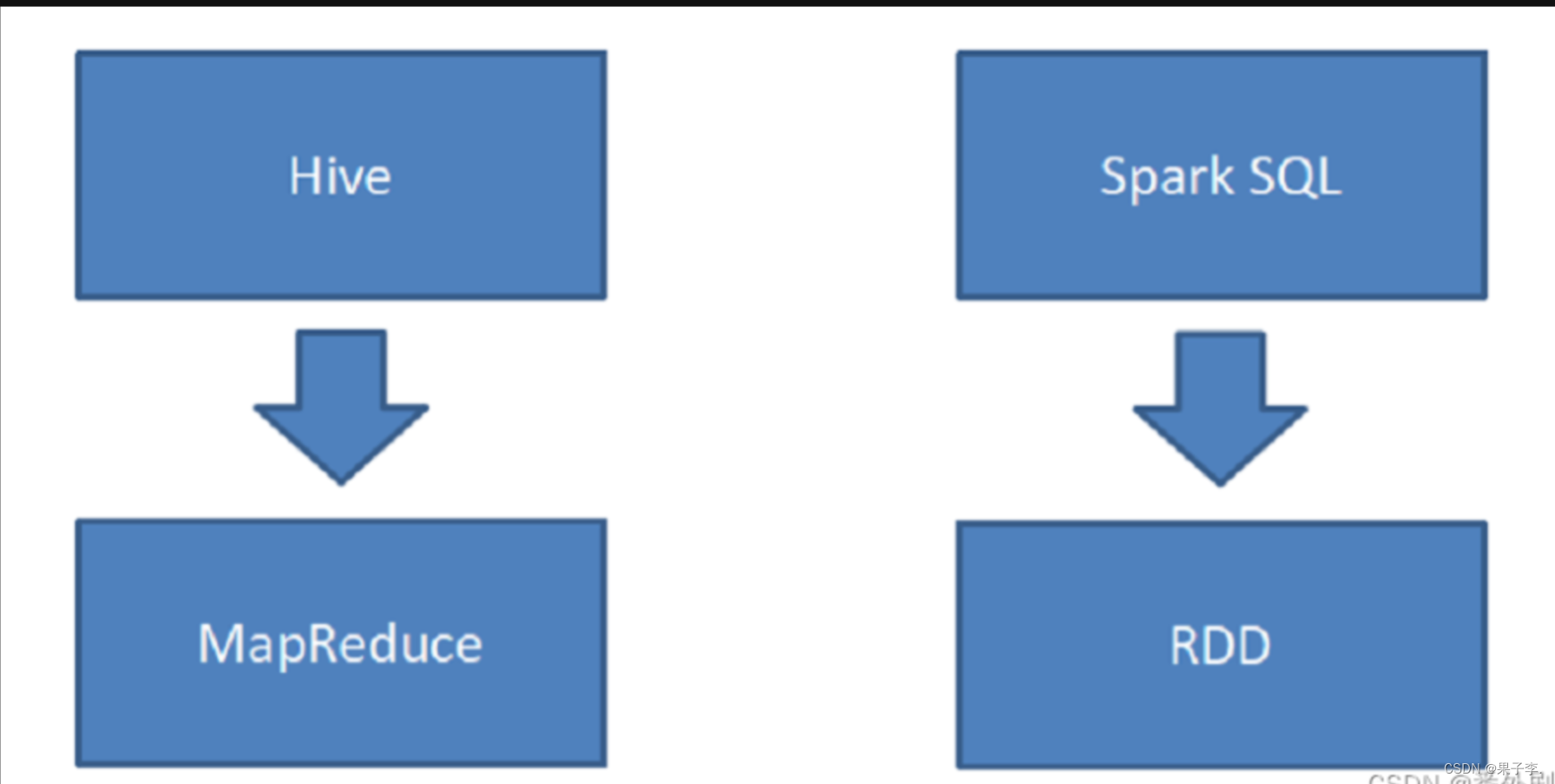
在学习Spark SQL前,需要了解数据分类

总结:
RDD 主要用于处理非结构化数据 、半结构化数据、结构化;
SparkSQL 是一个既支持 SQL 又支持命令式数据处理的工具;
SparkSQL 主要用于处理结构化数据(较为规范的半结构化数据也可以处理)
2.Spark SQL架构
Spark SQL架构与Hive架构相比,把底层的MapReduce执行引擎更改为Spark,还修改了Catalyst优化器,Spark SQL快速的计算效率得益于Catalyst优化器。从HiveQL被解析成语法抽象树起,执行计划生成和优化的工作全部交给Spark SQL的Catalyst优化器进行负责和管理。
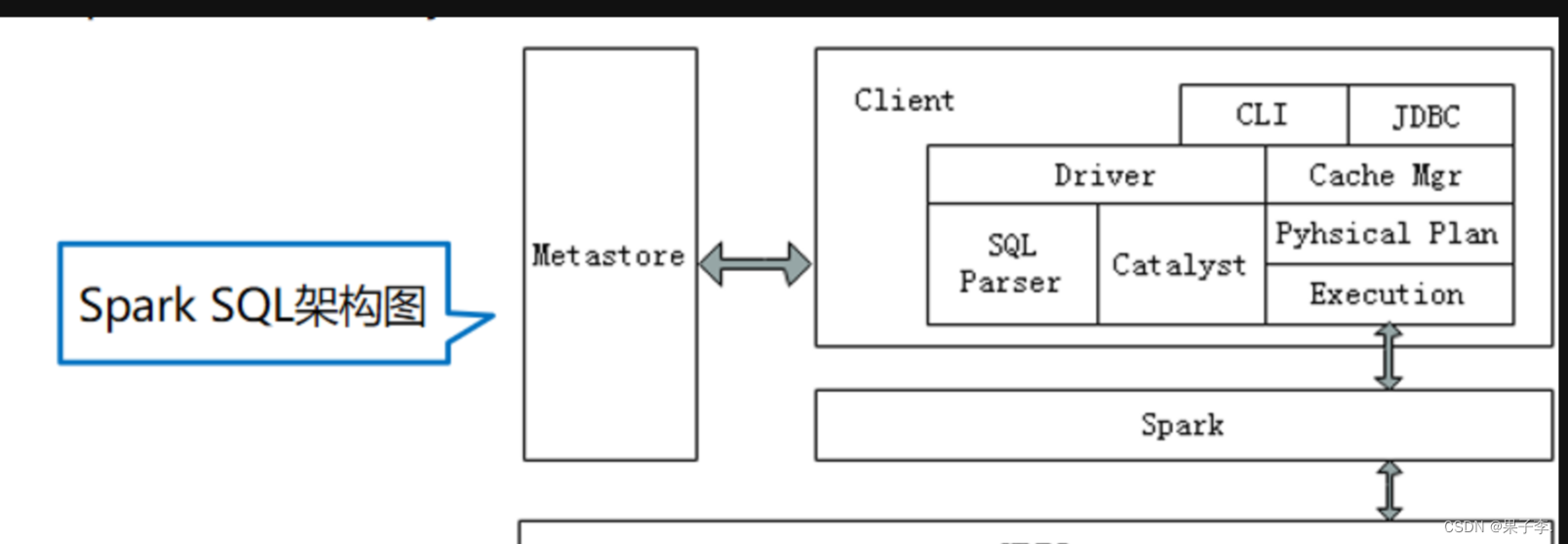
Spark要想很好地支持SQL,需要完成解析(Parser)、优化(Optimizer)、执行(Execution)三大过程。
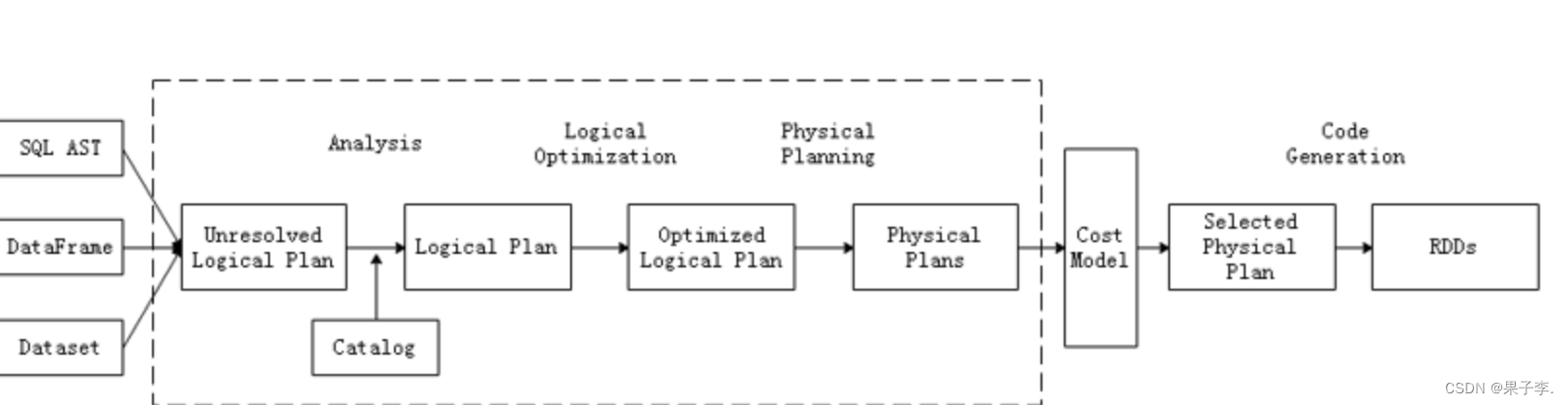
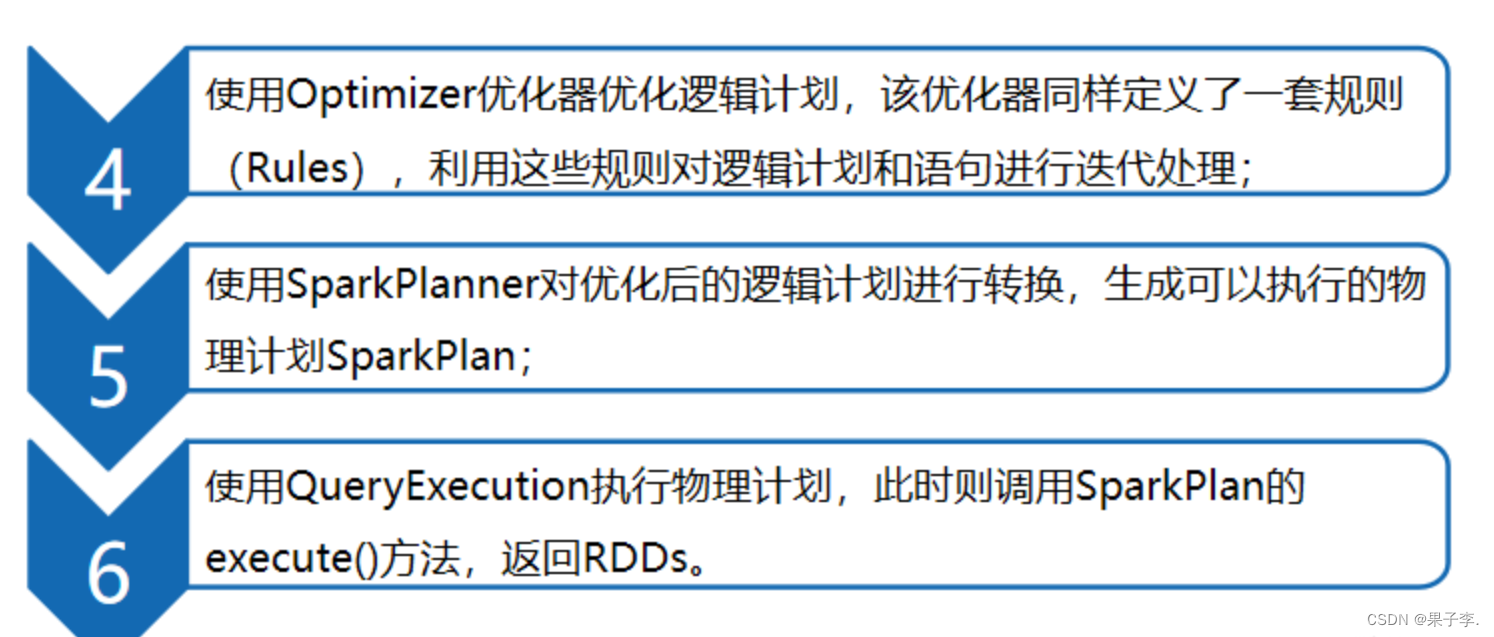
Catalyst优化器在执行计划生成和优化的工作时,离不开内部的五大组件。
SqlParse:完成SQL语法解析功能,目前只提供了一个简单的SQL解析器。
Analyze:主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据进行绑定,生成Resolved LogicalPlan。
Optimizer:对Resolved Lo;gicalPlan进行优化,生成OptimizedLogicalPlan。
Planner:将LogicalPlan转换成PhysicalPlan。
CostModel:主要根据过去的性能统计数据,选择最佳的物理执行计划

二、DataFrame概述
2.1DataFrame简介
Spark SQL使用的数据抽象并非是RDD,而是DataFrame。
在Spark 1.3.0版本之前,DataFrame被称为SchemaRDD。
DataFrame使Spark具备处理大规模结构化数据的能力。
在Spark中,DataFrame是一种以RDD为基础的分布式数据集。
DataFrame的结构类似传统数据库的二维表格,可以从很多数据源中创建,如结构化文件、外部数据库、Hive表等数据源。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
2.2 Spark SQL数据抽象
2.2.1 DataFrame 和 DataSet
Spark SQL数据抽象可以分为两类:
DataFrame:DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,带有 Schema 元信息(可以理解为数据库的列名和类型)。DataFrame = RDD + 泛型 + SQL 的操作 + 优化
DataSet:DataSet是DataFrame的进一步发展,它比RDD保存了更多的描述信息,概念上等同于关系型数据库中的二维表,它保存了类型信息,是强类型的,提供了编译时类型检查。调用 Dataset 的方法先会生成逻辑计划,然后被 spark 的优化器进行优化,最终生成物理计划,然后提交到集群中运行!DataFrame = Dateset[Row]
2.3 DataFrame的创建
创建DataFrame的两种基本方式:
已存在的RDD调用toDF()方法转换得到DataFrame。
通过Spark读取数据源直接创建DataFrame。
若使用SparkSession方式创建DataFrame,可以使用spark.read从不同类型的文件中加载数据创建DataFrame。spark.read的具体操作,在创建Dataframe之前,为了支持RDD转换成Dataframe及后续的SQL操作,需要导入import.spark.implicits._包启用隐式转换。若使用SparkSession方式创建Dataframe,可以使用spark.read操作,从不同类型的文件中加载数据创建DataFrame。

2.3.1 数据准备

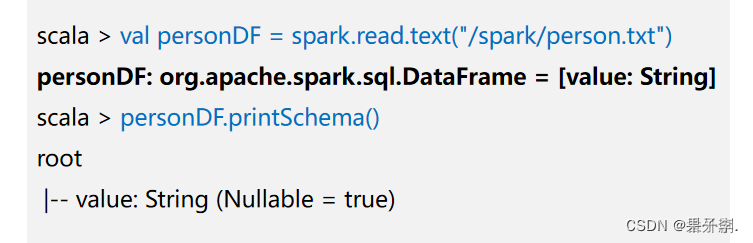
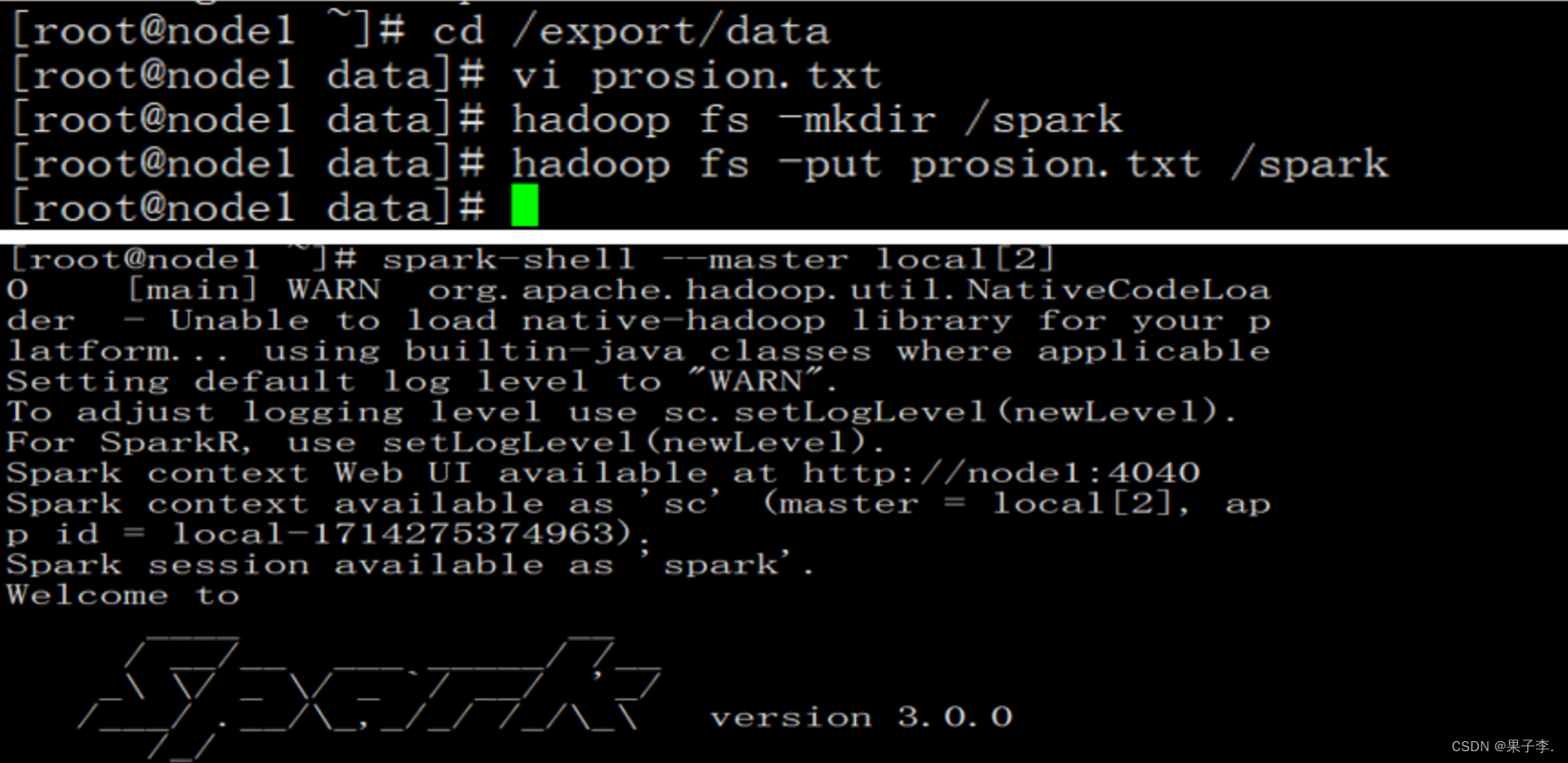
在HDFS文件系统中的/spark目录中有一个person.txt文件,内容如下:
2.3.2通过文件直接创建DataFrame
我们通过Spark读取数据源的方式进行创建DataFrame

2.3.3 RDD直接转换为DataFrame

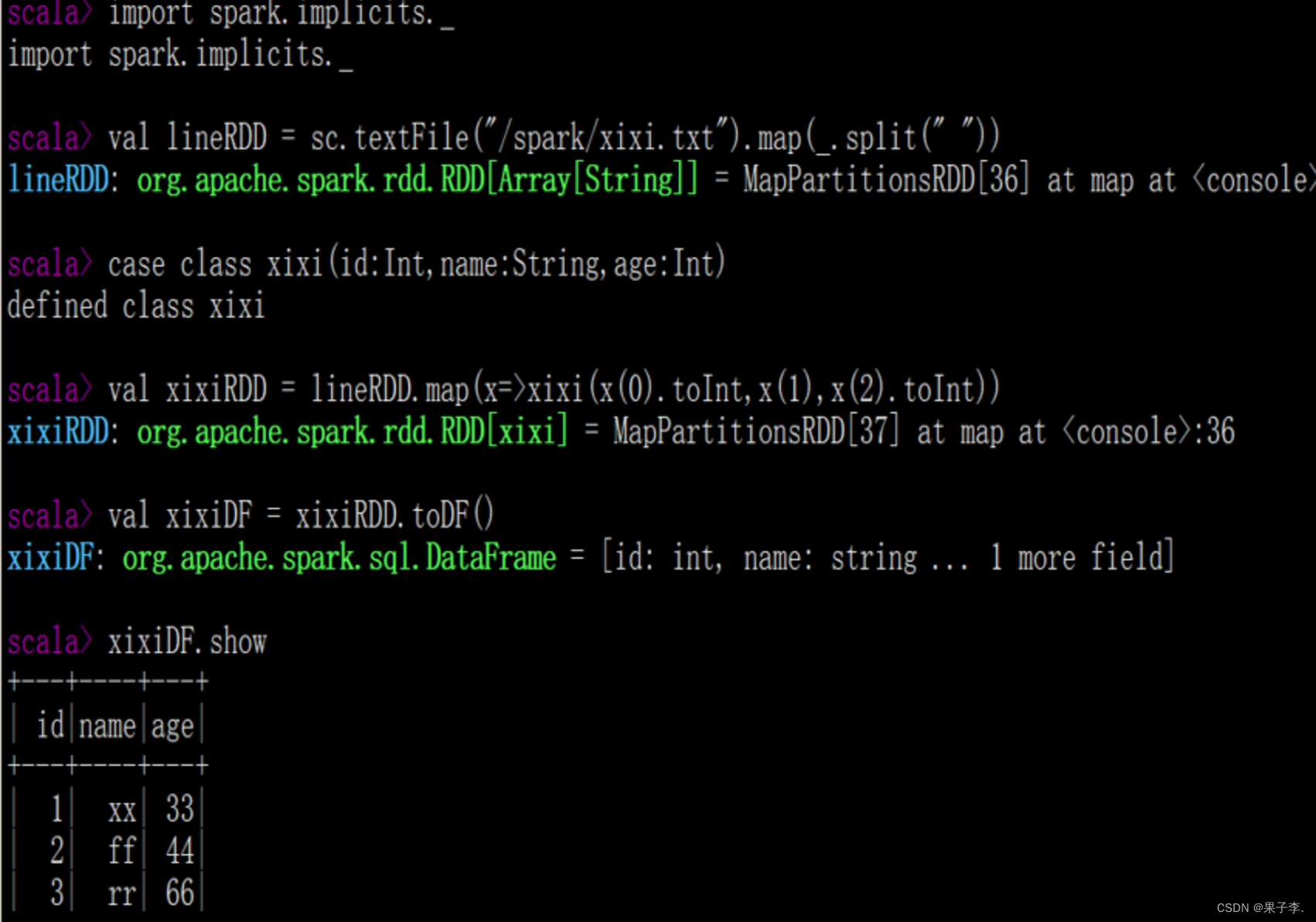
2.4 DataFrame的常用操作
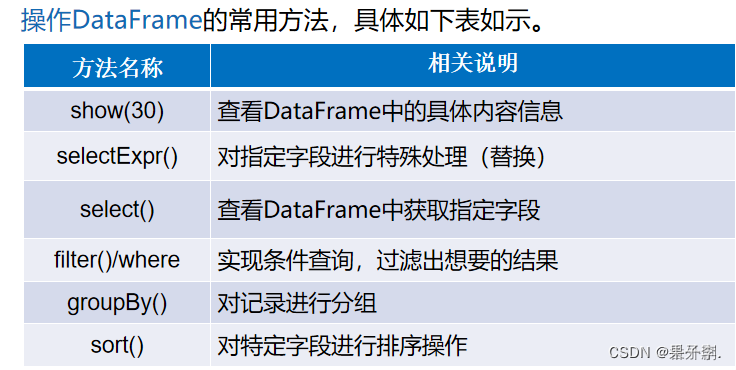
Dataframe提供了两种谮法风格,即DSL风格语法和SQL风格语法,二者在功能上并无区别,仅仅是根据用户习惯自定义选择操作方式。接下来,我们通过两种语法风格,分讲解Dstaframe操作的具体方法:
2.4.1 DSL风格操作
DataFrame提供了一个领域特定语言(DSL)以方便操作结构化数据,下面将针对DSL操作风格,讲解DataFrame 常用操作示例:
show():查看DataFrame中的具体内容信息
pritSchema0:查看0staFrame的Schema信息
select():查看DataFmame中造取部分列的数据
DSL风格示例:

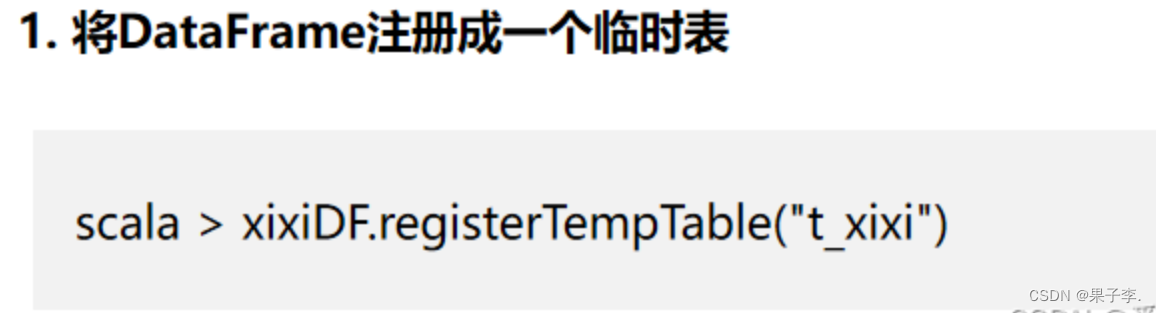
2.4.2 SQL风格操作DataFrame



SQL 风格示例:

总结:
DataFrame 和 DataSet 都可以通过RDD来进行创建;
也可以通过读取普通文本创建–注意:直接读取没有完整的约束,需要通过 RDD+Schema;
通过 josn/parquet 会有完整的约束;
不管是 DataFrame 还是 DataSet 都可以注册成表,之后就可以使用 SQL 进行查询了! 也可以使用 DSL
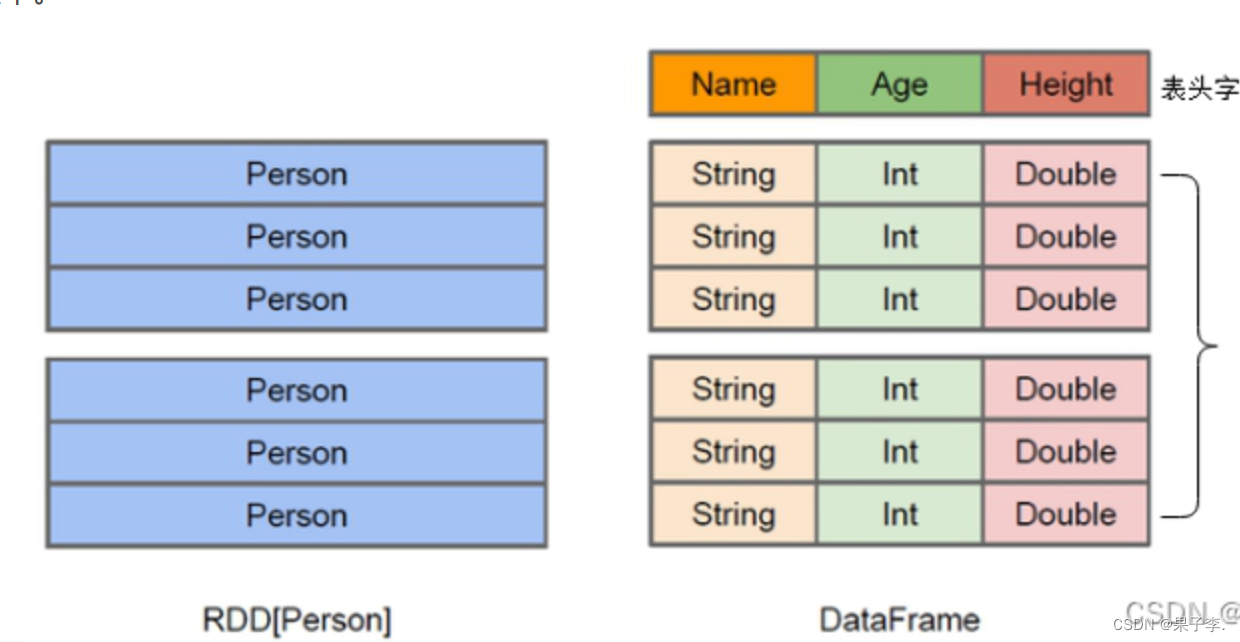
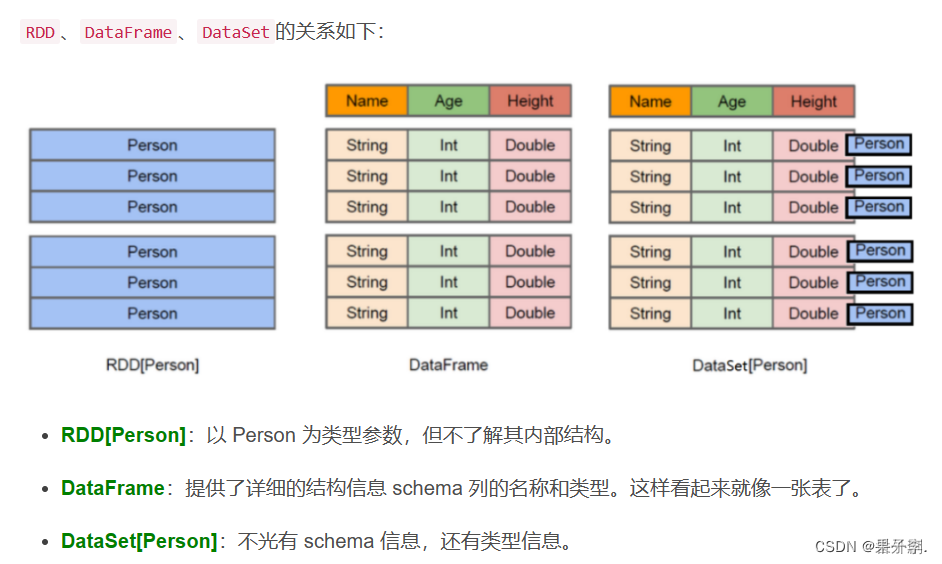
九、RDD、DataFrame及Dataset的区别
RDD数据的表现形式,如下图。此时RDD数据没有数据类型和元数据信息。

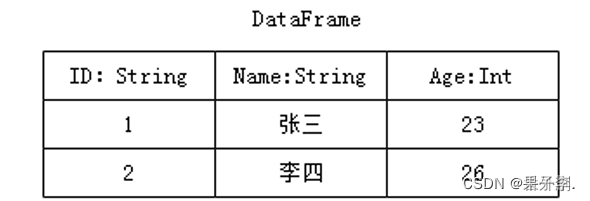
DataFrame数据的表现形式,如下图。此时DataFrame数据中添加Schema元数据信息(列名和数据类型,如ID:String),DataFrame每行类型固定为Row类型,每列的值无法直接访问,只有通过解析才能获取各个字段的值。
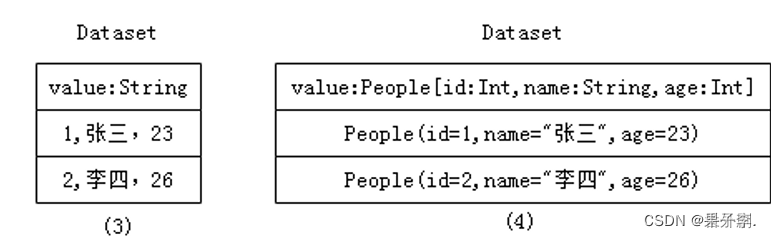
Dataset数据的表现形式,序号(3)和(4),其中序号(3)是在RDD每行数据的基础之上,添加一个数据类型(value:String)作为Schema元数据信息。而序号(4)每行数据添加People强数据类型,在Dataset[Person]中里存放了3个字段和属性,Dataset每行数据类型可自定义,一旦定义后,就具有错误检查机制。
十、Dataset概述
4.1 Dataset对象的创建
4.1.1 通过SparkSession中的createDataset来创建Dataset

4.1.2 DataFrame通过“as[ElementType]”方法转换得到Dataset

十一、RDD转换DataFrame
Spark官方提供了两种方法实现从RDD转换得到DataFrame。
第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知数据结构的RDD转换
第二种方法通过编程接口构造一个Schema,并将其应用在已知的RDD数据中
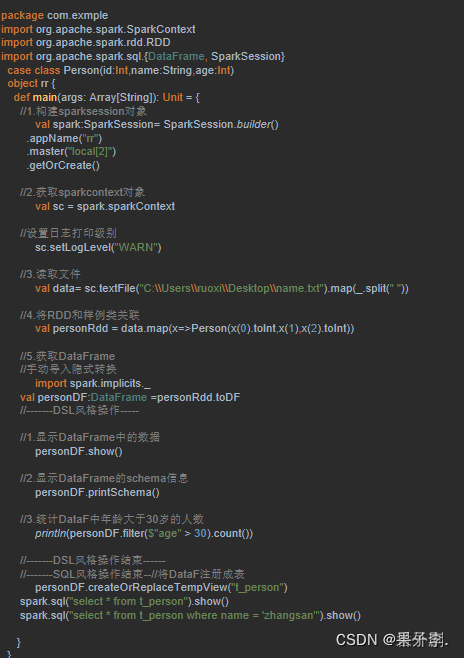
5.1 反射机制推断Schema
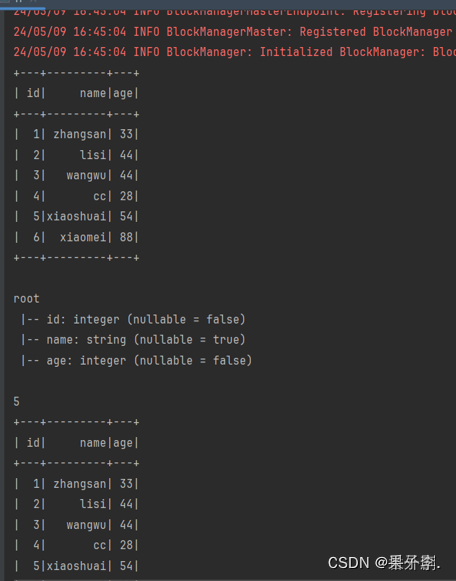
Windows系统开发Scala代码,可使用本地环境测试(需要先准备本地数据文件)。我们可以很容易的分析出当前数据文件中字段的信息,但计算机无法直观感受字段的实际含义,因此需要通过反射机制来推断包含特定类型对象的Schema信息,实现将RDD转换成DataFrame。

5.1.1 创建Maven工程
依赖

效果
5.1.2 编程方式定义Schema
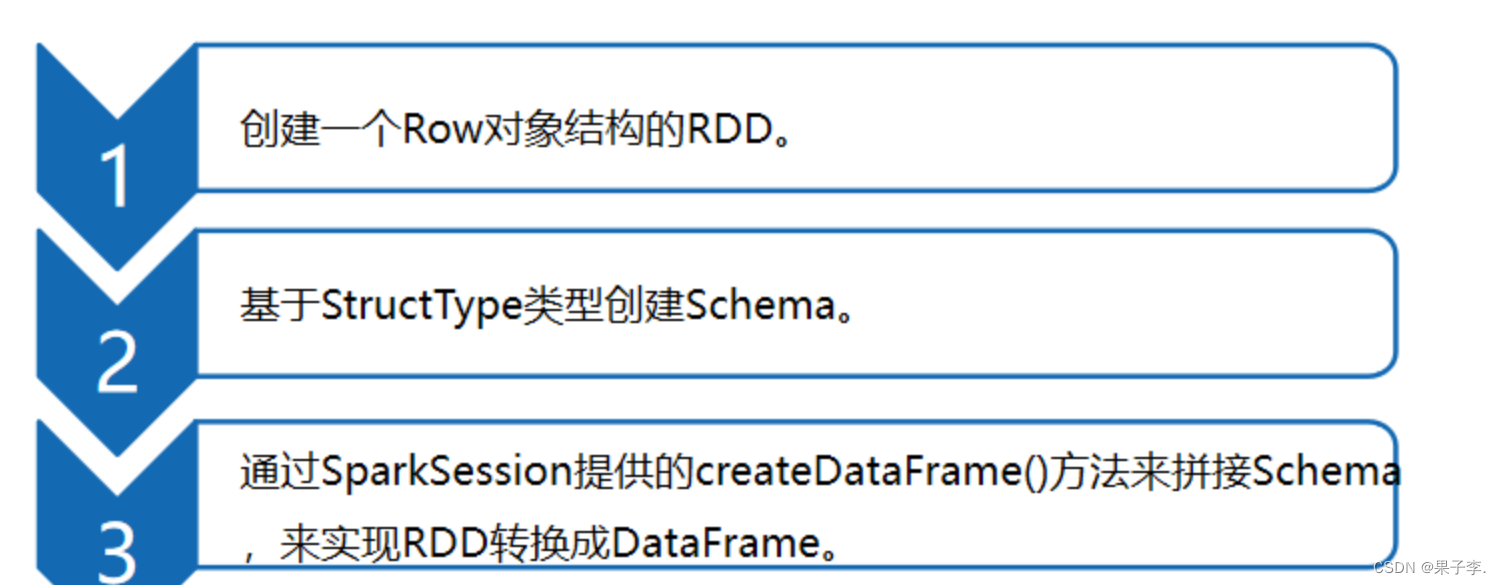
当Case类不能提前定义Schema时,就需要采用编程方式定义Schema信息,实现RDD转换DataFrame的功能。
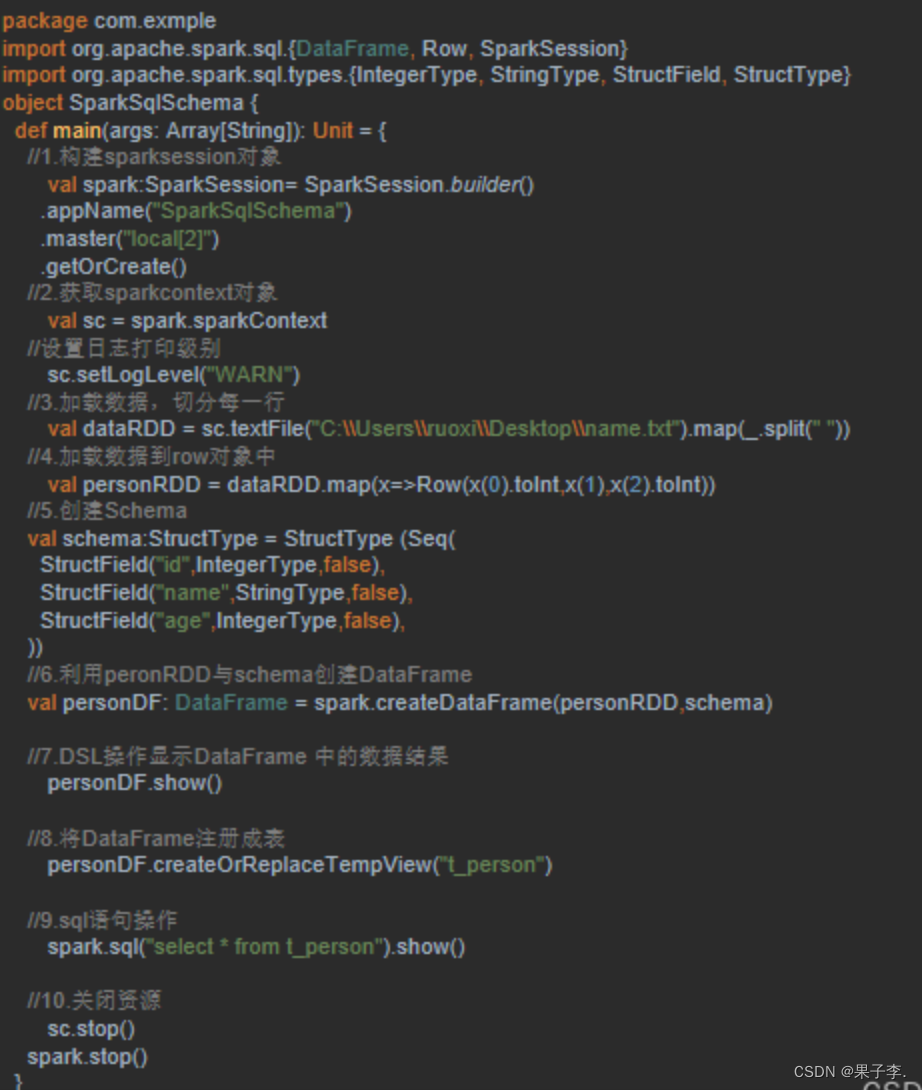
十二、Spark SQL 多数据源交互
读取文件
读取 json 文件:

读取 csv 文件:

读取 parquet 文件:

读取 mysql 表:

写入文件
写入 json 文件:

写入 csv 文件:

写入 parquet 文件:

写入 mysql 表:

十三、数据抽象
Spark Streaming 的基础抽象是 DStream(Discretized Stream,离散化数据流,连续不断的数据流),代表持续性的数据流和经过各种 Spark 算子操作后的结果数据流。
可以从以下多个角度深入理解 DStream:
7.1DStream 本质上就是一系列时间上连续的 RDD:
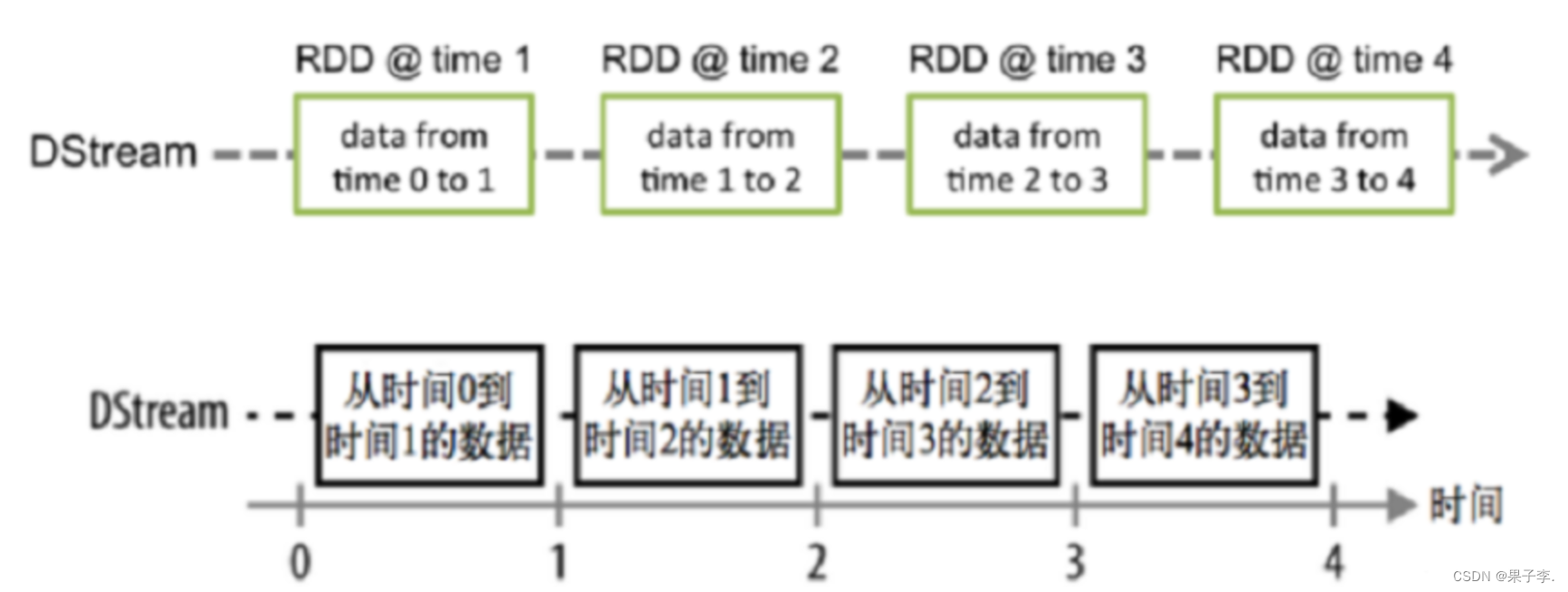
7.2 对 DStream 的数据的进行操作也是按照 RDD 为单位来进行的:

7.3 容错性
底层 RDD 之间存在依赖关系,DStream 直接也有依赖关系,RDD 具有容错性,那么 DStream 也具有容错性。
7.4 准实时性/近实时性
Spark Streaming 将流式计算分解成多个 Spark Job,对于每一时间段数据的处理都会经过 Spark DAG 图分解以及 Spark 的任务集的调度过程。
对于目前版本的 Spark Streaming 而言,其最小的 Batch Size 的选取在 0.5~5 秒钟之间。
所以 Spark Streaming 能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合。















 163
163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









