






大数据处理与分析-Spark
一.什么是spark
1.Spark 是当今大数据领域最活跃、最热门、最高效的大数据通用计算平台之一。
二.spark的特点
① Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统。
② Scala语法简洁,能提供优雅的API。
③ Scala兼容Java,运行速度快,且能融合到Hadoop生态圈中。
三.Spark运行架构
1.概念
① RDD:是弹性分布式数据集的英文缩写,是分布式内存的一个抽象概念,提供了一种高度受限的共享内存模型。
② DAG:是有向无环图的英文缩写,反映RDD之间的依赖关系。
③ Executor:是运行在工作节点上的一个进程,负责运行任务,并为应用程序存储数据。
④ 应用:用户编写的Spark应用程序。
⑤ 任务:运行在Executor上的工作单元。
⑥ 作业:一个作业包含多个RDD及作用于相应RDD上的各种操作。
⑦ 阶段:是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为“阶段”,或者也被称为“任务集”
1.特点
每个application都有自己专属的Executor进程,并且该进程在application运行期间一直驻留,executor进程以多线程的方式运行Task
Spark运行过程与资源管理无关,子要能够获取Executor进程并保持通信即可
Task采用了数据本地性和推测执行等优化机制,实现“计算向数据靠拢”
四.RDD
概念
1.一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,不同节点上进行并行计算
2.RDD提供了一种高度受限的共享内存模型,RDD是只读的记录分区集合,不能直接修改,只能通过在转换的过程中改
特性
1.高效的容错性
2.中间结果持久化到内存,数据在内存中的多个RDD操作直接按进行传递,避免了不必要的读写磁盘开销
3.存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
依赖关系
1.窄依赖指的是子RDD的一个分区只依赖于某个父RDD中的一个分区
宽依赖指的是子RDD的每一个分区都依赖于某个父RDD中一个以上的分区
运行过程
1)创建RDD对象;
2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
3)DAGScheduler负责把DAG图分解成多个Stage,每个Stage中包含了多个Task,每个Task会被TaskScheduler分发给各个WorkerNode上的Executor去执行。
MapReduce核心环节-Shuffle过程

Scala安装
(1)在Windows系统上安装Scala

- 从Scala官网下载Scala安装包,安装包名称为“scala.msi”。

- 双击scala.msi安装包,开始安装软件。

- 进入欢迎界面,单击右下角的“Next”按钮后出现许可协议选择提示框,选择接受许可协议中的条款并单击右下角的“Next”按钮。
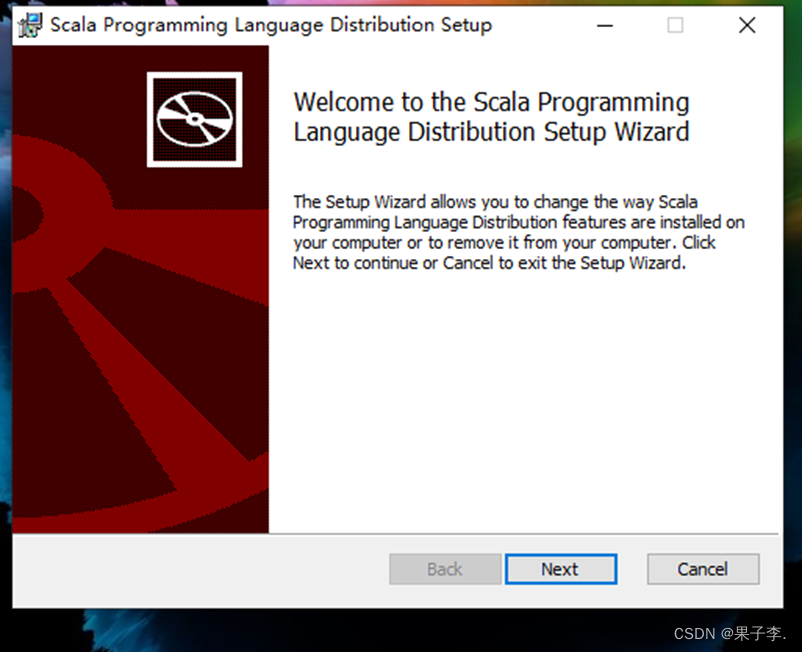
- 选择安装路径,本文Scala的安装路径选择在非系统盘的“D:\Program Files (x86)\spark\scala\” ,单击“OK”按钮进入安装界面。
(2)配置环境变量
1.右击此电脑的属性

2.选择高级系统测试

1.点击环境变量,点击path

2.点击新建,打开文件夹找到scala目录下的bin
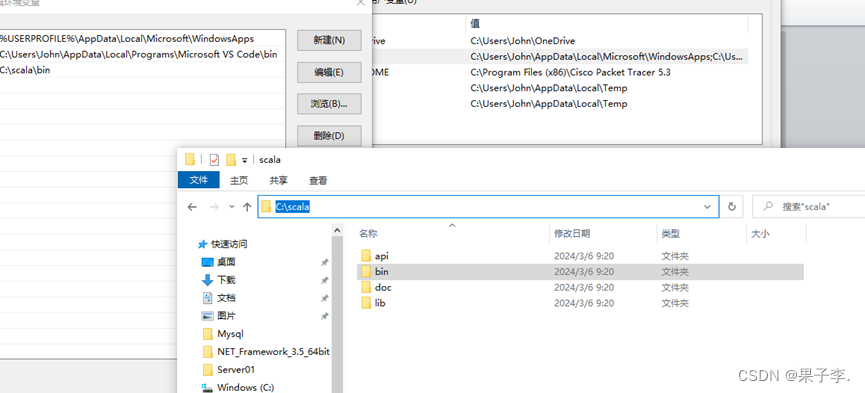
3.最后复制路径到path,点击ok环境配置就完成了
spark部署与安装
1.网上管网查找spark浏览器查看192.168.10.100:8080

2. (1)上传并解压安装spark安装包
tar -zxvf / export/ software/ spark-3.0.3-bin-hadoop2.7.tgz
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/bin
export PATH=$PATH:${SPARK_HOME}/sbin

先备份文件cp spark env.sh.template spark env.sh

export SCALA_HOME=/usr/local/soft/scala-2.12.12
export JAVA_HOME=/usr/local/soft/jdk1.8.0_202
export SPARK_MASTER_IP=master
export SPARK_WOKER_CORES=2
export SPARK_WOKER_MEMORY=2g
export HADOOP_CONF_DIR=/usr/local/soft/hadoop-3.1.3/etc/hadoop
#export SPARK_MASTER_WEBUI_PORT=8080
#export SPARK_MASTER_PORT=7070

vi slaves 修改内容为slave1 slave2(我的子机分别为是slave1 slave2)

scp -r /usr/local/soft/spark-3.0.3/ slave1:/usr/local/soft/
(5)分别在slave1 slave2上设置环境变量
export SPARK_HOME=/usr/local/soft/spark-3.0.3
export PATH=$PATH:${SPARK_HOME}/binexport PATH=$PATH:${SPARK_HOME}/sbin

(6)启动集群:spark目录下:./start-all.sh



















 6936
6936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









