






 本文介绍了ApacheHadoop生态系统的八个关键组件:Sqoop用于数据迁移,Flume负责日志收集,Kafka提供高吞吐量的消息队列,HBase是列式存储数据库,Storm支持连续计算,Spark和Flinkk是内存计算框架,Oozie管理工作流程,Hive和Impala则用于数据分析。
本文介绍了ApacheHadoop生态系统的八个关键组件:Sqoop用于数据迁移,Flume负责日志收集,Kafka提供高吞吐量的消息队列,HBase是列式存储数据库,Storm支持连续计算,Spark和Flinkk是内存计算框架,Oozie管理工作流程,Hive和Impala则用于数据分析。
▶️Hodoop 生态圈如下图示:
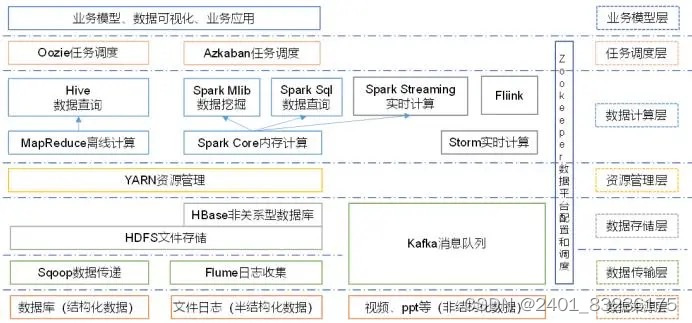
▶️其组件及作用以下详细介绍:
1️⃣ Sqoop:一款开源工具,主要用在Hadoop、Hive与传统数据库(Mysql)间进行数据传递,可以将关系型数据库数据导入到Hadoop的HDFS中,也可以从HDFS中导入关系型数据库中
2️⃣Flume:一个高可用、高可靠的分布式海量日志采集、聚合和传输系统,支持在日志系统中定制各类数据发送方,用于收集数据;
3️⃣Kafka:一种高吞吐量的分布式发布订阅消息系统;
4️⃣HBase:一个建立在HDFS之上,面向列的针对性结构化数据的可伸缩、高可靠、高性能、分布式的动态数据库,保存的数据可以使用Mapreducer来处理,将数据存储和并行计算完美的结合在一起
5️⃣Storm:对数据流做连续查询,在计算时就将结果以流动形式输出给用户,用于“连续计算”;
6️⃣Spark:一种基于内存的分布式计算框架,与Mapreducer不同的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法,内部提供了大量的库,如 Spark Sql、Spark Streaming等;
7️⃣Fiilnk:一种基于内存的分布式计算框架,用于实时计算场景较多;
8️⃣Oozie:一个管理hadoop job 的工作流程调动管理系统,用于协调多个MapReducer任务的执行;
9️⃣Hive:基于Hadoop的一个数据仓库工具,定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。通常用于离线分析。
🔟Impala:用于处理存储在Hadoop集群中大量数据的MPP(大规模并行处理)SQL查询引擎,与Hive不同,不基于MapReducer算法。它实现了一个基于守护进程的分布式结构,负责在同一台机器上运行的查询执行所有方面,执行效率高于Hive。















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









