






深度学习框架
定义:深度学习框架是一种用于构建、训练和部署深度神经网络模型的工具集合。它提供了丰富的函数和工具,使开发者能够方便地创建、调整和优化神经网络模型。
目前常用的深度学习框架有PyTorch、Theano、TensorFlow、Keras、Caffe、MXNet、CNTK、PaddlePaddle。
PyTorch
背景:PyTorch是一个由Facebook的人工智能研究团队开发的开源深度学习框架。
优点:
1. 动态计算图
PyTorch最突出的优点之一就是它使用了动态计算图(Dynamic Computation Graphs,DCGs),与TensorFlow和其他框架使用的静态计算图不同。动态计算图允许你在运行时更改图的行为。这使得PyTorch非常灵活,在处理不确定性或复杂性时具有优势,因此非常适合研究和原型设计。
2. 易用性
PyTorch被设计成易于理解和使用。其API设计的直观性使得学习和使用PyTorch成为一件非常愉快的事情。此外,由于PyTorch与Python的深度集成,它在Python程序员中非常流行。
3. 易于调试
由于PyTorch的动态性和Python性质,调试PyTorch程序变得相当直接。你可以使用Python的标准调试工具,如PDB或PyCharm,直接查看每个操作的结果和中间变量的状态。
4. 强大的社区支持
PyTorch的社区非常活跃和支持。官方论坛、GitHub、Stack Overflow等平台上有大量的PyTorch用户和开发者,你可以从中找到大量的资源和帮助。
5. 广泛的预训练模型
PyTorch提供了大量的预训练模型,包括但不限于ResNet,VGG,Inception,SqueezeNet,EfficientNet等等。这些预训练模型可以帮助你快速开始新的项目。
6. 高效的GPU利用
PyTorch可以非常高效地利用NVIDIA的CUDA库来进行GPU计算。同时,它还支持分布式计算,让你可以在多个GPU或服务器上训练模型。
应用:
1. 计算机视觉
2. 自然语言处理
3. 生成对抗网络
4. 强化学习
5. 时序数据分析
Theano
背景:Theano本身是一个通用的符号计算框架,而不仅仅能用于深度学习。与非符号架构的框架不同,它先使用tensor variable,在内部通过图结构,将复杂的符号表达式编译成为end-to-end的函数模型,然后才传入实际数据进行计算。对用户而言,编译的过程可以实现两个功能:编译优化和自动微分。最后,Theano依赖于numpy。
优点:
- 高效的计算性能:Theano能够优化数学表达式的计算,使得在CPU或GPU上的运行更加高效。
- 自动计算梯度:Theano可以自动计算数学表达式的梯度,这对于机器学习中的反向传播算法非常重要。
- 灵活性:Theano提供了灵活的接口,支持用户自定义函数和操作,使得它能够适应各种不同的深度学习算法和模型压缩方法。
- 易于使用:Theano的API设计简洁,用户可以快速上手并构建深度学习模型。
- 广泛的支持:Theano支持多种类型的神经网络和机器学习模型,包括卷积神经网络、循环神经网络等。
缺点:
- 学习曲线:尽管Theano本身易于使用,但是其底层的优化和编译过程相对复杂,对于初学者来说可能有一定的学习难度。
- 维护状态:Theano的开发和维护在近年来已经放缓,这可能会影响到其在未来的可用性和社区支持。
- 文档更新:随着项目维护的减少,相关的文档和教程可能不会及时更新,这对于新用户来说可能是一个问题。
- 兼容性问题:由于Theano的架构和实现方式,它可能与某些最新的硬件或软件不完全兼容,这可能会导致一些技术挑战。
- 社区转移:随着其他框架如TensorFlow和PyTorch的兴起,Theano的用户和贡献者社区可能会逐渐转移到这些框架上。
TensorFlow
背景:TensorFlow 是由 Google 团队开发的深度学习框架之一,它是一个完全基于 Python 语言设计的开源的软件。
优点:
- 广泛的社区支持:TensorFlow拥有一个庞大的社区,这为用户提供了丰富的文档、教程以及第三方库,有助于解决学习和开发中遇到的问题。
- 强大的分布式计算支持:TensorFlow设计用于大规模模型的训练和推理,它能够在多个CPU或GPU上进行分布式计算,这对于处理大型数据集和复杂模型非常有利。
- 高性能:TensorFlow能够利用GPU加速计算,这对于深度学习任务来说是一个重要的优势,因为它可以显著减少训练时间。
缺点:
- 学习曲线较陡峭:对于初学者来说,TensorFlow的学习曲线可能相对陡峭,这意味着新手可能需要更多的时间来熟悉其API和概念。
- 代码结构相对繁琐:在某些情况下,TensorFlow的代码可能显得相对复杂和冗长,这可能会增加编程的难度和调试的工作量。
- 灵活性问题:虽然TensorFlow非常强大,但在某些情况下,它的灵活性可能不如其他框架,比如在定义新的层类型时,可能需要编写大量的额外代码。
应用:
1.图像识别
2.手写数字分类
3.递归神经网络
4.单词嵌入
5.自然语言处理
6.视频检测
7.TensorFlow 可以运行在多个 CPU 或 GPU 上,同时它也可以运行在移动端操作系统上(如安卓、IOS 等),它的架构灵活,具有良好的可扩展性,能够支持各种网络模型(如OSI七层和TCP/IP四层)。
补充知识点:
TensorFlow的组件
1) Tensor
TensorFlow 这个名称源自框架核心组件“ Tensor”,它的英文含义是“张量”的意思。张量是矢量概念的推广,矢量是一阶张量,而标量是零阶张量,矩阵可视为二阶张量。
在 TensorFlow 框架中,使用张量表示所有的数据类型,您可以把张量想象成一个 n 维数组或者列表,虽然形式上可以这样理解,但是它们之间也存在明显的不同,后续将会介绍。张量中的所有值都具有相同的数据类型,和一个给定的已知形状(维数)。张量可以作为输入数据,也可以在计算结果中生成。
2) Graph
该组件能够对模型训练期间所做的计算做出详细的汇总和描述,因此又称“计算图”。
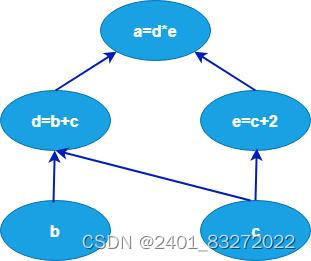
4) OP
上图所示每个椭圆要素代表着计算图中的节点(又称 OP)操作,节点在 TensorFlow 中以张量的形式表现出来,而每个节点之间连接线代表着节点之间的流动关系。
3) Session
Session 用来执行 Graph 中定义的运算,在 TensorFlow 中只有让 Graph(计算图)上的节点在 Session(会话)中执行,才会得到结果。Session 的开启涉及真实的运算,比较消耗资源。所以当你在使用结束后,务必关闭 Session。
Keras
1.Keras优点
1. 允许简单快速的原型设计(用户友好性,模块化和可扩展性)。
2. 支持卷积网络和循环网络,以及两者的组合。
3. 在CPU和GPU上无缝运行
2.Keras缺点
Keras比较注重网络层次,然而并非所有网络都是层层堆叠的,后面笔者的深度学习代码会涉及遗传算法与神经网络,这种网络就不是特别的规整,因此Keras在设计新的网络方面会比Tensorflow差一些。因此本书一些比较简单的实验均由keras完成,而一些高阶实验,我们则通过Tensorflow去完成。
Caffe
优点:
1. 高效
Caffe是一种高效的深度学习框架,它使用的是C++实现,并且在GPU上运行。这使得Caffe可以处理大规模的数据,并且可以在短时间内完成训练。
2. 灵活
Caffe是一种灵活的深度学习框架,它可以自定义网络结构和参数,并且可以在不同的任务中使用。
3. 可扩展
Caffe是一种可扩展的深度学习框架,它可以通过添加新的层和功能来扩展。
4. 多后端支持
Caffe支持多种后端,包括CUDA和OpenCL等。这使得Caffe可以在各种设备上运行,并且可以根据需要进行优化。
5. 大量的文档和教程
Caffe有大量的文档和教程,可以帮助用户快速上手,并且解决问题。
架构:
Caffe的架构可以分为两个部分:Caffe核心和Caffe后端。
1. Caffe核心
Caffe核心是Caffe的主要库,它提供了一些高级API,如Net和Solver,可以方便地构建和训练神经网络模型。
2. Caffe后端
Caffe后端是Caffe的底层库,它提供了一些低级API,如卷积、池化等。Caffe后端是灵活的,但通常需要更多的代码。
应用;
Caffe可以应用于许多领域,如计算机视觉、自然语言处理、语音识别等。
1. 计算机视觉
计算机视觉是深度学习的一个重要领域,Caffe可以在计算机视觉中得到广泛应用。例如,Caffe可以用于图像分类、目标检测、图像分割等任务。
2. 自然语言处理
自然语言处理是另一个深度学习的重要领域,Caffe可以在自然语言处理中得到广泛应用。例如,Caffe可以用于文本分类、情感分析、机器翻译等任务。
3. 语音识别
语音识别是另一个深度学习的重要领域,Caffe可以在语音识别中得到广泛应用。例如,Caffe可以用于语音识别、语音合成等任务。
扩展知识点:
过拟合:将训练样本自身的一些特点当作所有样本潜在的泛化特点。
表现:在训练集上表现很好,在测试集上表现不好。
过拟合的原因: 训练数据太少(比如只有几百组) 模型的复杂度太高(比如隐藏层层数设置的过多,神经元的数量设置的过大) 数据不纯.
解决:
1.移除特征,降低模型的复杂度:
2.减少神经元的个数,
3.减少隐藏层的层数
4.训练集增加更多的数据
5.重新清洗数据
6.数据增强
7.正则化
8.早停(防止过拟合,监控指标,提高效率,判断时机,实际应用)
欠拟合:还没训练好。
欠拟合的原因:
1. 数据未做归一化处理
2. 神经网络拟合能力不足
3. 数据的特征项不够
2. 解决方法:
1. 寻找最优的权重初始化方案
2. 增加网络层数、epoch
3. 使用适当的激活函数、优化器和学习率
4. 减少正则化参数
5. 增加特征
k 折交叉验证(k-fold cross validation):k 一般取 10 将数据集分为训练集和测试集,将测试集放在一边 将训练集分为 k 份 每次使用 k 份中的 1 份作为验证集,其他全部作为训练集。
通过 k 次训练后,我们得到了 k 个不同的模型。
评估 k 个模型的效果,从中挑选效果最好的超参数 使用最优的超参数,然后将 k 份数据全部作为训练集重新训练模型,得到最终模型

















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









