






导语:在日常数据分析中,文本关键词提取与数据可视化是两大核心技能。本文将通过两个完整代码案例,手把手教你用Python生成炫酷词云图和直观柱状图,分别实现对文本数据的挖掘与Excel表格数据的可视化呈现。
一、词云图生成:从文本中挖掘关键词
1. 核心功能与工具
-
功能:自动分析文本文件中的高频词汇,生成视觉冲击力强的词云图。
-
工具包:
-
jieba:中文分词工具,将文本切割为词语 -
pyecharts:百度开源可视化库,生成交互式词云 -
pandas:辅助数据处理(本代码未直接使用,但常配合使用,其本身也可以处理excel但此处我们使用openpyxl)import pandas as pd #导入词云图模块 from pyecharts.charts import WordCloud from pyecharts import options as opts #导入jieba库实现分词处理 import jieba #输入要打开的文件 with open(r"C:\Users\30719\Desktop\新建 文本文档.txt","r",encoding="utf-8") as file: #可以指定参数cut_all来改变模式 txt=jieba.lcut(file.read()) data={} #排除只有一个单词的 for i in txt: if len(i)==1: continue else: data[i]=data.get(i,0)+1 data=list(data.items()) w=WordCloud() #添加相应参数,其中数据是以[(),(),...]形式传入的 w=w.add(series_name="词云图",data_pair=data,word_size_range=[6,66]).set_series_opts(title_opts=opts.TitleOpts( title="标题", title_textstyle_opts=opts.TextStyleOpts(font_size=20) ),tooltip_opts=opts.TooltipOpts(is_show=True)) #保存文件,记住是要保存一个文件而不是保存一个目录 w.render("D:\\可视化文件\\p1.html")3. 关键点说明
-
分词处理:
jieba.lcut()采用精确分词模式,可通过cut_all=True切换全模式 -
词频统计:过滤单字词减少干扰,
data.get(i,0)实现计数 -
4. 效果预览
-
可视化配置:
-
word_size_range:控制词语大小 -
title_opts:设置标题样式
-
-
结果保存:生成HTML文件,支持交互式查看
-
以下是我在红楼梦百度百科上直接全屏复制后生成的内容 (以下是截图,但pyecharts生成的是可以交互式的html文件)
二、柱状图生成:Excel数据可视化
1. 核心功能与工具
-
功能:读取Excel表格数据,自动生成对比柱状图(因为实际应用中excel保存数据居多,我们此处用excel为例,大门本处不细说openpyxl的应用,以后可能单独说明python对excel文件的操作--pandas\openpyxl)
-
工具包:
-
openpyxl:Excel文件读写库 -
pyecharts:生成交互式柱状图
-
#导入柱状图模块
from pyecharts.charts import Bar
#导入excel处理的模块
from openpyxl import load_workbook
#打开文件,注意要加r或是使用\\
file_path=r"C:\Users\30719\Desktop\示例01.xlsx"
workbook=load_workbook(file_path)
#读取第一工作表
sheet=workbook['Sheet1']
#读取单元格数据,注意单元格数据必须要加.value
cell_value=sheet['A2'].value
print(f"A1单元格的值: {cell_value}")
name=[]
A=[]
for i,s in enumerate(sheet['1']):
if i>0:
name.append(s.value)
for i,s in enumerate(sheet['2']):
if i>0:
A.append(s.value)
bar=Bar()
#添加x,y轴的数据
bar.add_xaxis(xaxis_data=name)
#图例名称参数series_name,图例名称用于区分柱状图,在图表中呈现不同的颜色,并且默认显示在图表上方
#如果不设置图例名称是会报错的
bar.add_yaxis(series_name="商品总销量",y_axis=A)
bar.set_global_opts(
title_opts=opts.TitleOpts(title="商品销售排行榜"),
yaxis_opts=opts.AxisOpts(name="销售量(件)"))
#保存文件
bar.render("D:\\可视化文件\\p2.html")
3. 关键点说明
-
数据读取:
-
sheet['A'][1:]获取A列从第二行开始的数据 -
列表推导式快速提取单元格值
-
-
图表配置:
-
add_yaxis设置数据系列名称 -
set_global_opts添加标题和坐标轴标签
-
-
注意事项:
-
确保Excel文件路径正确
-
工作表名称与实际文件一致
-
4. 效果预览(此处只显示了A物品,B会在之后的双柱状图中使用)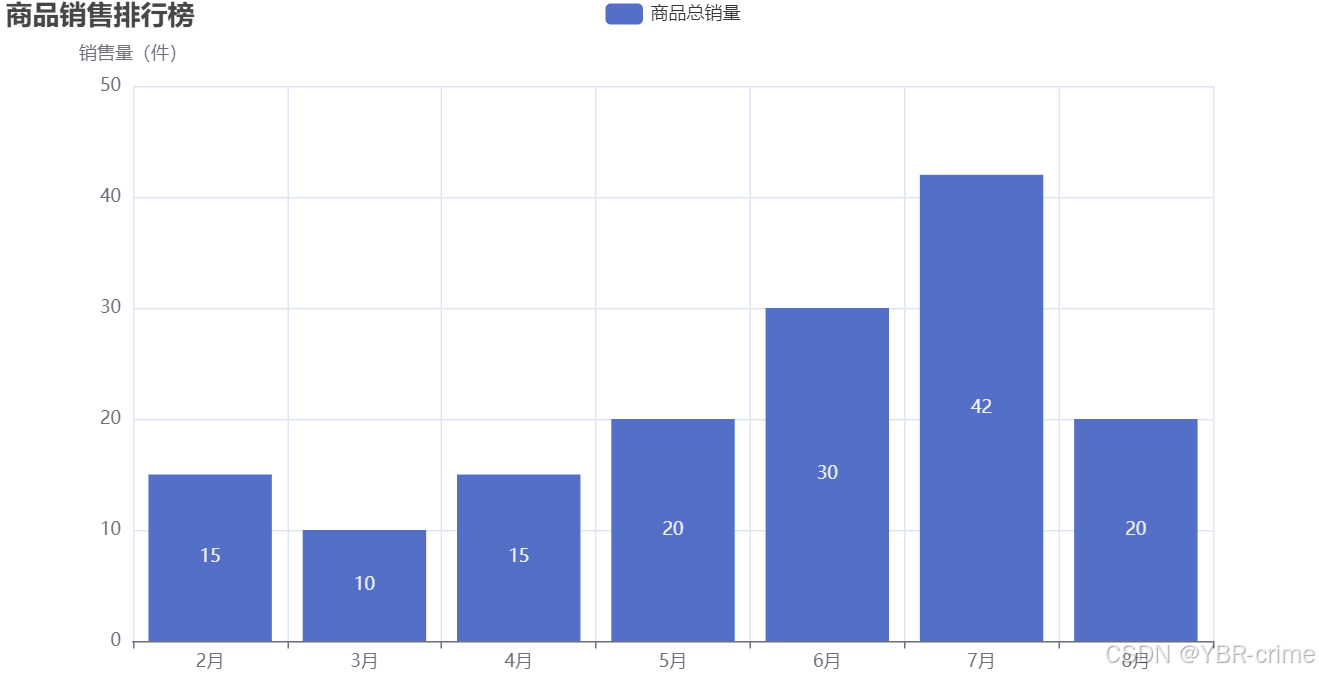
同样上述图其实是可以交互,即鼠标放在上面是可以显示数量的。

三、常见问题解答
Q1:为什么生成的图表是HTML文件?
A:pyecharts默认生成交互式网页,可使用浏览器直接打开,也支持导出为图片格式。
Q2:如何修改图表颜色?
A:在add方法中添加color参数
.add_yaxis(..., color="#FF0000")Q3:Excel数据读取报错怎么办?
A:检查:
-
文件路径是否包含中文或特殊字符
-
是否安装了openpyxl库(
pip install openpyxl) -
单元格数据是否为数值类型(注意对excel单元格数据提取一定要加.value这里十分重要,最容易遗漏,如果报错先看看是不是没加!)
以下官方链接供各位探索,可以有许多可以调整的参数!
注:本人本科生一名,记录自己学习内容,如有问题欢迎指教,一定会认真聆听!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









