






问题描述
在互联网项目中,一般以堆内缓存的使用居多,无论Guava Cache还是JDK自带的HashMap、ConcurrentHashMap等,都是在堆内缓存中做数据计算操作。这是因为堆内缓存的响应速度最快,但是堆内缓存的价格也最高。有没有既能节约成本,又能提供较好的性能的工具呢?
JVM一旦出现GC或者FULL GC的情况,就然删掉堆内存,此时应如何快速读取缓存数据?
问题分析与解决方案
实际上,堆内缓存、堆外缓存、磁盘缓存的响应速度是依次递减的。堆外缓存同样不需要考虑I/O、网卡、网络流量、连接数等一系列问题,数据并不存放在JVM内存上,而是直接存放在Linux系统内存上。
堆外缓存
因为堆内缓存在JVM的管理之内,所以堆内缓存的速度是无可挑剔的。但是由于堆内缓存占用了大量的JVM内存,所以在JVM GC的过程中可能会出现各种停顿和延时。并且随着堆内缓存内容的不断增多,JVM为了扩大当前堆内缓存的空间,会频繁进行垃圾回收。
由于JVM GC的存在,堆内缓存操作会受到不小的影响,尤其是在插入过程中,当涉及锁等操作时,各种堆内缓存容器很可能会引起性能的过度损耗。为了缓解堆内缓存的压力,衍生出了堆外缓存。堆外缓存的本质是通过Java代码直接操作计算机内存,将数据放置在计算机内存中,而非JVM内存中。堆外缓存又名堆外内存、本地内存。
堆外缓存由于不受JVM管控,不触及JVM GC的条件,所以不用担心堆外缓存出现频繁垃圾回收等相关问题。
不过堆外缓存也并非全都是优点,操作系统对每一个进程的内存管理都有相应的限制,所以在管控堆外缓存不佳的情况下,Java代码同样会爆出OOM(Out Of Memory Error,内存溢出错误)。而堆外缓存溢出并不体现在Java的GC日志中,所以在生产环境中如果出现堆外缓存溢出,将很难查找到问题根源。
基于历史因素,大部分堆外缓存都直接使用成熟的框架进行管理,以免编程时发生未知泄漏与异常。市场上常见的堆外缓存解决方案有EhCache、MapDB等。
MapDB
MapDB是一套简单易用的可插拔程序,其调用方式十分简单。本文着重对各种返回值及使用方式进行讲解,以代码方式帮助读者理解MapDB的使用。
注意:在学习堆外缓存时不建议刻意背诵各种MapDB之类的API,只需知道如何使用及熟悉各种数据结构即可。另外,本章后面简易阐释了多级缓存的概念和使用方式,这种代码设计方式或者说架构方式十分常见,在HTTP缓存、堆内缓存、堆外缓存、磁盘缓存和Redis缓存等不同的层级都可以用多级缓存的架构方式进行设计。
MapDB的特性如下所示:
-
可替换Map、List、Queues等相关集合。
-
使用堆外缓存,不受垃圾回收器的影响。
-
具有过期和磁盘溢出等多级缓存。
-
可用事务、MVCC、增量备份等方式替换关系数据库。
-
当对本地数据处理和过滤时,MapDB可以在合理的时间内处理大量的数据。
MapDB的Maven地址如下所示:

实战:初次使用MapDB
当通过代码在内存中打开HashMap时,可以使用堆外缓存并且不受垃圾回收的限制。MapDB使用堆内缓存的代码如下所示:
 HashMap(和其他集合)也可以存储在文件中,它可以在JVM重新启动期间保留内容。不过必须关闭数据库,以防止数据损坏。MapDB使用磁盘缓存的代码如下所示:
HashMap(和其他集合)也可以存储在文件中,它可以在JVM重新启动期间保留内容。不过必须关闭数据库,以防止数据损坏。MapDB使用磁盘缓存的代码如下所示:
 fileDB().make()生成的实体文件如图所示:
fileDB().make()生成的实体文件如图所示:
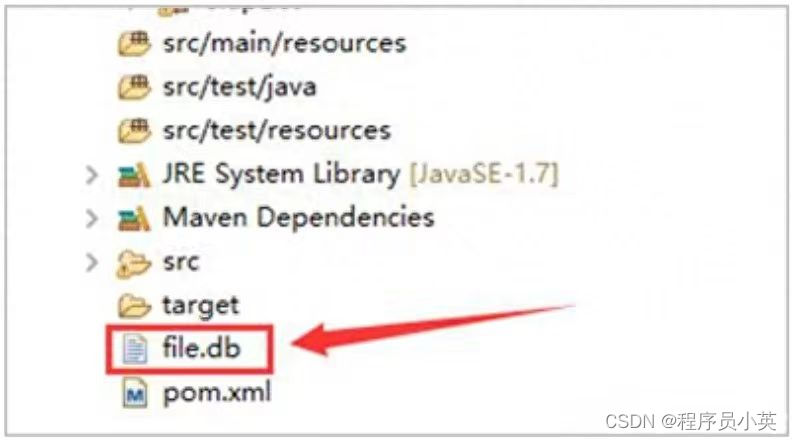
DBMaker类可以创建和配置MapDB数据库,一个数据库实例代表一个打开的数据库。DBMaker类可以创建和打开集合存储,并且可以使用commit、rollback和close等方法处理数据库的生命周期。
想要打开(或创建)一个存储,可以使用许多*DB静态方法,如DBMaker.fileDB。MapDB有很多格式和模式,每个xxxDB使用不同的模式。例如,memoryDB可以打开一个由byte数组支持的内存数据库,appendFileDB可以打开一个追加的日志文件。
一个xxxDB方法后面通常可以跟一个或多个配置项,最后用make方法打开选定的存储并返回一个DB对象。下面打开启用加密的文件存储,并以此构造DB对象:
![]() 在构造DB对象之后便可以通过该DB对象创建集合并使用空间了。可以选择如HashMap、TreeSet等不同的数据结构进行配置,最终直接进行操作。下面的代码创建了TreeSet并将其命名为TreeSet1:
在构造DB对象之后便可以通过该DB对象创建集合并使用空间了。可以选择如HashMap、TreeSet等不同的数据结构进行配置,最终直接进行操作。下面的代码创建了TreeSet并将其命名为TreeSet1:
![]()
MapDB的构造原理
MapDB可以通过fileDB、memoryDB等实例化出磁盘缓存与堆缓存的DB存储空间,然后通过不同的存储空间API存储数据。例如,MapDB可以通过下面的代码实例化出两个不同的存储空间:

(1)构造磁盘缓存。HashMap(和其他集合)也可以存储在文件中。此模式可以在JVM中保留内容。为防止数据损坏,需要先启动事务再更改文件,并且在修改文件之后尽可能用DB.close命令关闭文件。另外,也可以通过内置的allocateStartSize参数和allocateIncrement参数设置文件大小。
fileMmapEnable函数的功能是启用内存映射文件,更快地存储选项。但由于寻址问题,如果启用此模式,则在32位JVM上可能出现映射失败的异常,也可能损坏DB实体文件。
![]() (2)构建Java heap堆缓存。Java heap是JVM虚拟机中管理的最大一块内存。此模式构建的数据存储空间不会进行序列化,因此生成的数据集很小,但仍受垃圾回收影响,所以此模式在数据达到几GB之后性能会急剧下降。
(2)构建Java heap堆缓存。Java heap是JVM虚拟机中管理的最大一块内存。此模式构建的数据存储空间不会进行序列化,因此生成的数据集很小,但仍受垃圾回收影响,所以此模式在数据达到几GB之后性能会急剧下降。
(3)构建Java heap独立碎片性缓存。带有Sharded的函数皆为此种缓存方式,为了获得更好的并发性,Sharded会把缓存的数据分割成不同的段,即把HTreeMap分为不同的段。每个段是独立的,不与其他段共享任何状态,但是它们仍然共享底层存储。
使用Sharded存储时没有与HashMapMaker相关联的DB实例化对象,因此为了关闭Hash分片,在使用结束后必须调用heapShardedHashMap.close函数。
(4)构建Java heap独立碎片性缓存。与heapShardedHashMap类似,只是存储为Set链表结构。
![]()
(5)构建Java heap堆缓存,创建新的内存数据库。在JVM退出后,更改将丢失。此选项会将数据序列化为byte[],因此不受垃圾收集器的影响。
transactionEnable函数可开启WAL模式,默认为关闭。WAL(WriteAhead Logging)指预写日志系统,是数据库中一种高效的日志算法,对于非内存数据库而言,磁盘I/O操作是数据库效率的一大瓶颈。在相同的数据量下,采用WAL日志的数据库系统在事务提交时,磁盘写操作只有传统的回滚日志的一半左右,大大提高了数据库磁盘I/O操作的效率,从而提高了数据库的性能。
![]()
(6)构建堆外缓存。在此种模式下,数据完全存储于直接内存( DirectByteBuffer)中,可以使用allocateIncrement参数和allocateStartSize参数设置直接内存大小。除此之外,还应在JVM处规定堆外缓存使用大小,否则设置可能无法生效。JVM通过(-Xmx10G)参数与(XX:MaxDirectMemorySize=5G)参数来设置堆外缓存使用大小。
(7)构建独立碎片性堆外缓存。与heapShardedHashMap类似,在此种模式下,会把数据存储于直接内存中。
![]()
在临时文件夹中创建新的数据库。如果程序关闭,则删除临时文件:

MapDB允许用户用自己的卷、文件集、移动硬盘建立数据库。例如,在上面的代码中,打开内存映射文件并在其上创建数据库。
注意,contentAlreadyExists指映射文件中是否已经包含数据库。如果已包含数据库,则打开数据库;如果未包含数据库或为空的映射文件,则覆盖数据库。
MapDB的使用方法
1. 使用TreeSet
TreeSet是一个包包含序且没有重复元素的集合,作用是提供有序的Set集合。它继承自AbstractSet抽象类,实现了NavigableSet<E>、Cloneable和Serializable接口。TreeSet是基于treeMap实现的。TreeSet支持两种排序方式:自然排序,以及根据提供的Comparator进行排序。
DB在被创建之后,通常会转换成TreeSet、TreeMap、HashSet、HashMap和IndexTreeList等形式的集合。DB调用某一TreeSet的代码如下所示:
![]() db.treeSet虽然转换成了TreeSet集合,但未打开该集合并使用。集合可以由三种方式打开,如下所示:
db.treeSet虽然转换成了TreeSet集合,但未打开该集合并使用。集合可以由三种方式打开,如下所示:
-
create():创建新的集合。如果集合存在,则抛出异常。
-
open():打开存在的集合。如果集合不存在,则抛出异常。
-
createOrOpen():打开集合,如果集合不存在,则创建新的集合。
注意,不要使用已被弃用的make函数,以免出现bug。完整创造集合且打开TreeSet的代码如下所示:

NavigableSet是Java.util包下的集合接口,继承自SortedSet。它是一个红黑树实现的链表结构,可以直接作为集合使用。但是由DB创建出来的NavigableSet只能使用Object[]作为泛型。
2. 使用TreeMap
TreeMap是基于NavigableMap接口使用红黑树算法实现的。BTreeMap是一个可伸缩的并发ConcurrentNavigalMap接口的实现,其中包含插入、移除、更新作等API函数。另外,在BTreeMap中,键的升序排序比降序排序要快一些。
BTreeMap的示例代码如下所示:
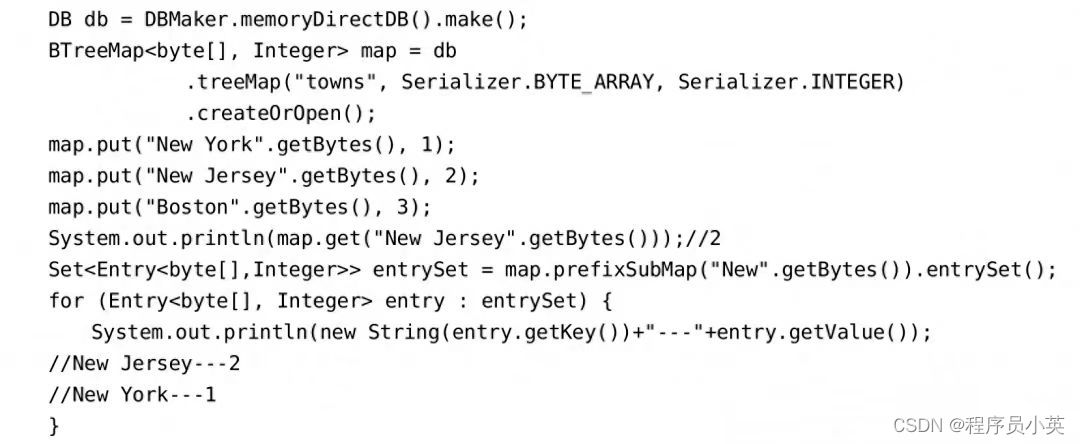
3. 使用HashMap
使用HashMap的代码如下所示:
 也可以通过MapDB的自身序列化方式得到HTreeMap,代码如下所示:
也可以通过MapDB的自身序列化方式得到HTreeMap,代码如下所示:

4. 使用IndexTreeList
IndexTreeList是MapDB中的List实现方式,使用IndexTreeList的代码如下所示:
MapDB实战
MapDB的序列化
MapDB通过DB暴露的API可获得各类容器,在容器中使用create函数制作出相应的空间。这些空间可转换成ConcurrentMap、KeySet等存储形式,代码如下所示:

大多数哈希映射使用的是Object.hashcode生成的32位哈希,并使用Object.equals(other)检查是否相等。MapDB通过Key序列化生成哈希代码。
例如,byte[]可以直接在HTreeMap中作为key使用。如果序列化,则BYTE_ARRAY可用作关键序列化器,序列化代码如下所示:
 同理,Object[]数组也可以用作键,并用byte[]替换字符串,这样可直接提高性能。序列化代码如下所示:
同理,Object[]数组也可以用作键,并用byte[]替换字符串,这样可直接提高性能。序列化代码如下所示:

MapDB的事务
DB处理事务生命周期的方法是commit(提交)、rollback(回滚)和close(关闭),一个DB对象表示单个事务。使用MapDB的事务的代码如下所示:

MapDB的监听器与多级缓存
HTreeMap支持监听器,可监听HTreeMap的插入、更新和删除等,可以将两个集合链接在一起。
所谓多级缓存指在整个系统架构的不同层级分别进行数据缓存,以提升访问效率。这也是最常用的编程方式。在MapDB中,一条数据在堆内缓存中过期后,它将被修改侦听器自动移到磁盘缓存上。MapDB建立绑定的代码如下所示:
 一旦建立绑定,则从堆内缓存中删除的过期数据都将被添加到磁盘缓存中,但这仅适用于过期数据。map.remove()可删除磁盘缓存中的数据,示例代码如下所示:
一旦建立绑定,则从堆内缓存中删除的过期数据都将被添加到磁盘缓存中,但这仅适用于过期数据。map.remove()可删除磁盘缓存中的数据,示例代码如下所示:
 如果调用了inMemory.get(key),并且值不存在,则MapDB将尝试在磁盘缓存中查找Map。如果能在磁盘缓存中找到值,则把该值添加到堆内缓存中,示例代码如下所示:
如果调用了inMemory.get(key),并且值不存在,则MapDB将尝试在磁盘缓存中查找Map。如果能在磁盘缓存中找到值,则把该值添加到堆内缓存中,示例代码如下所示:
 也可以删除整个容器,并把所有数据移到磁盘中:
也可以删除整个容器,并把所有数据移到磁盘中:
 值得注意的是,这种由堆内缓存转到磁盘缓存的代码编写方式,其构建部分代码最好在某一静态块中进行处理,以免多次被请求到,导致不必要的麻烦。
值得注意的是,这种由堆内缓存转到磁盘缓存的代码编写方式,其构建部分代码最好在某一静态块中进行处理,以免多次被请求到,导致不必要的麻烦。

















 1195
1195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









