







事件流根据事件的键和事件划分逻辑进行分区。对于每个事件,应用事件分区器,并为要写入的事件选择一个分区。再分区是生成具有以下一个或多个属性的新事件流的操作。
不同的分区数
增加事件流的分区数以提高下游并行度,或为与另一个流的分区数相匹配而进行协同分区(本章稍后将介绍)。
不同的事件键
改变事件的键以确保相同键的事件被路由到相同的分区。
不同的事件分区器
变更用于选择将事件写入哪个分区的逻辑。
纯粹无状态的处理器很少需要再次划分事件流,除非为了提高下游并行度而增加分区数。也就是说,无状态微服务可用于对下游有状态算子所消费的事件进行再分区,这是接下来所讲示例的主题。
分区器算法通常使用哈希函数将事件的键明确地映射到特定的分区。这可以确保具有相同键的所有事件最终都在同一个分区中。
示例:对一个事件流再分区
假设有一个用户数据流,其数据从面向 Web 的终端传入。用户的操作被转换成事件,事件的内容同时包含用户 ID 和其他任意事件数据,标记为 x。
此状态的消费者希望确保属于特定用户的所有数据都在同一个分区中,而不管源事件流是如何分区的。可以对这个流进行再分区以满足这种要求,如图
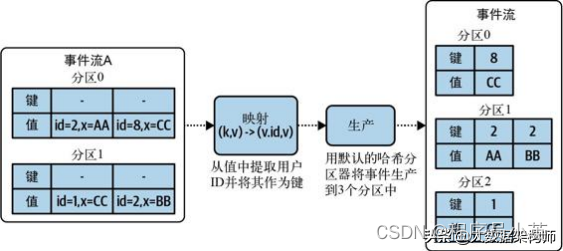
将给定键的所有事件放入同一个分区中,这样做为确保数据局部性提供了基础。消费者只需要消费单个分区中的事件,就可以构建与该键相关的事件的完整视图。这使消费者微服务能够扩展到多个实例,每个实例从一个分区消费,同时维护与该键相关的所有事件的完整状态账户。再分区和数据局部性是大规模执行有状态处理的关键部分。
对事件流协同分区
协同分区是将一个事件流重新划分为新的事件流,该事件流具有与另一个流相同的分区数和分区分配逻辑。当一个事件流中的键控事件需要与另一个流的事件并置时(为了数据局部性),这是必需的。这是有状态流处理的一个重要概念,因为许多有状态操作(如流联结)要求对给定键的所有事件,无论来自哪个流,都必须通过同一个节点进行处理。第 7 章将更详细地介绍这一点。
示例:对一个事件流进行协同分区
再考虑一下图 5-2 的再分区示例。假设你现在需要将再分区的用户事件流与用户实体流进行联结,该用户实体流用与事件流相同的 ID 作为键。这些流的联结如图

两个流具有相同的分区数,并且使用相同的分区器算法进行了分区。请注意,一个流中各个分区的键的分布与另一个流中的分布相匹配,并且每次联结都由其自身的消费者实例执行。下一节将介绍如何将分区分配给微服务实例以利用协同分区的流,正如在这个联结例子中所做的那样。
给消费者实例分配分区
每个微服务都维护着自己唯一的消费者组,这个消费者组表示其输入事件流的共有偏移量。第一个上线的消费者实例将使用消费者组的名称在事件代理上进行注册。一旦注册,就需要给消费者实例分配分区。
一些事件代理,比如 Apache Kafka,将分区分配委托给每个消费者组的第一个在线客户端。作为消费者组的领导者,这个实例负责履行分区指派者的职责,确保每当新实例加入该消费者组时,输入事件流分区都被正确分配。
其他事件代理,比如 Apache Pulsar,在代理中维护着集中式的分区分配权。在这种情况下,分区分配和再平衡由代理完成,但通过消费者组进行标识的机制保持不变。分配分区之后,工作可以从最后一个已知的消费事件偏移量开始。
在重新分配分区时,工作通常会暂时挂起以避免争用分区的情况。这可以确保在分配分区给新实例之前,其他实例不再处理任何被废除的分区,从而消除任何潜在的重复输出。
使用分区分配器分配分区
处理大数据通常需要多个消费者微服务实例,无论是专用流处理框架还是基础的生产者/消费者实现。分区分配器可以确保将分区以均衡和公平的方式分配给处理实例。
每当在消费者组中添加或删除消费者实例时,分区分配器都负责重新分配分区。根据所选择的事件代理,此组件可能被构建到消费者客户端中,或者由事件代理维护。
分配协同分区
分区分配器还负责确保满足所有协同分区的需求。所有标记为协同分区的分区必须分配给同一个消费者实例。这将确保为给定的微服务实例分配正确的事件数据子集,以执行其业务逻辑。这方面的最佳实践是分区分配器实现校验机制,可以查看事件流是否具有相等的分区数,并在不相等时抛出异常。
分区分配策略
在消费者实例处理能力相同的情况下,分区分配算法的目标是确保分区在消费者实例中均匀分布。分区分配算法也可能有次要目标,比如减少在再平衡期间重新分配的分区数量。当处理跨多个数据存储实例的物化状态分片时,这一点尤其重要,因为重新分配分区会导致将来的更新进入错误的分片。第7 章将进一步探讨关于内部状态存储的概念。
分配分区有许多常用的策略。默认策略可能会因框架或实现的不同而有所不同,但以下 3 种策略往往是最常用的。
01. 循环分配
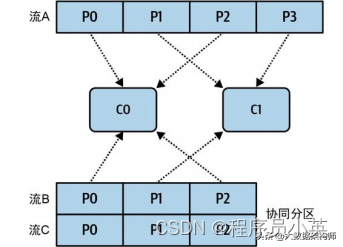
所有分区都被记录到一个列表中,并以循环方式分配给每个消费者实例。为协同分区流保留一个单独的列表,以确保正确分配协同分区。
图 5-4 展示了两个消费者实例,每个实例都有自己的分区集合。C0 有两组协同分区,而 C1 只有一组,因为分配开始和结束于 C0。
当给定消费者组的消费者实例数目增加时,应该再平衡分区分配,以便在新增的资源之间分散负载。图 5-5 展示了添加两个消费者实例的效果。
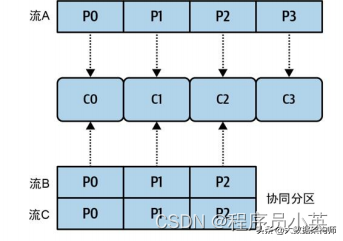
C2 现在被分配了协同分区 P2 以及流 A 的 P2 分区。而 C3 只被分配了来自流 A 的 P3 分区,因为没有其他分区可用于分配了。添加任何其他实例并不会提高并行化程度。
02. 静态分配
当特定的分区必须分配给特定的消费者时,可以使用静态分配协议。当在任意给定实例上物化大量有状态数据时,此方法非常有用,它通常用于内部状态存储。当消费者实例离开消费者组时,静态分配器不会重新分配分区,而是会等到丢失的消费者重新上线。根据实现的不同,如果原始消费者未能在指定的时间段内重新加入消费者组,则无论如何都可能会重新动态分配分区。
03. 自定义分配
通过利用外部信号和工具,可以根据客户的需要定制分配策略。例如,可以基于输入事件流中的当前延迟进行分配,以确保在所有消费者实例中平均分配工作。
从无状态处理实例故障中恢复
从无状态故障中恢复实际上等同于向消费者组添加新实例。无状态处理程序不需要任何状态恢复。这意味着一旦分配了分区并确定了流时间,它们就可以立即恢复处理事件。
小结
基本的无状态事件驱动型微服务消费事件、处理事件并会发出新的后续事件。每个事件都是单独处理的。基本的转换可以将事件更改为更加有用的格式,然后将事件再分区到使用新键的事件流中。有相同键、相同分区算法和相同分区数的事件流可被分入协同分区,它保证了对于给定的消费者实例的数据局部性。分区分配器用于确保消费者实例之间的分区均匀分布,并且正确分配协同分区的事件流。
协同分区和分区分配对于理解有状态的处理是很重要的,这部分内容将在第7 章中进行详细介绍。但是,首先你必须考虑如何处理来自多个事件流的多个分区。乱序事件、迟到事件和选择处理事件的顺序都会对服务的设计产生重大影响。这将是第 6 章的主题。















 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









