






初识分布式
说到分布式计算,就不得不提到图灵奖获得者Leslie Lamport,他奠定了分布式计算的理论基础。他提出了逻辑时钟的概念,为判定分布式系统中的事件发生顺序提供了理论基础;他定义了顺序一致性的概念,为多核应用提供了理论基础;他提出了“拜占庭将军问题”,为容错计算提供了理论基础;他设计的Paxos算法成为如今讨论和使用最广泛的共识算法……当然,他还是LaTeX的发明人。
本文讲述的绝大部分内容都没有超过前辈的发现和创造,感谢他们为拓展人类的知识域所做出的贡献!
什么是分布式系统
Lamport在1987年的一封电子邮件中是这样描述分布式系统的:
"A distributed system is one in which the failure of a computer you did not even know existed can render your own computer unusable."
我们可以简单理解为:如果一台你都不知道的计算机坏了,从而导致你自己的计算机都无法使用,那么这样一个系统就是分布式系统。
显然,这是一个非正式的定义。作者专门查阅了1987年5月Lamport发的一封邮件,当时Lamport在数字仪器公司(Digital Equipment Corporation,DEC)工作,需要用很多计算机来运行他的FF程序,而这个FF程序依赖于一个叫作nub的东西。他在邮件中写道:“电气问题不是根因,只不过是让这个情况更为突出罢了。现在新版本的nub使我的FF程序越来越依赖于在其他地方运行的程序。
花几秒等程序自动切换总比花一两个小时重启服务器要少些恼火吧,所以我提议搞一个让我们的系统更加鲁棒的项目。”结合这封电子邮件的上下文可知,Lamport已经意识到解决问题的关键不在于提高单台服务器的电气可靠性,而在于让整个系统能够容忍单台计算机的故障,这其实是分布式系统最重要的特征之一。
如今的分布式系统是一个涉及内容较广的概念,它在不同的语境下描述了不同的特征。广义上,任何由多台计算机节点(以下简称“节点”)组成并共同完成特定任务的计算机系统,都可以被认为是分布式系统。根据这个定义,我们经常会遇到如下的分布式系统。
(1)并行系统:一般由多个节点组成,其基本功能是将规模较大的总任务切分成多个规模较小的任务,并让多个节点并发处理小任务,以提高总任务的处理效率。并行系统和并行算法侧重于研究如何把总任务切分为子任务,以及将子任务调度到不同的节点上并发执行。它研究的是效率问题,节点越多,问题越容易处理。
(2)基于共享内存的分布式系统:由多个节点组成,节点之间通过共享内存进行通信,共同完成某些任务。这里的“共享内存”不一定是真正的物理内存,也可以是共享数据库或者共享存储。之所以被称为共享内存,是因为最初人们在研究这类分布式算法时,是基于多核处理器访问共享内存这一模型进行的,所以该称呼一直沿用至今。
(3)基于消息传递的分布式系统:由多个节点组成,节点之间没有共享内存,只能通过链路来传递消息,节点和链路都有可能出现故障。它研究的是如何减少故障对系统的可用性和一致性的影响,因此节点越多,问题越难处理。
本文研究的分布式系统特指“基于消息传递的分布式系统”。
在这个系统中,每个节点被称为进程。其中,“进程和链路均有可能失败”是本书所研究的分布式系统与其他分布式系统的核心区别,这也是基于消息传递的分布式算法的复杂性之所在。如无特殊说明,本文所说的“系统”和“分布式系统”(或计算、算法)均指基于消息传递的分布式系统(或计算、算法)。
分布式算法的意义
客观世界充满着既独立、又需要协作的实体,如何让它们按照人类的意图运作,分布式算法发挥着重要的作用。例如,在多路处理器的计算机中,处理器之间是不共享高速缓存的,但无论进程在哪个处理器上执行,都能看到同样的数据,这是因为每个处理器对应的缓存控制器上都运行了一种叫作“一致性缓存”的算法。这个一致性缓存算法就是一种基于消息传递的分布式算法,只不过分布的尺寸仅限于单台计算机内部而已。
有些应用在本质上就是分布式的,因此需要分布式算法。例如,有一个数据分发系统,它只要求每个接收者都能一个不落地收到所有的数据包,但对数据包的接收顺序没有要求,在分布式算法中,这叫作“尽力广播”;而一个交易系统不仅要求每个正确的进程(即证券信息接收端)能收到所有的包,还要求收包顺序与发包顺序完全一致,在分布式算法中,这叫作“先进先出广播”。类似的系统数不胜数,它们本身就是一个分布式系统,所以需要使用分布式算法。
还有一些应用,本身并不要求分布式算法,但出于高可用、容错等目的而不得不使用分布式算法。例如,对于一个业务并不繁忙的交易系统,单台数据库节点或许就足以满足性能需求。但为了避免单台节点故障,导致交易业务受影响,往往需要部署多台数据库节点以实现高可用,这要求在每台数据库节点上存储的交易记录是完全相同的。这就要用到分布式算法中的共识算法。
下面介绍一个著名的“两将军”问题(Two Generals Problem),感受一下分布式共识算法的巨大作用。
“两将军”问题
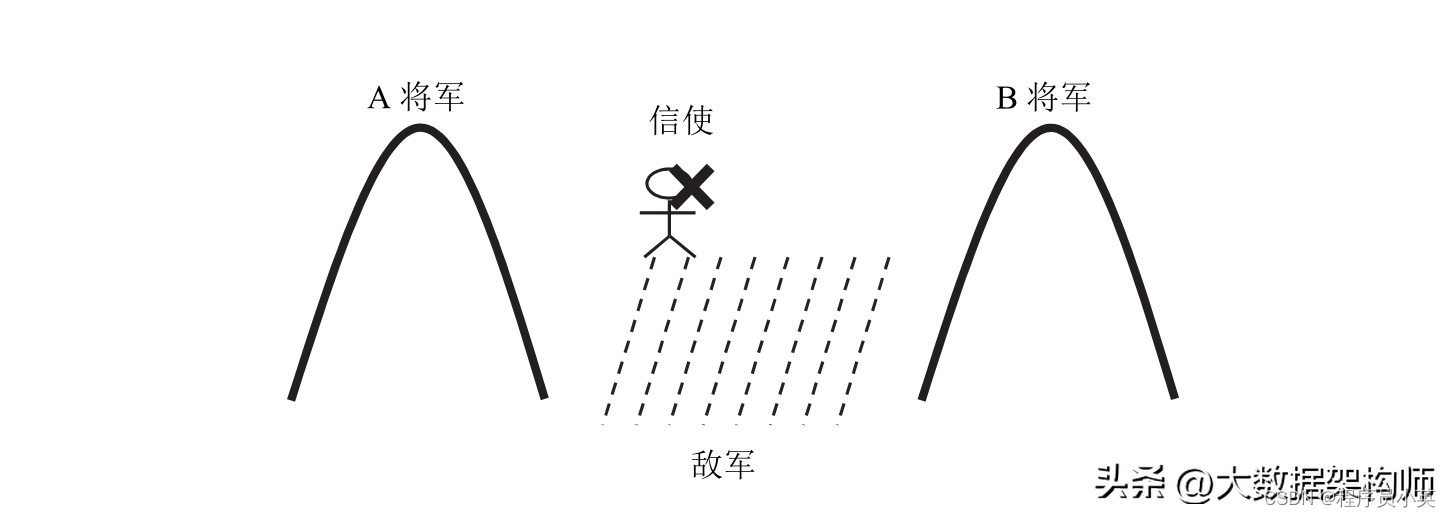
图1-1 “两将军”问题
如图1-1所示,假设有两支友军,分别由A和B两位将军统领。这两位将军都知道,仅当两支军队同时向敌军发起进攻时才能获胜,否则必败,因此两位将军要协商一个同时发起进攻的时间点。但两支友军驻扎在两座不同的山上,两山之间有一个山谷,两位将军只能派信使途经山谷向友军报信。然而山谷里驻扎着敌军,信使很有可能被敌军俘虏,导致消息无法在预期的时间内传递到友军。请问,是否存在一种确定的策略,只要两位将军按照这个策略执行,就能约定好同时发起进攻的时间呢?
乍一看,这个问题很简单。在日常生活中,我们经常会遇到类似的事情,例如张三和李四约好了明天下午4点喝茶,这与两位将军约定同时发起进攻的时间点在本质上没有区别。下面我们试着模拟一下两个将军的思考和行为,再做判断。
第1步:A将军向B将军发送消息“明日午时三刻何如?”
第2步:B将军收到了A将军发送的消息“明日午时三刻何如?”
第3步:A将军收到了B将军发送的消息“B同意”。
到这里,也许读者会认为两位将军已经就同时发起进攻的时间点达成一致了。但B将军敢在明日午时三刻发动进攻吗?不敢,因为B将军知道,虽然他(B将军)回复了“B同意”这条消息,但并不确定A将军是否收到了。如果A将军没有收到“B同意”这条消息,那么A将军就不会进攻,若B将军单独进攻,就只有死路一条,所以B将军不敢发动进攻。同理,A将军也想到了B将军会这么想,所以A将军也不会进攻。也许读者又会问,让A将军再发送一条确认消息“A收到(B同意)”给B将军,不就可以了吗?那我们再继续模拟一下。
第4步:B将军收到了A将军发送的消息“A收到(B同意)”。
此时,B 将军敢在明日午时三刻发动进攻吗?仍然不敢,因为 B 将军知道,虽然他(B将军)收到了A将军发送的“A收到(B同意)”这条消息,但A将军并不知道B将军是否收到了。如果B将军没有收到“A收到(B同意)”这条消息,那么B将军就不会进攻,若A将军单独进攻,就只有死路一条,所以A将军也不会进攻。想到这里,B 将军就不会进攻了。同理,A 将军也想到了B 将军会这么想,所以 A将军也不会进攻。
接下来,我们再来一个确认消息看能否让两位将军敢进攻。
第5步:A将军收到了B将军发送的消息“B收到(A收到(B同意))”。
此时,A 将军敢在明日午时三刻发动进攻吗?仍然不敢,因为 A 将军知道,虽然他(A将军)回复了“B收到(A收到(B同意))”这条消息,但B将军并不知道A将军是否收到了。如果A将军没有收到“B收到(A收到(B同意))”这条消息,那么A将军就不会进攻,若B将军单独进攻,就只有死路一条,所以B将军也不会进攻。想到这里,A将军也就不敢进攻了。同理,B将军也想到了A将军会这么想,所以B将军也不会进攻。
……
这样无限循环下去,一个看似能够轻松搞定的事情就变得无解了,这似乎有点违反直觉,我们把这种情况称为“脑裂”(Brain-Split)。这是一个形象的比喻:在正常情况下,一个人只有一个大脑,全身都要听从这个大脑的指挥。“脑裂”是指大脑分裂了,两个大脑互不买账,身体其他部位就不知道该听谁的了。“两将军”问题就是脑裂的结果,两位将军无法就何时发起进攻一事而做出一致的决定。
为什么会出现脑裂呢?关键在于“信使不可靠”。我们在日常生活工作中,以面对面或电话的方式约定某件事情时,其实是利用了一个潜在的假设——“通信是可靠的”。下面以张三约李四喝茶为例模拟一下。
张三约李四喝茶
假设张三想约李四喝茶。第1步:张三跟李四说“明天下午4点喝茶怎样?”
第2步:李四跟张三说“行啊”。
第3步:张三听到了李四说的“行啊”。
仅仅通过这3步,张三和李四就都会于明天下午4点去喝茶。之所以李四会去喝茶,是因为李四认为通信是可靠的,张三一定会听到自己(李四)说的“行啊”两个字,因此张三一定会去。之所以张三会去,是因为张三听到了李四说的“行啊”两个字之后,就知道李四会去,并且知道李四知道自己(张三)也会去,所以张三也会去喝茶。可见,通信可靠是多么重要。
回到“两将军”问题。上述模拟过程的失败,只能让读者感觉解决到两将军问题并非易事,但并不能证明“两将军”问题不可解。
幸运的是,1985年,Fischer、Lynch和Paterson三位计算机科学家共同发表了一篇论文,证明了一个不幸的结论——“异步系统无法实现共识”,这个结论被称为“FLP不可能结论”。其中,“信使会被俘虏”实际上就构造了一个异步系统,“何时发动进攻”就是所要达成的共识。根据FLP不可能结论,“两将军”问题无解。
“两将军”问题无解的现实影响
“两将军”问题无解对现实的影响是巨大的!“两将军”问题无解,实际上是说,对于任何两个进程,如果它们的通信不可靠,则无法可靠地达成任何共识。下面我们看看在工作中遇到的“两将军”问题。
1.双机热备技术
工作经验丰富的读者可能听过“双机热备”(或“双机高可用”)技术。这种技术宣称可以让两个节点形成主备关系,如果主节点出现故障,那么备节点就会自动接管,使整个服务得以继续运行。这种能够容忍单节点故障的技术称为高可用技术。但是,根据FLP不可能结论,如果两个节点间的通信不可靠,那么这两个节点就无法对“谁是主节点”这个问题达成共识,即出现脑裂。出现脑裂后,要么出现两个主节点的情况,要么出现没有主节点的情况,而无法保证一定会出现一主一备的情况。因此,可靠的双机热备方案是,要么加强通信链路的可靠性,要么引入第三节点。如果仅在两个节点上安装了“具有神奇功能”的软件,那肯定不是一个可靠的双机热备方案。
2.双活机房与数据中心打交道的读者应该听过“双活机房”或类似的词。
这种技术通过高速网络将两个异地机房互联,使分别部署在两个机房的两套系统形成主备关系。该技术宣称,如果主机房断电断网,那么备机房的系统就会自动接管业务,使整个服务得以继续运行。在灾难发生时,例如水灾、地震等,由于这种技术能够跨地域提高服务持续运行的能力,因此比双机热备技术更“高级”。
但实际上,因为异地机房通过广域网进行通信,如果网络不可靠,双活机房仍然有可能出现脑裂问题。实际上,广域网通信的成本远远高于局域网,在相同的代价下,异地两机房的互联可靠性远远低于同址两节点的互联可靠性,更容易出现脑裂现象。因此,如果要实现跨地域的高可用,则应该在第三机房部署第三节点以避免脑裂。
3.TCP协议中的TIME_WAIT
精通TCP协议的读者应该知道TIME_WAIT状态。当进程A关闭一个TCP连接时,进程A的TCP/IP协议栈会将该连接的状态改为TIME_WAIT,并等待若干分钟后,才真正释放该连接的资源,例如所占用的IP和端口。如果不等待足够长的时间,那么进程A就不能确定对端进程B是否收到了报文ACK,从而导致其他问题。例如,如果在进程A和进程B之间新建TCP连接时,进程A和进程B都有可能接收到上一个TCP连接的报文,从而导致新的TCP连接无法正常工作。这其实与FLP不可能结论也有关。
FLP不可能结论指出,如果通信不可靠,那么任何两个进程都无法达成共识。也就是说,通过一个TCP连接互联的两个进程其实是无法对“对方进程是否发送/接收了报文ACK”这个问题达成一致的。因此,TCP/IP协议栈不得不选择一个很长的超时值,例如2分钟,甚至更长。从分布式算法的角度看,选择很长的超时值,实际上是在规避进程间通信不可靠的问题。至于为什么说“规避”,需要继续学习本书才能理解。
通过上述分析不难看出,一个小小的“两将军”问题就可以解释那么多的现实问题,分布式算法在我们的工作和生活中更是几乎无处不在。掌握分布式算法的原理和应用,不仅能够帮助我们回答很多问题,让我们知道哪些事情可能、哪些事情不可能,还能让我们更好地改变世界。
设计分布式算法的主要挑战
设计分布式算法的主要挑战在于如何降低并发执行、进程失败和链路失败对系统对外服务能力的影响。
并发执行
并发执行是保证分布式算法正确性的一大挑战。
假设有一个进程p,它有m步,分别为s1, s2,…, sm。如果只分析这一个进程的执行轨迹,显然只有一种执行轨迹,即s1, s2,…, sm。如果要求si先于sj执行,只需要在代码中确保第i步在前、第j步在后即可。
但对于多进程并发执行的分布式系统,情况则复杂得多。假设有一个全局时钟负责记录每个进程的每一步发生的时间点,然后根据每一步发生的先后顺序写成一个序列,就得到了一个执行轨迹。假如有n个进程p1, p2,…,
pn,每个进程的步数为m,进程i的第j步表示为p(i, j)。如果n=m=2,那么该分布式系统可能的执行轨迹有6种:
<p(1,1), p(1,2), p(2,1), p(2,2)>
<p(1,1), p(2,1), p(1,2), p(2,2)>
<p(1,1), p(2,1), p(2,2), p(1,2)>
<p(2,1), p(2,2), p(1,1), p(1,2)>
<p(2,1), p(1,1), p(2,2), p(1,2)>
<p(2,1), p(1,1), p(1,2), p(2,2)>
通过多重集合的全排列公式可知,执行轨迹共有

种可能。我们把所有可能的执行轨迹的集合称为执行轨迹空间,它与进程数和步数的乘积的阶乘成正比。一看就知道,这不是什么好事。
仅仅令n、m为2、3、4,就可以发现执行轨迹空间爆炸的速度是惊人的。
如果进程数n=2,且每个进程的步数m=2,那么执行轨迹有6种;如果进程数n=3,且每个进程的步数m=3,那么执行轨迹有1680种;如果进程数n=4,且每个进程的步数m=4,那么执行轨迹则高达 63063000 种!面对爆炸式增长的执行轨迹空间,如何确保每一个可能的执行轨迹是正确的,对于开发者而言是一个巨大的挑战。
此外,基于消息传递的分布式系统没有共享内存,从而也没有所谓的信号量或锁,因此编程难度更大。另外,需要说明的是,尽管一些分布式框架(如ZooKeeper等)提供了信号量、锁等更高层语意的封装,但本书研究的是实现分布式框架的内在原理,而非使用这些分布式框架提供的外在接口。
进程失败
进程失败是设计分布式算法正确性的第二大挑战。在顺序执行算法中,一般不考虑进程失败的场景,因为进程失败了,那么研究对象就没有了;而在分布式算法中,进程失败是必然要面对的问题,不能因为单节点失败导致整个分布式系统的失败。
在分布式算法中,一个进程只有两种状态,要么是正确的,要么是失败的。正确就表示不是失败的,失败就表示不是正确的。
进程失败有很多种,设计分布式算法很重要的一个方面就是选择合适的失败模型。
第一种失败被称为崩溃式失败,属于比较简单的失败,即进程停止执行任何步骤,不收发任何消息,就像进程完全退出执行了一样,例如进程被停止执行或者节点断电了。
第二种失败被称为遗漏式失败,这时进程并非完全停止执行步骤,而是不能正常收发消息,包括进程收不到它该收的消息,或者发不出它该发的消息。当出现网络拥塞或缓冲区溢出时,就会出现这种失败。
第三种失败被称为恢复后崩溃失败,即进程在一次或多次恢复后最终崩溃,或者无限的处于恢复、崩溃的反复之中。反之,如果进程在经过有限次的崩溃、恢复后,最终恢复到正确状态,那么这个进程仍然是正确的。
第四种失败被称为随意式失败,也叫拜占庭失败(Byzantine Failure)。之所以用“拜占庭”命名,是因为Lamport在1982年发表了一篇论文讨论这个问题,这篇论文的名字就叫《拜占庭将军问题》。
与前面所述的失败不一样的是,拜占庭失败的进程可能“不按剧本演戏”,即会在某个不可预测的时间点执行预设算法以外的逻辑。分布式算法面对很多的失败情形,检测这些失败是很复杂的工作。
一方面,这个检测有可能不准确,把一个正确的进程误判为失败的进程;另一方面,有的正确的进程能够检测到这个失败的进程,而有的正确的进程却没有检测到这个失败的进程。也就是说,不是所有的正确的进程都能及时检测到失败的进程,导致这些正确的进程对待这个失败的进程时出现了分歧(执行不同的代码逻辑)。更有甚者,一个系统不止有一个失败的进程,情况就变得更加复杂了。
链路失败
链路失败是设计分布式算法正确性的第三大挑战,主要表现在以下方面。
第一,窃听。当消息在链路上传递时,如果经历了基于广播的网络(例如以太网),或者经过了其他的中间设备,那么消息可能被分布式系统以外的第三方实体获得,从而造成信息泄露。不过,这种信息泄露并不影响分布式系统的正确运行。
第二,篡改。当消息在链路上传递时,如果被第三方获得了,那么第三方可以对该消息加以篡改后再次将其发送到链路上,从而使一些正确的进程在收到了第三方发出的伪造消息后,执行了本不应该执行的步骤,最终导致分布式系统失败。此时,进程仍然是正确的,因为它依然严格遵守预设的算法执行步骤,但由于链路的失败而造成了分布式系统的失败。
第三,丢失。当消息在链路上传递时,有可能被丢失。例如,当消息经由以太网进行传递时,恰逢某一台以太网交换机重启,在重启的某个瞬间就可能存在消息丢失的情况。
第四,乱序。当消息在链路上传递时,可能存在先发后至或者后发先至的情况。例如,在一个IP网络中,进程A向进程B先后发出了两个消息,分别为M1和M2,由于IP网络中的任意两点可以存在多条路由,因此有可能先发出的消息M1经历了一条距离较远、延迟较大的路由,而后发出的消息M2经历了一条距离较近、延迟较小的路由,从而导致先发的M1晚于后发的M2到达目的地进程B。
第五,重发。当消息在链路上传递时,同一个消息有可能被重复传递两次或以上次数。例如,在一个IP网络中,有一个消息M本应该经由网络设备A、B、C……向目标进程发送。由于这些网络设备均采用“存储-转发”模式进行消息转发,因此存在这么一个时刻:B刚把消息向C转发出去后(这时B也不知道C是否收到了消息),正准备向A发送确认报文时,B宕机了(或者B与A之间的物理链路断开了),因此A没有收到B的确认报文,于是A就选择另一条不同于“A->B->C”的路由(例如“A->D->C”路由)转发消息M。
而实际上,消息M已经被B转发到了C,因此C将两次收到消息M,一次是来自B,另一次是来自D。
有人认为,对于上述丢失、乱序、重发问题,都可以采用TCP/IP协议解决。在很多对性能要求不苛刻的工程实践中,也的确采用TCP/IP协议避免了丢失、乱序和重发问题。但是分布式算法本身并不要求像 TCP/IP 协议那样严格遵守“先进先出”(First In First Out,FIFO)原则。
实际上,在一个分布式系统中,由于多个进程并发执行,消息的接收进程本来就不对消息发送的先后顺序做假定,因此像TCP/IP协议这样强FIFO的链路其实是过于严格了。不过,再强调一下,绝大多数工程应用对性能的要求并未苛刻到TCP/IP协议难以满足的地步,相反,使用标准成熟的TCP/IP协议能够大幅节省工程开发时间,因此在实际应用中,TCP/IP 协议仍然不失为一种实用的选择。
此外,链路失败的复杂性并不仅体现在以上五点上,还体现在它与进程失败之间的关系上。比如,进程A向进程B发送一个心跳请求,但没有得到应有的回应,这既可能是因为进程B遇到了崩溃式失败,也可能是因为A和B之间的链路遇到了丢包。进程和进程之间除通过链路以外没有其他的通信手段,而链路也不可靠,那么一个进程凭什么知道另一个进程是正确还是失败呢?
后面会介绍同步、异步和部分同步三个模型来讨论这些问题。
综上所述,并发执行、进程失败、链路失败三大挑战使设计分布式算法非常复杂。Lamport 之所以在 2013 年获得图灵奖,是因为他从看似极度混乱的分布式现象中找到了内在联系,并建立了定义清晰、良好的模型,为人们学习、研究和利用分布式系统打下了坚实的理论基础。















 4408
4408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









