






在数据流上进行模型学习并根据模型做出判断或预测,是将统计学习和机器学习的理论和方法推广应用在流数据的结果。流数据不断输入模型学习算法,实时更新模型参数,在线训练所得模型能够更加及时和真切地表达当前状况。
数据研究人员在为数据建模时,有两种非常不同的思路,一种是统计学习模型,另一种是机器学习模型。统计学习模型以统计分析为基础,偏向于挖掘数据内部产生的机制,更加注重模型和数据的可解释性;而机器学习模型以各种机器学习方法为基础,偏向于用历史数据来预测未来数据,更加注重模型的预测效果。
我们分别从统计学习角度和机器学习角度来讨论实时流数据模型学习和预测的问题。
4.6.1 统计学习模型
在使用统计学习模型来建模时,最主要的问题在于确定随机变量的概率分布函数或概率密度函数。常见的离散型随机变量分布模型有0-1分布、二项分布、多项式分布和泊松分布等。常见的连续型随机变量分布模型有均匀分布、正态分布和指数分布等。在传统针对离线批数据做统计分析时,所建模型的重要目标是解释既有的数据。建模得到的分布参数是不变的,如高斯分布的期望和方差、泊松分布的期望等。
但是在针对流数据进行统计建模时,虽然确定分布参数固然重要,但分布的参数可能随着时间流逝而发生变化。一个很常见的例子就是,一家商店晚上的客流量一般会比早上多,而周末的客流量也会比工作日的客流量多。如果我们用柏松分布来对每小时的客流量建模,很明显这个柏松分布的期望是随着时间在变化的。所以,当在实时流上构建统计学习模型时,模型通常会包含两层,一层是随机变量在一段时间窗口内的概率分布函数,另一层是概率分布函数的参数是随时间变化的变量。
例如,考虑了期望随时间变化的柏松分布就需要重新定义为

其中,λ(t)是当前时刻对λ值的估计。
具体怎样计算这个估计值呢?估计λ(t)本身比较简单,因为对于柏松分布,其期望就是λ(t)的无偏估计。稍微需要考虑的是应该怎样更新这个估计值,可以有两种更新方式。
·逐事件更新,即每来一个新数据就重新估计一次。
·定周期更新,即每隔一段时间重新估计一次,如每小时重新估计一次。以上两种方式都是不错的选择,可以根据具体业务场景需要及是否能够满足实时计算的性能要求做出合适选择。
4.6.2 P-value检验
在传统的统计检测中,P-value检验是非常重要的手段。以小明和小花抛硬币为例,小花押“字”朝上,小明押“花”朝上。小明从口袋拿出一个硬币抛了1次,结果是“花”朝上。小花不服,要求再来一局……在反反复复抛了10次后,总共有9次“花”向上,只有1次“字”向上。对于这个结果,小花更加不服气了,觉得小明的硬币一定是一个“假”硬币。那怎样科学地判断小明的硬币是否是“假”硬币呢?这里就可以用到P-value检验方法。首先,我们假定硬币是“真”的,也就是“字”朝上和“花”朝上的概率都是0.5,那么抛10次硬币只有不超过1次“字”向上的概率是
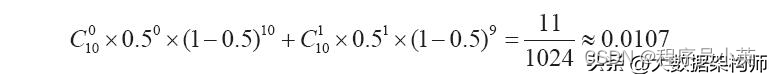
这么一算,只有百分之一的概率,小花当然可以理直气壮地怀疑小明对硬币做了手脚。在上面的这个例子中,0.0107就是P-value。由于P-value很小,故而可以推翻前面的“真”硬币假设。
当把统计学习模型应用在在线系统的异常检测时,P-value又有了一层新的含义。考虑统计PV(Page View,页面浏览量)的场景。根据过往经验和离线历史数据的统计,我们认为某个页面每秒钟的访问次数应该符合期望为6的泊松分布。可是实时流计算系统的统计结果显示当前1秒这个页面的访问量竟然达到了16次。这是正常流量波动还是系统受到了攻击?根据柏松分布的概率密度函数,计算得到P(X≥16) =0.0005。这个概率很小,意味着这秒的页面访问量和我们的预期并不相符。但此时我们并不是像之前P-value检验中那样拒绝假设,而是反过来断定1秒16次的访问量是异常行为,这预示着我们的系统可能正受到攻击。
4.6.3 机器学习模型
相比统计学习模型,使用机器学习的方法构建模型有一个极大的好处,即我们不需要对数据内在的产生机理有任何的先验知识,基本上只需要准备好模型使用的特征,确定要最优化的目标函数(也就是具体的机器学习模型),就可以让机器自动发现数据中潜在的产生模式,并对未知的数据做出预测。常见的机器学习模型有线性回归、逻辑回归、朴素贝叶斯、神经网络、决策树和随机森林等。下面我们以线性回归为例,初步介绍机器学习模型在流数据上是如何进行学习和预测的。
流数据是时间序列的一种表现形式。时间序列分析的重要目标之一是用历史序列来预测未来,如环境温度、股价和网站流量等。现在我们尝试用线性回归模型来预测下一个交易日的上证指数。以2003年全年的上证指数收盘价构成时间序列,我们的目标是用最近10个交易日收盘价预测下一个交易日的收盘价。所以,线性回归模型的输入就是最近10个交易日的收盘价,而输出则是下一个交易日的收盘价。
int numberOfVariables = 10;
UpdatingMultipleLinearRegression rm = new
MillerUpdatingRegression(numberOfVariables, true);
Queue<Double> xPrices = new LinkedList<>();
double[] predictPrices = new double[prices.length];
for (int i = 0; i < prices.length; i++) {
double price = prices[i];
// 用于训练和预测的数据量不足,所以跳过继续执行
if (i < numberOfVariables) {
xPrices.add(price);
predictPrices[i] = 0;
continue;
}
if (i <= numberOfVariables * 2 + 1) {
// 用于预测的数据量不足,所以跳过继续执行
predictPrices[i] = 0;
} else {
// 根据模型进行预测
double params[] = rm.regress().getParameterEstimates();
List<Double> xpList = new LinkedList<>();
xpList.add(1d);
xpList.addAll(xPrices);
double[] x_p = ArrayUtils.toPrimitive(xpList.toArray(new Double[0]));
double y_p = new ArrayRealVector(x_p).dotProduct(new ArrayRealVector
(params)); predictPrices[i] = y_p;
}
// 更新模型
double[] x = ArrayUtils.toPrimitive(xPrices.toArray(new Double[0]));
double y = price;
rm.addObservation(x, y);
xPrices.add(price);
xPrices.remove();
}
在上面的代码中,我们使用能够增量更新训练的线性回归模型实现MillerUpdating-Regression。按照时间顺序,依次将每天的收盘价price和前10个交易日的收盘价xPrices分别作为线性回归模型的因变量y和自变量x,构成一组观察记录,然后通过addObservation方法更新到模型。另外,使用regress函数获得当前训练所得线性回归模型的参数,再结合过去10个交易日的收盘价xPrices即可求得下一日收盘价的预测值y_p。图4-11是某段时期上证指数预测值与真实值的对比。
从图4-11中可以看出,预测收盘价曲线能够比较好地跟随真实收盘价曲线变化的趋势,但是并不能非常好地预测真实收盘价曲线的突变。
整体而言,预测收盘价曲线总是比真实收盘价曲线“慢半拍”。这意味着,我们并不能指望用这个线性回归模型从上证指数的变化中获利。
当然,这里用线性回归模型预测上证指数只是一个演示性质的例子。如果我们把上证指数换成其他参数,如网站流量、环境温度等,就可以将同样的方法推广应用到其他更适合线性回归模型的场景。

图4-11 某段时期上证指数预测值与真实值的对比
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









