






Apache Storm
Apache Storm(简称Storm)是一款由Twitter开源的大规模分布式流计算平台。Storm出现得较早,是分布式流计算平台的先行者。
不过随着各种流计算平台的出现,Storm也在不断尝试着改进和改变。
Storm可以说是最早被大家广泛接受的大规模分布式流计算框架,所以我们先从对Storm的讨论开始。
系统架构
图6-1展示了Storm系统架构。Storm集群由两种节点组成:Master节点和Worker节点。Master节点运行Nimbus进程,用于代码分发、任务分配和状态监控。Worker节点运行Supervisor进程和Worker进程,其中Supervisor进程负责管理Worker进程的整个生命周期,而Worker进程创建Executor线程,用于执行具体任务(Task)。在Nimbus和Supervisor之间,还需要通过Zookeeper来共享流计算作业状态,协调作业的调度和执行。
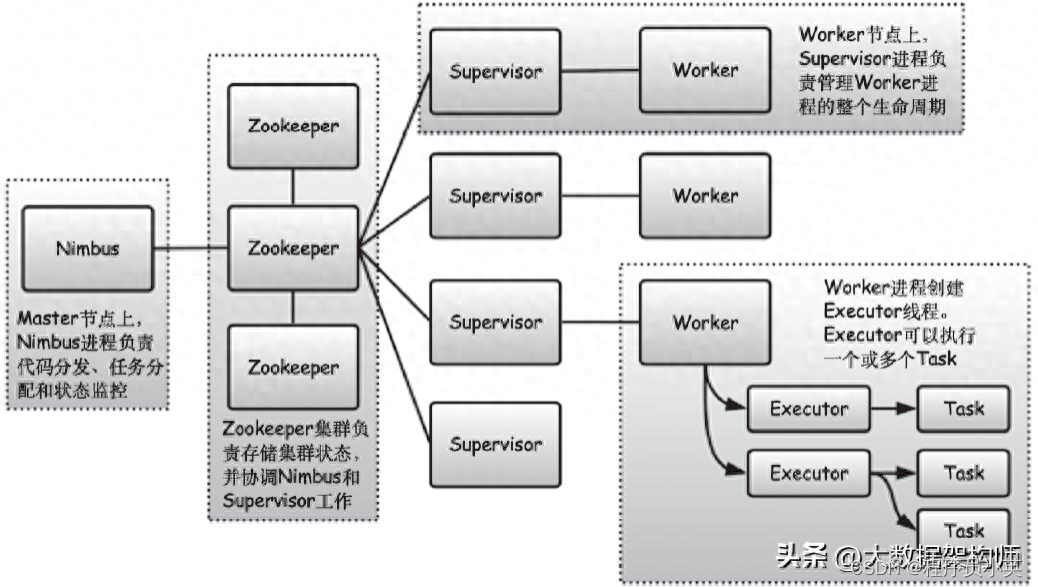
图6-1 Storm系统架构
流的描述
在Storm中,通过Topology、Tuple、Stream、Spout和Bolt等概念来描述一个流计算作业。
·Topology:也就是第3章中用来描述流计算作业的DAG,它完整地描述了流计算应用的执行过程。
当Topology部署在Storm集群上并开始运行后,除非明确停止,否则它会一直运行下去。这和MapReduce作业在完成后就退出的行为是不同的。Topology由Spout、Bolt和连接它们的Stream构成,其中Topology的节点对应着Spout或Bolt,而边则对应着Stream。
·Tuple:用于描述Storm中的消息,一个Tuple可以视为一条消息。
·Stream:这是Storm中的一个核心抽象概念,用于描述消息流。
Stream由Tuple构成,一个Stream可以视为一组无边界的Tuple序列。
·Spout:用于表示消息流的输入源。Spout从外部数据源读取数据,然后将其发送到消息流中。
·Bolt:Storm进行消息处理的地方。Bolt负责消息的过滤、运算、聚类、关联、数据库访问等各种逻辑。开发者在Bolt中实现各种流处理逻辑。
流的执行
流的执行是指在流计算应用中,输入的数据流经过处理最后输出到外部系统的过程。通常情况下,一个流计算应用会包含多个执行步骤,并且这些步骤的执行步调极有可能不一致。因此,需要使用反向压力功能来实现不同执行步骤间的流控。
早期版本的Storm使用TopologyBuilder来构建流计算应用,但是以新一代流计算框架的角度来看,基于TopologyBuilder的API在实际使用时并不直观和方便。所以,与时俱进的Storm从2.0.0版本开始,提供了更加现代的流计算应用接口——Strea.API。虽然目前Strea.API仍然处于实验阶段,但如果新开发一个Storm流计算应用,还是建议直接使用Strea.API,因为这种风格的流计算编程接口才是流计算应用开发的未来。在接下来的讨论中,我们直接基于Strea.API,从流的输入、流的处理、流的输出和反向压力4个方面来讨论Storm中流的执行过程。
1.流的输入
Storm从Spout输入数据流,并用StreamBuilder从Spout构建一个流。下面是一个典型的用StreamBuilder从Spout构建Stream的例子。
public class DemoWordSpout extends BaseRichSpout {
// 忽略了其他字段和方法
public void nextTuple() {
Utils.sleep(100L);
String[] words = new String[]{"apple", "orange", "banana", "mango",
"pear"};
Random rand = new Random();
String word = words[rand.nextInt(words.length)];
this._collector.emit(new Values(new Object[]{word}));
}
}
StreamBuilder builder = new StreamBuilder();
Stream<String> words = builder.newStream(new DemoWordSpout(), new
ValueMapper<String>(0));
Spout的核心方法是nextTuple,从名字上就可以看出这个方法的作用是逐条从消息源读取消息,并将消息表示为Tuple。不同数据源的nextTuple方法的实现方式不相同。另外,Spout还有两个与消息传递可靠性和故障处理相关的方法,即ack和fail。当消息发送成功时,可以通过调用ack方法从发送消息列表中删除已成功发送的消息。当消息发送失败时,可以通过fail方式尝试重新发送或在最终失败时做出合适处理。
2.流的处理
Storm的Stream API 与更新一代的流计算框架(如SparkStreaming、Flink等)更加相似。总体而言,它提供了3类API。第一类API是常用的流式处理操作,如filter、map、reduce、aggregate等。第二类API是流数据状态相关的操作,比如window、join、cogroup等。第三类API是流信息状态相关的操作,目前有updateStateByKey和stateQuery。下面是一个对Stream进行处理的例子。
wordCounts = words
.mapToPair(w -> Pair.of(w, 1))
.countByKey();
在上面的例子中,先用mapToPair将单词流words转化为计数元组流,然后通过countByKey将计数元组流转化为单词计数流wordCounts。
3.流的输出
Storm的Strea.API提供了将流输出到控制台、文件系统或数据库等外部系统的方法。目前Strea.API提供的输出操作包括print、peek、forEach和to。其中,peek是对流的完全原样中继,并可以在中继时提供一段操作逻辑,因而peek方法可以用于方便地检测流在任意阶段的状况。forEach方法是最通用的输出方式,可以执行任意逻辑。
to方法允许将一个Bolt作为输出方法,可以方便地继承早期版本中已经存在的各种输出Bolt实现。下面的例子演示了将单词计数流输出到控制台。
wordCounts.forEach(new WordCountExample.Print2FileConsumer());
public static class Print2FileConsumer<T> implements Consumer<T> {
// 忽略了其他字段和方法
public void appendToFile(Object line) {
Files.write(Paths.get("/logs/console.log"),
String.valueOf(line + "\n").getBytes(),
StandardOpenOption.APPEND, StandardOpenOption.CREATE);
}
@Override
public void accept(T input) {
appendToFile(input);
}
}
4.反向压力
Storm支持反向压力。早期版本的Storm通过开启acker机制和max.spout.pending参数实现反向压力。当下游Bolt处理较慢,Spout发送出但没有被确认的消息数超过max.spout.pending参数设定值时,Spout就暂停发送消息。这种方式实现了反向压力,但有一个不算轻微的缺陷。一方面,静态配置max.spout.pending参数很难使得系统在运行时有最佳的反向压力性能表现。另一方面,这种反向压力实现方式本质上只是在消息源头对消息发送速度做限制,而不是对流处理过程中各个阶段做反向压力,它会导致系统的处理速度发生比较严重的抖动,降低系统的运行效率。
在较新版本的Storm中,除了监控Spout发送出但没有被确认的消息数外,还需监控每级Bolt接收队列的消息数量。当消息数超过阈值时,通过Zookeeper通知Spout暂停发送消息。这种方式实现了流处理过程中各个阶段反向压力的动态监控,能够更好地在运行时调整对Spout的限速,降低了系统处理速度的抖动,也提高了系统的运行效率。
流的状态
前面我们将流的状态分成两种:流数据状态和流信息状态。
在流数据状态方面,早期版本的Storm提供了Trident、窗口(window)和自定义批处理3种有状态处理方案。Trident将流数据切分成一个个的元组块(tuple batch),并将其分发到集群中处理。
Trident针对元组块的处理,提供了过滤、聚合、关联、分组、自定义函数等功能。其中,聚合、关联、分组等功能在实现过程中涉及状态保存的问题。另外,Trident在元组块处理过程中可能失败,失败后需要重新处理,这个过程涉及状态保存和事务一致性问题。因此,Trident有针对性地提供了一套Trident状态接口(Trident StateAPI)来处理状态和事务一致性问题。Trident支持3种级别的Spout和State:Transactional、Opaque Transactional和NoTransactional。其中,Transactional提供了强一致性保证机制,Opaque Transactional提供了弱一致性保证机制,No-Transactional未提供一致性保证机制。Storm支持Bolt按窗口处理数据,目前实现的窗口类型包括滑动窗口(sliding window)和滚动窗口(tumblingwindow)。
Storm支持自定义批处理方式。Storm系统内置了定时消息机制,即每隔一段时间向Bolt发送tick元组,Bolt在接收到tick元组后,可以根据需求自行决定什么时候处理数据、处理哪些数据等,在此基础上就可实现各种自定义的批处理方式。例如,可以通过tick实现窗口功能(当然Storm本身已经支持),或实现类似于Flink中watermark的功能(Storm本身也已经支持)等。
从2.0.0版本引入的Stream API提供了window、join、cogroup等流数据状态相关的API,这些API更加通用,使用起来也更方便,因此再次建议读者直接使用这类API来开发Storm流计算应用。在流信息状态方面,早期版本Storm中的Trident状态接口包含对流信息状态的支持,并且还支持了3种级别的事务一致性。例如,使用Trident状态接口可以实现单词计数功能。但是Trident状态与Trident支持的处理功能耦合太紧,这使得Trident状态接口的使用并不通用。
例如,在非Trident的Topology中就不能使用Trident状态接口了。所以,当使用Storm做实时流计算时,经常需要用户自行实现对流信息状态的管理。例如,使用Redis来记录事件发生的次数。不过,最新版本Storm的Strea.API已经逐渐开始引入更通用的流信息状态接口,目前提供的updateStateByKey和stateQuery就是这种尝试。
消息传达可靠性保证
Storm提供了不同级别的消息可靠性保证机制,包括尽力而为(best effort)、至少一次(at least once)和通过Trident实现的精确一次(exactly once)。在Storm中,一条消息被完全处理,是指代表这条消息的元组及由这个元组生成的子元组、孙子元组、各代重孙元组都被成功处理。
反之,只要这些元组中有任何一个元组在指定时间内处理失败,那就认为这条消息是处理失败的。
不过,要使用Storm的这种消息完全处理机制,需要在程序开发时,配合Storm系统做两件额外的事情。首先,当在处理元组过程中生成了子元组时,需要通过ack告知Storm系统。其次,当完成对一个元组的处理时,也需要通过ack或fail告知Storm系统。在具体业务逻辑开发过程中,用户根据业务需要选择合理的消息保证级别实现即可。很多场景下并非一定要保证严格的数据一致性,毕竟越严格的消息保证级别通常实现起来也会越复杂,性能损耗也会更大。














 3237
3237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









