







Spark简介
Spark最初由美国加州伯克利大学(UCBerkeley)的AMP(Algorithms, Machines and People)实验室于2009年开发,是基于内存计算的大数据并行计算框架,可用于构建大型的、低延迟的数据分析应用程序。Spark加入Apache孵化器项目后,开始获得迅猛的发展,Spark是Apache软件基金会最重要的三大分布式计算系统开源项目之一(即Hadoop、Spark、Storm)。其计算速度快于MapReduce。
Spark优势
Spark具有如下几个主要特点:
- 运行速度快:Spark使用先进的DAG(Directed Acyclic Graph,有向无环图)执行引擎,以支持循环数据流与内存计算,基于内存的执行速度可比Hadoop MapReduce快上百倍,基于磁盘的执行速度也能快十倍;
- 容易使用:Spark支持使用Scala、Java、Python和R语言进行编程,简洁的API设计有助于用户轻松构建并行程序,并且可以通过Spark Shell进行交互式编程;
- 通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件,这些组件可以无缝整合在同一个应用中,足以应对复杂的计算;
- 运行模式多样:Spark可运行于独立的集群模式中,或者运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源。
Spark在借鉴Hadoop MapReduce优点的同时,很好地解决了MapReduce所面临的问题。相比于MapReduce,Spark主要具有如下优点:
- Spark的计算模式也属于MapReduce,但不局限于Map和Reduce操作,还提供了多种数据集操作类型,编程模型比MapReduce更灵活;
- Spark提供了内存计算,中间结果直接放到内存中,带来了更高的迭代运算效率;
- Spark基于DAG的任务调度执行机制,要优于MapReduce的迭代执行机制。
Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。使用Hadoop进行迭代计算非常耗资源,因为每次迭代都需要从磁盘中写入、读取中间数据,IO开销大。而Spark将数据载入内存后,之后的迭代计算都可以直接使用内存中的中间结果作运算,避免了从磁盘中频繁读取数据。
在实际进行开发时,使用Hadoop需要编写不少相对底层的代码,不够高效。相对而言,Spark提供了多种高层次、简洁的API,通常情况下,对于实现相同功能的应用程序,Spark的代码量要比Hadoop少2-5倍。更重要的是,Spark提供了实时交互式编程反馈,可以方便地验证、调整算法。
尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop,主要用于替代Hadoop中的MapReduce计算模型。实际上,Spark已经很好地融入了Hadoop生态圈,并成为其中的重要一员,它可以借助于YARN实现资源调度管理,借助于HDFS实现分布式存储。此外,Hadoop可以使用廉价的、异构的机器来做分布式存储与计算,但是,Spark对硬件的要求稍高一些,对内存与CPU有一定的要求。
spark生态
Spark专注于数据的处理分析,而数据的存储还是要借助于Hadoop分布式文件系统HDFS、Amazon S3等来实现的。因此,Spark生态系统可以很好地实现与Hadoop生态系统的兼容,使得现有Hadoop应用程序可以非常容易地迁移到Spark系统中。

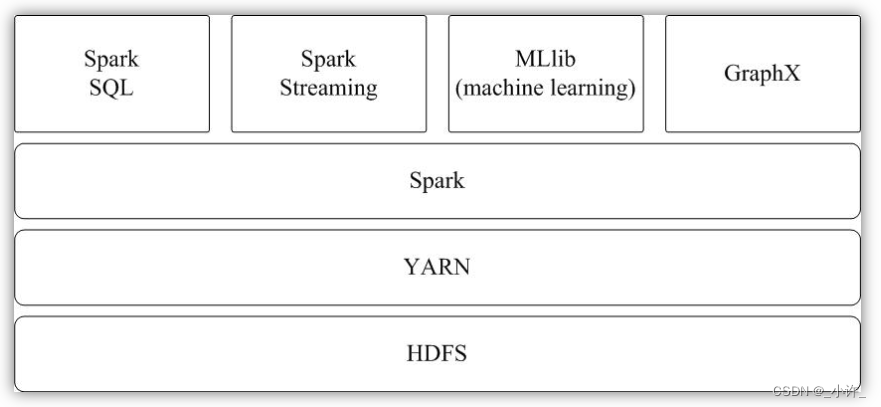
Spark的生态系统主要包含了Spark Core、Spark SQL、Spark Streaming、MLLib和GraphX 等组件,各个组件的具体功能如下:
- Spark Core:Spark Core包含Spark的基本功能,如内存计算、任务调度、部署模式、故障恢复、存储管理等。Spark建立在统一的抽象RDD之上,使其可以以基本一致的方式应对不同的大数据处理场景;通常所说的Apache Spark,就是指Spark Core;
- Spark SQL:Spark SQL允许开发人员直接处理RDD,同时也可查询Hive、HBase等外部数据源。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行查询,并进行更复杂的数据分析;
- Spark Streaming:Spark Streaming支持高吞吐量、可容错处理的实时流数据处理,其核心思路是将流式计算分解成一系列短小的批处理作业。Spark Streaming支持多种数据输入源,如Kafka、Flume和TCP套接字等;
- MLlib(机器学习):MLlib提供了常用机器学习算法的实现,包括聚类、分类、回归、协同过滤等,降低了机器学习的门槛,开发人员只要具备一定的理论知识就能进行机器学习的工作;
- GraphX(图计算):GraphX是Spark中用于图计算的API,可认为是Pregel在Spark上的重写及优化,Graphx性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
Spark安装
spark安装需要hadoop环境,参考Ubuntu 20.04下搭建单机伪分布式Hadoop
解压压缩包,配置环境变量
# 配置环境变量
sudo /etc/profile
# 重启环境变量
source /etc/profile
启动spark:
spark-shell
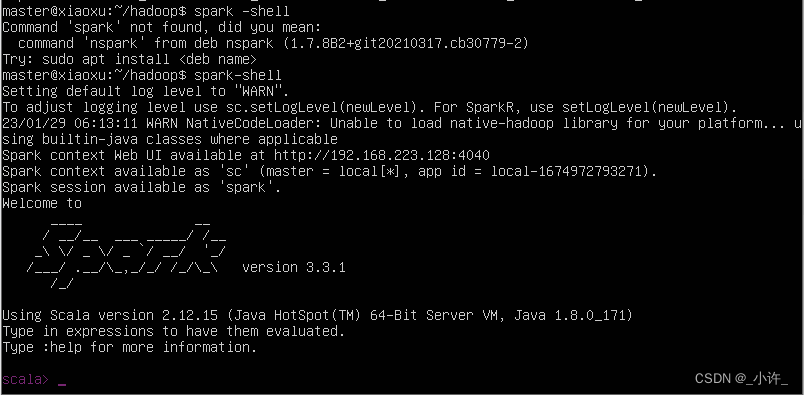
spark是用scala语言,最好会scala,如果不会百度检索如何用java操作spark。
Spark部署模式主要有四种:Local模式(单机模式)、Standalone模式(使用Spark自带的简单集群管理器)、YARN模式(使用YARN作为集群管理器)和Mesos模式(使用Mesos作为集群管理器)。
这里是Local模式(单机模式)的 Spark安装。
Spark应用程序在集群上部署运行时,可以由不同的组件为其提供资源管理调度服务(资源包括CPU、内存等)。比如,可以使用自带的独立集群管理器(standalone),或者使用YARN,也可以使用Mesos。因此,Spark包括三种不同类型的集群部署方式,包括standalone、Spark on Mesos和Spark on YARN。
1.standalone模式
与MapReduce1.0框架类似,Spark框架本身也自带了完整的资源调度管理服务,可以独立部署到一个集群中,而不需要依赖其他系统来为其提供资源管理调度服务。在架构的设计上,Spark与MapReduce1.0完全一致,都是由一个Master和若干个Slave构成,并且以槽(slot)作为资源分配单位。不同的是,Spark中的槽不再像MapReduce1.0那样分为Map 槽和Reduce槽,而是只设计了统一的一种槽提供给各种任务来使用。
2.Spark on Mesos模式
Mesos是一种资源调度管理框架,可以为运行在它上面的Spark提供服务。Spark on Mesos模式中,Spark程序所需要的各种资源,都由Mesos负责调度。由于Mesos和Spark存在一定的血缘关系,因此,Spark这个框架在进行设计开发的时候,就充分考虑到了对Mesos的充分支持,因此,相对而言,Spark运行在Mesos上,要比运行在YARN上更加灵活、自然。目前,Spark官方推荐采用这种模式,所以,许多公司在实际应用中也采用该模式。
3. Spark on YARN模式
Spark可运行于YARN之上,与Hadoop进行统一部署,即“Spark on YARN”,其架构如图9-13所示,资源管理和调度依赖YARN,分布式存储则依赖HDFS。
Spark使用
spark-shell交互式编程
通过spark-shell交互式学习,加深Spark程序开发的理解。这里介绍Spark Shell 的基本使用。Spark shell 提供了简单的方式来学习 API,并且提供了交互的方式来分析数据。你可以输入一条语句,Spark shell会立即执行语句并返回结果,这就是我们所说的REPL(Read-Eval-Print Loop,交互式解释器),为我们提供了交互式执行环境,表达式计算完成就会输出结果,而不必等到整个程序运行完毕,因此可即时查看中间结果,并对程序进行修改,这样可以在很大程度上提升开发效率。
Spark Shell 支持 Scala 和 Python,这里使用 Scala 来进行介绍。
如果不会scala可以安装pyspark通过python的交互语言操作。
前面已经安装了Hadoop和Spark,如果Spark不使用HDFS和YARN,那么就不用启动Hadoop也可以正常使用Spark。如果在使用Spark的过程中需要用到 HDFS,就要首先启动 Hadoop。(本地使用不需要启动hadoop)

:quit
Ctrl + c [连按2次] 退出
Spark独立应用程序编程
除了交互式编程外使用scala的独立应用编程。Scala独立应用程序和java独立应用一样,java通过maven包管理工具使开发更加方便,scala使用sbt包管理工具。sbt编程语言scala的构建工具配置及项目构建(附带网盘下载)
构建完sbt项目后
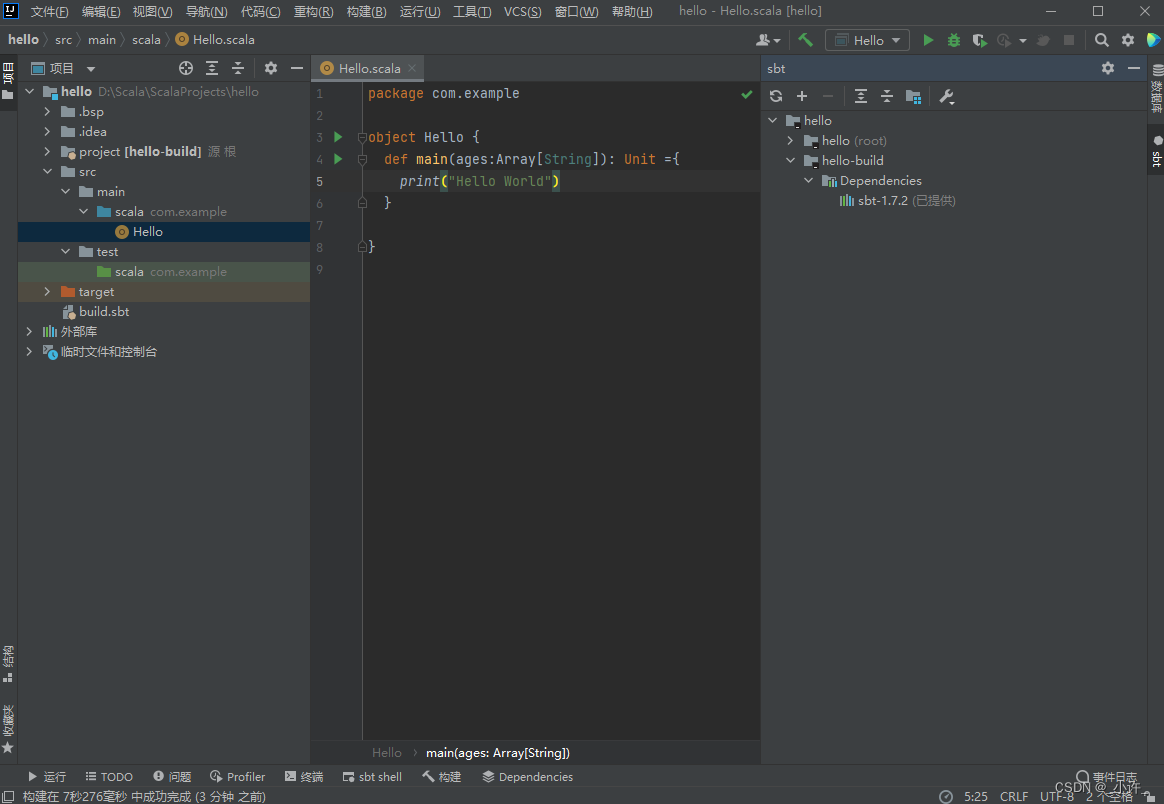
package com.example
object Hello {
def main(ages:Array[String]): Unit ={
print("Hello World")
}
}
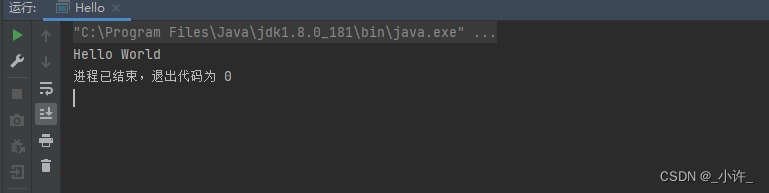
spark-shell程序
复制文件
创建word.txt文件,内容如下:

启动spark输入如下语句
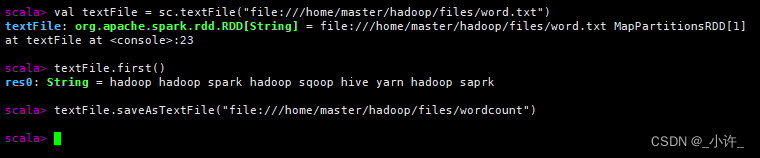
sc是spark的上下文连接,是操纵spark的关键,在初始化时就已经创建:
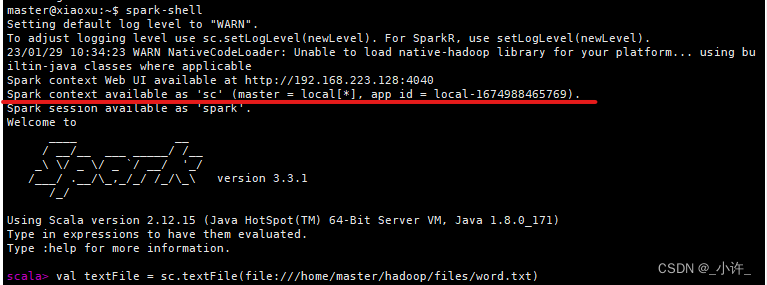
textFile是sc的操作txt文件的方法,该对象包换若干方法操作txt文件。
//加载本地文件
val textFile = sc.textFile("file:///usr/.../word.txt")
//加载hdfs文件
val textFile = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt")


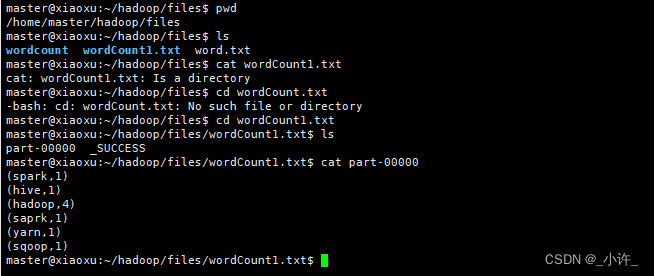
在生成的wordcount下生成了part-00000文件是saveAsTextFile()方法,为保存内容,具有和word.txt同样的内容。
词频统计
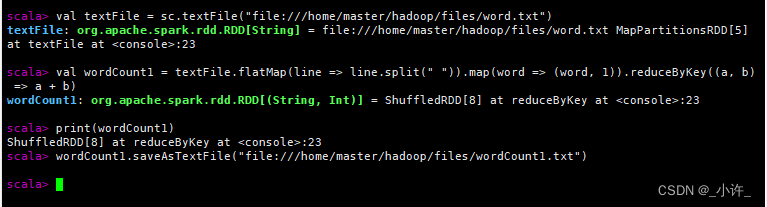
//加载文件
val textFile = sc.textFile("file:///home/master/hadoop/files/word.txt")
//词频统计逻辑
val wordCount1 = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
//打印对象
print(wordCount1)
//遍历对象
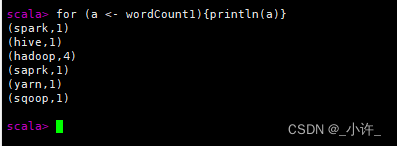
for (a <- wordCount1){println(a)}
//将该对象保存到路径下wordCount1.txt,最后一个是目录不是文件
wordCount1.saveAsTextFile("file:///home/master/hadoop/files/wordCount1.txt")
学习资源厦门大学林子雨老师大数据教程

















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











