







其实很简单,就是基于主从复制架构,简单来说,就搞一个主库,挂多个从库,然后我们就单单只是写主库,然后主库会自动把数据给同步到从库上去。
MySQL 主从复制原理的是啥?
主库将变更写入 binlog 日志,然后从库连接到主库之后,从库有一个 IO 线程,将主库的 binlog 日志拷贝到自己本地,写入一个 relay 中继日志中。接着从库中有一个 SQL 线程会从中继日志读取 binlog,然后执行 binlog 日志中的内容,也就是在自己本地再次执行一遍 SQL,这样就可以保证自己跟主库的数据是一样的。
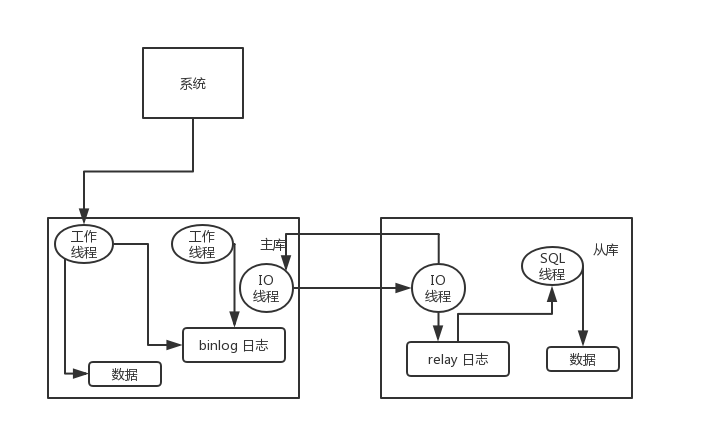
这里有一个非常重要的一点,就是从库同步主库数据的过程是串行化的,也就是说主库上并行的操作,在从库上会串行执行。所以这就是一个非常重要的点了,由于从库从主库拷贝日志以及串行执行 SQL 的特点,在高并发场景下,从库的数据一定会比主库慢一些,是有延时的。所以经常出现,刚写入主库的数据可能是读不到的,要过几十毫秒,甚至几百毫秒才能读取到。
而且这里还有另外一个问题,就是如果主库突然宕机,然后恰好数据还没同步到从库,那么有些数据可能在从库上是没有的,有些数据可能就丢失了。
所以 MySQL 实际上在这一块有两个机制,一个是半同步复制,用来解决主库数据丢失问题&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









