







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
之后配置 fat.config 文件,将 sudo_password 改成正确的值,firmadyne_path 不需要改。
仿真的方式是 fat.py + 固件的路径名
$ ./fat.py <firmware file>
在我的环境下使用 python3 fat.py <firmware file> 命令运行会出现固件解压失败的问题;<firmware file> 不使用绝对路径也会出错,需要注意一下。
运行后 FAT 能正常识别出网卡信息说明能够仿真成功,之后按回车键就可以把系统跑起来。

IoT-vulhub
一个存放复现 IOT 漏洞的 docker 环境的项目,由于其中内置的 docker 比较老外加 docker 本身的限制导致调试比较困难,但是项目本身搭建环境的思想还是值得学习的。
汇编基础
ARM32
关于汇编
由于 ida 对 arm 汇编进行了“美化”,因此我们通过 ida 看到的不是原生的 arm 汇编。这里我们借助 catstione 和 keystone-engine 库定义了几个辅助函数方便查看原生汇编。
from keystone import \*
from capstone import \*
import idc
asmer =Ks(KS_ARCH_ARM,KS_MODE_ARM)
disasmer=Cs(CS_ARCH_ARM,CS_MODE_ARM)
def disasm(machine_code, addr=0):
l = ""
for i in disasmer.disasm(machine_code, addr):
l += "{:8s} {};\n".format(i.mnemonic, i.op_str)
return l.strip('\n')
def asm(asm_code, addr=0):
l = b''
for i in asmer.asm(asm_code, addr)[0]:
l += bytes([i])
return l
def get\_disasm(addr):
return disasm(idc.get_bytes(addr, idc.next_head(addr) - addr), addr)
def get\_asm(addr):
return asm(get_disasm(addr), addr)
def get\_code(start, end):
cur = start
code = ""
while cur < end:
code += "0x%08x %s\n"%(cur, get_disasm(cur))
cur = idc.next_head(cur)
return code
寄存器和指令基本格式
寄存器
| 寄存器名称 | 寄存器描述 |
|---|---|
| R0 | 函数的第1个参数, 以及保存函数返回的结果 |
| R1 - R3 | 保存函数的第2~4个参数 |
| R4 – R8 | 通用寄存器,其中R7在系统调用时存储调用号 |
| R9 | 平台相关 |
| R10 | 通用寄存器, 可用于保存局部变量 |
| R11/FP | 栈帧指针, 用于记录栈帧 |
| R12 | 过程间调用, 保存函数及其调用的子函数之间的立即数 |
| R13/SP | 栈指针, 指向栈顶 |
| R14/LR | 链接寄存器, 用于保存子函数调用的返回地址 |
| R15/PC | 程序计数器, 保存当前执行指令地址+8 |
| CSPR | 当前程序状态寄存器 |
在 pwndbg 项目的 pwndbg/lib/regs.py 中可以修改寄存器显示。
arm = RegisterSet(
retaddr=("lr",),
flags={"cpsr": arm_cpsr_flags},
gpr=("r0", "r1", "r2", "r3", "r4", "r5", "r6", "r7", "r8", "r9", "r10", "r11", "r12", "lr"),
args=("r0", "r1", "r2", "r3"),
retval="r0",
)
常用指令
| 指令 | 描述 | 指令 | 描述 |
|---|---|---|---|
| MOV | 移动数据 | EOR | 按位异或 |
| MVN | 移动并取反 | LDR | 加载 |
| ADD | 加 | STR | 存储 |
| SUB | 减 | LDM | 加载多个 |
| MUL | 乘 | STM | 存储多个 |
| LSL | 逻辑左移 | PUSH | 入栈 |
| LSR | 逻辑右移 | POP | 出栈 |
| ASR | 算术右移 | B | 跳转 |
| ROR | 循环右移 | BL | 跳转并将返回地址保存到LR寄存器 |
| CMP | 比较 | BX | 跳转并切换Arm/Thumb模式 |
| AND | 按位与 | BLX | 跳转,保存返回地址,并切换ARM/Thubmb模式 |
| ORR | 按位或 | SWI/WVC | 系统调用 |
总体设计和指令规格
- 没有隐式内存操作指令
- 0-3个操作数,内存操作数和立即数不能同时存在,内存操作数至多出现1次,寄存器操作数总在最前
特殊情况:
- C标志位使用
- 读PC寄存器
断点
在 IDA 调试中,无论是断点还是单步调试都是依靠 #UND 0x10 触发断点实现,且 IDA 调试器 无法分辨出改指令是否是自己设置的,在读取数据时会按实际情况返回数据。
该指令在 Arm 模式和 Thumb 模式的硬编码不同:
- Arm 模式断点:
F0 01 F0 E7 - Thumb 模式断点:
10 DE
PC寄存器相关指令
MOV PC, R0:相当于PC = R0MOV R0, PC- 在 Arm 模式中相当于
R0 = PC + 8 - 在 Thumb 模式中相当于
R0 = PC + 4
- 在 Arm 模式中相当于
LDR R0, [PC,#x]
可以看做 3 步:- 读 PC 寄存器的值,规则与
MOV R0, PC相同,即根据处于 Arm 或 Thumb 模式加上相应的偏移 - 将读出的值再加上偏移 x 作为地址,然后将地址向下取整做 4 字节对齐
- 从计算出的地址的值读入到 R0 寄存器中
- 读 PC 寄存器的值,规则与
条件和标志位响应
CPSR 寄存器
CPSR 寄存器结构如下图所示:

各标志位含义:
N,bit[31]
若运算结果为 0 或正数则该该标志位置 0,若运算结果为负数则该标志位置 1 。Z,bit[30]
运算结果为 0 则置 1,否则置 0 。C,bit[29]
无符号数溢出,加法溢出置 1,减法溢出置 0。V,bit[28]
有符号数溢出T,bit[5]T = 0表示 Arm 模式T = 1表示 Thumb 模式。
注意:指令是否影响标志位取决于是否是否加 S 后缀(大多数情况,具体看指令硬编码第 20 位是否置 1),比如 MOV 不影响标志位但 MOVS 影响标志位。
执行条件
cond 标志的值及其对应含义如下表所示:

cond 标志位位于指令硬编码的高 4 比特,在执行时根据标志寄存器决定该指令是否执行。
MOV 指令
MOV 不访问内存,因此操作数只能是寄存器或立即数。
MOV 立即数
由于 ARM 汇编指令长度的影响,对立即数范围有严格的限制。允许 MOV 的立即数有如下几类:
- 立即数不超过 16 位

该指令在给寄存器低 16 比特赋值的同时会将寄存器高 16 比特清零。 - 立即数可以用 不超过8 比特的数循环右移不超过 32 的偶数得到

其中 imm12 中的低 8 比特是需要循环右移的数,高 4 比特乘 2 是需要循环右移的次数。 - (MOVT)立即数不超过 16 位且需要移动到寄存器高 16 位(通常与 MOV 配合使且应当先 MOV 后 MOVT)

该指令在给寄存器高 16 比特赋值的同时不会将寄存器低 16 比特清零。
MOV 寄存器, 寄存器
- 寄存器 + 立即数移位

例如MOV R0, R1,LSL#4,该指令等同于LSL R0, R1,#4。
移位类型由 stype 决定,移位的值为 imm5 。 - 寄存器 + 寄存器移位

例如MOV R0, R1,LSR R2,该指令等同于LSR R0, R1,R2。
基本整型运算
相关指令
ADD:加ADR:PC 与操作数相加结果放入结果寄存器中ADRL:伪指令,与ADR相似,不过通过类似MOV + MOVT的方式使得寻址范围更大CMN:加,只影响标志寄存器
SUB:减CMP:减,只影响标志寄存器
RSB:反减AND:与TST:与,只影响标志寄存器
BIC:第二个操作数与第三个操作数的反码逻辑与结果放在第一个寄存器中ORR:或EOR:异或TEQ:异或,只影响标志寄存器
LSL:逻辑左移LSR:逻辑右移ASR:算术右移
ADD 指令(举例)
- ADD 立即数

这里 12 比特长的立即数与前面 MOV 的机制一样,采用移位的方式将其扩展为 32 位范围。 - ADD 寄存器,立即数移位

与 MOV 机制相同,例如ADD R0, R1, R2,LSL #4。 - ADD 寄存器,寄存器移位

- ADR
本质还是 ADD,不过被加数为 PC 寄存器。由于设计到读 PC 寄存器,因此根据当前所处的模式,读出来的 PC 寄存器的值会加上相应的偏移。
访存指令
数据流向
- LDR:
寄存器 ← 内存,例:ldr r0, [pc, #8],ldr r3, [r5], #4。 - STR:
寄存器 → 内存,例:str r3, [r4]。
操作的寄存器和内存地址
- 寄存器:
LDR R0, [R1] - 寄存器 + 偏移(立即数):
LDR R0, [R1,#4]

- 12 位立即数即偏移,不存在移位扩展。
- U 为立即数的正负号。
- P = 0 则外偏移,W = 1 则内偏移,内外偏移不能同时存在。
- 寄存器 + 移位偏移(寄存器):
LDR R0, [R1,R2,LSL #4]

LDR R0, [R1,R2,LSL R3]
后续的附加行为
- 内偏移:
LDR R0, [R1,#4]!
该指令表示将[R1 + 4]赋值给 R0 ,然后将 R1 的值设为R1 + 4。 - 外偏移:
LDR R0, [R1],#4
该指令表示将[R1]赋值给 R0 ,然后将 R1 的值设为R1 + 4。
注意:外偏移和内偏移不能同时存在。
根据附加附加行为性质可知:
PUSH R0相当于STR R0, [SP,#-4]!POP R0相当于LDR R0, [SP],#4
块访存指令
指令结构
LDM\STM+后缀 寄存器(!), {寄存器组}
- LDM 表示将寄存器指向的地址的数据依次存放在寄存器组中。
- STM 表示将寄存器组中的数据依次存放在寄存器指向的地址。
- 寄存器组可以写作范围,比如
{R0-R4};也可指定具体寄存器,比如{R0,R2,R3}。但是读写操作是按照寄存器下标的顺序依次操作寄存器组中的寄存器(编号小的在低地址),因为指令对应硬编码无法体现出寄存器组的顺序。
以 LDM 为例:

后缀类型

- I 表示地址加;D 表示地址减。
- A 表示先读写内存,再改变指向;B 表示先改变指向,再读写内存。
- 带 ! 表示修改的指向写入寄存器;不带 ! 表示修改的指向不写入寄存器。
- 如果操作地址寄存器为 SP 时LDMFD 相当于 LDMIA ;STMFD 相当于 STMDB 。
根据不同后缀类型的性质可以确定如下用法:
- STMFD 相当于 PUSH
- LDMFD 相当于 POP
- STM\LDMIA 可以快速复制内存
分支和模式切换
B + imm

- 跳转目标:立即数
- 模式切换:不带模式切换
- 写入 LR 的值:不影响 LR 寄存器
指令编码的立即数为目标地址与 PC 寄存器的差值除 4 。由于涉及读 PC 寄存器,因此根据当前模式要加上相应的偏移。跳转范围为 PC 值加上正负 32M 的偏移。
BL + imm

- 跳转目标:立即数
- 模式切换:不带模式切换
- 写入 LR 的值:
下一条指令的地址 | T 标志位
BX + reg

- 跳转目标:寄存器中的值去掉最低一位
- 模式切换:跳转时将寄存器中存储的地址的最低一位写入 T 标志位
- 写入 LR 的值:不影响 LR 寄存器。
BLX + imm

- 跳转目标:立即数
- 模式切换:一定切换模式
- 写入 LR 的值:
下一条指令的地址 | T 标志位
BLX + reg

- 跳转目标:寄存器中的值去掉最低一位
- 模式切换:跳转时将寄存器中存储的地址的最低一位写入 T 标志位
- 写入 LR 的值:
下一条指令的地址 | T 标志位
拓展
BX reg和MOV PC, reg的区别:BX 可以切换模式,MOV 不能切换模式。LDR PC, [R0]:可以做模式切换,常用于 PLT 表中调用 GOT 表中对应的函数地址(最低位表示模式)。LDMFD SP!, {R11,PC}:同样可以做模式切换,常与STMFD SP!, {R11,PC}一起用于函数调用时保存栈帧和返回地址。
Thumb 模式
特点
- 段指令一般不使用 R8-R12
- 一般没有条件码和标志响应位,指令默认影响标志位
- 运算指令优先对第一,第二操作数相同情况有短指令编码。对于 STMFD 和 LDMFD,如果以 SP 寄存器的值作为地址则简写为 PUSH 和 POP 。
IT 块

结构如下图:

IT 指令的 mask 编码为从高到低,T 为 0,E 为 1 ,最后填一个 1 表示结束。比如 ITTEE EQ 的 mask 的二进制形式为 0111 。
调用约定
- 前 4 个参数:R0-R3,其它参数栈传递
- 非异变寄存器:R4-R11,使用此类寄存器的函数负责恢复寄存器原来的值。
- R11/FP:栈帧指针,类似 EBP。
- R12:导入表寻址
函数示例:
0x00010570 push {fp, lr}; ; 保存 FP 和 LR 寄存器,其中 FP 寄存器在栈顶。
0x00010574 add fp, sp, #4; ; FP 寄存器指向保存返回地址的位置。
0x00010578 sub sp, sp, #0x20; ; 抬升栈顶,开辟栈空间。
0x0001057C sub r3, fp, #0x24; ; R3 寄存器指向局部变量 char s[0x24] 开头,也就是栈顶。
0x00010580 mov r2, #0x20; ; memset 参数3
0x00010584 mov r1, #0; ; memset 参数2
0x00010588 mov r0, r3; ; memset 参数1
0x0001058C bl #0x10410; ; 调用 memset@plt
0x00010590 ldr r0, [pc, #0x40]; ; 由于是 ARM 模式,因此是取 0x00010590 + 8 + 0x40 = 0x000105D8 地址处的值。考虑到 ARM 的访存能力,编译器会为每个函数创建一个地址表来记录全局变量的地址。
0x00010594 bl #0x103d4; ; 调用 puts@plt
0x00010598 ldr r0, [pc, #0x3c];
0x0001059C bl #0x103d4;
0x000105A0 ldr r0, [pc, #0x38];
0x000105A4 bl #0x103d4;
0x000105A8 ldr r0, [pc, #0x34];
0x000105AC bl #0x103bc;
0x000105B0 sub r3, fp, #0x24; ; R3 寄存器指向局部变量 char s[0x24] 开头。
0x000105B4 mov r2, #0x38; ; read 第 3 个参数
0x000105B8 mov r1, r3; ; read 第 2 个参数
0x000105BC mov r0, #0; ; read 第 1 个参数
0x000105C0 bl #0x103c8; ; 调用 read@plt
0x000105C4 ldr r0, [pc, #0x1c];
0x000105C8 bl #0x103d4;
0x000105CC mov r0, r0;
0x000105D0 sub sp, fp, #4; ; SP = FP - 4 ,即指向了栈上保存 FP 寄存器的值的位置。
0x000105D4 pop {fp, pc}; ; 恢复 FP 和 PC 寄存器。
.text:000105D8 B0 06 01 00 off_105D8 DCD aForMyFirstTric ; DATA XREF: pwnme+20↑r
.text:000105D8 ; "For my first trick, I will attempt to f"...
.text:000105DC 10 07 01 00 off_105DC DCD aWhatCouldPossi ; DATA XREF: pwnme+28↑r
.text:000105DC ; "What could possibly go wrong?"
.text:000105E0 30 07 01 00 off_105E0 DCD aYouThereMayIHa ; DATA XREF: pwnme+30↑r
.text:000105E0 ; "You there, may I have your input please"...
.text:000105E4 90 07 01 00 off_105E4 DCD format ; DATA XREF: pwnme+38↑r
.text:000105E4 ; "> "
.text:000105E8 94 07 01 00 off_105E8 DCD aThankYou ; DATA XREF: pwnme+54↑r
.text:000105E8 ; "Thank you!"
对应反编译代码如下:
int pwnme()
{
char s[36]; // [sp+0h] [bp-24h] BYREF
memset(s, 0, 0x20u);
puts("For my first trick, I will attempt to fit 56 bytes of user input into 32 bytes of stack buffer!");
puts("What could possibly go wrong?");
puts("You there, may I have your input please? And don't worry about null bytes, we're using read()!\n");
printf("> ");
read(0, s, 0x38u);
return puts("Thank you!");
}
MIPS32
寄存器
通用寄存器
MIPS 有 32 个通用寄存器 (General purpose registers),以美元符号 ($) 表示。可以表示为 $0~ 31 ,也可以用寄存器名称表示如, 31,也可以用寄存器名称表示如, 31,也可以用寄存器名称表示如,sp、 t 9 、 t9 、 t9、fp 等等。
| 寄存器 | 名称 | 用途 |
|---|---|---|
| $0 | $zero | 常量0 |
| $1 | $at | 保留给汇编器 |
| $2-$3 | v 0 − v0- v0−v1 | 函数调用返回值 |
| $4-$7 | a 0 − a0- a0−a3 | 函数调用参数 |
| $8-$15 | t 0 − t0- t0−t7 | 暂时使用,不需要保存恢复 |
| $16-$23 | s 0 − s0- s0−s7 | 使用需要保存和恢复 |
| $24-$25 | t 8 − t8- t8−t9 | 暂时使用,不需要保存和恢复,$t9 通常与调用函数有关 |
| $28 | $gp | 全局指针,用来充当寄存器间接寻址时的基址寄存器 |
| $29 | $sp | 堆栈指针 |
| $30 | $fp | 栈帧指针 |
| $31 | $ra | 返回地址 |
pwndbg 中的 S8 寄存器对应的是 $fp,而 pwndbg 中的 FP 寄存器貌似是虚拟出来用来表示栈底的,大概就是始终指向每次进一个函数时的栈顶位置。
修改一下 pwndbg/lib/regs.py 中寄存器的定义,让 $ra 寄存器也能显示出来。
# http://logos.cs.uic.edu/366/notes/mips%20quick%20tutorial.htm
# r0 => zero
# r1 => temporary
# r2-r3 => values
# r4-r7 => arguments
# r8-r15 => temporary
# r16-r23 => saved values
# r24-r25 => temporary
# r26-r27 => interrupt/trap handler
# r28 => global pointer
# r29 => stack pointer
# r30 => frame pointer
# r31 => return address
mips = RegisterSet(
frame="fp",
retaddr=("ra",),
gpr=(
"v0",
"v1",
"a0",
"a1",
"a2",
"a3",
"t0",
"t1",
"t2",
"t3",
"t4",
"t5",
"t6",
"t7",
"t8",
"t9",
"s0",
"s1",
"s2",
"s3",
"s4",
"s5",
"s6",
"s7",
"s8",
"gp",
"ra",
),
args=("a0", "a1", "a2", "a3"),
retval="v0",
)
特殊寄存器
MIPS32 架构还定义了 3 个特殊寄存器,分别是 P C (程序计数器)、 PC(程序计数器)、 PC(程序计数器)、HI (乘除结果高位寄存器)和 L O (乘除结果低位寄存器)。在进行乘运算的时候, LO (乘除结果低位寄存器)。在进行乘运算的时候, LO(乘除结果低位寄存器)。在进行乘运算的时候,HI 和 $LO 保存乘法的结果,其中 H I 保存高 32 位, HI 保存高 32 位, HI保存高32位,LO 保存低 32 位。而在除法运算中, H I 保存余数, HI 保存余数, HI保存余数,LO 保存商。
运算指令
MIPS 的运算指令有 ADD ,SUB,MULT,DIV,AND,OR,XOR 等,运算指令有如下特征:
- 运算指令通常带有 3 个操作数,表示为后两个操作数做运算,结果存放在第一个操作数中,以 ADD 为例, 指令
add $d, $s, $t表示$d = $s + $t。 - 运算指令后面会跟一个后缀来描述操作数的类型,以 ADD 指令为例:
- ADD 加法指令,语法为:
add $d, $s, $t。 - ADDI(Add immediate)表示第三个操作数为有符号的立即数,语法为:
addi $t, $s, imm。 - ADDU(Add unsigned)表示操作数是无符号数,语法为:
addu $d, $s, $t。 - ADDIU( Add immediate unsigned)前两个指令特征的叠加,语法为:
addiu $t, $s, imm。
- ADD 加法指令,语法为:
另外移位操作 SL(左移),SR(右移)后面必须跟后缀描述操作类型等,以 SR 为例有如下形式:
- SRA(Shift right arithmetic):算术右移指令,高位补符号位,语法为:
sra $d, $t, h。
注意没有算术左移指令,因为左移不需要区分类型。 - SRL(Shift right logical):逻辑右移指令,高位补 0 ,语法为:
srl $d, $t, h。 - SRLV(Shift right logical variable):移位的位数在寄存器中,语法为:
srlv $d, $t, $s。
条件判断指令
与 X86 和 ARM 架构不同,MIPS 没有状态寄存器,条件判断有专门的指令,并将判断结果存放到指定的寄存器中,这与高级语言比较相似。条件判断指令的形式为 SLT+描述操作数类型的后缀。
以 SLT(Set on less than)为例,语法为 slt $d, $s, $t,表示如果 $s < $t 则将 $d 置 0 ,否则置 1 。
分支跳转指令
跳转指令
跳转指令的操作码长度为 6 比特,因此后面的 26 比特的操作数描述了跳转的地址。因为 MIPS 的指令长度为 4 字节,即每条指令的低 2 位始终为 0,也就是说 26 比特的操作数描述了28 比特长度的地址。因此 MIPS 的地址计算方式为:跳转地址 = (当前指令的起始地址 & 0xF0000000)|(操作数 << 2) 。
比如下面这段汇编:
.text:00400728 register_tm_clones:
...
.text:00400824 CA 01 10 08 j register_tm_clones
### 一、网安学习成长路线图
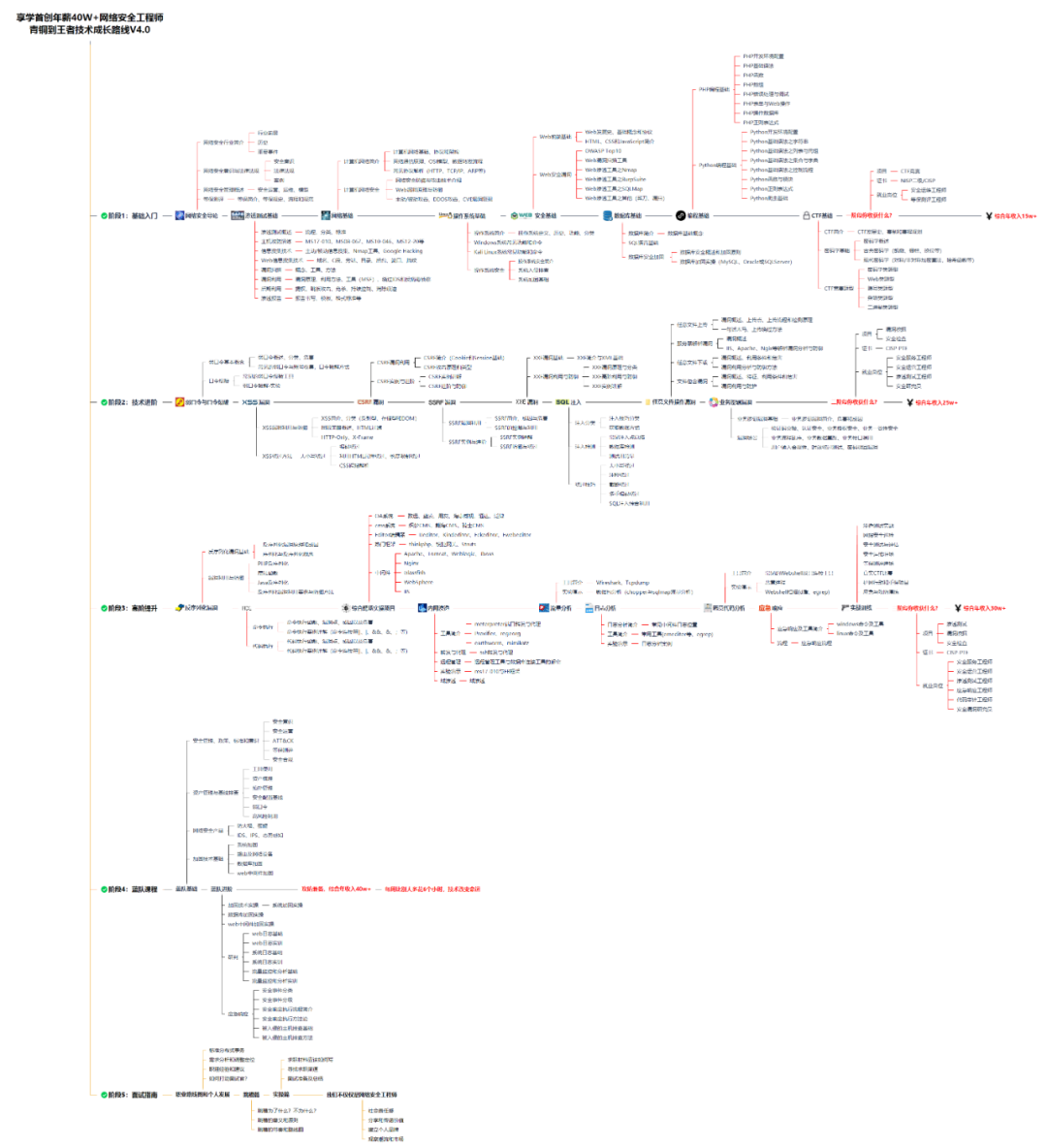
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
### 二、网安视频合集
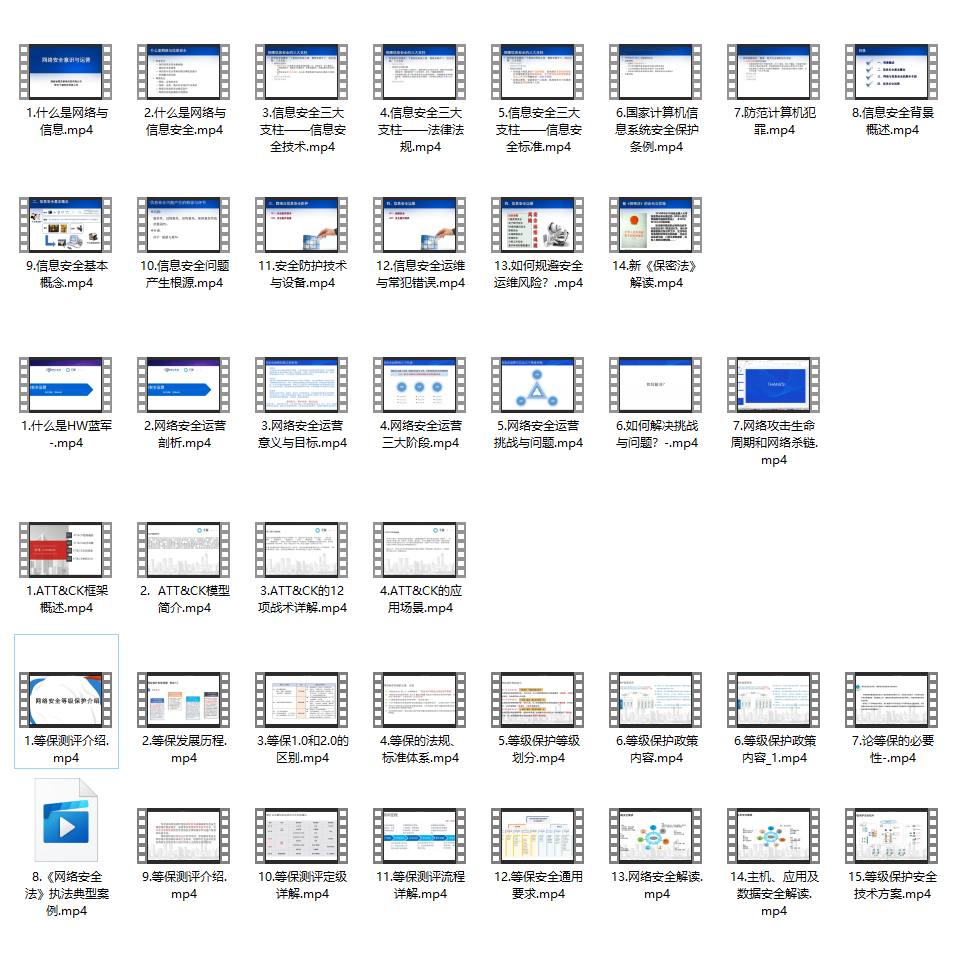
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
### 三、精品网安学习书籍
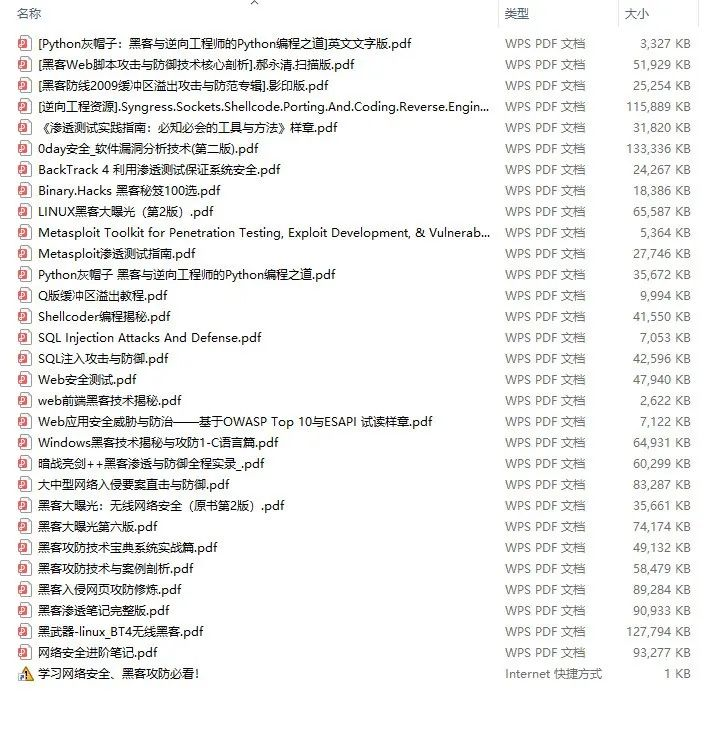
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
### 四、网络安全源码合集+工具包
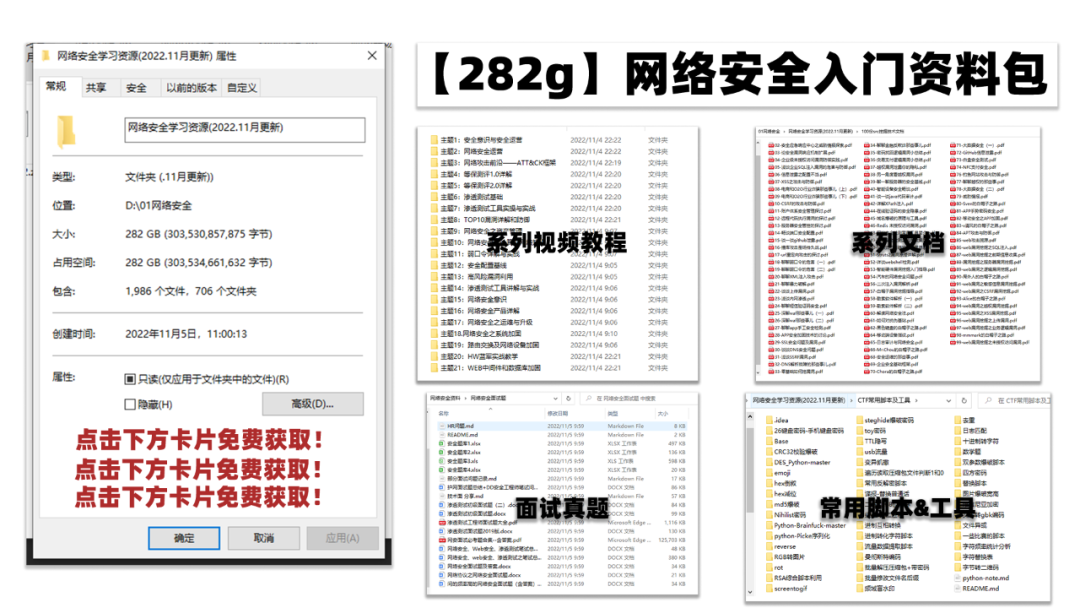
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 五、网络安全面试题
最后就是大家最关心的网络安全面试题板块
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
,可以学到不一样的思路。

### 四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

### 五、网络安全面试题
最后就是大家最关心的网络安全面试题板块

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**
[外链图片转存中...(img-YqpceKJb-1713332234965)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









